深入探索和分析MySQL数据库的全方位的优化实战开发指南(数据库底层优化篇)
- 硬件层面优化
- 数据库物理机分析
- 底层技术优化
- 磁盘性能优化
- 随机IO能力的能力支持
- RAID磁盘阵列
- RAID10
- RAID10的优势
- 网卡优化
- 网络设备
- 坑点问题建议
- 服务器硬件配置调整
- 服务器BIOS调整优化
- 提升CPU效率参考设置:
- 内存频率设置
- NUMA问题处理
- NUMA是什么
- NUMA的适合场景
- 阵列卡调整优化
- 操作系统层面优化
- MySQL进程实例的选择优化
- 建议将操作系统和数据分开
- 文件系统层优化
- 调整磁盘Cache mode
- 读写磁盘缓存
- 解析命令 `"sdparm -s WCE=1,RCD=0 -S /dev/sdb":`
- 状态值解析
- 采用Linux I/O scheduler算法deadline
- deadline算法
- 过期时间参数调优
- 采用xfs文件系统
- 调整日志大小
- 调整日志存储位置
- 调整日志和数据缓冲区
- 调整日志缓冲区大小
- 调整数据缓冲区大小
- 优化TCP协议栈
- 优化TCP连接层面
- 优化TCP连接时间
- 调整连接重试
- 提升连接范围和数量
- 扩展优化方向
- 网络优化
硬件层面优化
硬件层面的优化主要包括对数据库物理机的采购和配置。
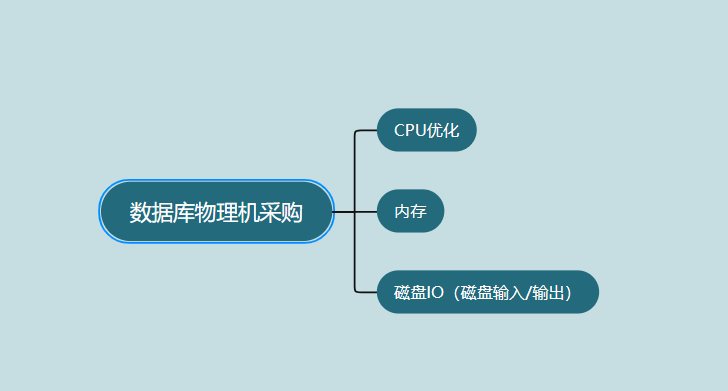
数据库物理机分析
-
CPU(运算):建议选择64位的CPU,每台机器至少配置2-4颗CPU,但最多可以达到16颗。此外,较大的L2缓存有助于性能提升。
-
内存:根据百度的建议,可以选择96G-256G的内存,并配置3-4个实例。而对于新浪的情况,32-64G的内存足够,并运行1-2个实例。
-
磁盘IO(磁盘输入/输出):建议选择机械盘,优先考虑SAS(串行附加存储)接口的磁盘,且数量越多越好。这样可以提高磁盘IO能力,从而提升数据库的读写性能。
注意,以上建议仅涉及硬件层面的优化,实际的配置还需根据具体的数据库类型、工作负载和预算等因素进行综合考虑。此外,还可以通过其他技术手段,如优化数据库参数设置、调整文件系统和磁盘分区等方式来进一步提升数据库性能。
底层技术优化
主要的优化方向:磁盘性能优化、RAID磁盘阵列、网卡优化和网络设备等。
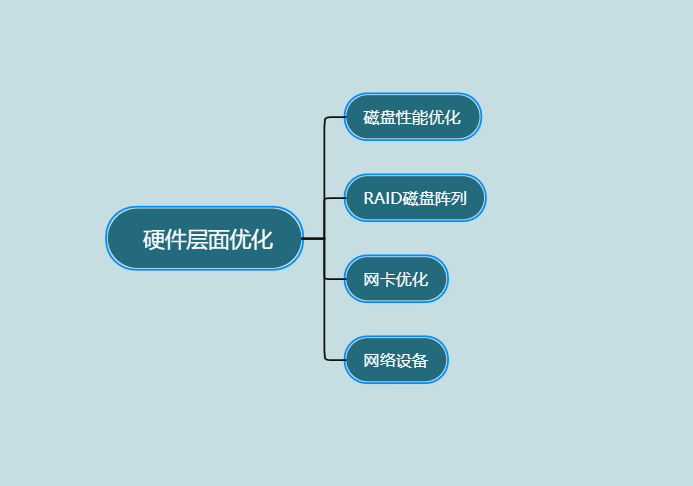
磁盘性能优化
-
SSD(高并发):对于需要高并发处理的场景,建议选择SSD或者PCIe SSD设备。这些设备可以提供上千倍的IOPS(每秒输入/输出操作数),以提高系统的性能。
-
SAS(普通业务线上):对于普通的线上业务,SAS(串行附加存储)设备是一种较好的选择。
-
SATA(线下):对于线下的业务,可以考虑使用SATA(串行ATA)设备。
随机IO能力的能力支持
-
SAS单盘能力:SAS磁盘的随机IO能力通常为300IOPS(每秒输入/输出操作数)。
-
SSD随机IO能力:SSD磁盘的随机IO能力可达到35000IOPS。
-
Flashcache HBA卡:通过使用Flashcache HBA卡,可以进一步提升随机IO的性能。
注意,以上建议仅基于一般性的情况,实际的性能优化策略应根据具体的应用场景、负载特点和预算等因素进行综合考虑。因此,在做出最终的硬件选择之前,建议与专业的硬件工程师或厂商进行进一步的讨论和评估。
RAID磁盘阵列
-
主库:主库可以选择RAID10,这样可以提供更好的数据安全性和读写性能。
-
从库:从库可以选择RAID10、RAID5或RAID0,具体选择取决于对数据安全性和性能的需求。从库的配置应该等于或大于主库的性能,以确保从库可以满足快速同步数据的需求。
RAID10
RAID 10是一种将RAID 1和RAID 0结合起来的磁盘阵列级别。它通过将数据镜像在多个驱动器上,并将这些驱动器组合成条带化阵列,以提供数据冗余和性能增强。
在RAID10中,首先将数据以镜像的方式写入两个驱动器,这确保了数据的冗余性和容错能力。 如果任一驱动器发生故障,系统可以从镜像驱动器中恢复数据,保持数据的完整性和可用性。
然后,这两个镜像驱动器被组合成一个RAID 0条带化阵列。RAID 0使用条带化方式将数据均匀分布在多个驱动器上,从而提高读写性能。RAID 0的优势是读写速度显著提升,因为可以同时从多个驱动器读取或写入数据。
RAID10的优势
RAID10的优势是在提供高性能的同时,保持了数据的冗余和安全性。它可以快速恢复驱动器故障,因为备份数据已经存在于镜像驱动器上,而无需重建整个阵列。
需要注意的是,RAID10至少需要四个驱动器来实现镜像和条带化的结合。通常,RAID10被用于需要高性能和数据冗余的应用,例如数据库服务器、虚拟化环境和关键业务系统。
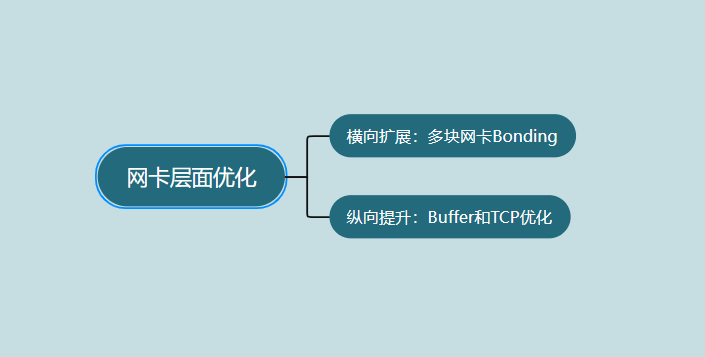
网卡优化
-
多块网卡Bonding:使用多块网卡进行Bonding(绑定),可以提供更高的带宽和冗余。这样可以提高网络的可靠性和性能。
-
Buffer和TCP优化:通过调整网卡缓冲区以及优化TCP参数,可以提升网络传输的效率和稳定性,从而提高数据库的性能。
网络设备
-
千兆网卡:建议使用千兆网卡,以满足大部分数据库的传输需求。
-
千兆/万兆交换机:选择适当的千兆或万兆交换机,以满足数据库在局域网中的数据传输需求。
坑点问题建议
-
虚拟技术问题:考虑到数据库是IO密集型服务,建议尽量避免使用虚拟化技术,以避免因为资源共享而造成的性能问题。
-
主库和从库的资源分配:从库的硬件性能应该不低于主库,以确保它可以处理同步数据的压力,并保持和主库的数据一致性。
服务器硬件配置调整
服务器BIOS调整优化
提升CPU效率参考设置:
-
打开性能功耗优化(DAPC)模式,以发挥CPU的最大性能。这对于数据库通常需要高运算量的情况下非常有用。
-
打开CIE和CStates等选项,以提升CPU的效率。这些选项将有助于实现更好的能量管理和性能平衡。
内存频率设置
在内存设置菜单中,选择最佳性能选项,例如Memory Frequency(内存频率)选择Maximum Performance(最佳性能)。这将确保内存以最高的频率运行,以提高系统性能。
NUMA问题处理
启用Node Interleaving选项,以避免NUMA(非一致性存储访问)问题。这将帮助平衡系统中不同节点的内存访问,提高性能和效率。
NUMA是什么
NUMA(Non-Uniform Memory Access)是一种计算机体系结构设计,旨在处理多处理器系统中的内存访问不均匀性问题。
在多处理器系统中,每个处理器都有自己的本地内存和共享内存。本地内存是与处理器直接关联的,可以快速访问。而共享内存则由多个处理器共享,访问速度相对较慢。
NUMA系统通过在物理内存和处理器之间创建节点(node)来解决内存访问不均匀性。每个节点包含多个处理器和本地内存组成,并且可以与其他节点共享内存。每个处理器可以更快地访问本地节点的内存,而访问远程节点的内存速度较慢。
操作系统和应用程序可以通过NUMA感知来优化内存访问。通过将任务分配给最接近其数据所在节点的处理器,可以减少内存访问的延迟,并提高系统性能。
NUMA的适合场景
NUMA设计适用于大型多处理器系统,特别是在需要处理大量内存的高性能计算、服务器和虚拟化环境中。它有助于提高数据访问效率,并减少内存访问的延迟。
注意,这些调整建议是一般性的,不同服务器的BIOS设置可能略有不同。在进行调整之前,请仔细阅读服务器的BIOS手册,并确保了解每个选项的功能和影响。此外,建议在进行任何BIOS调整之前备份重要的数据和配置,以防止意外的问题发生。
阵列卡调整优化
-
建议购置带有CACHE和BBU模块的阵列卡,尤其适用于使用机械硬盘的环境。
-
建议将阵列写策略设置为WEB或甚至OFRCE WB,特别适用于对数据安全要求较高的场景。这些写策略将使用写回(write back)方式来提升写入性能。
-
强烈建议不使用WT策略,并关闭阵列的预读策略。WT策略可能会降低写入性能,并且预读策略对于一些特定的工作负载可能并不适用。
操作系统层面优化
MySQL进程实例的选择优化
建议将操作系统和数据分开
“将操作系统和数据分开,既在逻辑上也在物理上进行分离” 这句话的意思是为了获得最佳性能,建议将操作系统和数据库的数据存储位置分开。
在逻辑上分离意味着,操作系统和数据库应该使用不同的目录或分区进行存储。这样可以确保操作系统的文件和数据库的数据文件分开管理,避免混淆和冲突。
在物理上分离意味着,可以将操作系统和数据库安装在不同的物理硬盘上。这样做可以避免操作系统和数据库之间共享磁盘资源导致的性能瓶颈,并提高数据库的读写速度。
通过将操作系统和数据分开,在逻辑和物理上进行分离,可以提高系统的整体性能和灵活性。这种配置使得操作系统和数据库各自专注于其特定的任务,减少了资源竞争和冲突,提升了系统的稳定性和响应能力。
文件系统层优化
调整磁盘Cache mode
理解"调整磁盘Cache mode,启用WCE=1(Write Cache Enable),RCD=0(Read Cache Disable)模式"之前,让我们先了解一下磁盘的缓存。
读写磁盘缓存
磁盘缓存是一种临时存储机制,用于加快磁盘的读写速度。它主要包括读缓存和写缓存。
-
读缓存(Read Cache)存储最近读取的数据块,当再次访问相同数据时,可以直接从缓存中读取,而不需要再次从磁盘读取数据,提高了读取速度。
-
写缓存(Write Cache)存储要写入磁盘的数据,当应用程序进行写操作时,数据首先被写入缓存中,然后由磁盘控制器异步地将数据写入磁盘。这可以显著提高写入速度。
解析命令 "sdparm -s WCE=1,RCD=0 -S /dev/sdb":
- “sdparm” 是一个用于设置磁盘参数的命令行实用工具。
- “-s WCE=1,RCD=0” 标志将WCE(Write Cache Enable)设置为1(启用写缓存),将RCD(Read Cache Disable)设置为0(禁用读缓存)。
- “-S /dev/sdb” 标志指定要应用这些参数的磁盘,这里是/dev/sdb。
状态值解析
-
通过将WCE设置为1,我们启用了磁盘的写缓存功能。这意味着写操作将首先被写入磁盘缓存,然后由磁盘控制器异步地将数据写入实际磁盘。这可以显著提高写入性能,但也带来了一定的数据丢失风险,因为缓存中的数据尚未被持久化到磁盘。
-
通过将RCD设置为0,我们禁用了磁盘的读缓存功能。这意味着每次进行读取操作时,数据都将直接从磁盘读取,而不会使用读取缓存。这样可以确保读取到的数据是最新的,而不是读取到了缓存中旧的数据。
注意,这些参数的设置可能因磁盘型号和驱动程序而异,因此在应用该命令之前,请确保对应硬件和驱动程序支持这些参数设置。
采用Linux I/O scheduler算法deadline
Linux中的I/O调度器是用来管理和调度磁盘I/O操作的算法。其中,deadline是一种常用的I/O调度算法。
deadline算法
deadline算法的主要目标是通过合理分配磁盘带宽,提高磁盘访问的响应时间和性能。它在处理I/O请求时,将读写请求分成两个队列,分别用于读取和写入操作。它采用了三个重要参数来控制调度行为:
-
read_expire(读取超时时间):它定义了一个读取请求在队列中可以等待的最长时间。当读取请求超过这个时间时,它会被放入写入队列以提高响应时间。一般建议将read_expire设置为write_expire的一半。
-
write_expire(写入超时时间):它定义了一个写入请求在队列中可以等待的最长时间。当写入请求超过这个时间时,它会被强制执行,以保证写入操作的及时性。
-
fifo_batch(批量处理请求数):它定义了一次性处理的最大请求数量。当队列中达到fifo_batch设置的请求数时,调度器会将这些请求作为一个批次处理,以提高效率。
过期时间参数调优
通过设置这些参数,可以根据实际需求来调整磁盘I/O的调度行为。对于CentOS Linux系统,建议将read_expire设置为write_expire的一半,以平衡读取和写入操作的响应时间。
你可以使用以下命令来设置deadline调度器的参数:
echo 500 >/sys/block/sdb/queue/iosched/read_expire
echo 1000 >/sys/block/sdb/queue/iosched/write_expire
以上命令将read_expire设置为500毫秒,write_expire设置为1000毫秒。你也可以根据具体情况进行自定义设置。通过调整deadline调度算法的参数,可以优化磁盘I/O性能,提高系统的响应速度和效率。
采用xfs文件系统
如果你使用XFS文件系统,并且希望进行高性能设置,以下是一些调整XFS文件系统日志和缓冲变量的建议:
调整日志大小
日志是XFS文件系统用于记录文件系统操作的关键组成部分。增加日志大小可以提高系统的写入性能和吞吐量。通过以下命令可以调整日志大小(以512字节块为单位):
sudo xfs_admin -L <log_size> /dev/<device>
其中,<log_size>是期望的日志大小,<device>是XFS文件系统所在的设备名称。
调整日志存储位置
XFS文件系统的日志存储在文件系统的起始扇区。如果你的磁盘布局使得起始扇区被频繁访问,你可以将日志存储在其他位置来减少争用。可以使用以下命令将日志存储在指定块设备上:
sudo xfs_admin -J device=/dev/<journal_device> /dev/<filesystem_device>
其中,<journal_device>是用于存储日志的设备名称,<filesystem_device>是XFS文件系统所在的设备名称。
调整日志和数据缓冲区
XFS使用日志和数据缓冲区来提高性能。你可以通过以下方法调整这些缓冲区的大小:
调整日志缓冲区大小
编辑/etc/sysctl.conf文件,在末尾添加以下行,并重新加载sysctl配置:
fs.xfs.logbufs=<num_log_buffers>
其中, <num_log_buffers>是期望的日志缓冲区数目。增加日志缓冲区的大小可以提高写入性能。
调整数据缓冲区大小
编辑/etc/sysctl.conf文件,在末尾添加以下行,并重新加载sysctl配置:
vm.dirty_background_bytes=<background_bytes>
vm.dirty_bytes=<dirty_bytes>
其中,<background_bytes>是系统进程在触发后台写入操作之前保持的脏数据大小(单位:字节),<dirty_bytes>是系统进程在触发强制写入操作前可以累积的脏数据大小(单位:字节)。增加数据缓冲区的大小可以提高写入性能。
优化TCP协议栈
这些配置参数是用来优化TCP连接性能的。我们逐一解释它们的作用:
优化TCP连接层面
-
net.ipv4.tcp_tw_recycle=1:启用TCP连接的快速回收,即允许在TIME_WAIT状态下的连接被立即回收重用。这可以减少服务器上处于TIME_WAIT状态的连接数量,提高TCP连接的效率。 -
net.ipv4.tcp_tw_reuse=1:启用TCP连接的端口复用,即允许服务器上处于TIME_WAIT状态的本地端口被立即重用。这样可以避免端口耗尽的问题,提高系统对新连接的支持能力。
优化TCP连接时间
-
net.ipv4.tcp_fin_timeout=2:指定了处于FIN-WAIT-2状态的连接最长的保持时间,控制了关闭连接的速度。通过减少这个时间,系统可以更快地处理更多的连接。 -
net.ipv4.tcp_keepalive_time=600:指定了TCP的Keepalive发送间隔时间。Keepalive机制用于检测连接是否存活,通过减少检测时间,系统可以更快地释放闲置连接资源。 -
net.ipv4.tcp_max_syn_backlog=16384:指定了系统支持的最大SYN半连接数。SYN半连接是TCP三次握手中的第一次握手,通过增加这个数值,系统可以处理更多的连接请求。
调整连接重试
net.ipv4.tcp_synack_retries=1、net.ipv4.tcp_sync_retries=1:指定了TCP连接建立过程中的SYN包重试次数,减少重试次数可以加速连接建立的速度。
提升连接范围和数量
net.ipv4.ip_local_prot_range=450065535:指定了系统可用的本地端口范围。通过增大这个范围,系统可以支持更多的并发连接。
扩展优化方向
-
net.ipv4.tcp_timestamps = 0:将TCP时间戳功能禁用。TCP时间戳用于在网络中识别重复包和计算往返时间(RTT)。禁用时间戳可以减少对服务器的计算负担,但也可能影响某些特定的网络应用。 -
net.ipv4.tcp_max_orphans = 3276800:指定了系统在没有相关的socket文件句柄的情况下所能持有的TCP套接字数量的最大值。TCP套接字是在TIME_WAIT状态下的连接,该参数可以控制套接字的最大数量,避免资源耗尽问题。 -
net.ipv4.tcp_max_tw_buckets = 360000:指定了系统为处理处于TIME_WAIT状态的连接所维护的最大套接字桶的数量。套接字桶用于存储已关闭的连接,以便在TIME_WAIT状态下等待一段时间以确保网络上的数据已传输完毕。这个参数可以控制系统处理TIME_WAIT连接的效率和数量。
注意,修改这些参数可能会对系统性能和网络连接产生影响。在进行修改之前,请确保了解其含义和潜在的影响,并在进行修改之前备份重要的配置文件,并进行测试。
网络优化
-
net.core.rmem_max=16777216:设置了最大的套接字读缓冲区大小。套接字读缓冲区用于存储从网络接收的数据。较大的缓冲区大小可以提高系统对数据接收的效率和吞吐量。这里设置为16MB。 -
net.core.wmem_max=16777216:设置了最大的套接字写缓冲区大小。套接字写缓冲区用于存储将要发送到网络的数据。较大的缓冲区大小可以提高系统对数据发送的效率和吞吐量。这里设置为16MB。 -
net.core.wmem_default=8388608:设置了默认的套接字写缓冲区大小。这个值是新创建的套接字写缓冲区的初始大小。这里设置为8MB。 -
net.core.rmem_default=8388608:设置了默认的套接字读缓冲区大小。这个值是新创建的套接字读缓冲区的初始大小。这里设置为8MB。 -
net.ipv4.tcp_rmem=4096 87380 16777216:设置了TCP套接字的读缓冲区大小的参数。它是一个由三个值组成的数组,分别表示最小缓冲区大小、默认缓冲区大小和最大缓冲区大小。在这里,最小缓冲区大小被设置为4KB,默认缓冲区大小为87.38KB,最大缓冲区大小为16MB。 -
net.ipv4.tcp_wmem=4096 65536 16777216:设置了TCP套接字的写缓冲区大小的参数。与tcp_rmem类似,这里最小缓冲区大小为4KB,默认缓冲区大小为64KB,最大缓冲区大小为16MB。 -
net.ipv4.tcp_mem=94500000 915000000927000000:设置了Linux autotuning TCP缓冲区大小的参数。这个参数指定了当前系统中所有TCP缓冲区的最小值、默认值和最大值。在这里,最小值为94.5MB,默认值为915MB,最大值为927MB。这个参数可以让系统根据当前网络环境动态调整TCP缓冲区的大小。 -
net.core.netdev_max_backlog=3000:设置了网络设备接收队列的最大长度。这个参数指定了在网络接口上等待处理的传入数据包的最大数量。较大的队列长度可以缓解瞬时的网络流量高峰。这里设置为3000。
这些配置旨在优化系统的套接字缓冲区大小、TCP接收/发送缓冲区以及网络设备接收队列长度。通过适当调整这些参数,可以提高系统的网络性能和吞吐量。请注意,在进行修改之前,请确保了解其含义和潜在的影响,并在进行修改之前备份重要的配置文件,并进行测试。