case表达式
CASE表达式是SQL里非常重要而且使用起来非常便利的技术,我们应该学会用它来描述条件分支。本节将通过行列转换、已有数据重分组(分类)、与约束的结合使用、针对聚合结果的条件分支等例题,来介绍CASE表达式的用法。标红即为他的作用
先读如下文章
明白mysql是行引擎
MySQL行列转换,理解 case when then else end as的用法_m0_72084056的博客-CSDN博客
case表达式的基本概念
CASE表达式有简单CASE表达式(simple case expression)和搜索CASE表达式(searched case expression)两种写法 如下图所示

这两种写法的执行结果是相同的,“sex”列(字段)如果是’1',那么结果为男;如果是’2',那么结果为女。简单CASE表达式正如其名,写法简单,但能实现的事情比较有限。简单CASE表达式能写的条件,搜索CASE表达式也能写,所以我们着重去看搜索CASE表达式
注:在发现为真的WHEN子句时,CASE表达式的真假值判断就会中止,而剩余的WHEN子句会被忽略。为了避免引起不必要的混乱,使用WHEN子句时要注意条件的排他性。
- 剩余的WHEN子句被忽略的写法示例
-
--例如,这样写的话,结果里不会出现“第二” CASE WHEN col_1 IN ('a', 'b') THEN’第一’ WHEN col_1 IN ('a') THEN’第二’ ELSE ’其他’ END
此外还需要注意
- 统一各分支返回的数据类型
- 不要忘了写END
- 养成写ELSE子句的习惯
- 与END不同,ELSE子句是可选的,不写也不会出错。不写ELSE子句时,CASE表达式的执行结果是NULL。但是不写可能会造成“语法没有错误,结果却不对”这种不易追查原因的麻烦,所以最好明确地写上ELSE子句(即便是在结果可以为NULL的情况下)。养成这样的习惯后,我们从代码上就可以清楚地看到这种条件下会生成NULL,而且将来代码有修改时也能减少失误。
将已有编号方式转换为新的方式并统计
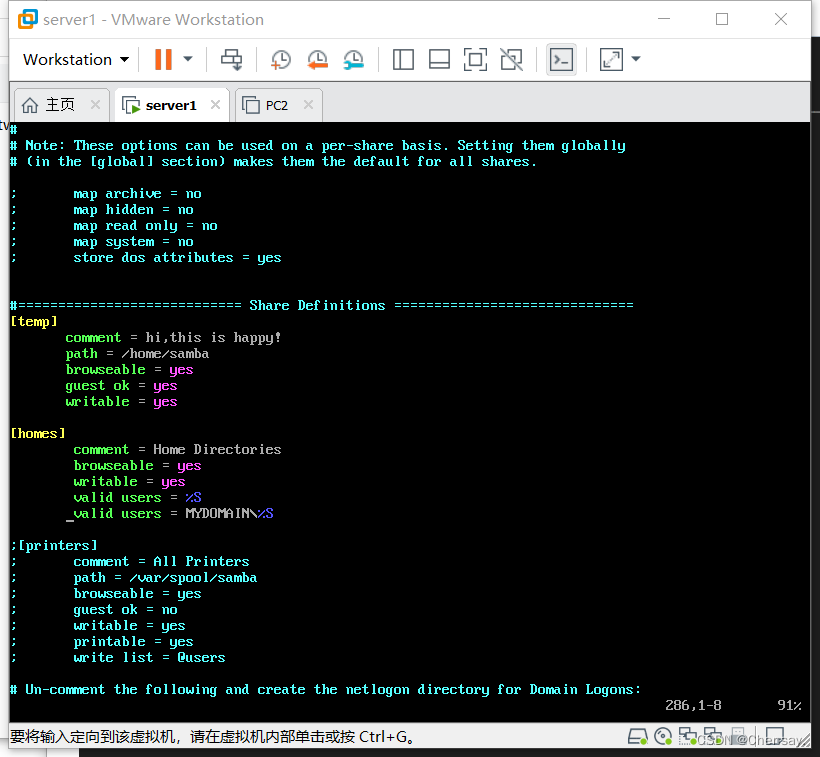
在进行非定制化统计时,我们经常会遇到将已有编号方式转换为另外一种便于分析的方式并进行统计的需求。例如,现在有一张按照“‘1:北海道’、‘2:青森’、……、‘47:冲绳’”这种编号方式来统计都道府县[插图]人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。具体来说,就是统计下表PopTbl中的内容,得出如右表“统计结果”所示的结果。
■ 统计数据源表PopTbl

- 转换成这种格式的结果

大家会怎么实现呢?定义一个包含“地区编号”列的视图是一种做法,但是这样一来,需要添加的列的数量将等同于统计对象的编号个数,而且很难动态地修改。而如果使用CASE表达式,则用如下所示的一条SQL语句就可以完成。为了便于理解,这里用县名(pref_name)代替编号作为GROUP BY的列。
各个语句的执行顺序(穿插的小点)
sql语句的书写顺序select--from--where--group by--having--order by
与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行
from--where--group by--having--select--order by,
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据
2.from后面的表关联,是自右向左解析的
而where条件的解析顺序是自下而上的。
也就是说,在写SQL文的时候,尽量把数据量大的表放在最右边来进行关联, 而把能筛选出大量数据的条件放在where语句的最下面。
同样的

个技巧非常好用。不过,必须在SELECT子句和GROUP BY子句这两处写一样的CASE表达式,这有点儿麻烦。后期需要修改的时候,很容易发生只改了这一处而忘掉改另一处的失误。
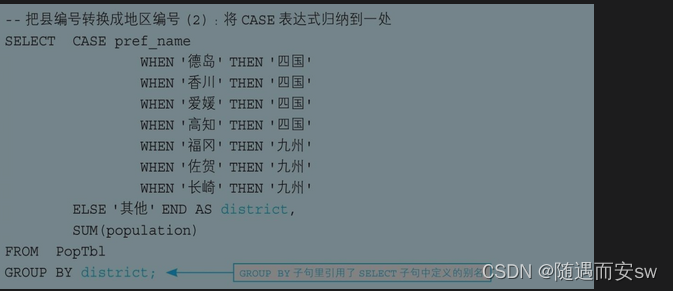
不过有些数据库不支持,有些事不规范的,因为group是先于 select执行的 ,但是方便啊
用一条SQL语句进行不同条件的统计
进行不同条件的统计是CASE表达式的著名用法之一。例如,我们需要往存储各县人口数量的表PopTbl里添加上“性别”列,然后求按性别、县名汇总的人数。具体来说,就是统计表PopTbl2中的数据,然后求出如表“统计结果”所示的结果
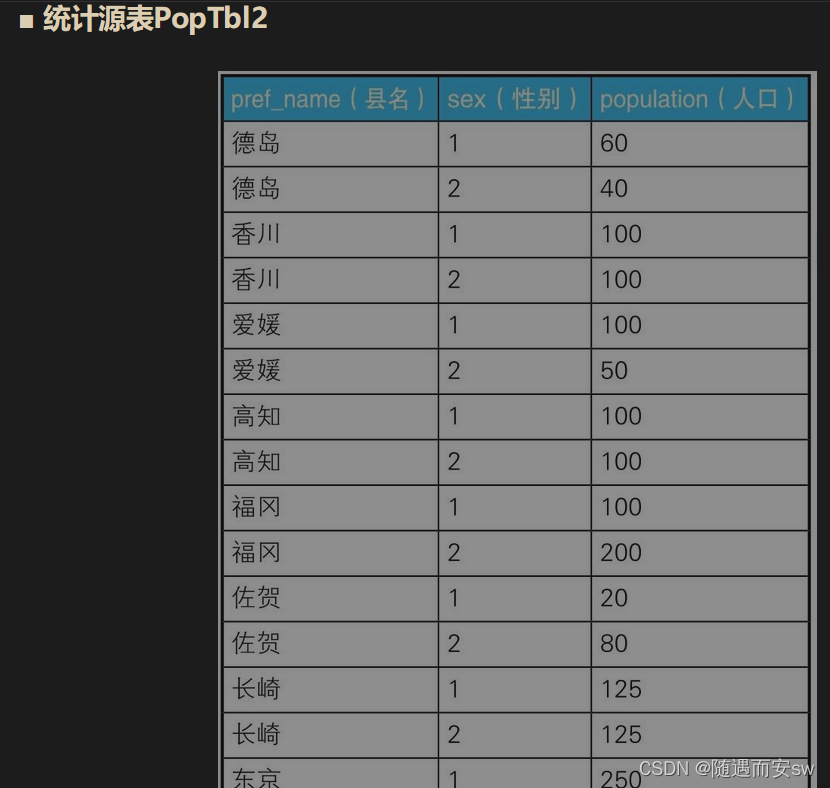
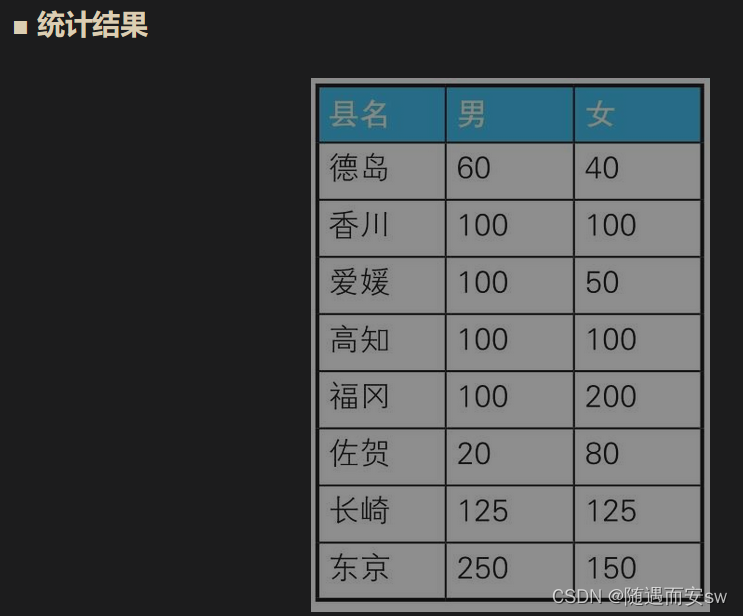
从表中我们看到我们甚至更改了变得结构 我的理解这个case 表达式甚至能让你 查询出表中没有,但是可以总计欸的字段
两张题解
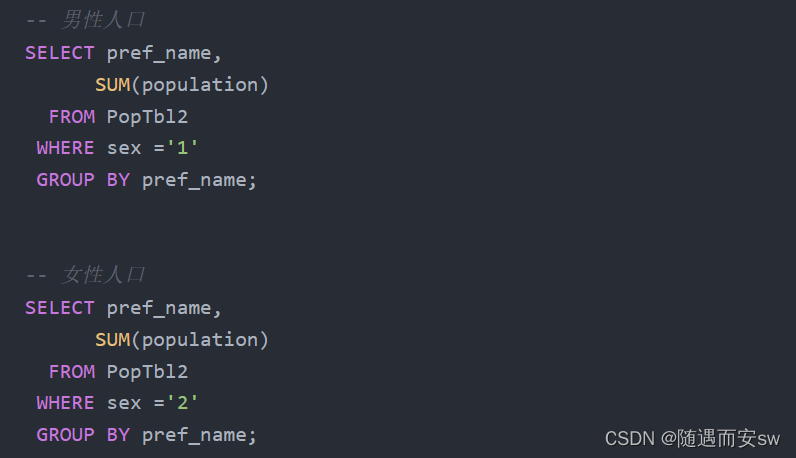
最后需要通过宿主语言或者应用程序将查询结果按列展开。如果使用UNION,只用一条SQL语句就可以实现,但使用这种做法时,工作量并没有减少,SQL语句也会变得很长。而如果使用CASE表达式,下面这一条简单的SQL语句就可以搞定
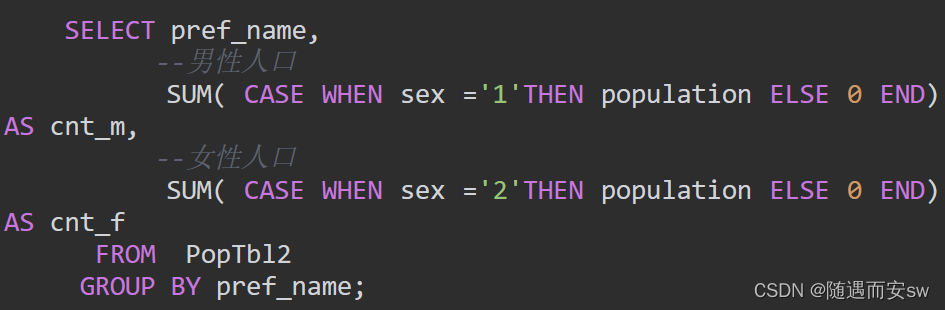
上面这段代码所做的是,分别统计每个县的“男性”(即’1')人数和“女性”(即’2')人数。也就是说,这里是将“行结构”的数据转换成了“列结构”的数据。除了SUM, COUNT、AVG等聚合函数也都可以用于将行结构的数据转换成列结构的数据。
写一句代表我对你们的嘲笑哈哈哈哈哈
新手用WHERE子句进行条件分支,高手用SELECT子句进行条件分支。
用CHECK约束定义多个列的条件关系
首先啊,check和case 是非常般配的一对 嘻嘻嘻嘻哈哈哈哈 ,我一定是以很新的方式 学习
假设某公司规定“女性员工的工资必须在20万日元以下”,而在这个公司的人事表中,这条无理的规定是使用CHECK约束来描述的,代码如下所示
CONSTRAINT check_salary CHECK
( CASE WHEN sex ='2'
THEN CASE WHEN salary <= 200000
THEN 1 ELSE 0 END
ELSE 1 END = 1 )
在这段代码里,CASE表达式被嵌入到CHECK约束里,描述了“如果是女性员工,则工资是20万日元以下”这个命题。在命题逻辑中,该命题是叫作蕴含式(conditional)的逻辑表达式,记作P→Q。
这里需要重点理解的是蕴含式和逻辑与(logical product)的区别。逻辑与也是一个逻辑表达式,意思是“P且Q”,记作P∧Q。用逻辑与改写的CHECK约束如下所示。
结论是上述两个语句的结果是不一样的

在UPDATE语句里进行条件分支
举个例子 下面是一张工资表
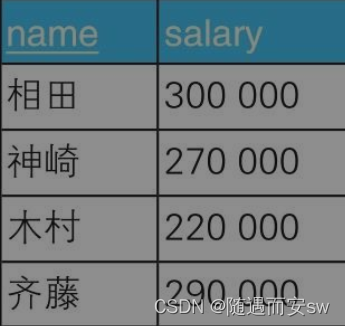
我们对表进行如下更新
1.对当前工资为30万日元以上的员工,降薪10%。
2.对当前工资为25万日元以上且不满28万日元的员工,加薪20%。
如果我们对这些更新条件进行单独更新的话,就会出现问题 比如刚刚更新完了第一条,那么第条更新完的数据又符合第二条他又更新了怎么办,
这时候 就用case 语句来解决这种多条件更新的问题
这样只用更新一次效率也快
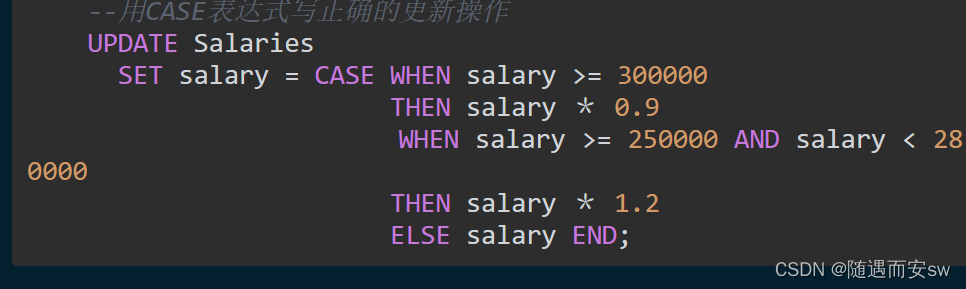
需要注意的是,SQL语句最后一行的ELSE salary非常重要,必须写上。因为如果没有它,条件1和条件2都不满足的员工的工资就会被更新成NULL。这一点与CASE表达式的设计有关,在刚开始介绍CASE表达式的时候我们就已经了解到,如果CASE表达式里没有明确指定ELSE子句,执行结果会被默认地处理成ELSE NULL。现在大家明白笔者最开始强调使用CASE表达式时要习惯性地写上ELSE子句的理由了吧?
值调换问题

在mysql中主键值重复会出错好像会出错
但是呢也一般是因为表设计错误才需要调换值
表之间的数据匹配


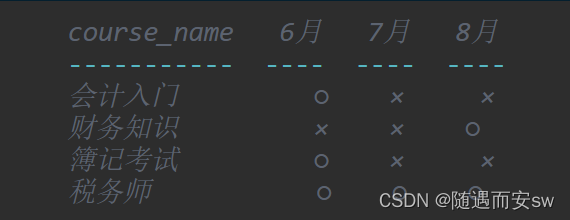
我们使用in和exist 关键词去查找
--表的匹配:使用IN谓词
SELECT course_name,
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200706) THEN'○'
ELSE'×'END AS "6月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200707) THEN'○'
ELSE'×'END AS "7月",
CASE WHEN course_id IN
(SELECT course_id FROM OpenCourses
WHERE month = 200708) THEN'○'
ELSE'×'END AS "8月"
FROM CourseMaster;
--表的匹配:使用EXISTS谓词
SELECT CM.course_name,
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200706
AND OC.course_id = CM.course_id) THEN'○'
ELSE'×'END AS "6月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200707
AND OC.course_id = CM.course_id) THEN'○'
ELSE'×'END AS "7月",
CASE WHEN EXISTS
(SELECT course_id FROM OpenCourses OC
WHERE month = 200708
AND OC.course_id = CM.course_id) THEN'○'
ELSE'×'END AS "8月"
FROM CourseMaster CM;
这样的查询没有进行聚合,因此也不需要排序,月份增加的时候仅修改SELECT子句就可以了,扩展性比较好。因为原来是有顺序的
无论使用IN还是EXISTS,得到的结果是一样的,但从性能方面来说,EXISTS更好。通过EXISTS进行的子查询能够用到“month, course_id”这样的主键索引,因此尤其是当表OpenCourses里数据比较多的时候更有优势
在CASE表达式中使用聚合函数
一句话就是case能代替having去办