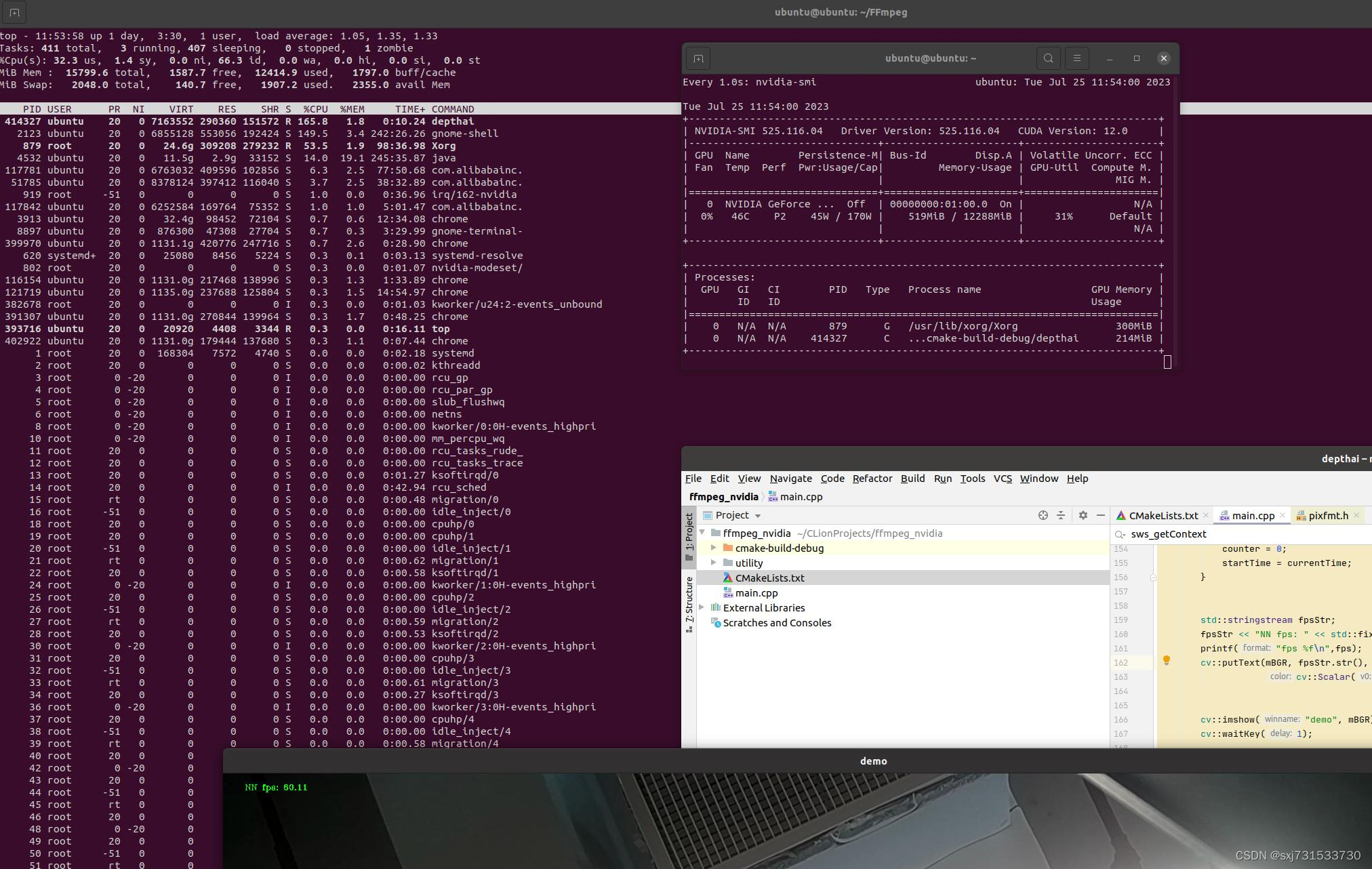
本课时我们主要了解 Curl 命令的使用和常见案例。在学习本课时的内容之前,你需要先了解 HTTP 的请求过程,以及 Linux 操作系统的基础知识。
首先,我们先来介绍一下 Curl ,Curl 是一个Linux命令行中的工具,它模拟客户端请求,遵循 请求协议为HTTP 或 HTTPS,我们在之前的课程里了解了 Chrome 浏览器下的开发者工具,它就是一个类似的工具,只不过它非 IDE 工具,是一个命令行工具。
其实很多场景中我们是需要命令行工具的,如你现在有一套脚本,你需要调用 HTTP API 接口,或是监控自己的网站服务端的状态,那就需要用命令做 HTTP\HTTPS 的请求调用,并获取结果。
另外当你需要使用一个工具能快速分析一个网站出现的故障或问题,而非必要用浏览器的方式,这个时候你也需要一个命令行工具来方便使用,所以运维工程师了解 Curl 命令的使用是十分必要的。
Curl 使用用途
本课时内容围绕 Curl 命令展开 ,并分享一些场景案例的使用经验。
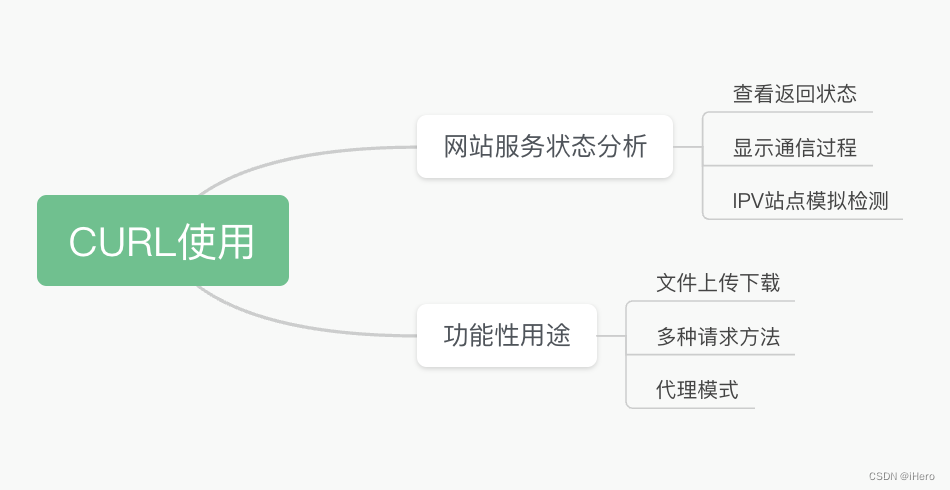
Curl 的使用主要分为两大类。
一个是网站服务的分析,工程师会希望了解查看网站的返回状态如何;希望了解整个 HTTP 通信过程;想知道特定场景如 IPV6 的服务站点环境下进行模拟检测,等等。
第二个类型就是功能用途的使用。这里我们会了解 Curl 如何上传文件、下载文件;如何做断点续传,如何发起多种 HTTP 的请求;如何使用到 Curl 的代理模式来进行访问。
网站服务分析
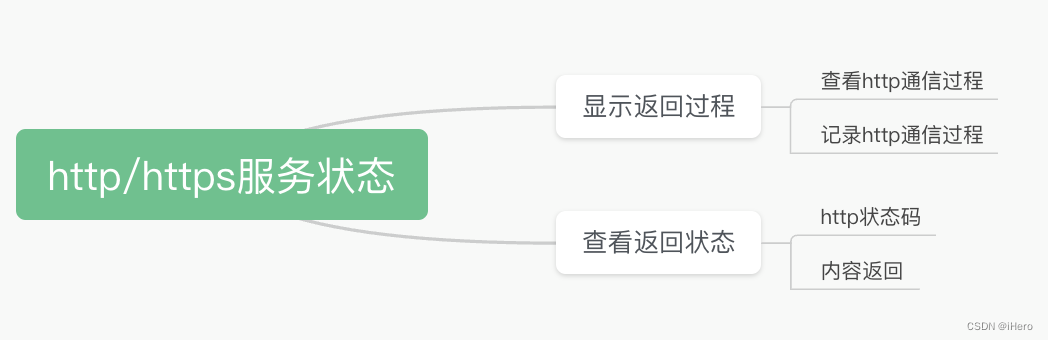
我们先从网站的服务分析开始讲起。聊到网站的状态分析,经常有同学会问我一些问题,比如说自己的网站无法打开怎么排查?自己安装了一个服务,打开浏览器请求不到,怎么去分析?提出这样的问题,我觉得你可能对于整个网站服务的故障排查思路不是非常清晰,下面我们来梳理一下。
当部署、变更完一个站点后,首先应该分析服务端状态,那先从进程开始:
- 我们查看进程是不是启动的?是不是存在的?
- 进程存在状态是否正常,是 running 的状态还是进入了死锁的状态?
另外,我们可以通过它对 CPU 等资源使用率去分析这个进程是否属于正常范围,还可以通过日志去分析它的错误信息。
在分析完进程状态都是正常后,接下来我们就需要去了解,为什么从客户端访问服务端会有问题?
- 首先,就要从底层的网络开始排查 ,你的网络状态是否可以 ping 通,第二点,建立 TCP 连接是否正常?这个时候我们可以通过
Telnet 或者 TCPdump 等方式去进行抓包或分析。 - 鉴定网络状态正常后,再往上层也就是应用层寻找问题,如果网站为 HTTP\HTTPS Web服务,那我们就需要模拟 HTTP
请求到服务端,去判断服务端返回的头信息和 body 信息是不是符合我们的预期,这个时候就需要用到相关的工具去进行分析了。Curl
命令就在这个过程中起到非常好的作用。
说到了检查网站 HTTP\ HTTPS 的服务状态,那 Curl 命令对于这块的分析主要是去排查哪些方面呢?
最通常的场景是要看整个服务端返回的状态。head 头信息里包含 HTTP 状态信息(Status Code),如果数值为 200 表示正常响应,如果非正常响应则会看到其他数值,比如 500、404、403 等等,我们就可以根据这个状态码去直接定位一个可能引起问题的方向,如:403 可能是因为访问受限,404 可能是没有找到文件,500 可能是程序出现的问题等
还有时候,我们选择分析它返回的 body 的内容是不是符合预期。这个都可以通过 Curl 命令来实现。
Curl 命令使用格式
接下来,一起看一下 Curl 的使用方式。
首先 Curl 命令后面加一个 options,表示配置 Curl 发起请求的参数(可选),最后加需要请求URL,这里我加一个 -i 的选项,代表终端只看服务端返回的头信息,没有加 -i 则默认查看返回的 body 数据内容。如果加了一个 –o output.txt 表示把服务端返回的内容输出到一个文件里面。
我们来展示一下是怎么做到的。
首先,我用 Curl 命令请求 baidu.com,这个时候我们会看到它返回的都是 body 里面的 HTML 代码,如果我们只想要看它返回的 response head 信息怎么办呢?我们可以加一个 -I 选项,就会看到服务端返回的相关头信息,这里面有很多 response head 信息,比如说 HTTP 的协议类型是 1.1,服务端状态码是 200,表示服务端返回正常。同时看到服务端返回的数据长度、类型以及缓存的头信息。
以上是 Curl 使用的普通模式,想必大部分同学应该比较清楚。接下来我们进一步看一下一些特殊的场景。
这里请求我的博客地址 URL(命令:curl www.taida.ltd),会发现并没有默认的 body 数据返回。为什么呢?因为服务端返回来一些重定向类型的状态码,比如 301、302 的这种重定向,是没有 body 数据的,只会返回头信息,所以我们可以先看头信息的内容。
在这个时候,如果想更加全面地了解整个通信过程,可以加一个 -v (命令:curl www.taida.ltd)参数。你可以看到请求服务端是不是已经发送出去了?并可以看到客户端发送的请求内容是什么,另外是看到服务端返回的情况,加 -v 的参数的作用就是可以把整个通信过程都打印出来。
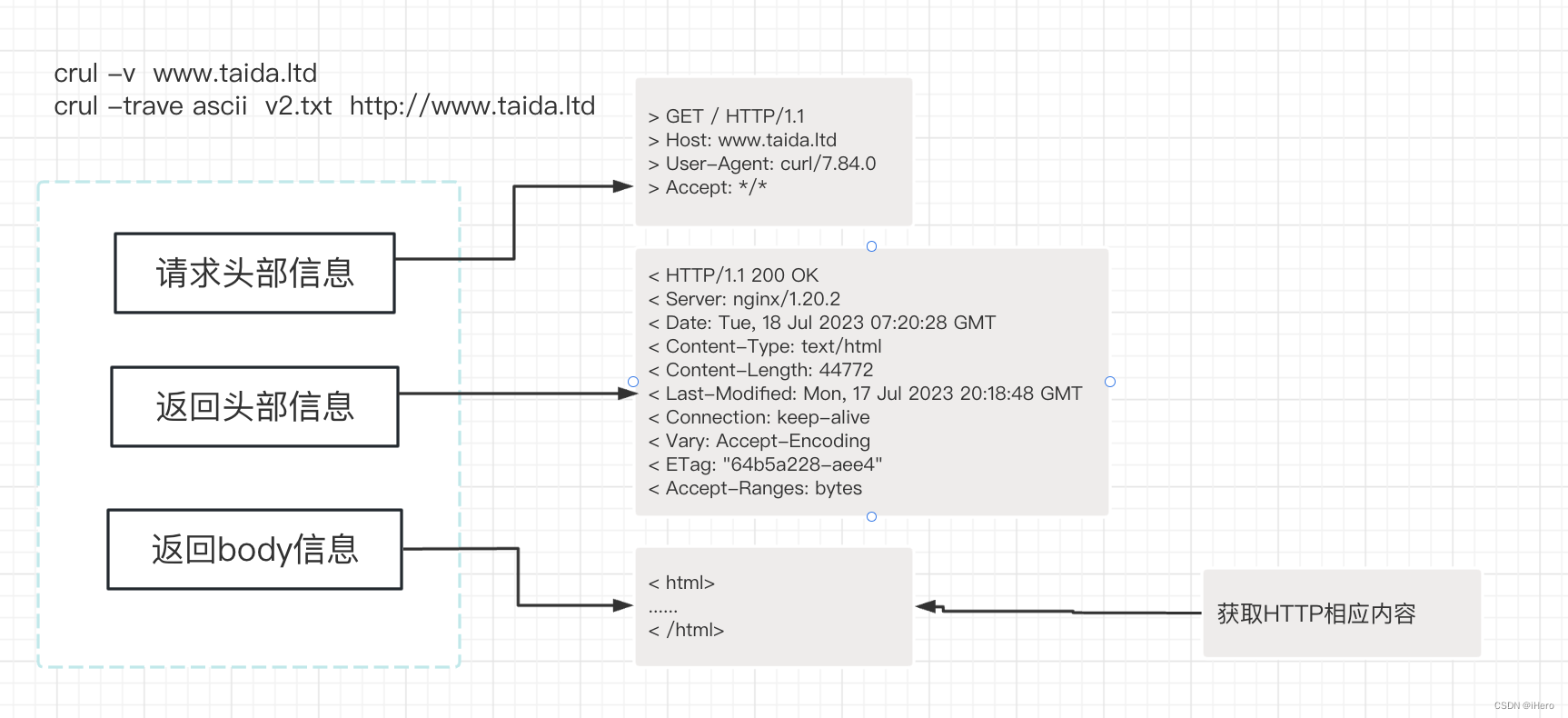
这里就是加入 -v 以后能看到整个请求过程,包含:请求的头信息是什么,然后服务端返回的头信息是什么,服务端返回的如果有 body 的信息的话,同样会打印出 body 信息。
在头信息里面,我们可能需要重点去关注服务状态的状态码。通常你可以根据如下规则分析:
回状态码在 100~199 之间,代表服务端是正常给到了一个信息响应,但没有完全建立起一次完整 HTTP 请求响应。
200~299 表示成功响应,看到这个状态码,可以认为服务端处理这次请求是正常的。
300~399 表示重定向,比如说 301、302 这些常见的重定向的状态码。
如果是 400 以上,说明客户端的请求方式得不到正常响应,那我们就需要具体去分析它的状态码,常见如 403、404、499、400 等相关的这些错误代码。你如果不了解,可以把错误代码在百度或者 Google 中搜索查看代表的是什么意思。
500+ 一般是服务端的程序或者逻辑相关的一些服务响应出现问题。
接下来,我们再来回到控制台来做进一步的演示。
通过 -v 参数(curl -v www.taida.ltd)可以看到服务端返回的状态码为 301,代表返回了一个重定向的状态码,并且会给到 location 的 head 头信息。我们知道 301 的状态码表示直接把请求重定向到另外一个地址, location 后的这个地址就是重定向的地址(Location: http://www.taida.ltd/jeson)。这个时候 Curl 命令中有没有可能一步到位去请求这个地址,就这个时候就可以通过 -L 参数来实现。
这里我加一个 -L 参数(curl -L http://www.taida.ltd)来看下效果。这时我们会看到整个通信过程就变化了,然后有很多 body 的信息打印出来,我们回到打印信息的最上面,去看一下通信过程。
首先,看到的是第一次请求服务端返回一个重定向状态(301 重定向),Curl 则再次发起请求到重定向后的地址,最终能拿到 body 数据和后一次请求的响应码。
接下来,我们继续在控制台深入讲解的 Curl 其他场景,用 Curl 请求如何添加请求头信息。
首先你看到这里是一个下载数据包的链接,因为它是下载包(数据量大)所以我加一个 -I 参数,只看返回的 head 头信息,发起请求后服务端返回的状态码是 404,表示这个包是没有找到。那这里为什么返回一个 404 ?因为这个请求链接我做了一个特殊安全设置,我在 Nginx 里面直接设置了一个返回 404 规则,要求客户端需要携带 Referer 信息过来,然后才能够进行正常访问下载。 我们知道 Referer 是 HTTP 请求头里面一个常见的信息头,它表示请求这个地址来源于哪一个地址。
所以接下来,我在 Curl 请求中添加一个 Referer 头请求,这里加入一个 -e 选项(curl -e “http://www.taida.ltd/” -I http://www.taida.ltd/download/ywgs_lg.tgz
),然后加入一个要求的 refer 链接地址 URL ,这样就匹配到了服务端的规则,从而可以正常访问。。
我们来看一下,这个时候返回的就是一个 200 的状态码了。
Curl 命令使用方式
退出控制台演示,更多的 Curl 命令的使用方式,我们来看一下。
如果是访问 HTTPS 站点,HTTPS 的站点是分为公共证书和自定义证书类型,如果是公共证书,就不需要在本地添加私有密钥了。如果是你自己创建的一个自定义证书,这个时候你就需要把密钥放到客户端,然后通过 Curl 加 -E 的方式去请求 HTTPS 服务端。
另外一些使用,刚刚演示中加入了 Referer 头,你还可以加其他的 HTTP 协议头信息,HTTP 请求头里面是可以被用户自定义或者改写的。这里请求某一个网站的时候,我加了一个–user-agent 头,它表示我请求的浏览器端是用的什么类型的浏览器。
我们看到前面的讲解中这个头信息都是 HTTP 的标准头信息,我可不可以添加一些自定义的请求头信息呢?如果可以又怎么做呢?这个时候我们可以通过 --head 来添加自定义的头部信息,这里演示了添加一个 Content-Type:application/json 就是请求的类型头信息。
另外一部分就是模拟在检测 IPv6 的服务端站点。
我们知道 IPv6 用来解决 IPv4 的 IP 地址不足的问题。当前来看,很多大型的网站已经在强制要求使用 IPv6 并且支持 IPv6 协议,我们也会看到很多的基站或者是自己家的 IP 地址,可以分配到一个 IPv6 的地址。如果你的本地有 IPv6 的地址,而且服务端支持 IPv6 服务,那很有可能你的 DNS 解析就会优先解析 IPv6。这样就满足条件去检测 IPv6 的服务站点,怎么做呢?
我们可以通过这样一种方式来做,如代码所示,这里给你具体解释一下。
curl -6 -vo /dev/null --resolve "static.meituan.net:80:[240e:ff:e02c:1:21::]" "http://static.meituan.net/bs/@mtfe/knb-core/latest/dist/index.js"
curl -6 表示发起的是一个 IPv6 的请求。 -v 表示现实通信过程。-o 表示把请求返回的 body 数据放到本地空设备,也就是 body 数据不展示,只显头部信息,相当于 -I 的作用。–resolve 表示做的是域名和 IP 的解析,我把 static.meituan.net 这个域名的请求地址手动指定解析到 IPv6 地址,然后后面是请求的 URL 了。
这个就是整个 IPv6 的模拟检测的方式,继续演示下,这个时候我们看到整个返回状态和请求过程。
好了,以上就是 Curl 对网站排查的部分内容。
Curl 功能性使用
接下来,我就带你来了解一下,除了使用 Curl 进行网站分析排查场景以外在功能性的一些使用方式。
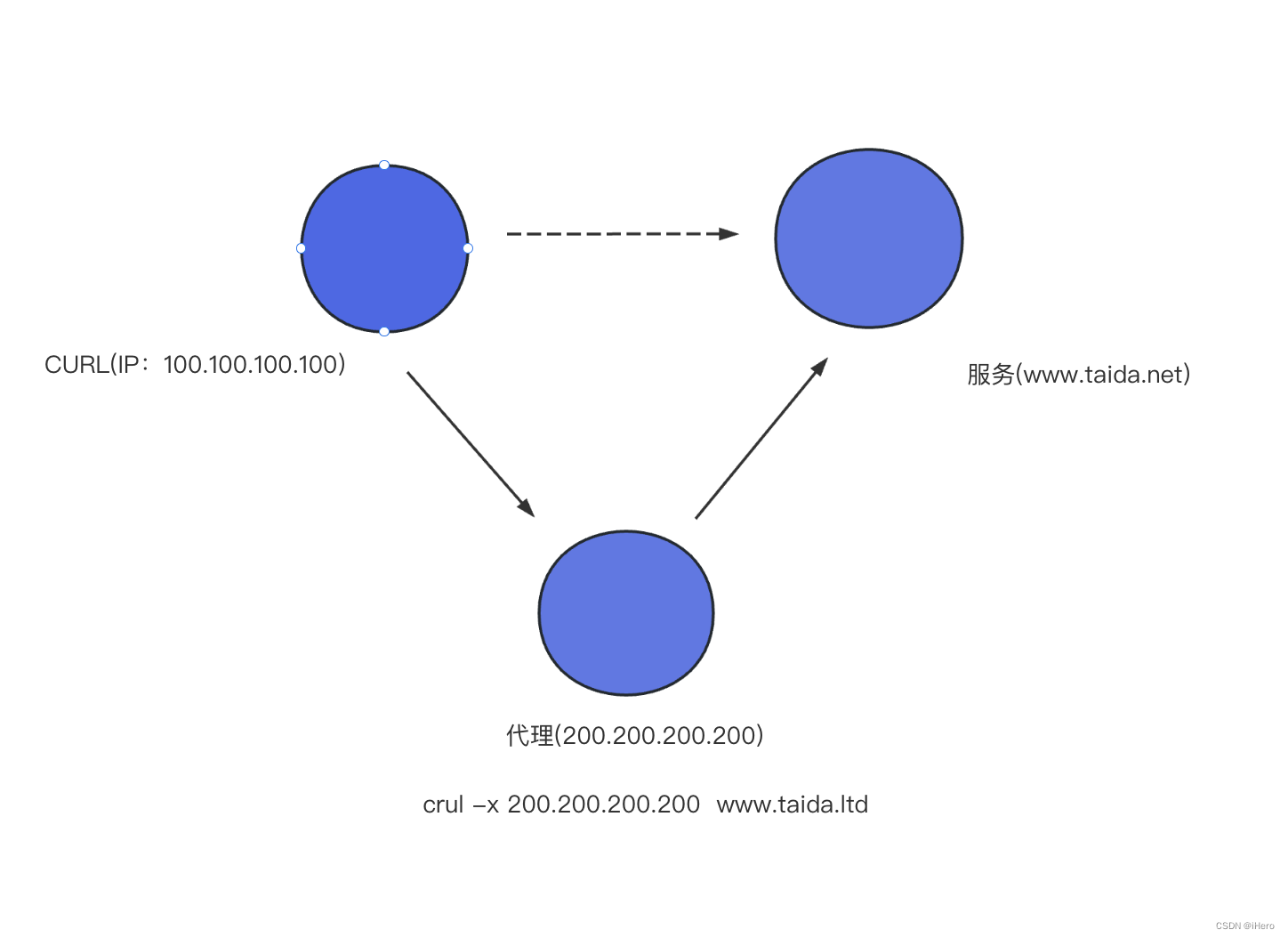
首先第一个方式就是代理模式,我们看到 Curl 命令可以支持借用代理的方式请求。
假设我这里的代理的 IP 是 200.200.200.200,那么只要加入一个 -x,也就是通过 200.200.200.200 这台机器去请求服务端站点,这就是通过代理去访问的一种方式。
另外就是文件的上传和下载,我们可以通过这样的一些格式去做文件的上传。也可以通过 FTP 协议的方式,是直接去下载文件。如果加入一个 -C 就是开启断点续传,关于断点续传可以看一下这个图,客户端跟服务端作一个下载下载的时候会获取到这个包的索引,当出现网络抖动或者波动的时候再去下载,就可以直接在基于这个索引的值继续基于原有断点长度的范围数值继续下载,所以如果为了稳定的下载一个文件,就可以使用断点续传的方式。
Curl 的 HTTP 请求方法
最后一个部分就是介绍 Curl 命令的 HTTP 请求方法。
在前面我们介绍的 Curl 时都是使用 get 方法去获取服务端的内容,除了 get 方法以外,我们还有 HTTP 的请求方法,包括了 post,add,option 等相关方法。但如果我们想指定请求方法,就可以通过 -X 选项中加请求方式来完成。
比如 -X post 表示向服务端 POST 一个请求,arg1 是这个参数的名称,后面是参数的值,然后是第二个参数arg2以及参数的值,这样的话就是以 post 方式去传传递请求的数据信息。另外就是 put 方法,我们同样也可以通过 -X put 的方式去传递。-d 就是我传递的这个数值。如果使用 delete 方式,就是请求服务器并且删除 URL 的标识资源。