2023 年第二届钉钉杯大学生大数据挑战赛 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析

相关链接
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题二Python代码分析
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题三时间序列预测Python代码分析
1 题目
Citi Bike是纽约市在2013年启动的一项自行车共享出行计划,由“花旗银行”(Citi Bank)赞助并取名为“花旗单车”(Citi Bike)。在曼哈顿,布鲁克林,皇后区和泽西市有8,000辆自行车和500个车站。为纽约的居民和游客提供一种 方便快捷,并且省钱的自行车出行方式。人们随处都能借到Citi Bank,并在他们的目的地归还。本案例的数据有两部分:第一部分是纽约市公共自行车的借还交易流水表。Citi Bik自行车与共享单车不同,不能使用手机扫码在任意地点借还车,而需要使用固定的自行车桩借还车,数据集包含2013年7月1日至2016年8 月31日共38个月(1158天)的数据,每个月一个文件。其中2013年7月到2014年8 月的数据格式与其它年月的数据格式有所差别,具体体现在变量starttime和stoptime的存储格式不同。
第二部分是纽约市那段时间的天气数据,并存储在weather_data_NYC.csv文 件中,该文件包含2010年至2016年的小时级别的天气数据。
公共自行车数据字段表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | trip duration | 旅行时长 | 骑行时间,数值型,秒 |
| 2 | start time | 出发时间 | 借车时间,字符串,m/d/YYY HH:MM:SS |
| 3 | stop time | 结束时间 | 还车时间,字符串,m/d/YYY HH:MM:SS |
| 4 | start station id | 借车站点编号 | 定性变量,站点唯一编号 |
| 5 | start station name | 借车站点名称 | 字符串 |
| 6 | start station latitude | 借车站点维度 | 数值型 |
| 7 | start station longtude | 借车站点经度 | 数值型 |
| 8 | end station id | 还车站点编号 | 定性变量,站点唯一编号 |
| 9 | end station name | 还车站点名称 | 字符串 |
| 10 | end station latitude | 还车站点纬度 | 数值型 |
| 11 | end station longitude | 还车站点经度 | 数值型 |
| 12 | bile id | 自行车编号 | 定性变量,自行车唯一编号 |
| 13 | Use type | 用户类型 | Subscriber:年度用户; Customer:24小时或者7天的临时用户 |
| 14 | birth year | 出生年份 | 仅此列存在缺失值 |
| 15 | gender | 性别 | 0:未知 1:男性 2:女性 |
天气数据字段简介表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | date | 日期 | 字符串 |
| 2 | time | 时间 | EDT(Eastern Daylight Timing)指美国东部夏令单位 |
| 3 | temperature | 气温 | 单位:℃ |
| 4 | dew_poit | 露点 | 单位:℃ |
| 5 | humidity | 湿度 | 百分数 |
| 6 | pressure | 海平面气压 | 单位:百帕 |
| 7 | visibility | 能见度 | 单位:千米 |
| 8 | wind_direction | 风向 | 离散型,类别包括west,calm等 |
| 9 | wind_speed | 风速 | 单位:千米每小时 |
| 10 | moment_wind_speed | 瞬间风速 | 单位:千米每小时 |
| 11 | precipitation | 降水量 | 单位:毫米,存在缺失值 |
| 12 | activity | 活动 | 离散型,类别包括snow等 |
| 13 | conditions | 状态 | 离散型,类别包括overcast,light snow等 |
| 14 | WindDirDegrees | 风向角 | 连续型,取值为0~359 |
| 15 | DateUTC | 格林尼治时间 | YYY/m/d HH:MM |
二、解决问题
- 自行车借还情况功能实现:
实现各个站点在一天的自行车借还情况网络图,该网络图是有向图,箭头从借车站点指向还车站点(很多站点之间同时有借还记录,所以大部分站点两两之间是双向连接)。
(一)以2014年8月3日为例进行网络分析,实现自行车借还网络图,计算网络图的节点数,边数,网络密度(表示边的个数占所有可能的连接比例数),给出计算过程和画图结果。
(二)使用上述的网络分析图,对经度位于40.695~40.72,纬度位于- 74.023~-73.973之间的局域网区域进行分析,计算出平均最短路径长度(所有点 两两之间的最短路径长度进行算数平均)和网络直径(被定义网络中最短路径的 最大值)。
- 聚类分析
对于2013年7月1日至2015年8月31日数据集的自行车数据进行聚类分析,选 择合适的聚类数量K值,至少选择两种聚类算法进行聚类,并且比较不同的聚类 方法以及分析聚类结果。
- 站点借车量的预测分析:
对所有站点公共自行车的借车量预测,预测出未来的单日借车量。将2013年 7月-2015年7月数据作为训练集,2015年8月1-31日的数据作为测试集,预测2015 年8月1-31日每天的自行车单日借车量。给出每个站点预测结果的MAPE,并且给 出模型的参数数量,最后算出所有站点的MAPE的均值(注:测试集不能参与到训 练和验证中,否则作违规处理)。
M
A
P
E
=
1
n
∑
∣
y
i
−
y
i
^
y
i
∣
×
100
%
MAPE = \frac{1}{n} \sum{|\frac{y_i-\hat{y_i}}{y_i}|} \times 100\%
MAPE=n1∑∣yiyi−yi^∣×100%
data.csv是纽约市公共自行车的借还交易流水信息,格式如下表,请使用python对数据预处理和特征工程后,聚类分析:
公共自行车数据字段表
| 变量编号 | 变量名 | 变量含义 | 变量取值及说明 |
|---|---|---|---|
| 1 | trip duration | 旅行时长 | 骑行时间,数值型,秒 |
| 2 | start time | 出发时间 | 借车时间,字符串,m/d/YYY HH:MM:SS |
| 3 | stop time | 结束时间 | 还车时间,字符串,m/d/YYY HH:MM:SS |
| 4 | start station id | 借车站点编号 | 定性变量,站点唯一编号 |
| 5 | start station name | 借车站点名称 | 字符串 |
| 6 | start station latitude | 借车站点维度 | 数值型 |
| 7 | start station longtude | 借车站点经度 | 数值型 |
| 8 | end station id | 还车站点编号 | 定性变量,站点唯一编号 |
| 9 | end station name | 还车站点名称 | 字符串 |
| 10 | end station latitude | 还车站点纬度 | 数值型 |
| 11 | end station longitude | 还车站点经度 | 数值型 |
| 12 | bile id | 自行车编号 | 定性变量,自行车唯一编号 |
| 13 | Use type | 用户类型 | Subscriber:年度用户; Customer:24小时或者7天的临时用户 |
| 14 | birth year | 出生年份 | 仅此列存在缺失值 |
| 15 | gender | 性别 | 0:未知 1:男性 2:女性 |
2 问题分析
2.1 问题一
- 绘制有向图
a. 读入数据并分别提取“起始站点编号”和“结束站点编号”两列数据,构建自行车借还网络图。
b. 对于第一步构建的网络图,我们需要计算网络图的节点数,边数,网络密度。节点数即为站点数,边数为借还次数。网络密度为边的数量占所有可能的连接比例。
c. 画出自行车借还网络图。
e. 计算平均最短路径长度和网络直径
首先选出符合条件(经度位于40.695~40.72,纬度位于- 74.023~-73.973之间)的借车站点和还车站点,并以它们为节点构建一个子图进行分析。然后可以直接使用networkx库中的函数来计算平均最短路径长度和网络直径。
2.2 问题二
-
数据预处理:对进行数据清洗和特征提取。可以使用PCA、LDA算法进行降维,减小计算复杂度。
-
聚类算法:
a. K-means: 进行数据聚类时,选择不同的K值进行多次试验,选取最优的聚类结果。可以使用轮廓系数、Calinski-Harabaz指数等评价指标进行比较和选择。
b. DBSCAN: 利用密度对数据点进行聚类,不需要预先指定聚类的数量。使用基于密度的聚类算法时,可以通过调整半径参数和密度参数来得到不同聚类效果。
c. 层次聚类:可分为自顶向下和自底向上两种方式。通过迭代计算每个数据点之间的相似度,将数据点逐渐合并,最后得到聚类结果。d.改进的聚类算法
e. 深度聚类算法
-
聚类结果分析:选择最优的聚类结果后,对不同类别骑车的用户进行画像。分析每个类别的用户行为特征。
2.3 问题三
- 导入数据并进行数据预处理,整合以站点为单位的借车数据。
- 对数据进行时间序列分析,使用ARIMA模型进行单日借车量预测。
- 使用时间序列交叉验证方法进行模型评估,计算每个站点预测结果的MAPE。
- 计算所有站点的MAPE的均值,给出模型的参数数量。
3 Python代码实现
3.1 问题一
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题一Python代码分析
3.2 问题二
【2023 年第二届钉钉杯大学生大数据挑战赛】 初赛 B:美国纽约公共自行车使用量预测分析 问题二Python代码分析
3.3 问题三
(1)合并天气数据
import pandas as pd
import os
# 加载数据
# 合并数据
folder_path = '初赛数据集/问题3数据集'
dfs = []
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
csv_path = os.path.join(folder_path, filename)
tempdf = pd.read_csv(csv_path)[0:5000]
dfs.append(tempdf)
bike_data = pd.concat(dfs,axis=0)
weather_data = pd.read_csv('初赛数据集/weather_data_NYC(3).csv')
# 查看数据格式及之间的关联
print(bike_data.head())
print(weather_data.head())
# 将“start time”列和“stop time”列转换为datetime格式
bike_data['starttime'] = pd.to_datetime(bike_data['starttime'])
bike_data['stoptime'] = pd.to_datetime(bike_data['stoptime'])
weather_data['date'] = pd.to_datetime(weather_data['date'])
# 在每张表格中加入一个“day”列,代表日期
bike_data['day'] = bike_data['starttime'].dt.date
weather_data['day'] = weather_data['date'].dt.date
print(bike_data.head())
print(weather_data.head())
(2)特征工程
从两个数据集提取用于建模的特征。
-
对于公共自行车的使用情况,考虑借车站、还车站、借车时间等。
-
对于天气条件,还可以考虑温度、湿度、风速等因素。
# 对于公共自行车的使用情况,提取用于建模的特征
bike_data_features = bike_data[['start station id', 'end station id', 'starttime', 'day']]
...略
# 对天气条件进行处理,提取用于建模的特征
weather_data_features = weather_data[['date', 'temperature', 'humidity', 'wind_speed']]
...略
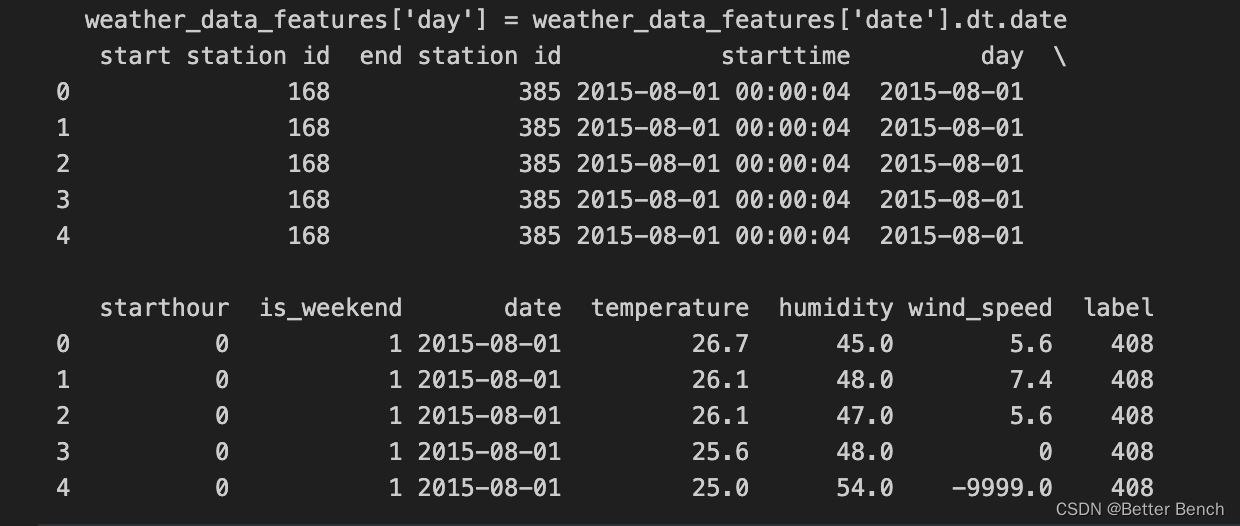
# 接下来,需要将两个数据集进行合并,以创建一个数据集来训练模型。我们可以通过将bike_data_features和weather_data_features根据日期(day)合并来实现:
model_data = pd.merge(bike_data_features, weather_data_features, on='day', how='left')
# 类别特征编码
...略
# 测试集:打标签,计算每天的借车数量
BorrowCounts = model_data.groupby(['day', 'start station id']).size().reset_index()
BorrowCounts = BorrowCounts.rename(columns={0: 'count'})
model_data = pd.merge(model_data, BorrowCounts, on=['day', 'start station id'], how='left')
...略
print(model_data.head())
(3)模型训练
回归预测问题,可以采用回归模型,比如XGB、LGB、线性回归、神经网络回归等模型,常用的时间序列预测模型ARIMA模型、GARCH模型、LSTM等。以下是XGB为例。
# 将数据集拆分为训练集和测试集,建立模型并对它进行训练:
import xgboost as xgb
from sklearn.metrics import mean_absolute_percentage_error, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 拆分数据集
train_data = model_data[model_data['day'] < pd.to_datetime('2015-08-01').date()]
test_data = model_data[model_data['day'] >= pd.to_datetime('2015-08-01').date()]
# 定义输入特征以及输出
data_train = train_data[['start station id', 'end station id', 'starthour', 'is_weekend', 'temperature', 'humidity', 'wind_speed']]
Y_train = train_data['label']
# 测试集:打标签,计算每天的借车数量
data_test = test_data[['start station id', 'end station id', 'starthour', 'is_weekend', 'temperature', 'humidity', 'wind_speed']]
Y_test = test_data['label']
X_train = scaler.fit_transform(data_train)
X_test = scaler.transform(data_test)
# # 定义模型并训练
# XGBoost回归模型,还可以使用线性回归、决策树回归、神经网络回归
model = xgb.XGBRegressor(
objective='reg:squarederror',
n_jobs=-1,
n_estimators=1000,
max_depth=7,
subsample=0.8,
learning_rate=0.05,
gamma=0,
colsample_bytree=0.9,
random_state=2023, max_features=None, alpha=0.3)
model.fit(X_train, Y_train)

(4) 模型评价与检验
# 计算每个站点的MAPE:
# 对测试集进行预测
Y_pred = model.predict(X_test)
def calculate_mape(row):
return mean_absolute_percentage_error([row['pred']],[row['true']])
# 计算每个站点的MAPE
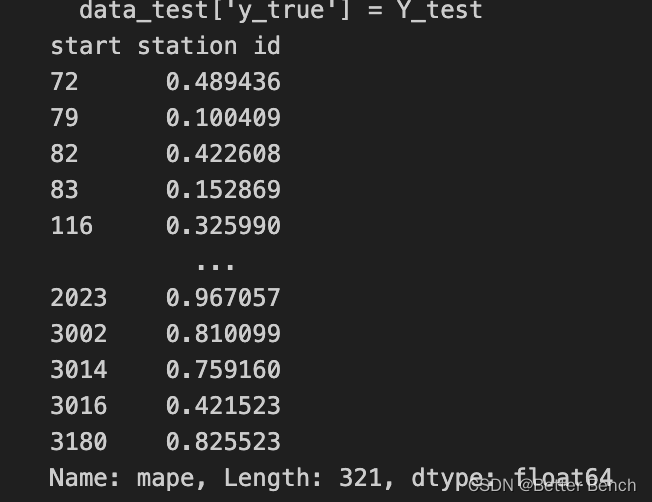
data_test['pred'] = Y_pred
data_test['y_true'] = Y_test
data_test['mape'] = data_test.apply(calculate_mape, axis=1)
mape_by_station = data_test.groupby('start station id')['mape'].mean()
print(mape_by_station)
# 计算所有站点的MAPE的均值
mape_mean = mean_absolute_percentage_error(Y_test,Y_pred)
print(mape_mean)
0.47444156668192194
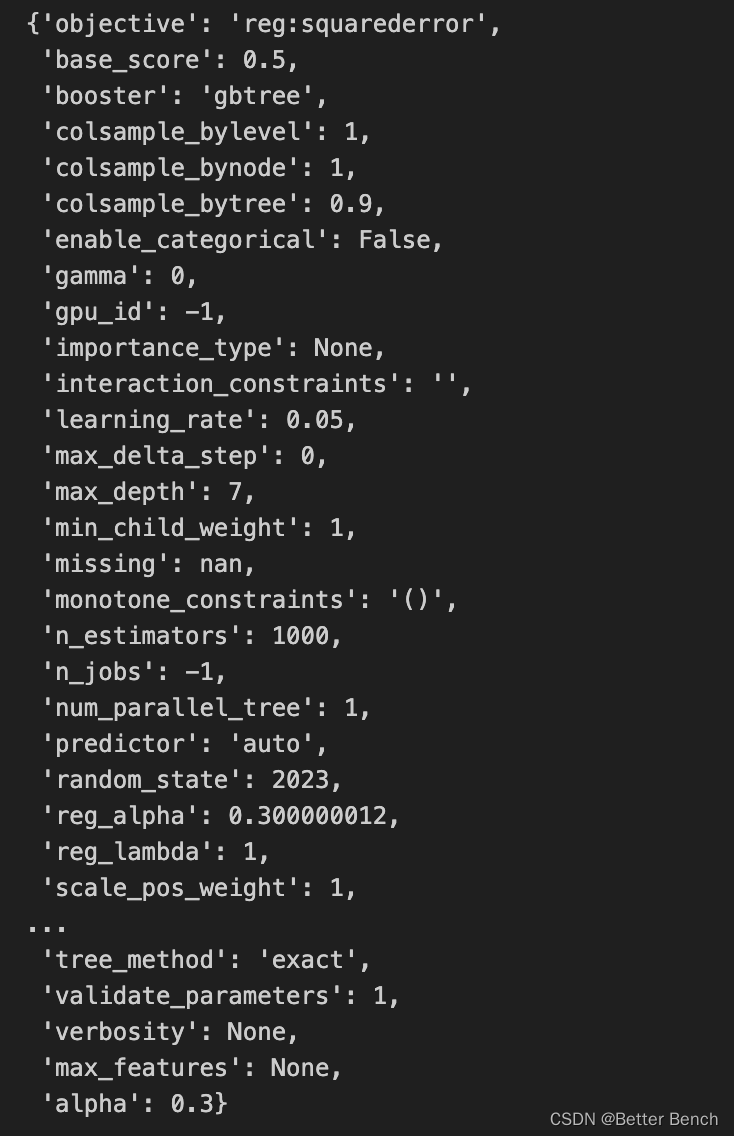
# 计算XGB模型的参数数量:
model.get_params()
完整代码
见知乎文章底部链接,下载包括所有问题的全部代码
zhuanlan.zhihu.com/p/643865954