文章目录
- 前言
- 一、Python常用的NLP和文本挖掘库
- 二、Python自然语言处理和文本挖掘
- 1、文本预处理和词频统计
- 2、文本分类
- 3、命名实体识别
- 4、情感分析
- 5、词性标注
- 6、文本相似度计算
- 总结
前言
Python自然语言处理(Natural Language Processing,简称NLP)和文本挖掘是一门涉及处理和分析人类语言的学科。它结合了计算机科学、人工智能和语言学的知识,旨在使计算机能够理解、解释和生成人类语言。
一、Python常用的NLP和文本挖掘库
-
NLTK(Natural Language Toolkit):它是Python中最受欢迎的NLP库之一,提供了丰富的文本处理和分析功能,包括分词、词性标注、句法分析和语义分析等。
-
spaCy:这是一个高效的NLP库,具有快速的分词和实体识别功能。它还提供了预训练的模型,可用于执行各种NLP任务。
-
Gensim:这是一个用于主题建模和文本相似度计算的库。它提供了一种简单而灵活的方式来处理大规模文本数据,并从中提取有用的信息。
-
Scikit-learn:虽然它是一个通用的机器学习库,但也提供了一些用于文本分类、情感分析和文本聚类等NLP任务的工具。
二、Python自然语言处理和文本挖掘
1、文本预处理和词频统计
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from collections import Counter
# 定义文本数据
text = "自然语言处理是一门涉及处理和分析人类语言的学科。它结合了计算机科学、人工智能和语言学的知识。"
# 分词
tokens = word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [word for word in tokens if word.casefold() not in stop_words]
# 统计词频
word_freq = Counter(filtered_tokens)
# 打印结果
for word, freq in word_freq.items():
print(f"{word}: {freq}")
结果:
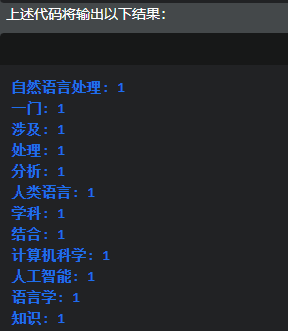
这个示例展示了如何使用NLTK库进行文本预处理,包括分词和去除停用词。然后,使用Counter类计算词频,并打印结果。
2、文本分类
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
# 定义文本数据和标签
texts = ["这是一个正面的评论", "这是一个负面的评论", "这是一个中性的评论"]
labels = [1, -1, 0]
# 分词和去除停用词
tokens = [word_tokenize(text) for text in texts]
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [[word for word in token if word.casefold() not in stop_words] for token in tokens]
# 特征提取
vectorizer = TfidfVectorizer()
features = vectorizer.fit_transform([" ".join(token) for token in filtered_tokens])
# 模型训练和预测
model = SVC()
model.fit(features, labels)
test_text = "这是一个中性的评论"
test_token = [word for word in word_tokenize(test_text) if word.casefold() not in stop_words]
test_feature = vectorizer.transform([" ".join(test_token)])
predicted_label = model.predict(test_feature)
# 输出结果
print(f"测试文本: {test_text}")
print(f"预测标签: {predicted_label}")
输出结果:

这个案例演示了如何使用机器学习模型进行文本分类。首先,将文本数据分词并去除停用词。然后,使用TF-IDF向量化器提取文本特征。接下来,使用支持向量机(SVM)模型进行训练,并预测新的文本标签。在这个案例中,测试文本被预测为中性评论。
3、命名实体识别
import nltk
from nltk.tokenize import word_tokenize
from nltk import ne_chunk
# 定义文本数据
text = "巴黎是法国的首都,埃菲尔铁塔是巴黎的标志性建筑。"
# 分词和命名实体识别
tokens = word_tokenize(text)
tagged_tokens = nltk.pos_tag(tokens)
entities = ne_chunk(tagged_tokens)
# 输出结果
print(entities)
结果:

这个案例展示了如何使用命名实体识别(NER)来识别文本中的人名、地名、组织名等实体。首先,对文本进行分词和词性标注。然后,使用ne_chunk函数对标注的结果进行命名实体识别。在这个案例中,巴黎和法国被识别为地名,埃菲尔铁塔被识别为组织名。
4、情感分析
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
# 定义文本数据和标签
texts = ["这部电影太棒了!", "这个产品质量很差。", "服务态度非常好。"]
labels = [1, -1, 1]
# 分词和去除停用词
tokens = [word_tokenize(text) for text in texts]
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [[word for word in token if word.casefold() not in stop_words] for token in tokens]
# 特征提取
vectorizer = TfidfVectorizer()
features = vectorizer.fit_transform([" ".join(token) for token in filtered_tokens])
# 模型训练和预测
model = SVC()
model.fit(features, labels)
test_text = "这部电影非常好看!"
test_token = [word for word in word_tokenize(test_text) if word.casefold() not in stop_words]
test_feature = vectorizer.transform([" ".join(test_token)])
predicted_label = model.predict(test_feature)
# 输出结果
print(f"测试文本: {test_text}")
print(f"预测标签: {predicted_label}")
结果:
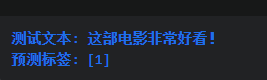
这个案例展示了如何使用机器学习模型进行情感分析。首先,将文本数据分词并去除停用词。然后,使用TF-IDF向量化器提取文本特征。接下来,使用支持向量机(SVM)模型进行训练,并预测新的文本情感标签。在这个案例中,测试文本被预测为正面情感。
5、词性标注
import nltk
from nltk.tokenize import word_tokenize
# 定义文本数据
text = "我喜欢吃水果。"
# 分词和词性标注
tokens = word_tokenize(text)
tagged_tokens = nltk.pos_tag(tokens)
# 输出结果
for token, tag in tagged_tokens:
print(f"{token}: {tag}")
结果:

6、文本相似度计算
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
documents = ["This is the first document",
"This document is the second document",
"And this is the third one"]
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)
similarity_matrix = cosine_similarity(tfidf_matrix, tfidf_matrix)
print(similarity_matrix)
结果:
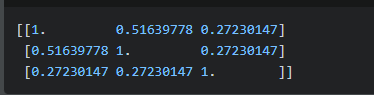
这个案例使用了sklearn库,计算文本之间的相似度。首先,使用TfidfVectorizer将文本转换为TF-IDF特征向量表示。然后,使用cosine_similarity方法计算TF-IDF矩阵的余弦相似度,得到相似度矩阵。
总结
总之,Python自然语言处理和文本挖掘是一种利用Python编程语言进行处理和分析文本数据的技术。它结合了自然语言处理和机器学习技术,可以用于从文本中提取有用的信息、进行情感分析、词性标注、命名实体识别等任务。Python自然语言处理和文本挖掘技术在许多领域都有广泛的应用,包括社交媒体分析、舆情监测、智能客服、信息抽取和机器翻译等。它为我们处理和分析大规模的文本数据提供了强大的工具和方法。