MySql执行流程
MySQL作为当下最流行的开源关系型数据库,有一个很关键和基本的能力,就是必须能够保证数据不会丢。那么在这个能力背后,MySQL是如何设计才能保证不管在什么时间崩溃,恢复后都能保证数据不会丢呢?有哪些关键技术支撑了这个能力;
MySQL 保证数据不会丢的能力主要体现在两方面:
- 能够恢复到任何时间点的状态;
- 能够保证MySQL在任何时间段突然奔溃,重启后之前提交的记录都不会丢失;
对于第一点将MySQL恢复到任何时间点的状态,相信很多人都知道,只要保留有足够的binlog,就能通过重跑binlog来实现。
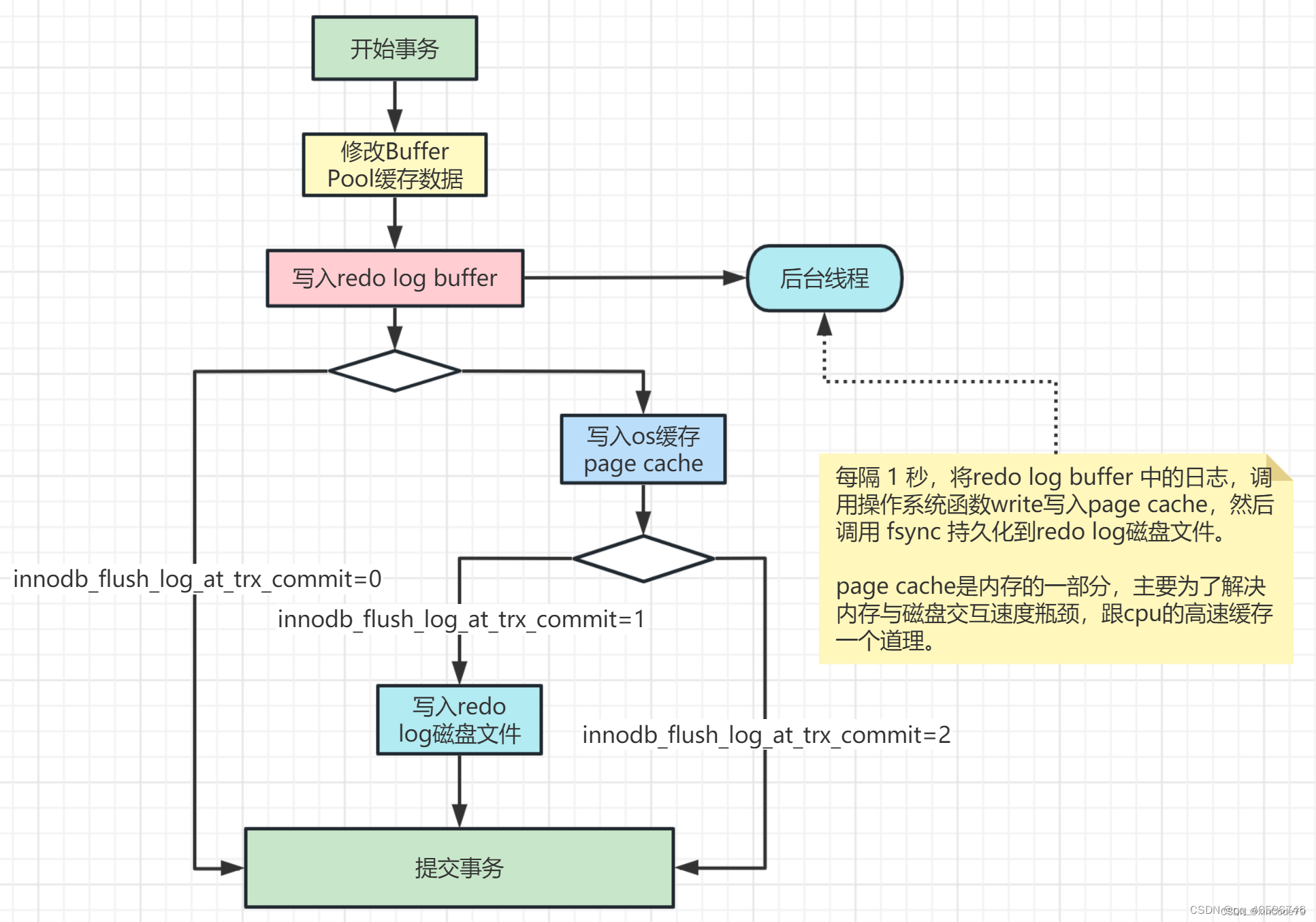
对于第二点的能力,也就是本文标题所讲的crash-safe。即在 InnoDB 存储引擎中,事务提交过程中任何阶段,MySQL突然奔溃,重启后都能保证事务的完整性,已提交的数据不会丢失,未提交完整的数据会自动进行回滚。这个能力依赖的就是redo log和unod log两个日志。
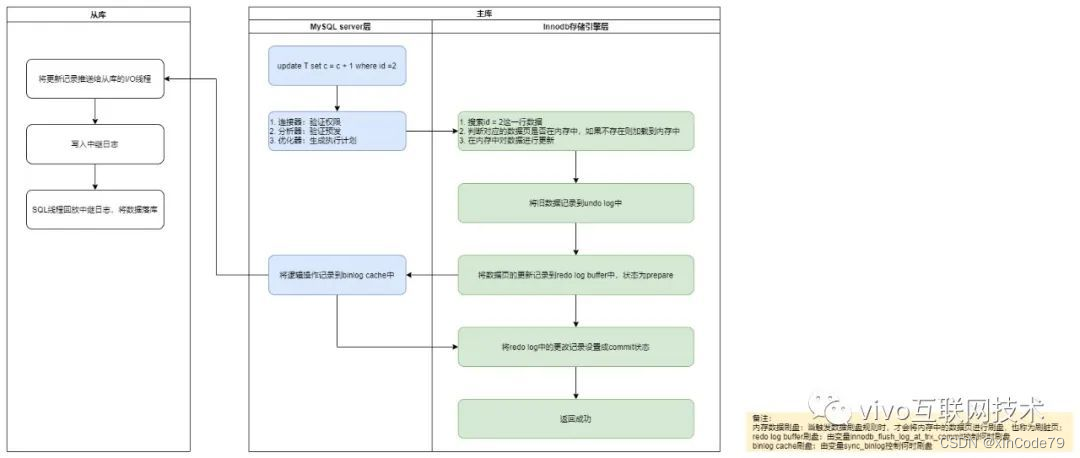
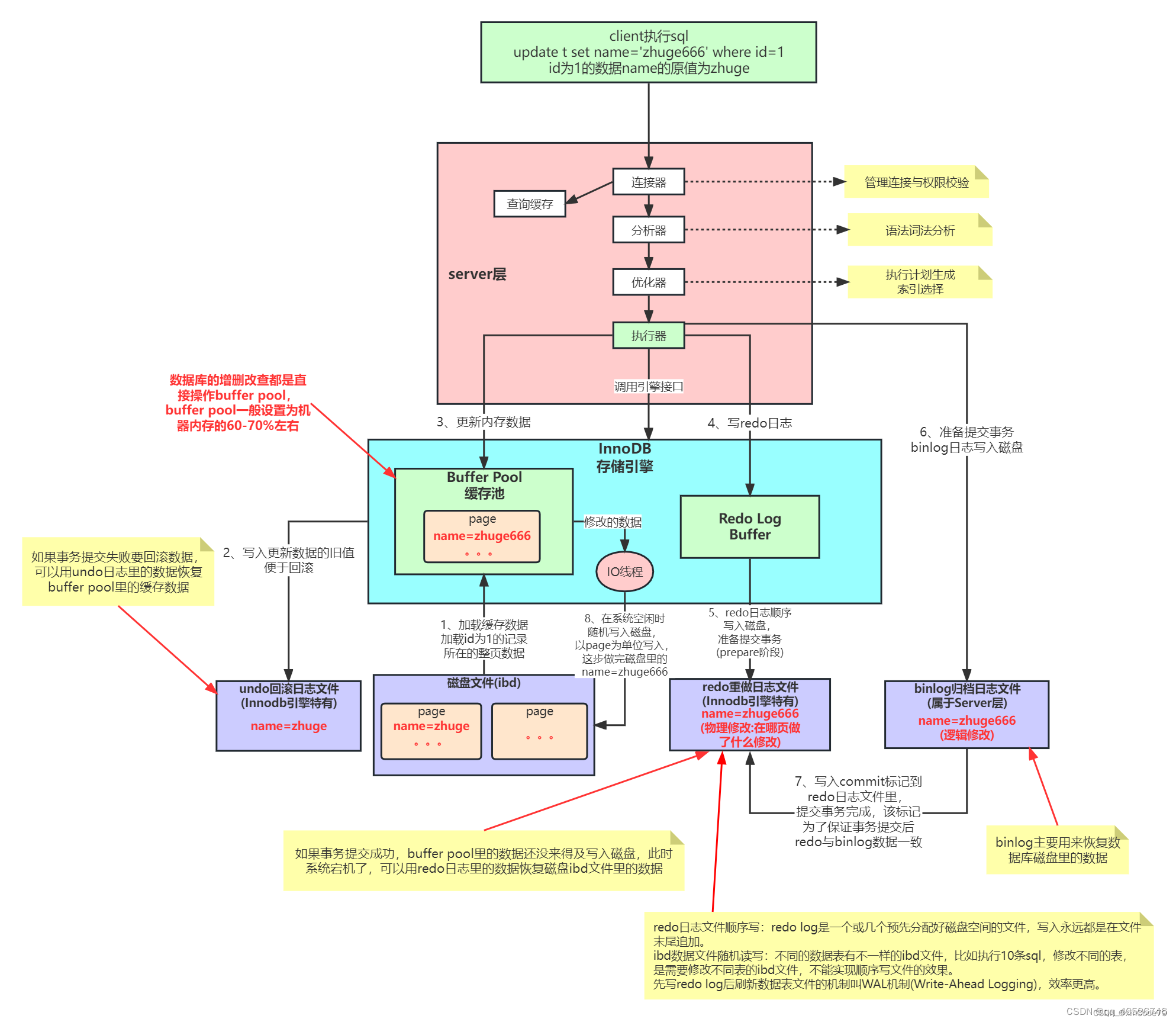
因为crash-safe主要体现在事务执行过程中突然奔溃,重启后能保证事务完整性,所以在讲解具体原理之前,先了解下MySQL事务执行有哪些关键阶段,后面才能依据这几个阶段来进行解析。下面以一条更新语句的执行流程为例,话不多说,直接上图:
从上图可以清晰地看出一条更新语句在MySQL中是怎么执行的,简单进行总结一下:
- 从内存中找出这条数据记录,对其进行更新;
- 将对数据页的更改记录到redo log中;
- 将逻辑操作记录到binlog中;
- 对于内存中的数据和日志,都是由后台线程,当触发到落盘规则后再异步进行刷盘;
上面演示了一条更新语句的详细执行过程,接下来咱们通过解答问题,带着问题来剖析这个crash-safe的设计原理。
- 问题:为什么不直接更改磁盘中的数据,而要在内存中更改,然后还需要写日志,最后再落盘这么复杂?
这个问题相信很多同学都能猜出来,MySQL更改数据的时候,之所以不直接写磁盘文件中的数据,最主要就是性能问题。因为直接写磁盘文件是随机写,开销大性能低,没办法满足MySQL的性能要求。所以才会设计成先在内存中对数据进行更改,再异步落盘。但是内存总是不可靠,万一断电重启,还没来得及落盘的内存数据就会丢失,所以还需要加上写日志这个步骤,万一断电重启,还能通过日志中的记录进行恢复。
二、WAL技术
写日志虽然也是写磁盘,但是它是顺序写,相比随机写开销更小,能提升语句执行的性能(针对顺序写为什么比随机写更快,可以比喻为你有一个本子,按照顺序一页一页写肯定比写一个字都要找到对应页写快得多)。
这个技术就是大多数存储系统基本都会用的WAL(Write Ahead Log)技术,也称为日志先行的技术,指的是对数据文件进行修改前,必须将修改先记录日志。保证了数据一致性和持久性,并且提升语句执行性能。
核心日志
● 问题:更新SQL语句执行流程中,总共需要写3个日志,这3个是不是都需要,能不能进行简化?
更新SQL执行过程中,总共涉及MySQL日志模块其中的三个核心日志,分别是redo log(重做日志)、undo log(回滚日志)、binlog(归档日志)。这里提前预告,crash-safe的能力主要依赖的就是这三大日志。
接下来,针对每个日志将单独介绍各自的作用,然后再来评估是否能简化掉。
三、核心日志模块
四、两阶段提交
五、组提交
六、数据恢复流程
七、总结