文章目录
- 发展历史
- 卷积神经网络的应用领域
- 卷积的原理和作用
- 卷积和传统的神经网络的区别
- 卷积网络的整体架构
- 输入层
- 卷积层
- 池化层
- 全连接层
- 卷积和池化叠加多层
- 卷积可以处理什么类型的数据
- 卷积的超参数
- 卷积最大的优势
- 卷积的细节
- 卷积的原理
- 卷积的参数
- 卷积的次数
- 步长 卷积核尺寸 边缘填充 卷积核个数
- 卷积的特征尺寸计算
- 卷积参数共享
- 最大池化
- 卷积的层数
- 感受野
本文介绍深度学习中极为重要的一个神经网络CNN,卷积神经网络
发展历史
最早 98年 yann LeCun 在论文中提出了一个LeNet-5模型,当初美国的很多银行都用它来识别支票上面的手写数字。
09年 李飞飞 号召进行全美的图像识别,并举行了IMAGE NET比赛,这个比赛一直持续了很多年
目前这个网站依然存在,分类达到了21841类

- 2012年
冠军,Hinton和他的学生alex 准确率57% top1-5达到80.2%
- 2014年
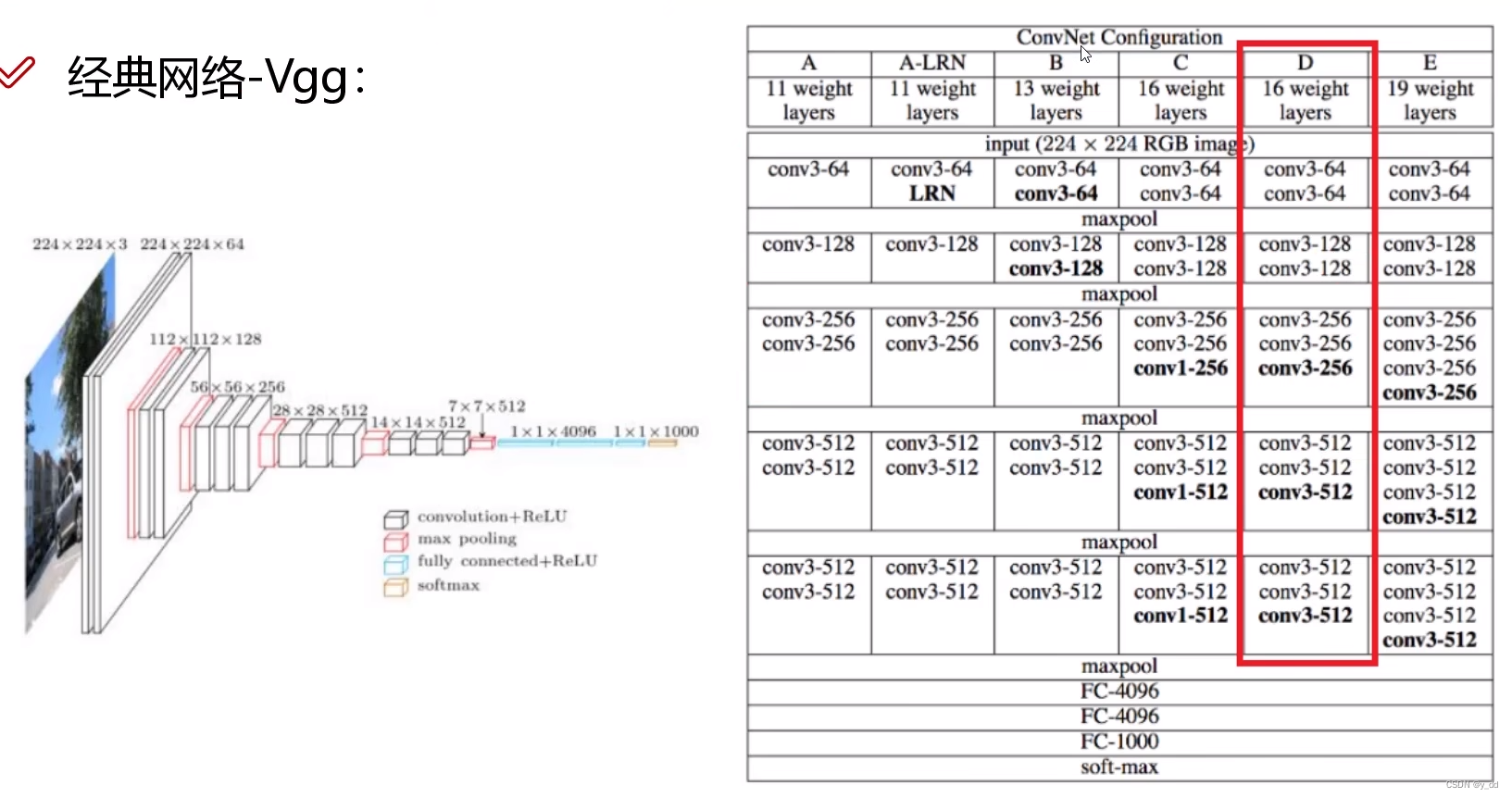
冠亚军 模型分别是googlenet和vgg
googlenet google提出
VGG牛津大学提出,但它在迁移学习任务中表现要比googlenet更优,而且从图像中提取CNN特征,VGG模型是首选,缺点就是参数需要140M,需要更大的存储空间
- 2015年
ResNet 采用了152层,采用残差学习的方法进行训练,简单并且实用,并且衍生了ResNet50等一系列模型
后来Alpha zero,训练8小时可以打败alpha go,作者是毕业于清华的何凯明
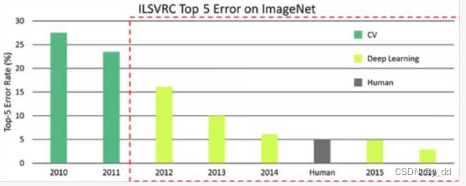
下面可以看到,15年 深度学习在图像识别方面超越人类了,IMAGENET 比赛也从此停办了
卷积神经网络的应用领域
检测任务
分类与检索(比如找相似的产品)
超分辨率重构

医学任务
字体识别
无人驾驶

人脸识别

卷积的原理和作用
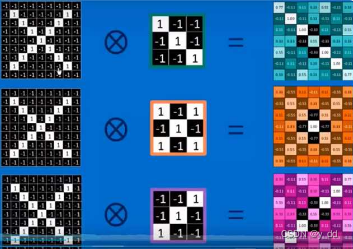
提取特征时,使用具备原图特征的卷积核提取的图,就具备同样的特征
卷积和传统的神经网络的区别
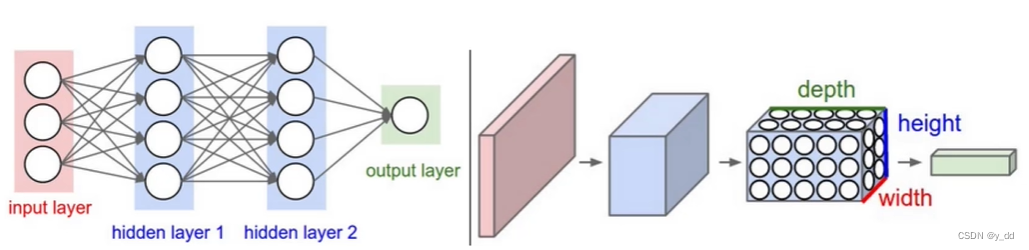
先从直观上看区别:
左图:传统的神经网络的输入是一维的,被拉伸的数据
右图:卷积神经网络则是输入一个立体的图像,不需要拉伸
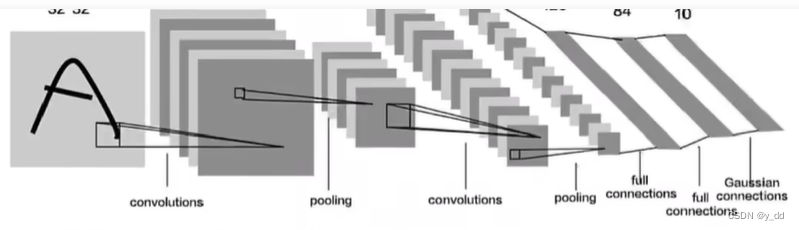
卷积网络的整体架构
输入层
比如输入的图片,常用的(h,w,c)三位的数据
卷积层
作用:提取特征参数
比如一个图片, 每块对应的特征都是不同的,于是划分成一个小区域去提取特征,跟传统的网络一样,就需要一组权重参数去提取这一块小区域数据的特征。
池化层
作用:降低计算量,保留的特征的同时,降低尺寸

分为最大和平均池化,一般来说最大池化表现的最好,究竟什么是池化后面会有详细描述
全连接层
最终的输出一般都是一维的数据,需要全连接层,比如分类任务,最终是要输出10分类的概率,一个多维的图片最终要输出一个一维的数据,所以需要全连接层
卷积和池化叠加多层
通常的卷积结构是卷积、池化、激活函数,堆叠的多少是随意的,一般情况下叠加的层数越多,特征曲线就能表达的越丰富,但实验证明,并不是越多越好。
卷积可以处理什么类型的数据
可以处理多维的,但是特征要呈现图像类似的特征,什么意思呢?比如一张图片像素点如果随意换位置,那这个图片与原图肯定不是同一张图片了,所以文本、语音类都可以处理,但是呢,对于前后无关,信息前后又无关联(举个例子来说,一个人员信息,人员 姓名 地址这三个特征,换一下位置,这个信息是不变的,这种就是前后无关的)的不适用
卷积的超参数
hyperparameter 是指卷积网络初始,参数包括:
- 卷积中特征数 特征尺寸
- 池化中的window size、stride
- 全连接层:neuron个数
卷积最大的优势
提取特征 分类图片等特别有用
卷积的细节
卷积的原理
已突破为例,卷积操作是将输入图片中每个通道与卷积核每个通道内积后的矩阵和,这个矩阵和就是feature map
所以这就要去卷积核的通道数必须与图片的通道数相同
先用一维数据展示一下,下面是一个卷积核的一个通道的数据
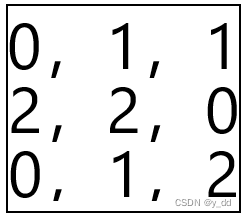
也就是下图中小点表示的数字,蓝色框大点的为输入,最终的输出是右边的绿色部分
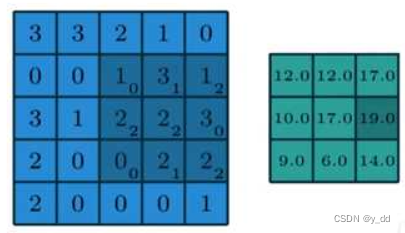
执行的操作,移动卷积核,每移动一次卷积核与被覆盖的输入部分进行内积操作,比如此时的计算就是:
(10+3! + 12 + 22+ 22 + 30 + 00 + 21 + 2*2 = 19),对应右图输出中的加深的19,当然每次卷积移动的步长是可以选择的,这是移动的步长是1
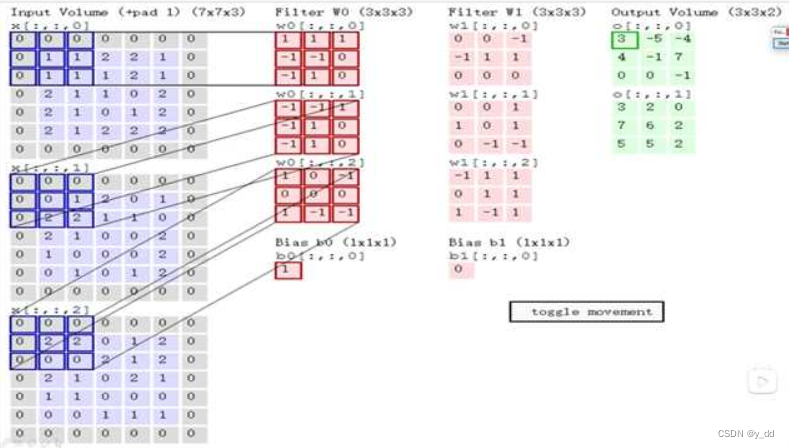
所以当输入的图像是3通道立体的图象时,卷积核也是3维的,最终输出的特征图将三个通道分别卷积后的和。下图最终输出是第4列的2图,那第二个图是什么情况呢? 因为我们可以输入两组卷积(一般也称做filter),所以可以输出一个2个特征图
卷积的参数
卷积的次数
卷积一次够么?
通常模型都 需要执行多次卷积
步长 卷积核尺寸 边缘填充 卷积核个数
卷积的动态展示

- 步长
步长小的时候,提取的特征比较丰富,步长过大会导致提取到的特征很少,特征丰富的话计算量就会很大。
卷积核的尺寸也是同样如此
所以一般模型的步长和卷积核尺寸都不会太大
- 边缘填充
观察卷积的操作发现,卷积操作时,边界的点具备劣势,它被利用的次数少,这对于提取的特征来说是不公平的,导致特征确实,为解决这个问题就有边缘填充这个操作。
边缘填充后,可以提高边界点的利用率,填充的值,一般是zero padding ,这样不影响内积值,另有其他用途的除外
- 卷积核的个数
决定可以得到的特征图的个数
卷积的特征尺寸计算
计算卷积后H W

padding*2 是因为填充的时候,肯定上下或者左右对称填充的
dilation表示空洞,当没有空洞,stride是一维的时候,可以用这个

卷积参数共享
卷积参数共享是卷积中重要的概念,也是卷积比全连接层的优势所在,它可以让卷积操作的参数数据量大大缩减的情况下
参数共享是指:卷积是对一张图像的位置,都是使用相同的卷积核,得出一个feature map
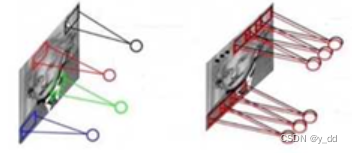
比如32323的图片,继续用10个553的卷积核进行卷积,与使用全连接的模型的权重参数的量差距极大:
一个卷积核 553 总共个10个filter,那么权重参数是750个
而全连接层 需要3232100 78400个
最大池化
最大提取特征的意义是:相当于只挑选最重要的参数
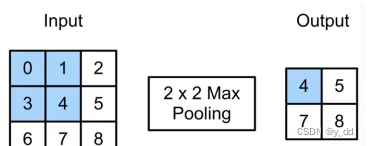
最大池化的操作:跟卷积有点类似,只不过没有权重参数需要更新,是从池化核框住的部分选择最大值,平均池化就是取平均值
一般都是选择最大池化 优于平均池化
池化层的作用,除了可以降低数据量,也可以防止过拟合
卷积的层数
卷积的层数是不是越多越好?
注意一般说的层不包括激活函数和池化层,因为这些层不带参数,不需要更新,不算层数
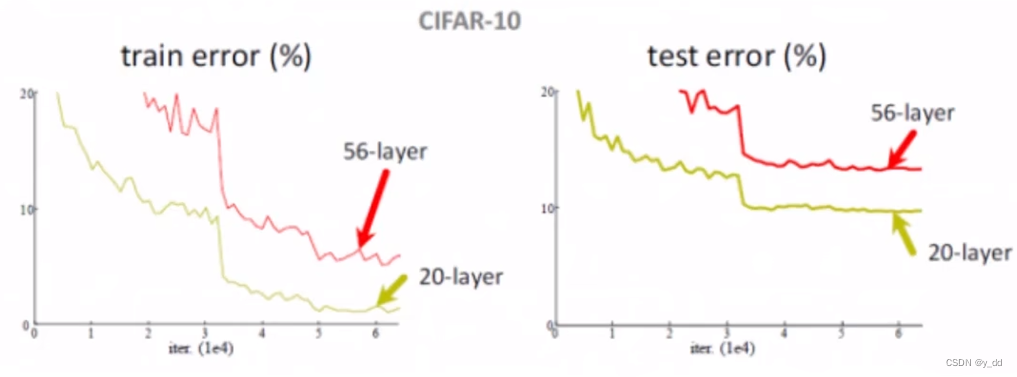
普通的卷积RELU和池化后,深度20层甚至比50层的效果要好
这就带来一个问题,特征在经过卷积之后的提取特征还是好的特征么? 在经过多次提取以后,前面层的特征就不一定能够保持住了
这个问题的在ResNet 也已经解决了,增加一些同等映射

感受野
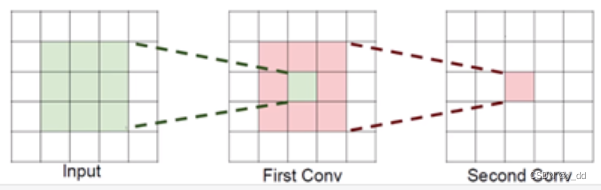
卷积中最长用的多组3*3的卷积核,这是为什么呢? 这里牵扯一个感受野的概念
- 使用3个(3,3)的卷积,保持步长1,经过两次卷积后感受野就是7*7(inut输入特征的大小)
- 使用一次(7,7)的卷积核的效果,同样可以提取7*7的特征
感受野是一样的,为什么使用更多更小的卷积核来做卷积呢?
举个例子:输入是h w c ,得到 c个特征图
假设用(7*7),那么需要的参数就是c * 7 * 7 * c 个权重参数
如果使用上述1方案,则使用3 *c *3 * 3 * c 使用的参数更少
所以卷积中,通常是堆叠小的卷积核,这样需要的参数更少,并且卷积越多,可以加入的非线性也越多,特征提取的就越细致,这也是VGG网络的基本出发点,用小的卷积核提取特征





![[MySQL]MySQL视图特性](https://img-blog.csdnimg.cn/img_convert/17636659840f4d197e8c2e90414aee99.png)