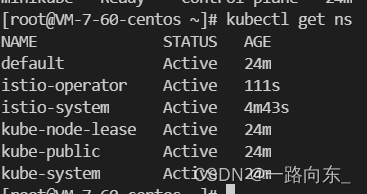
参考:图解Self-Attention_子燕若水的博客-CSDN博客
举个例子:
假设输入数据形状为(243,34),表示的是243帧,每帧包含34个特征(比如17个关键点的x,y坐标)。那么这个数据在Transformer Encoder中的流动过程如下:
- 输入数据shape是(243, 34),表示243个时间步(帧),每个时间步是一个34维的向量(一帧的编码向量)。
- 首先加入位置编码,为每个时间步增加位置信息。位置编码的shape仍然是(243, 34)。
- 然后进入Multi-Head Attention (MHA)层。MHA会计算每个时间步与所有时间步的关联性。输出shape保持不变,(243, 34)。
- MHA输出通过一个前馈全连接网络(Feed Forward Network, FFN),进行非线性转换,shape不变。
- 通过残差连接和Layer Normalization,把MHA和FFN的输出加入最初的输入数据中,作为这个Encoder layer的最终输出,shape还是(243, 34)。
- 栈叠多个这样的Encoder Layer,重复进行自注意力计算和特征转换,输出shape保持不变。
- 每个时间步(帧)都能调用其周围所有帧的信息,通过MHA建模全局依赖关系。
所以综上,输入在Encoder中通过MHA和FFN被复用转换多次,但shape保持不变,依然编码每个时间步的特征。shape的维持使得 Encoder可以灵活堆叠。
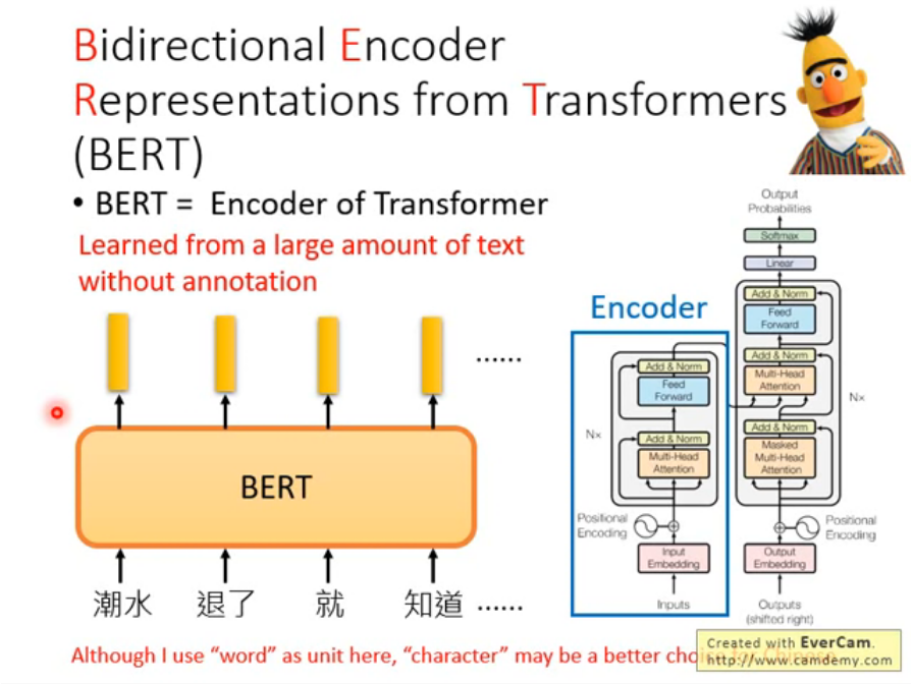
Training of BERT
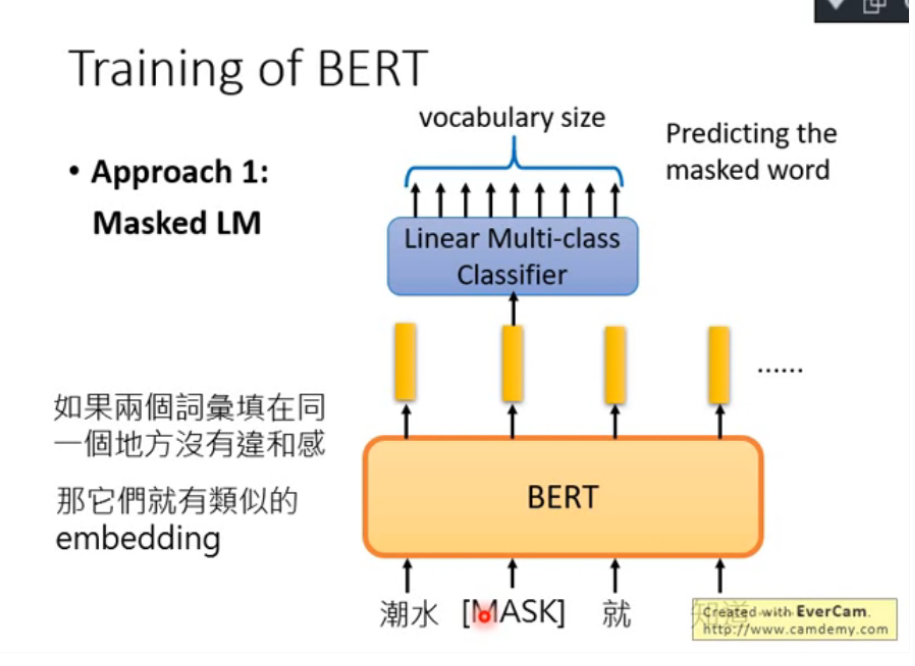
獻上有兩種訓練方法,第一種為Masked LM:即,輸入給BERT的詞彙會有15%的詞彙會被置換為一個特殊的token,這個token稱為"MASK"。也就是蓋掉句子裡面15%的資訊。BERT要做的就是猜這些被蓋掉的詞彙是那幾個詞彙。
作法如下說明:假設輸入的第二個詞彙是被蓋掉的,所有的input經過BERT得到一個output-embedding,然後將被蓋掉的那個詞彙丟到Linear Multi-class Classifier裡面,讓這個Classifier猜這個被蓋掉的是那一個詞彙。但是,因為這是一個Linear model,因此它很弱,要它能猜的出來就必需要BERT能夠抽出一個很好的representation,因此BERT所抽出來的embedding會跟上下文間的詞彙的embedding是相近的。







![[JVM]String str1 = new String(“yhz“)和 String str2 = “yhz“ 的区别](https://img-blog.csdnimg.cn/18ba6ce386984c00ae4e8f5197e5c3e0.png)