⭐作者介绍:大二本科网络工程专业在读,持续学习Java,努力输出优质文章
⭐作者主页:@逐梦苍穹
⭐所属专栏:JavaEE、Spring
目录
- 1、简介
- 2、作用
- 3、开发步骤
- 3.1、导入坐标
- 3.2、创建对象
- c3p0
- druid
- 提取jdbc.properties
- 读取配置文件
- 3.3、Spring设置数据源
- 注意
- 再解耦
- 3.4、使用数据源
- 手动
- 使用jdbc.properties
- Spring容器创建
1、简介

Spring框架提供了多种数据源选项,常见的有以下几种:
- JDBC数据源:Spring提供了对JDBC数据源的支持,可以通过配置数据源参数来连接各种关系型数据库,如MySQL、Oracle、PostgreSQL等。你可以使用Spring的JdbcTemplate或者ORM框架(如Hibernate)来执行SQL操作。
- Apache Tomcat数据源:Spring支持使用Apache Tomcat提供的连接池作为数据源。Tomcat数据源是一个成熟的连接池实现,可以高效地管理数据库连接。
- HikariCP数据源:HikariCP是一个快速高效的连接池,被广泛用于Java应用程序中。Spring可以集成HikariCP作为数据源,通过配置参数来管理连接池。
- C3P0数据源:C3P0是一个受欢迎的连接池库,也可以作为Spring的数据源。你可以配置C3P0连接池的参数,以满足应用程序对数据库连接的需求。
- 还有其他第三方连接池库,如DBCP、BoneCP等,也可以与Spring集成作为数据源。
使用Spring数据源,你可以在Spring的配置文件中定义数据源,并通过注入的方式在应用程序中使用它。这样,你就可以方便地访问数据库,并执行相应的数据库操作。
2、作用
Spring数据源的主要作用是提供数据库连接池,以管理和分配数据库连接。数据库连接是与数据库交互的关键资源之一,每次与数据库建立连接的过程都需要进行网络通信和身份验证,这是一个开销较大的操作。通过使用数据源,可以避免频繁地创建和销毁数据库连接,提高应用程序的性能和响应速度。
以下是Spring数据源的一些主要作用:
- 连接管理:数据源负责创建、管理和维护数据库连接。它可以在应用程序启动时初始化一定数量的连接,并在需要时分配连接给应用程序。连接使用完毕后,数据源可以将连接归还到连接池中,以便其他请求可以继续复用该连接,减少连接创建和销毁的开销。
- 连接池管理:数据源通过连接池来管理数据库连接。连接池维护一定数量的可用连接,当应用程序请求连接时,从连接池中获取一个可用连接分配给应用程序。如果连接池中没有可用连接,数据源可以根据配置的策略来创建新的连接或等待可用连接释放。
- 连接配置:数据源允许你配置数据库连接的参数,如数据库驱动、URL、用户名、密码等。这些配置可以集中管理,便于维护和修改,而不需要在应用程序的多个地方进行重复配置。
- 事务管理:Spring数据源与Spring的事务管理框架紧密集成,可以为应用程序提供事务管理的功能。它可以与Spring的声明式事务管理一起使用,自动管理事务的起始、提交和回滚,并确保在事务范围内的数据库操作的一致性和隔离性。
- 故障恢复:数据源可以处理数据库连接的异常情况,如连接超时、连接断开等。它可以检测到连接的异常状态,并尝试重新建立连接,从而提高应用程序的可靠性和容错性。
通过使用Spring数据源,应用程序可以更高效地管理数据库连接,提升应用性能和扩展性。同时,数据源还提供了一些额外的功能,如连接池配置、事务管理等,使开发人员能够更轻松地进行数据库操作和事务管理。
3、开发步骤
① 导入数据源的坐标和数据库驱动坐标
② 创建数据源对象
③ 设置数据源的基本连接数据
④ 使用数据源获取连接资源和归还连接资源
3.1、导入坐标
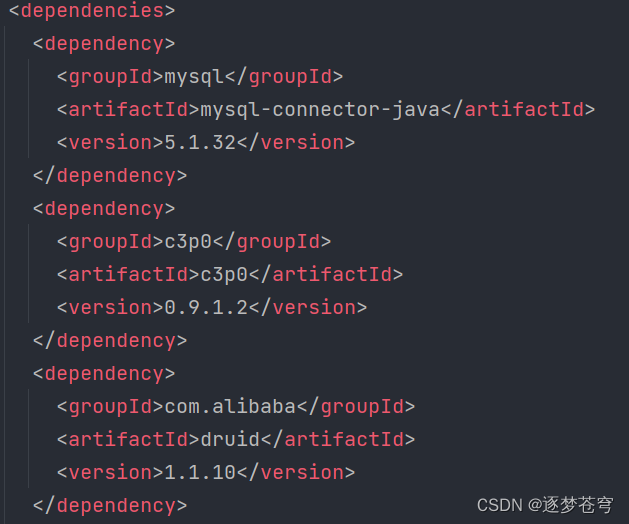
3.2、创建对象
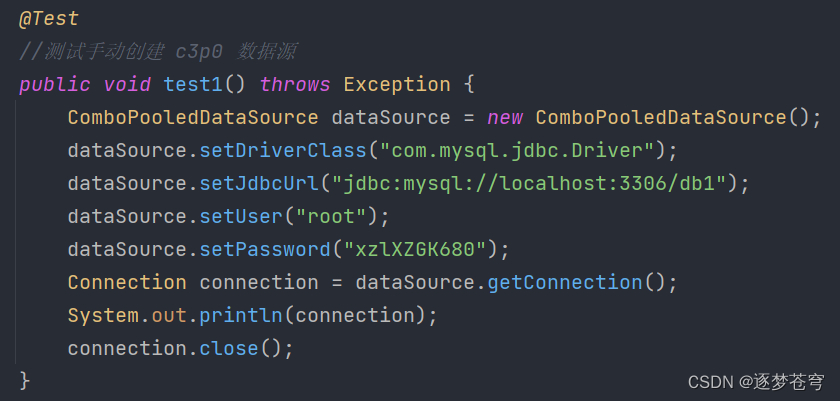
c3p0
ComboPooledDataSource dataSource = new ComboPooledDataSource();
dataSource.setDriverClass("com.mysql.jdbc.Driver");
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUser("root");
dataSource.setPassword("root");
Connection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
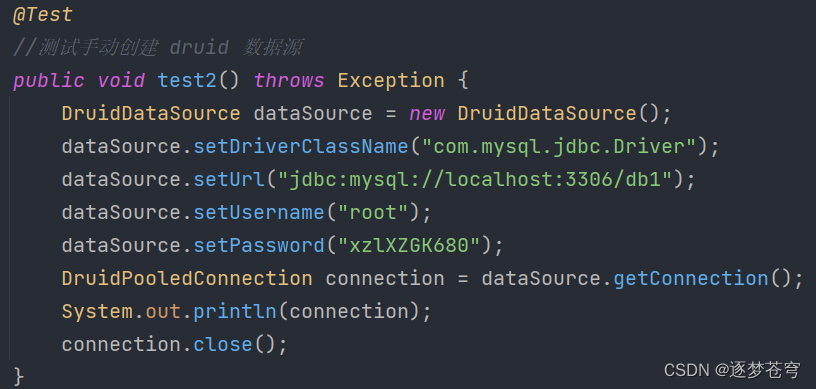
druid
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root");
DruidPooledConnection connection = dataSource.getConnection();
System.out.println(connection);
connection.close();
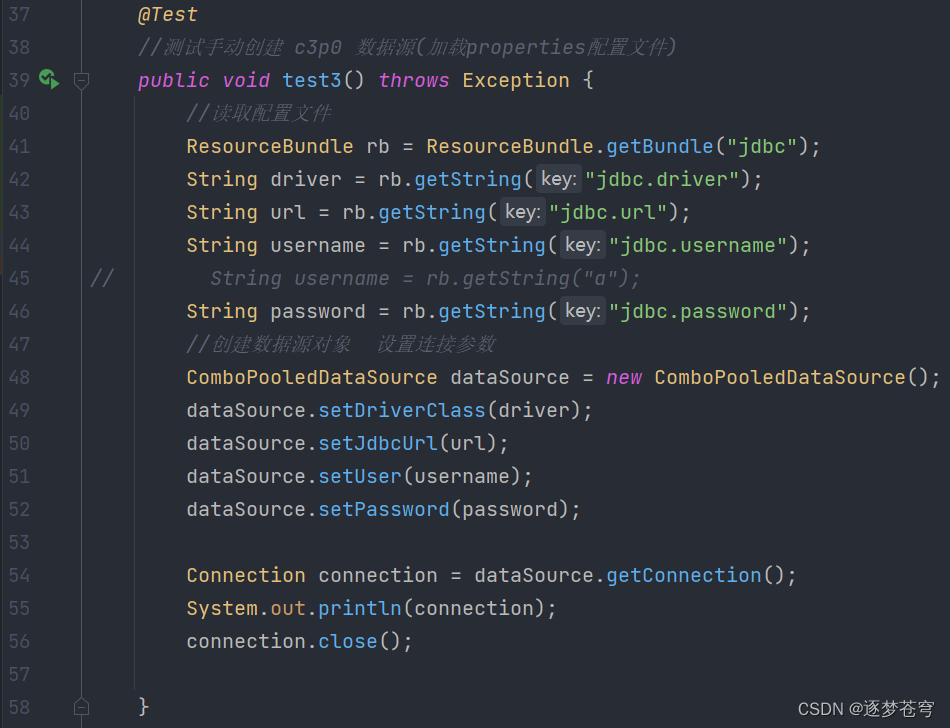
提取jdbc.properties
前面两种创建方式耦合度太高,下面进行解耦合:提取jdbc.properties配置文件:
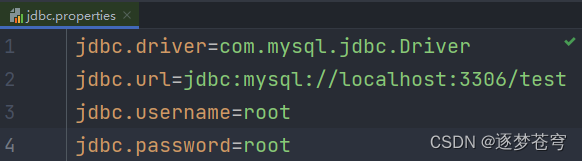
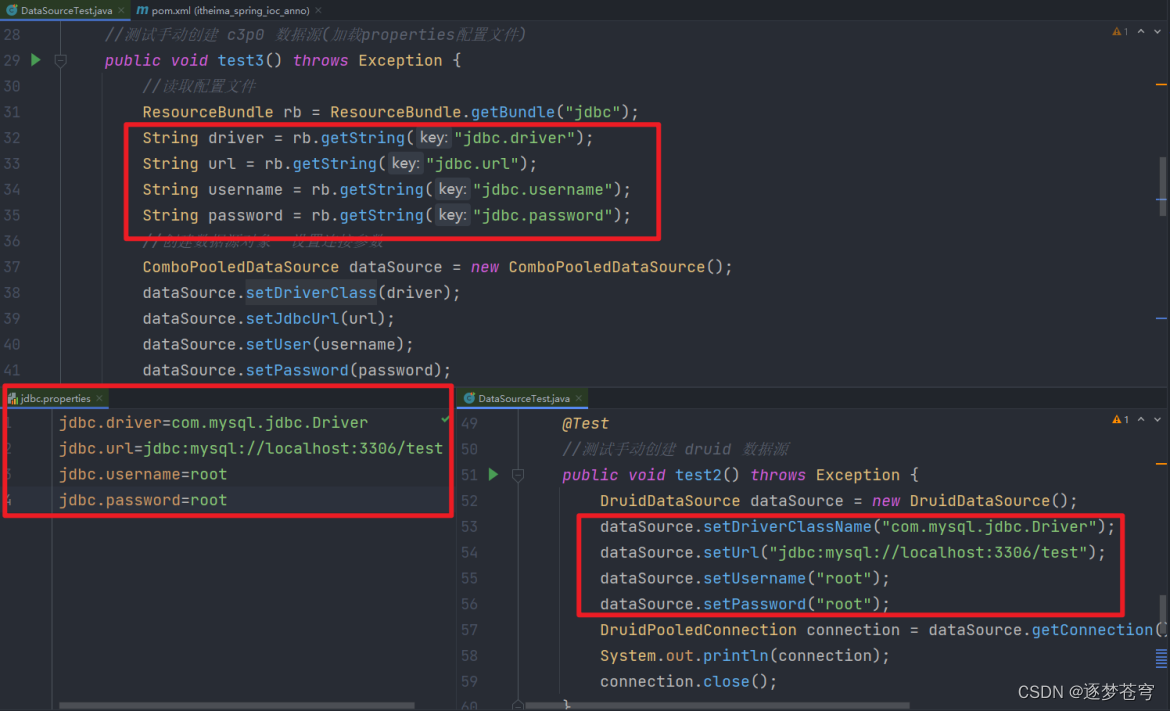
读取配置文件
配置文件里面的内容,实际上就是键值对,类如jdbc.url是一种约定俗成的写法,但是实际上如果写成username=root也无可厚非,不会报错,但是不建议这样做
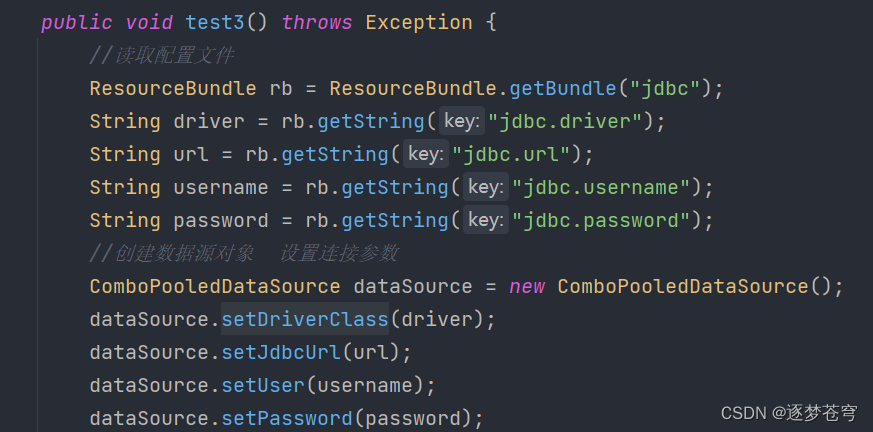
ResourceBundle.getBundle方法是Java提供的用于加载资源束(Resource Bundle)的静态方法。它的使用方式如下:
通过基名加载默认的资源束:ResourceBundle rb = ResourceBundle.getBundle(“bundleName”);
这种用法会根据指定的bundleName加载默认的资源束。
默认的资源束文件的命名约定是bundleName.properties,其中bundleName是资源束的基名。
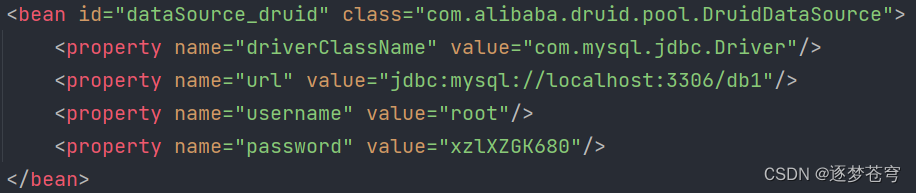
3.3、Spring设置数据源
可以将DataSource的创建权交由Spring容器去完成
- DataSource有无参构造方法,而Spring默认就是通过无参构造方法实例化对象的
- DataSource要想使用需要通过set方法设置数据库连接信息,而Spring可以通过set方法进行字符串注入
Druid数据源:
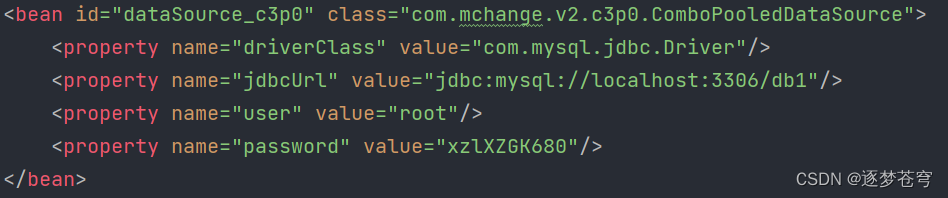
C3p0数据源:
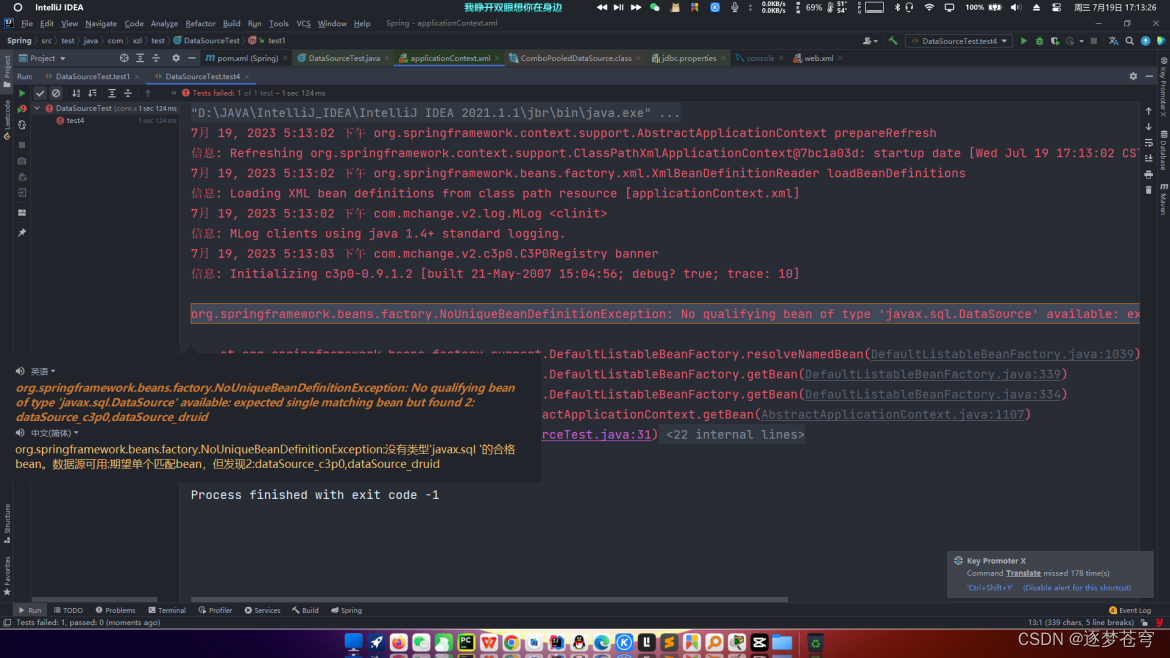
注意
xml配置数据源只能有一个!
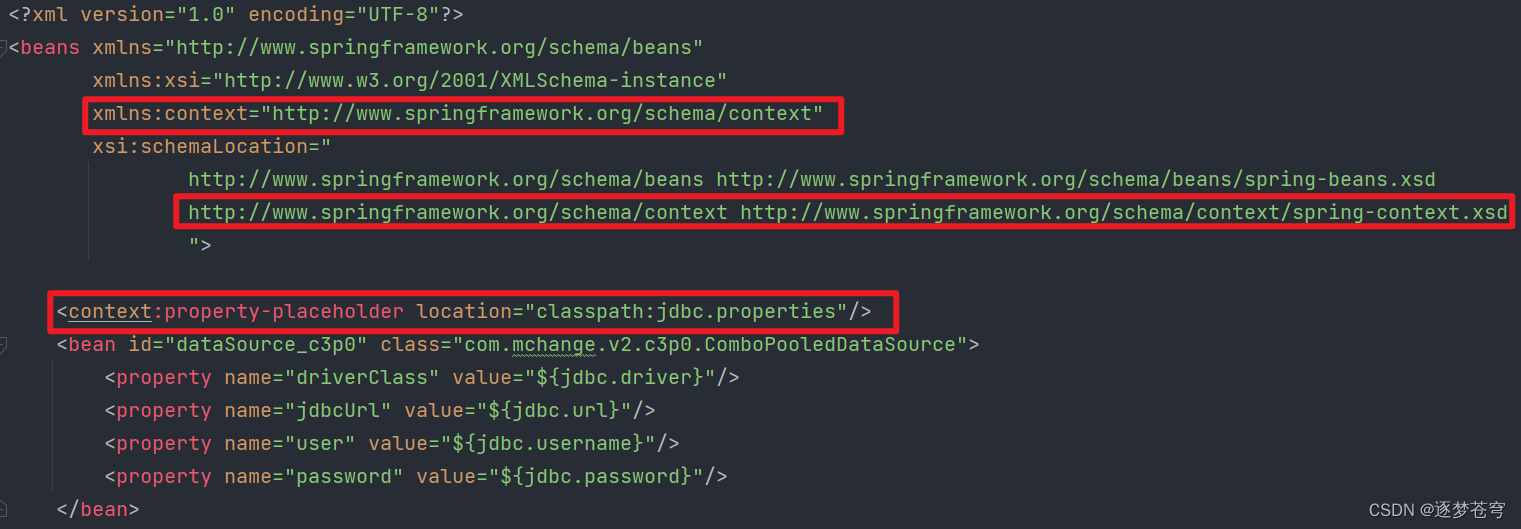
再解耦
上面配置的时候,也是把配置信息写在applicationContext.xml里面,这样依旧耦合。
下面结合jdbc.properties和applicationContext.xml,使用spring提供的命名空间引入配置文件,从而实现对配置信息进行抽取:
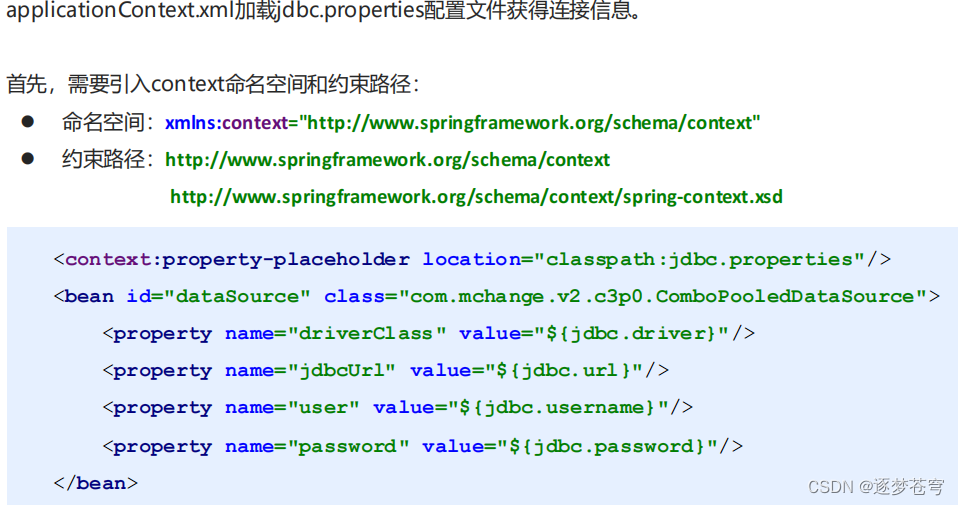
3.4、使用数据源
手动
使用jdbc.properties
Spring容器创建
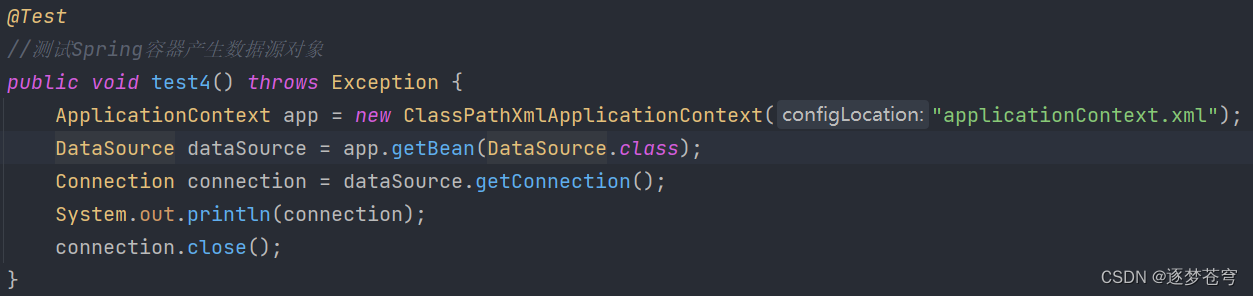
DataSource是一个数据源对象: