本期我们来讲解list,有了string和vector的基础,我们学习起来会快很多
目录
list介绍
编辑
list常用接口
insert
erase
reverse
sort
merge
unique
remove
splice
模拟实现
基础框架
构造函数
push_back
迭代器
常见问题
const迭代器
insert
erase
push和pop
size
析构和clear
拷贝构造
赋值
全部代码
本期内容需要比较扎实的基础
list介绍

1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
2. list 的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。3. list 与 forward_list 非常相似:最主要的不同在于 forward_list 是单链表,只能朝前迭代,已让其更简单高效。4. 与其他的序列式容器相比 (array , vector , deque) , list 通常在任意位置进行插入、移除元素的执行效率更好。5. 与其他序列式容器相比, list 和 forward_list 最大的缺陷是不支持任意位置的随机访问,比如:要访问 list的第6 个元素,必须从已知的位置 ( 比如头部或者尾部 ) 迭代到该位置,在这段位置上迭代需要线性的时间开销;list 还需要一些额外的空间,以保存每个节点的相关联信息 ( 对于存储类型较小元素的大 list 来说这可能是一个重要的因素)
简单来说,list就是带头双向循环列表

我们先简单看看如何使用
list常用接口
list的迭代器啦,构造函数,析构函数这些跟我们前面学的都是一样的,大家稍微看看文档即可,这里就不细讲了

不过list不一样的是它有头插头删,尾插尾删,这些和我们以前用C语言实现的是一样的
insert

我们从vector开始,insert里的参数都不是pos,而是迭代器了

我们之前使用vector时是可以使用迭代器+一个数的,而list是不行的,因为vector是数组,是连续的空间,而list是链表 ,是一个个节点

我们想在5的位置插入,是需要手动让迭代器走的,然后再插入
我们上面插入了1,2,3,4,5,如果我们想在数字3前面插入数据,是需要使用find的,但是我们看文档,list是没有提供find的,我们在vector里说过,find属于算法,通过迭代器来和算法联系起来,我们通过统一的方法,而不用关注容器底层是如何实现的
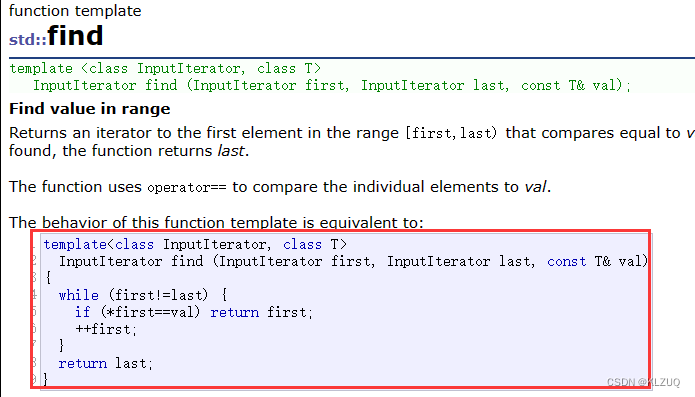
我们来看find的查找,它的循环条件是first!=last,而不是小于,我们用while来进行遍历,也使用的是begin!=end,而不是小于,因为后面节点的地址不一定比前面小
通过迭代器,不止是vector,list,即使是树也是可以查找的,因为都是迭代器,区间范围是左闭右开

比如我们在3前面插入30
并且由于是带头双向循环的原因,insert是不存在迭代器失效问题的
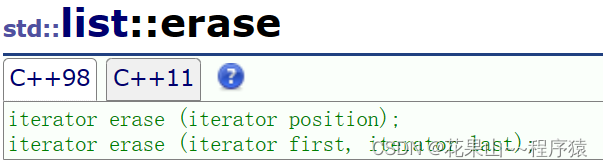
erase

虽然insert没有迭代器失效问题,但是erase是有的

节点都不存在了
insert以后,it不失效,erase以后,it会失效
如果我们要删掉所有的偶数呢?
是需要使用返回值的,和vector是一样的

返回的是刚刚被删除的元素的后一个
reverse

reverse是链表的逆置,其实有点多余了,因为算法库里也有

意义其实不大
sort
sort在库里面也有,那是否也是多余的呢?

这里编译报错了
sort编译报错了,原因是sort底层是快排,快排是需要三叔数取中的,会取到这个数的位置,链表是不适应这个场景的


我们仔细看算法库里sort,find,reverse这些,都是模板,我们仔细看参数名字,sort的是random,reverse的是bidirection,一个是随机的意思,一个是双向的意思,这些都是暗示,这些名字都不是随便起的
这里就和迭代器有关了,迭代器分为单向迭代器,双向迭代器和随机迭代器,单向迭代器只能++,双向可以++也可以- -,而随机不仅可以++和- -,还可以+和-
单链表的迭代器就是单向迭代器,双向链表,也就是list就是双向迭代器,还有map和set也是,vector和string是随机迭代器

find的迭代器是input,是所有迭代器都可以使用,这里涉及到继承,我们后面会讲
那我们该如何知道一个容器的迭代器属于什么呢?

其实文档里都有说明 ,比如list的迭代器是双向的
但迭代器的使用不是定死的,比如string,vector都可以使用reverse,因为随机迭代器可以看作特殊的双向迭代器,是可以兼容的,比如双向可以使用单向的
我们再回过头来看list的sort还有意义吗?有一点,但不多
如果要排序的话,我们应该使用vector,而不是list,在500w的数据量时,vector能比list快10倍
list的排序底层使用的是归并排序,所以list的sort的意义就是方便
我们要排序的话

可以这样做,把list的数据拷贝到vector,然后再拷贝回来
所以各位以后在排序时,尤其是数据量大时,不要用list的sort
merge

merge是两个链表的归并

不过归并前先排序一下
unique

unique去重的意思,不过去重前也是需要先排序的,不然效率太低了
remove

remove就是find加erase
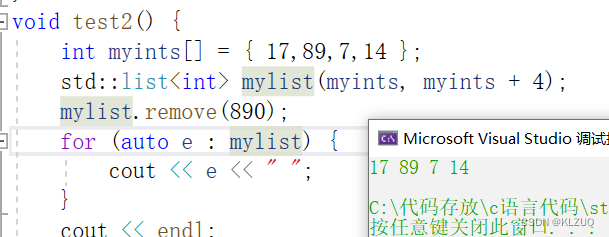
找不到的话就什么也不做,找到就删除
splice

splice是转移,可以将a链表的节点拿下来转移到b链表
我们看第一个接口,是把x链表的所有值转移到当前链表(position)之前,第二个是转移x链表的i,第三个是转移一个区间

这里是调用第一个接口 ,是全部转移,此时mylist2是空的
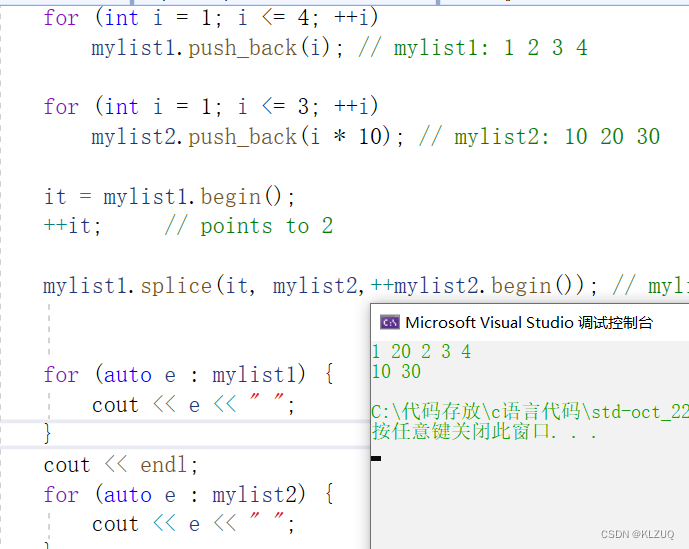
这里调用第二个接口,我们把第二个链表的第二个数转移到第一个链表

这是第三个接口 ,我们把第二个链表的第二个位置开始全部转移
还可以自己转移自己
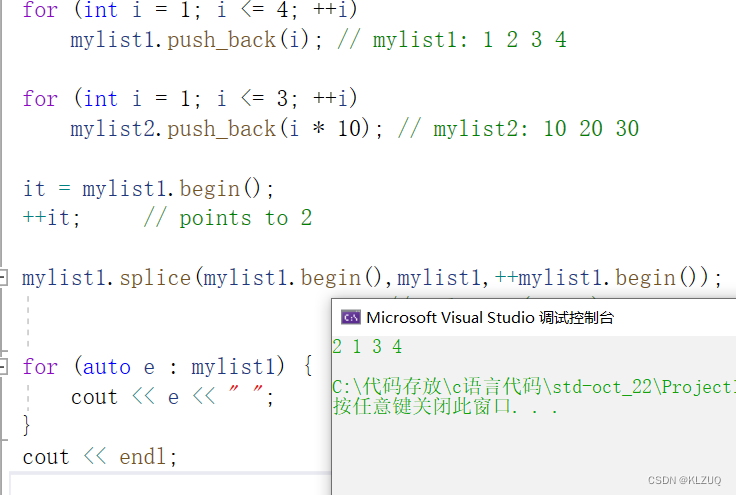
我们把第二个位置转移到第一个位置的前面

还有不要有重叠,像这样就死循环了
模拟实现
下面我们来进行模拟实现
首先我们先看看源代码

我们看到有一个void*类型

我们还找到了链表

还找到了成员变量
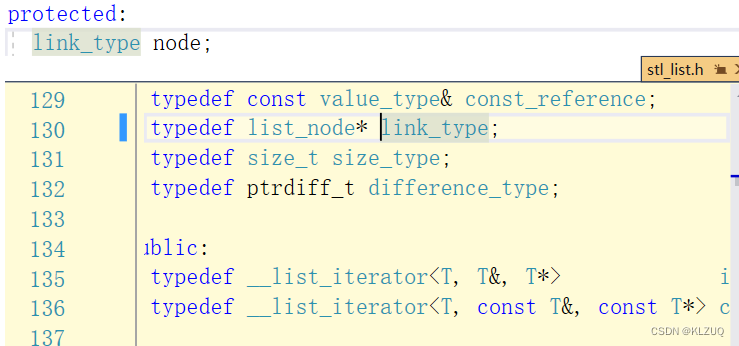
它的本质是这样的

我们还看到了无参的构造函数 ,初始化了一个节点

getnode是哨兵位节点

putnode下面我们发现了熟人,construct

这些我们了解一下即可
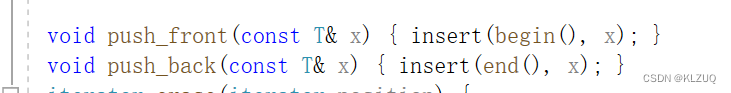
我们还可以找到pushback ,我们发现它调用了insert
我们就不再深入,各位感兴趣的话可以自己再看看,下面我们进入正题
基础框架

我们使用struct定义节点,使用class也可以,不过需要使用public,节点不是公有的使用起来会非常麻烦

补全一下,最后写成这样,看框住的地方,有人可能直接在private里写list_node* _head,这样是错误的,因为 忘记了<T>
构造函数
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
}
除了list里要写构造函数,节点里也要写一个,因为我们在插入节点时是需要创建的,而创建时调用构造函数即可
push_back
void push_back(const T& x)
{
Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}其实写起来和我们以前用C实现的是一样的
迭代器
![]()
首先,大家想一想我们的迭代器用Node*可以吗?
大家想一想,数组是连续的,我们解引用后就可以直接用,++就可以到下一个位置,但是链表不行,它不是连续的,即使当前是连续的,我们插入一个值,也会变成不连续的

我们当时日期对象++是如何到下一天的?是调用了一个函数,是需要运算符重载



我们看库里面,是这样实现的 ,我们要++的话,就是让node=node->next
深入看库对于现在的我们来说还是有点难度的,我们就不再往下看

所以我们最后迭代器是这样一个东西
现在需要写begin和end

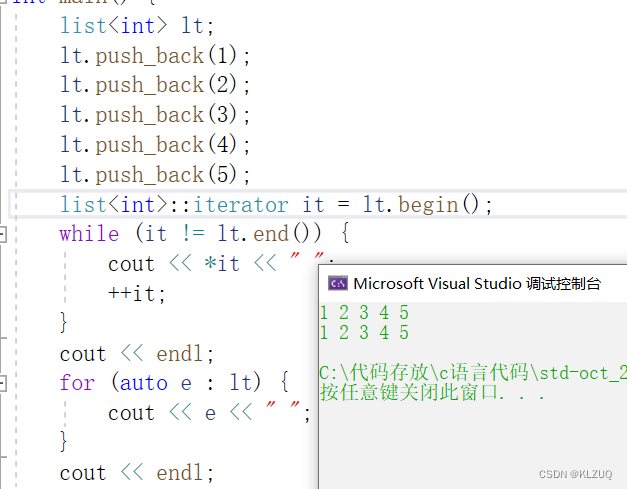
我们遍历是这样写的

begin是第一个数据,end是最后一个数据的下一个位置 
我们看库里面,库里面的node是我们的head,end返回了node,begin返回了node的next,和我们是一样的
迭代器是自定义类型,是节点指针,但因为底层原因,不是连续的,我们不能用原生的,不像之前的vector等等,C++可以用一个类来封装内置类型,然后重载运算符,比如++就是调operator++,就变成我们来控制了,就像C里面指针是不符合我们行为的,我们可以把它写的和指针一样,但是底层不一样

就像这样,再想想我们要写list的遍历,也是这样写,但是*it看起来一样,实际不一样,一个数组,一个链表,甚至一棵树,遍历都可以这样写,封装和运算符重载的力量是非常强大的
我们从应用的角度来实现,即从遍历这里开始写怎么写迭代器


我们补全一下__list_iterator,再看 begin,这里为什么可以这样返回呢?因为单参数的构造函数支持隐式类型转换,就像const char*可以转换为string一样

还可以这样写,本质是一样的
我们再想想解引用该怎么办
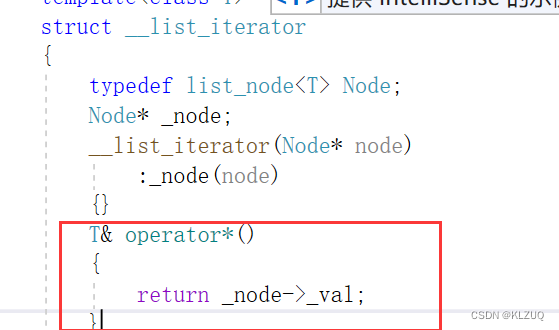
转换为调用operator*,返回节点里的值,因为出了作用域节点还在,val也还在,所以我们返回引用

同样的,我们还要写++,我们让node=node->next即可

我们还要写不等于

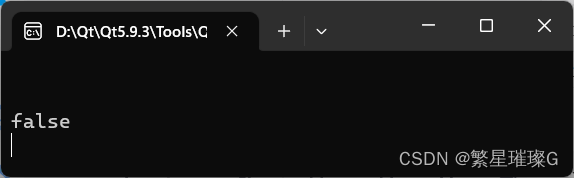
此时我们进行测试发现报错了,报错的是!=
原因是在我们的循环条件里,去调用operator!= ,然后我们的operator!=的参数我们给的是引用,调用了end,end返回的是iterator,是传值返回,传值返回的是head的拷贝,是临时对象,具有常性,所以我们在!=要加const

也就是这样

此时就没有问题了

我们上面实现了++,我们++有前置++,还有后置++,下面是后置++的实现

同样的,我们实现了不等于,也要实现等于
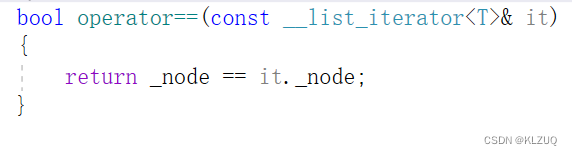
常见问题
下面再解释一下第一次学习的同学一些常见问题
为什么两个typedef不在一块,iterator是对外用的,所以放在public里,而Node是对内用的,我们不希望别人访问我们的节点,别人使用迭代器就可以了,所以不在一块
还有为什么我们起名是list_node,而不是node,迭代器也是,因为除了list,还有vector,树等等各种结构,他们都在std这个命名空间里面

就像我写的这个namespace bai,官方的std,它所有的都在这里面,所以不这样取名会存在命名冲突问题
还有一个疑惑,迭代器的本质是通过自定义类型封装,改变了原生指针的行为,达到我们的目的
![]()
再看一个问题,这里调用begin,begin的值是如何给it的? 是拷贝构造,这里不是赋值
我们现在的迭代器没有写拷贝构造,默认生成的拷贝构造对内置类型完成值拷贝,也就是浅拷贝,但是没有问题,我们要的就是浅拷贝

begin返回这个位置的迭代器,给it,我们就期望it里面的节点指针也是指向这个位置
但是两个对象指向同一个节点,为什么这里没有崩溃?
崩溃的核心原因在于析构函数多次释放,但是迭代器对象我们没写析构函数,原因是节点不是属于迭代器的,不需要迭代器来进行释放,我们只是借助迭代器来访问容器,不论数组,链表,树,我们都可以用同样的方式来访问容器,而不是管理容器,节点是由链表释放的
const迭代器

大家先想想这样设计const迭代器对吗?
迭代器模拟的是指针,指针有两种const指针
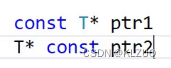
const迭代器模拟的是第一种指针的行为,第二个指针是不能++的,const在*后面,修饰的是指针本身,而第一个是修饰指向的内容不能修改,const迭代器是期望指向的内容不能修改
此时我们再看我们上面设计的,是不行的,我们模拟的是上面的ptr2,这样写出来的是const迭代器本身不能修改,我们就不能遍历,不能++了,因为++是非const,const是不能调用非const的,同样我们也不能把++变为const,因为++里要改变成员变量
我们怎么写才能控制指向的内容不能修改?

我们控制解引用即可 ,这样返回的就是const引用
此时就会有人把上面迭代器整个拷贝一份,然后改改名什么的,那样设计太冗余了

我们再看库里面,它加了两个模板参数

我们先在自己的迭代器这里加一个Ref,然后修改operator*的返回值类型
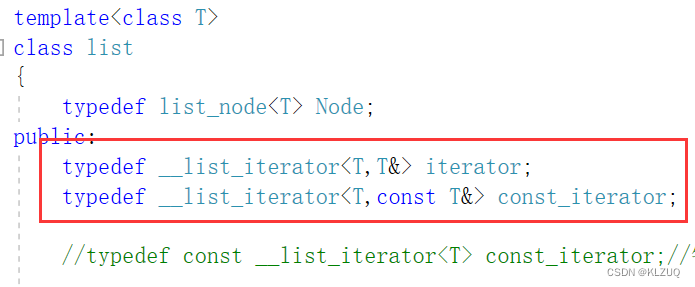
接着我们在list里就可以typedef const迭代器了
其实这样写也相当于我们写了两个类,大家想一想,vector<int>和vector<double>是两个类,是两个相似的类,有编译器通过模板生成
而我们这样写,通过模板参数,给T引用的时候,operator*返回的就是T引用,给const T引用时返回的就是const T引用,但是他们两个是两个类,给不同的模板参数就是不同的类
这样写的话,我们还要修改一些东西
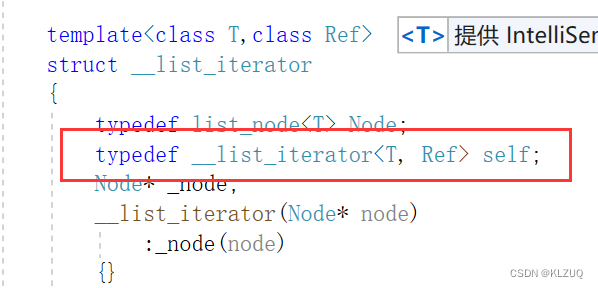
我们要在迭代器类里写这样一个,我们习惯叫做self,就是自己的意思

接着我们把这些修改为self即可

还有别忘记写const的begin和end


我们继续看源码发现,除了重载operator*之外,还重装了这样一个,并且库里面是三个模板参数,我们现在只有两个
我们知道,指针除了*解引用,还有->解引用,*是取指针指向的数据,指向的对象,那->呢?
如果是一个结构体的指针,就需要->,迭代器是模拟指针的行为,什么时候模拟结构体指针呢?

operator->默认返回的是T*

我们先看这样一段代码,我们下面*it解引用是什么? 这段代码为什么不能运行?
因为*it是取里面的数据T,T是A,而A是自定义类型,这里是需要重载流插入的,这是第一种方法,如果我们不想重载,A里的成员变量a1,a2都不是私有的

我们是可以这样写的
此时迭代器是模拟的指向结构体的指针,如果这里类型是int,我们直接解引用,如果是自定义类型,是需要用箭头的

是可以这样写的
但是这里有个非常诡异的问题


首先,我们把operator->屏蔽掉的话这里是会报错的

但是,这个箭头调用是非常奇怪的,operator*是没问题的
![]()
如果是*it,这里就是it.operator*() ,然后operator*返回A&,A.a1,A.a2是没有问题的
而箭头是it.operator->(),返回的是A*,A*怎么去访问呢?
所以这里严格来说严格是it->->_a1,才是符合语法的,是两个箭头,第一个箭头的运算符重载,调用operator->返回A*,A*再加一个箭头才能访问
因为运算符重载要求可读性,所以编译器在这里是特殊处理的,省略了一个箭头
如果是const迭代器,operator->应该返回const T*
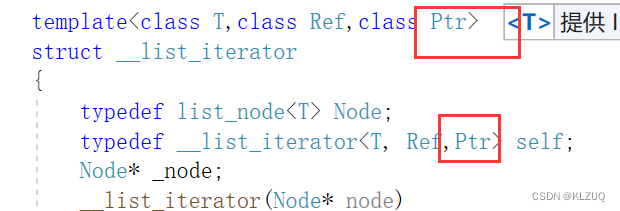
所以我们需要加第三个模板参数Ptr

然后用Ptr代替T*

普通迭代器传T*,const传const T*
我们上面实现的思路大家也发现了,我们要从核心的东西开始看,如果一上来我们就看到迭代器有三个参数,人都是懵的,是看不明白的,所以看不懂的东西我们可以先暂时放下,先看后面的,看它的核心,看它的功能,慢慢就可以知道了,我们看不懂的原因是当前站的高度太低了,很多东西是需要看好几遍的

另外这些不修改的我们最好再加上const
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}再补充一下--
insert
void insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
prev->_next = newnode;
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
}insert非常简单,这里是可以体先出为什么我们节点使用的是结构体,而不是类,如果是类的话,会变得麻烦一点,我们是和库保持一致的,库里面也使用的是结构体,而且我们不用担心有人会写it._node这种代码,因为官方只规定了迭代器可以++这些,而没有规定底层,我们不确定这里是_node,还是Node,或者是_Node,即使我们去查了源码,也只是针对当前平台,换一个平台可能就不同了

库里面和我们是差不多的
erase
void erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
}erase是需要先检查一下的,end是哨兵位,不能删除,另外,我们可以发现,这里是存在迭代器失效问题的,所以我们需要返回下一个位置,另外我们上面还看到了insert其实也有返回值,我们一块补充一下
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
prev->_next = newnode;
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
return newnode;
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
return next;
}push和pop
void push_back(const T& x)
{
/*Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;*/
insert(end(),x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}这些都没什么说的,有了insert和insert,我们都是可以复用的
size
size_t size()
{
size_t sz = 0;
iterator it = begin();
while (it != end())
{
++sz;
++it;
}
return sz;
}我们可以这样遍历一遍,如果感觉这样不好,也可以加一个成员变量_size

这样写我们要修改一下insert和erase

++一下即可,其他地方不用变 ,同理,erase里--一下即可

还有初始化也要修改一下
析构和clear
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
_size = 0;
}clear和析构是不一样的,clear是清理数据,清理还要释放空间,不过哨兵位是不清的,所以我们需要接受一下,it刚好接受下一个位置,最后处理一下size即可,析构直接复用即可


我们简单测试一下,没有问题
拷贝构造
list(const list<T>& lt)//拷贝构造
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
for (auto& e : lt)
{
push_back(e);
}
}我们把数据一个一个的放进去即可

这里是有点冗余,我们提取一下公共部分,库里面也是这样写的
赋值
void swap(list<T>& lt)
{
std::swap(_head,lt._head);
std::swap(_size, lt._size);
}
list<T>& operator=(list<T> lt)//赋值
{
swap(lt);
return *this;
}和vector一样,我们直接用现代写法
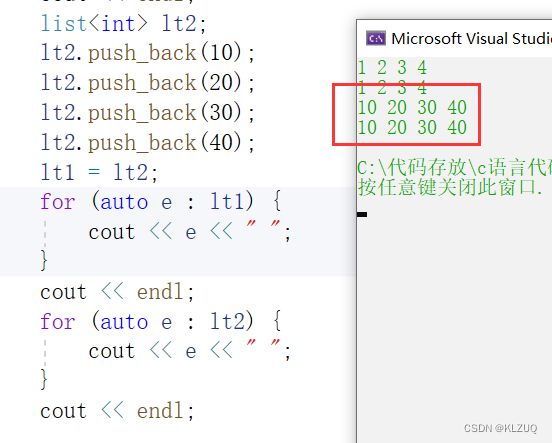
测试一下也没有问题
![]()

仔细看我们和库里面的区别,库里面最开始是list&,我们是list<T>&
我们写的是类型,它写的是类名
对于拷贝构造和赋值,写类名是允许的,不过这样写有点降低可读性,我们这里不推荐和库一样
类模板在类里面使用,既可以写类名,也可以写类型,虽然语法上允许,不过我们最好保持统一写类型
全部代码
#include<iostream>
#include<list>
#include<algorithm>
#include<assert.h>
using namespace std;
namespace bai
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _val;
list_node(const T& val = T())
:_next(nullptr)
,_prev(nullptr)
,_val(val)
{}
};
template<class T,class Ref,class Ptr>
struct __list_iterator
{
typedef list_node<T> Node;
typedef __list_iterator<T, Ref,Ptr> self;
Node* _node;
__list_iterator(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_val;
}
Ptr operator->()
{
return &_node->_val;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self operator++(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const self& it) const
{
return _node != it._node;
}
bool operator==(const self& it) const
{
return _node == it._node;
}
};
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef __list_iterator<T,T&,T*> iterator;
typedef __list_iterator<T,const T&,const T*> const_iterator;
//typedef const __list_iterator<T> const_iterator;//错误的
iterator begin()
{
//return _head->_next;
return iterator(_head->_next);
}
iterator end()
{
return _head;
//return iterator(_head);
}
const_iterator begin() const
{
//return _head->_next;
return const_iterator(_head->_next);
}
const_iterator end() const
{
return _head;
//return const_iterator(_head);
}
void empty_init()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}
list()
{
empty_init();
}
//list(const list& lt)//拷贝构造
list(const list<T>& lt)//拷贝构造
{
empty_init();
for (auto& e : lt)
{
push_back(e);
}
}
void swap(list<T>& lt)
{
std::swap(_head,lt._head);
std::swap(_size, lt._size);
}
//list& operator=(list lt)//赋值
list<T>& operator=(list<T> lt)//赋值
{
swap(lt);
return *this;
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
_size = 0;
}
void push_back(const T& x)
{
/*Node* tail = _head->_prev;
Node* newnode = new Node(x);
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;*/
insert(end(),x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
prev->_next = newnode;
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
++_size;
return newnode;
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
--_size;
return next;
}
size_t size()
{
/*size_t sz = 0;
iterator it = begin();
while (it != end())
{
++sz;
++it;
}
return sz;*/
return _size;
}
private:
Node* _head;
size_t _size;
};
}以上即为本期全部内容,希望大家可以有所收获
如有错误,还请指正