目录
一,list 使用
1. list 文档介绍
2. 常见接口
1. list中的sort
2. list + sort 与 vector + sort效率对比
3. 关于迭代器失效
4. clear
二,list 实现
1.框架搭建
2. 迭代器类——核心框架
3. operator-> 实现
4. const——迭代器
5. insert
6. erase
7. clear——实现
8. 拷贝构造
首先实现迭代器构造函数:
拷贝构造复用:
9. operator=
10. 全代码
结语

一,list 使用
1. list 文档介绍
1. list 是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。2. list 的底层是 双向链表 结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。3. list 与 forward_list 非常相似:最主要的不同在于 forward_list 是 单链表 ,只能朝前迭代,已让其更简单高效。4. 与其他的序列式容器相比 (array , vector , deque) , list 通常在任意位置进行插入、移除元素的执行效率更好。5. 与其他序列式容器相比, list 和 forward_list 最大的缺陷 是 不支持任意位置的随机访问 ,比如:要访问 list 的第6 个元素,必须从已知的位置。( 比如头部或者尾部 ) 迭代到该位置,在这段位置上迭代需要线性的时间开销list还需要一些额外的空间,以保存每个节点的相关联信息 ( 对于存储类型较小元素的大 list 来说这可能是一个重要的因素)
STL文档网址:list - C++ Reference (cplusplus.com)

2. 常见接口

STL 以设计模板类似,只对特殊处进行讲解。
1. list中的sort

我们知道算法库里面有sort函数,那为什么list要单独写一个sort ?? 原因: 算法库里面的sort使用有前提——数据地址连续。(list的sort底层实现大多是 非递归的归并 排序 )
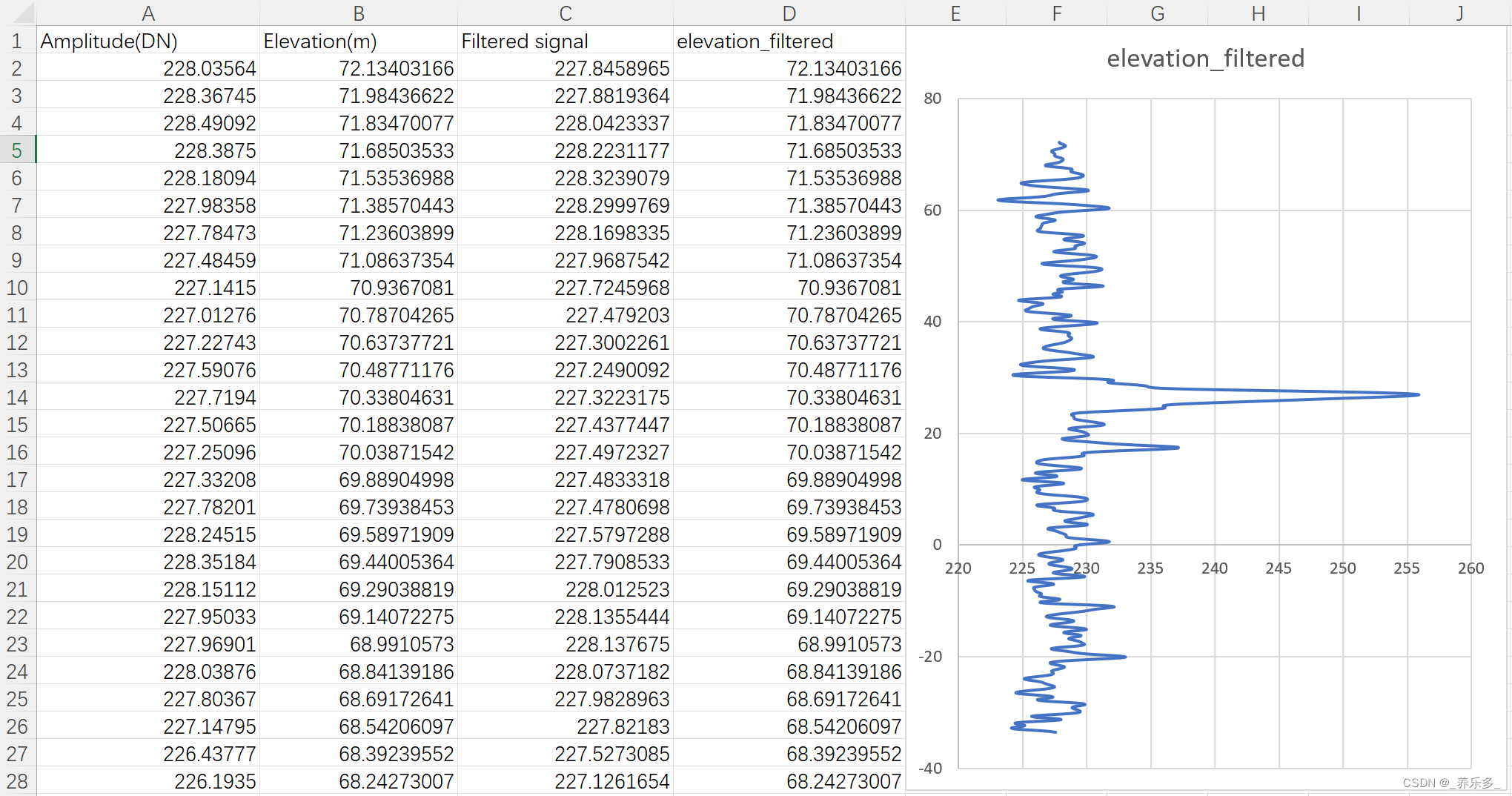
2. list + sort 与 vector + sort效率对比
直接说结论: list的sort 接口意义不大。
效率实验:
测试组: 用list接受数据并用list的sort进行排序。
对照组: 先用vector接收数据,并用算法库中的sort排序,最后将数据转移到list中。
时间效率结果:
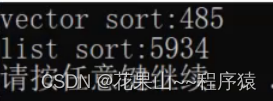
小量两者相差不大,但数据量大时,会有5到10倍的差距。
3. 关于迭代器失效
void TestListIterator1()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
list<int> l(array, array+sizeof(array)/sizeof(array[0]));
auto it = l.begin();
while (it != l.end())
{
// erase()函数执行后,it所指向的节点已被删除,因此it无效,在下一次使用it时,必须先给
其赋值
l.erase(it);
++it;
}
}
// 改正
void TestListIterator()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
list<int> l(array, array+sizeof(array)/sizeof(array[0]));
auto it = l.begin();
while (it != l.end())
{
l.erase(it++); // it = l.erase(it);
}
}
4. clear
清除链表数据,保留头结点。

二,list 实现
1.框架搭建
1
2 #include <iostream>
3 #include <list>
4 uising namespace std;
5 namespace my_list
6 {
7 template<class T>
8 struct list_node
9 {
10 list_node ( const T& val = T() ) // 针对不同的数据类型,所以用数据类型的仿函数
11 :_val(val)
12 ,_prev(nullptr)
13 ,_next(nullptr)
14 {}
15
16 T _val;
17 list_node<T>* _prev ;
18 list_node<T>* _next ;
19 };
template<class T>
22 class list
23 {
24 typedef list_node<T> Node;
25 public:
26 list() //
27 {
28 _head = new Node;
29 _head->_prev = _head;
30 _head->_next = _head;
31 }
private:
45 Node* _head;
46 };
47 }
2. 迭代器类——核心框架
之前string, vector在物理内存中是连续的,因此迭代器就跟指针差不多了,解引用一次即可表示数据。list在物理内存上不是连续存储的。list底层是带头的双向链表,通过头结点的指针,对所指向的数据进行操作处理。
struct _list_iterator // 由于List的迭代器,表层是通过头结点进行操作,数据在头里面,一层解引用
25 { // 解决不了问题
26 typedef list_node<T> Node;
27 typedef _list_iterator iterator;
28 Node* _node; // 迭代器类,内部只要一个结点的指针即可
29
30 _list_iterator(Node* x)
31 : _node(x)
32 {}
33
34 // 重载迭代器*,因为结点的解引用,只是得到结点。目的:支持读,写
35 T& operator*()
36 {
37 return _node->_val;
38 }
39 // 重载迭代器++,list不是连续的空间,地址++不合理;目的:++后为下一个迭代器位置,且支持读,写
40 iterator& operator++() // 前置++
41 {
42 _node = _node->_next;
43 return *this;
44 }
45
46
47 bool operator!=(const iterator& v) const
48 {
49 return _node != v._node;
50 }
大家是否有注意到吗? 我们的迭代器框架里没有写析构与拷贝构造?其实里面暗藏玄鸡。
首先是析构: 1. _node指针属于链表,我们不能随便释放空间。2. 自定义类型,系统自动调用自定义类型的析构函数。
其次是拷贝: 我们只需要目标的地址,值拷贝就行,不需要深拷贝,所以不用写。
3. operator-> 实现
假设T是自定义类型,需要读取里面成员函数,甚至是成员变量。那么一般的写法: (*it).a1, 既然是指针写箭头会更方便
// 实现
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &(operator*()); //这个挺怪异的,马上讲解
}
// 测试
void test2()
{
struct pos
{
int a1 = 1;
int a2 = 2;
};
my_list::list<pos> x;
my_list::list<pos>::iterator it = x.begin();
while (it != x.end())
{
cout << (*it).a1;
cout << it->a1;
}
}
4. const——迭代器
普通迭代器, 解引用得到数据本体;而const迭代器,解引用得到本体,不能对本体进行修改。下面是实现思路:

迭代器代码:
#include <iostream>
#include <string>
using namespace std;
namespace my_list
{
template <class T>
struct list_node // 不用修改
{
list_node(const T& data = T())
: _data(data)
, _next(nullptr)
, _prv(nullptr)
{}
T _data;
list_node* _next;
list_node* _prv;
};
template <class T, class Ref, class Ptr>
struct list_iterator // 迭代器,仅修改会返回能写的函数,*, ->
{
typedef list_node<T> Node;
typedef list_iterator< T, Ref, Ptr> iterator;
Node* _node;
list_iterator(Node* node)
: _node(node)
{}
bool operator!= (const iterator& it)
{
return _node != it._node;
}
bool operator==(const iterator& it)
{
return _node == it._node;
}
iterator& operator++()
{
_node = _node->_next;
return *this;
}
iterator operator++(int)
{
iterator tmp(*this);
_node = _node->_next;
return *tmp;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &(operator*());
}
};
template <class T> // 提供const迭代器类型+ const迭代器的begin(),end()
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
list()
{
_head = new Node;
_head->_next = _head;
_head->_prv = _head;
}
void push_back( const T& val)
{
Node* tmp = new Node(val);
tmp->_data = val;
tmp->_next = _head;
tmp->_prv = _head->_prv;
_head->_prv->_next = tmp;
_head->_prv = tmp;
}
private:
Node* _head;
};
}
5. insert

我们实现最简单的1:
// 在当前位置插入一个数据,当前数据向后移
iterator insert(iterator pos, const T& data)
{
Node* cur = pos._node;
Node* prv = cur->_prv;
Node* newnode = new Node(data);
newnode->_next = cur;
newnode->_prv = prv;
prv->_next = newnode;
cur->_prv = newnode;
return iterator(newnode);
}这样头插,push_back也能复用insert:
void push_back( const T& val)
{
/*Node* tmp = new Node(val);
tmp->_data = val;
tmp->_next = _head;
tmp->_prv = _head->_prv;
_head->_prv->_next = tmp;
_head->_prv = tmp;*/
insert(iterator(_head), val); // 头插同理
} void push_front(const T& val)
{
insert(iterator(_head->_next), val);
}
6. erase
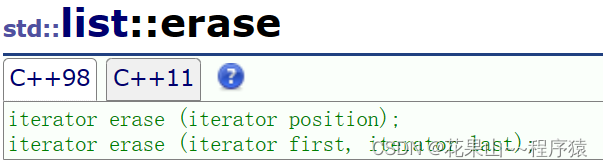
删除迭代器pos位置,然后返回下一个迭代器。
iterator erase(iterator pos)
{
Node* cur = pos._node;
Node* prv = cur->_prv;
Node* next = cur->_next;
prv->_next = next;
next->_prv = prv;
delete cur;
return iterator(next);
}这里只完成迭代器的核心代码,其他小功能就只做代码分享。
7. clear——实现
完成clear的同时,list析构函数也能复用。
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}8. 拷贝构造
传统写法: 自己对数据一个个拷贝。
现代写法: 利用迭代器构造函数,然后交换一下_head结点即可。
首先实现迭代器构造函数:
template <class input_iterator>
list( input_iterator begin, input_iterator end)
{
list_initial(); // 对头结点进行初始化
while (begin != end)
{
push_back(*begin);
++begin;
}
}拷贝构造复用:
void swap(list<T>& x) // 顺便实现一个swap
{
std::swap(x._head, _head);
}
list(const list<T>& x)
{
list_initial();
list tmp(x.begin(), x.end());
swap(tmp);
}
// tmp 调用析构时,会将this的_headfree掉9. operator=
list<T>& operator=(list<T> tmp) // 拷贝构造
{
swap(tmp);
return *this;
}10. 全代码
#include <iostream>
#include <string>
using namespace std;
namespace my_list
{
template <class T>
struct list_node
{
list_node(const T& data = T())
: _data(data)
, _next(nullptr)
, _prv(nullptr)
{}
T _data;
list_node* _next;
list_node* _prv;
};
template <class T, class Ref, class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator< T, Ref, Ptr> iterator;
Node* _node;
list_iterator(Node* node)
: _node(node)
{}
bool operator!= (const iterator& it)
{
return _node != it._node;
}
bool operator==(const iterator& it)
{
return _node == it._node;
}
iterator& operator++()
{
_node = _node->_next;
return *this;
}
iterator operator++(int)
{
iterator tmp(*this);
_node = _node->_next;
return *tmp;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &(operator*());
}
};
template <class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
void list_initial()
{
_head = new Node;
_head->_next = _head;
_head->_prv = _head;
}
list()
{
list_initial();
}
template <class input_iterator>
list( input_iterator begin, input_iterator end)
{
list_initial(); // 对头结点进行初始化
while (begin != end)
{
push_back(*begin);
++begin;
}
}
void swap(list<T>& x)
{
std::swap(x._head, _head);
}
list(const list<T>& x)
{
list_initial();
list tmp(x.begin(), x.end());
swap(tmp);
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
void push_back( const T& val)
{
/*Node* tmp = new Node(val);
tmp->_data = val;
tmp->_next = _head;
tmp->_prv = _head->_prv;
_head->_prv->_next = tmp;
_head->_prv = tmp;*/
insert(iterator(_head), val); // 头插同理
}
void push_front(const T& val)
{
insert(iterator(_head->_next), val);
}
// 在当前位置插入一个数据,当前数据向后移
iterator insert(iterator pos, const T& data)
{
Node* cur = pos._node;
Node* prv = cur->_prv;
Node* newnode = new Node(data);
newnode->_next = cur;
newnode->_prv = prv;
prv->_next = newnode;
cur->_prv = newnode;
return iterator(newnode);
}
iterator erase(iterator pos)
{
Node* cur = pos._node;
Node* prv = cur->_prv;
Node* next = cur->_next;
prv->_next = next;
next->_prv = prv;
delete cur;
return iterator(next);
}
iterator Pop_back()
{
erase(iterator(_head->_prv));
return _head;
}
iterator Pop_front()
{
Node* next = _head->_next->_next;
erase(iterator(_head->_next));
return next;
}
list<T>& operator=(list<T> tmp)
{
swap(tmp);
return *this;
}
private:
Node* _head;
};
}
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。