目录
前言
一、Set 类型
1.1、操作命令
sadd / smembers(添加)
sismember(判断存在)
scard(获取元素个数)
spop(删除元素)
smove(移动)
srem(删除)
sinter / sinterstore(交集 / 存储)
sunion / sunionstore(并集 / 存储)
sdiff / sdiffstore(差集 / 存储)
1.2、set 的内部编码方式
1.3、使用场景
用户画像(set 保存用户 “标签”)
共同好友
统计 UV(去重)
前言
redis 中所有的 key 都是字符串,value 的类型是存在差异的,因此出现了操控不同 value 的命令,接下来,就一起来学习一下吧~
Ps1:接下来,我给出的指令都是按照 Redis 官方文档的语法格式来解析的,[ ] 相当于一个独立的单元,表示可选项(可有可无),其中 | 表示 “或者” 的意思,多个只能出现一个,[ ] 和 [ ] 之间是可以同时存在的.
Ps2:一个快速失去年终奖的小技巧 —— 清除 redis 上所有的数据 =》 FLUSHALL,这个操作可以把 redis 上所有的键值对全部带走.
Ps3:不同操作返回值差别挺大,很容易记混,不用可以去背,经常使用的操作,自然就记住了.
一、Set 类型
1.1、操作命令
redis 中的 set 就是一个集合,集合就是把一些关联的数据放在一起,我们把集合中的元素叫 member ,具有以下特殊的特性:
- 集合中的元素是无序的.
- 集合中的元素是唯一的,不能重复.
- 和 list 类似,集合中的每个元素都是 string 类型的,同时也可以使用 json 这样的格式让 string 存储 结构化 的数据.
Ps:这里提到的到无序,对应前面讲到的 list.
list: [1, 2, 3] 和 [2, 1, 3] 是两个不同的 list.
set: [1, 2, 3] 和 [2, 1, 3] 是两个相同的 set.
sadd / smembers(添加)
将一个或多个元素添加到 set 中,返回值是成功添加的元素个数. 注意,重复的元素会添加失败.
SADD key member [member ...]获取一个 set 中所有的元素. 注意,返回的元素是无序的.
SMEMBERS key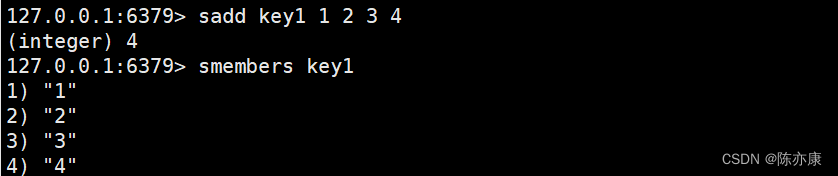
sismember(判断存在)
判断一个元素是否在 set 中,返回 1 表示存在,0表示不存在.
SISMEMBER key member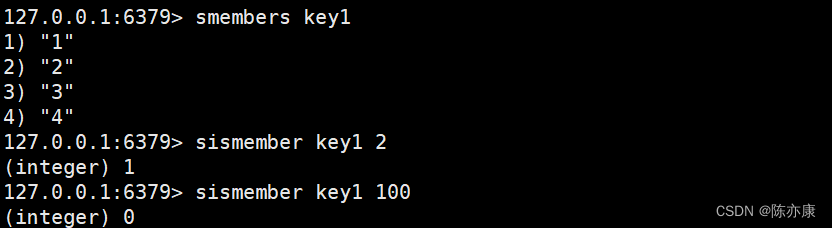
scard(获取元素个数)
用来获取 set 中元素的个数.
SCARD key 

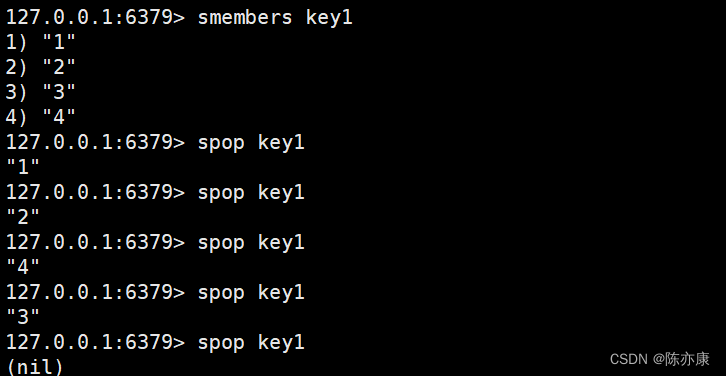
spop(删除元素)
pop 一般表示 “从末尾” 删除一个元素,集合中的元素都是无序的,末尾是什么呢?在 redis 的 set 中,使用 spop 表示随机删除一个元素.
SPOP key [count]通过 count 参数可以指定删除的个数,没写就是默认删除这一个.

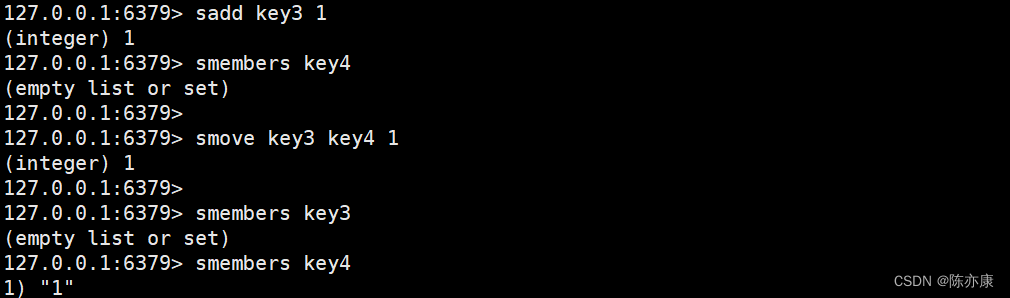
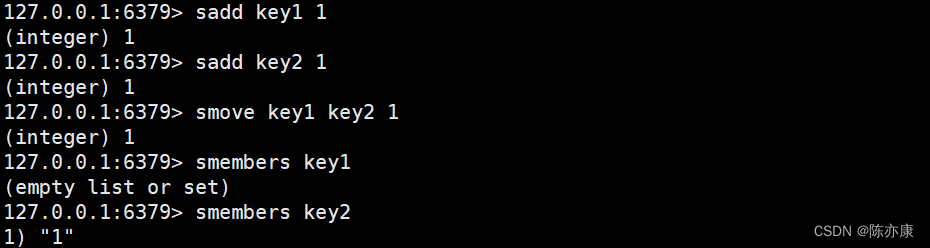
smove(移动)
将 member 从 source 上删除,再插入到 destination 中.
返回 1 表示移动成功.
返回 0 表示移动失败,但是 source 中删除成功,只是 destination 中不能出现重复元素(destination 中含有新插入的元素).
SMOVE source destination member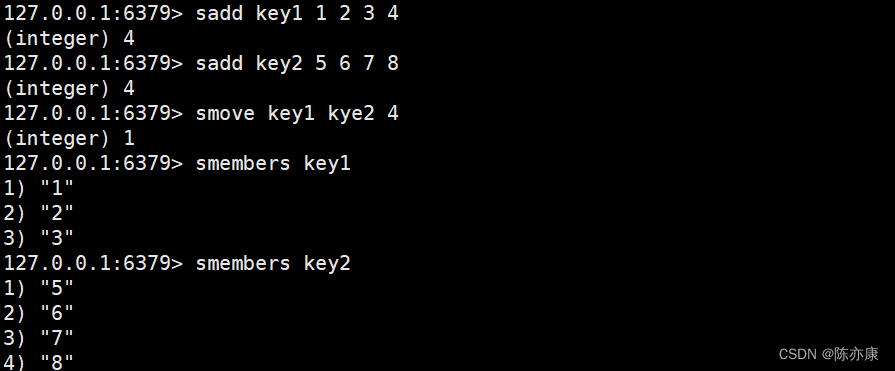
srem(删除)
可以一次删除一个 或 多个 member ,返回值表示删除元素的个数.
SREM key member [member ...]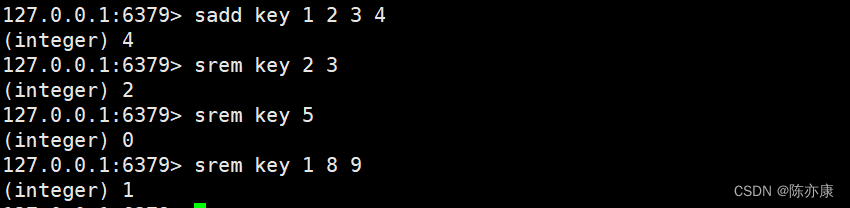
sinter / sinterstore(交集 / 存储)
交集就是在两个集合中都有的元素,通过 sinter 就可以获取多个元素的之间的交集,时间复杂度为 O(N*M),N 是最小的集合元素个数,M 是最大集合的元素个数.
SINTER key [key ...]
//此处 key 对应一个集合,返回值就是最终交集的数据.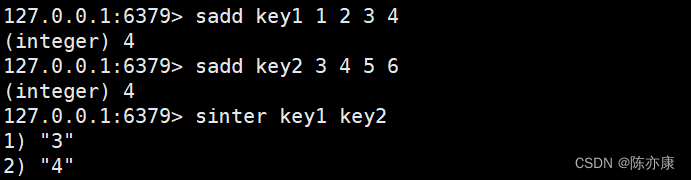
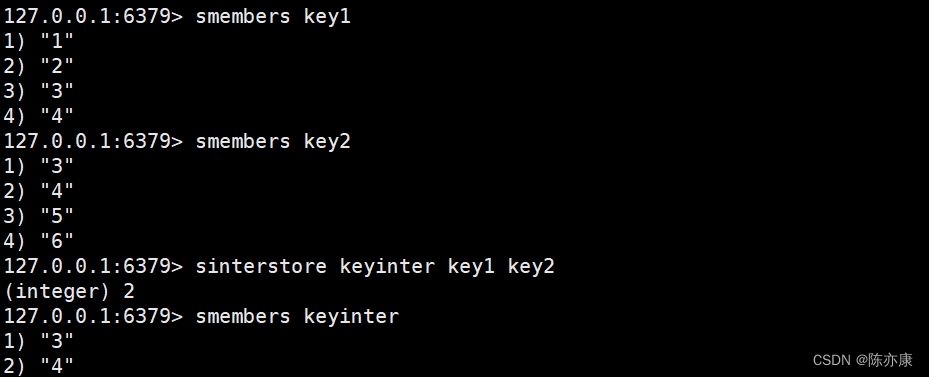
sinterstore 用来将算好的交集,放到 destination 这个 key 对应的集合中
SINTERSTORE destination key [key ...]
sunion / sunionstore(并集 / 存储)
并集就是两个集合的数据全集,sunion 就是返回并集的结果数据,时间复杂度为 O(N),N 表示总的元素个数.
SUNION key [key ...]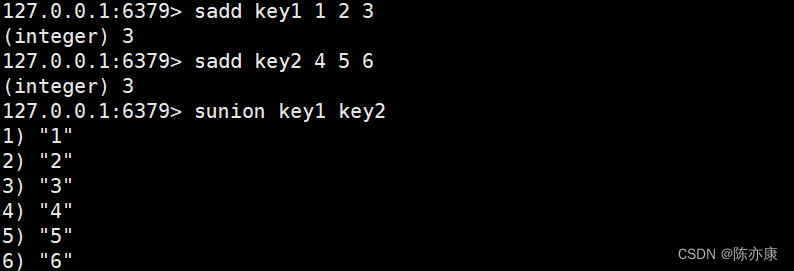
sunionstore 直接把并集的结果存储到 destination 对应的集合中,返回值事并集的元素个数.
SUNIONSTORE destination key [key ...] 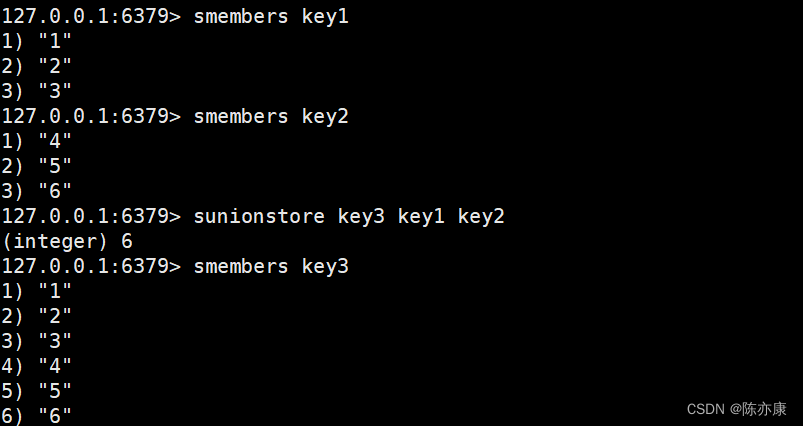
sdiff / sdiffstore(差集 / 存储)
差集,A 和 B 做差集,就是找出哪些元素在 A 中存在,同时 B 中不存在(B 和 A 做差集则相反).
SDIFF key [key ...]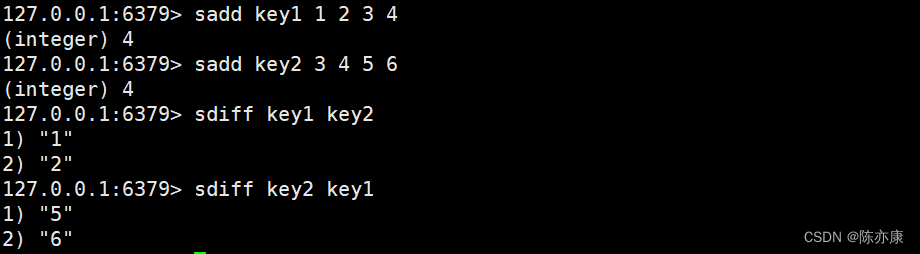
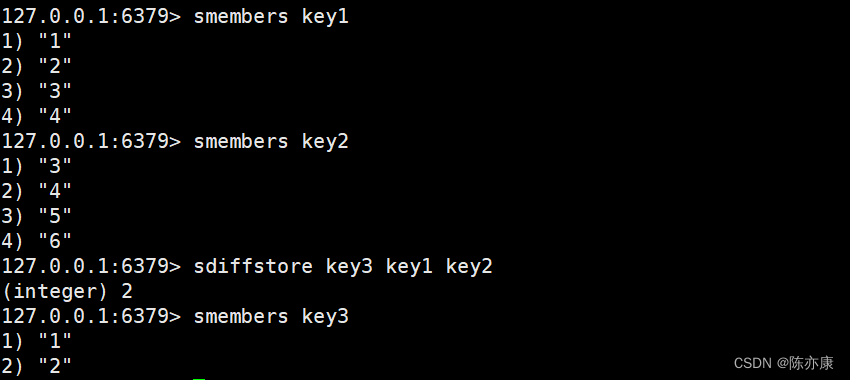
sdiffstore 就是将差集的结果放在 destination 中,时间复杂度为 O(N).
SDIFFSTORE destination key [key ...]
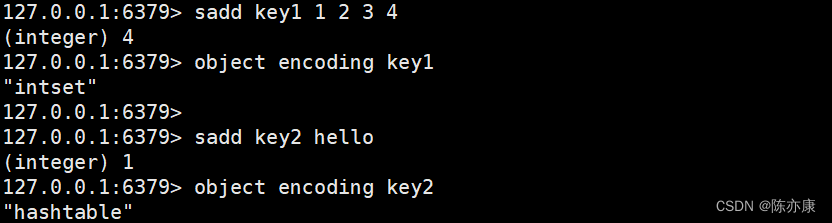
1.2、set 的内部编码方式
set 内部有两种编码方式:
- intset:整数集合,当所有元素均为整数,并且元素个数不是很多的时候,为了节省空间,做出的特定优化.
- hashtable:最基本的哈希表(不是 java 标准库中的 HashTable),redis 内部对哈希表的实现方式和 java 中的哈希表可能不太一样,但是整体思想都是一样的;时间上复杂度O(1),但是空间上会有一定的浪费(hash 是一个数组,数组上有些位置有元素,有些位置没有元素).
1.3、使用场景
用户画像(set 保存用户 “标签”)
通过你对这个服务器访问的数据,分析出你这个人的一些特征,之后再 “投其所好”~
抖音这款软件在这方面做的就尤为突出,他会根据用户经常观看收藏点赞那种类型的视频,就能看出你这个人的 性别、年龄、居住地、爱好... 通过这个过程,就会将这些特征,就会转换成标签保存到 redis 的 set 中,之后就会给你推送与这些标签相关的视频内容.
共同好友
基于 set 的 “集合求交集” 就可得到两个用户之间的 “用户关系”
在 QQ 上,我这边加了很多好友,你这边也加了很多好友,这样系统就可以做到好友推荐:
A 的好友中有 B 和 C.
D 的好友中也有 B 和 C.
系统就会把 A 推荐给 D.
统计 UV(去重)
利用 set 的去重机制,衡量用户规模.
一个互联网产品衡量用户规模,主要就是两个指标:
PV:page view,用户每次访问服务器都会产生一个 pv.
UV:user view ,每个用户访问服务器,都会产生一个 uv,但是同一个用户多次访问,不会使 uv 增加,这就需要基于 set 实现去重.