目录
一、日志
1、错误日志
2、二进制日志
2.1 介绍
2.2 格式
2.3 删除
3、查询日志
4、慢查询日志
二、主从复制
1、概述
2、原理
3、搭建
三、分库分表
1、介绍
1.1背景
1.2拆分策略
1.3垂直拆分
1.4水平拆分
1.5实现技术
2、Mycat概述
2.1 介绍
2.2 安装
2.3 mycat的目录介绍
2.4 mycat 结构与概念
3、Mycat入门
4、Mycat配置
4.1 schema.xml
4.2 rule.xml
4.3 server.xml
5、Mycat分片规则
1.垂直分库
2.水平分表
2.1 schema.xml
2.2 server.xml
3.分片规则:
3.1范围分片
3.2取模分片
3.3一致性hash算法
3.4枚举分片
3.5应用指定算法
3.6固定hash算法
3.7字符串hash解析
3.8按天分片
3.9按自然月分片
6、Mycat管理及监控
四、读写分离
1、介绍
2、一主一从
4、双主双从
5、双主双从读写分离
一、日志
1、错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为 mysqld.log
查看日志位置:
show variables like '%log_error%';2、二进制日志
2.1 介绍
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:
- 灾难时的数据恢复;
- MySQL的主从复制。
在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
show variables like '%log_bin%';参数说明:
-
log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名需要再该basename的基础上加上编号(编号从000001开始)。
-
log_bin_index:binlog的索引文件,里面记录了当前服务器关联的binlog文件有哪些。
2.2 格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录 |
show variables like '%binlog_format%';如果我们需要配置二进制日志的格式,只需要在 /etc/my.cnf 中配置 binlog_format 参数.
而如果想要查看二进制格式的日志,需要使用mysqlbinlog命令
2.3 删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种指令清理日志:
reset master 删除全部 binlog 日志,删除之后,日志编号,将从 binlog.000001重新开始
purge master logs to 'binlog.*' 删除 * 编号之前的所有日志
purge master logs before'yyyy-mm-dd hh24:mi:ss' 删除日志为 "yyyy-mm-dd hh24:mi:ss" 之前产生的所有日志也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。默认实际30天
show variables like '%binlog_expire_logs_seconds%';3、查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。
如果需要开启查询日志,可以修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
#开启查询日志 , 0 关闭, 1 开启
general_log=1
#设置日志的文件名 , 如果没有指定, 默认的文件名为 host_name.log
general_log_file=mysql_query.log 开启了查询日志之后,在MySQL的数据存放目录,也就是 /var/lib/mysql/ 目录下就会出现mysql_query.log 文件。
之后所有的客户端的增删改查操作都会记录在该日志文件之中,长时间运行后,该日志文件将会非常大,所以非必要不用开。
4、慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。
long_query_time 默认为10 秒,最小为 0, 精度可以到微秒。如果需要开启慢查询日志,需要在MySQL的配置文件 /etc/my.cnf 中配置如下参数:
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用
log_slow_admin_statements和 更改此行为 log_queries_not_using_indexes
#记录执行较慢的管理语句
log_slow_admin_statements =1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 1注意:上述所有的参数配置完成之后,都需要重新启动MySQL服务器才可以生效。
二、主从复制
1、概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL 复制的优点主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,以避免备份期间影响主库服务。

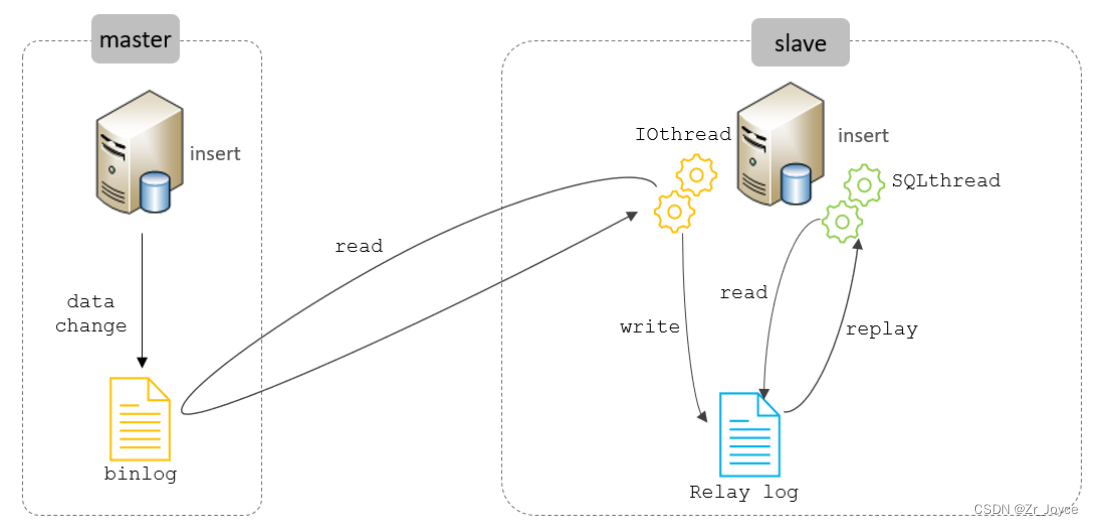
2、原理
MySQL主从复制的核心就是 二进制日志,具体的过程如下
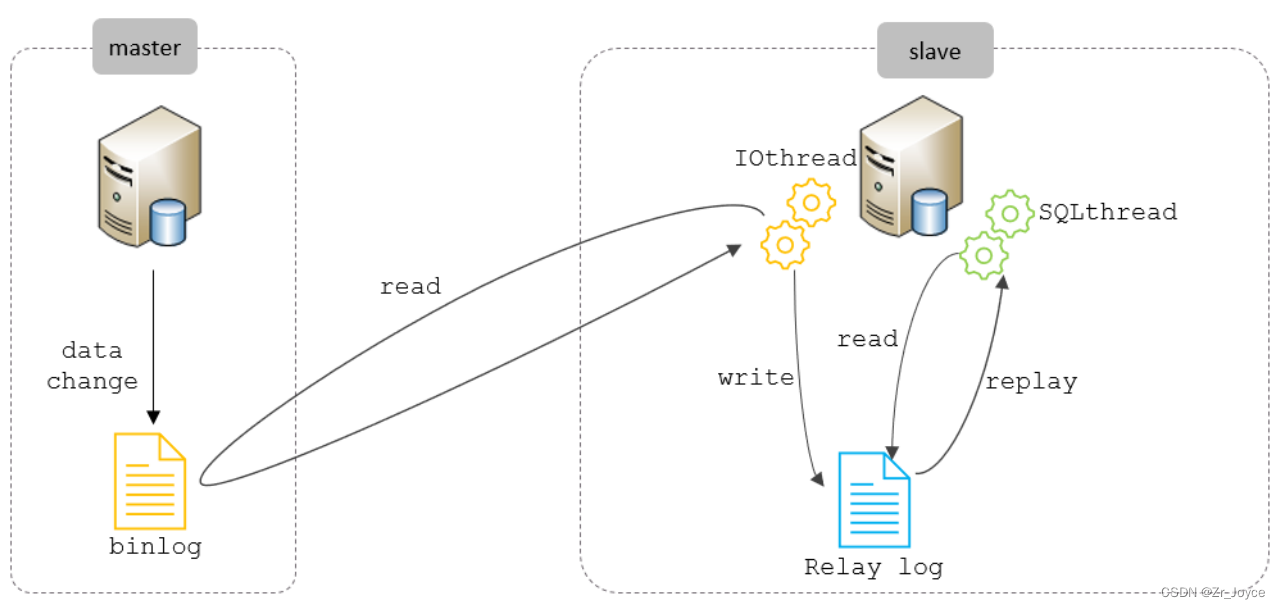
复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- slave重做中继日志中的事件,将改变反映它自己的数据。
3、搭建
3.1 准备
先开放指定的端口或关闭MySQL服务器的防火墙
准备好两台服务器之后,在上述的两台服务器中分别安装好MySQL,并完成基础的初始化准备(安装、密码配置等操作)工作。 其中:
192.168.200.200 作为主服务器master
192.168.200.201 作为从服务器slave 3.2主库配置
3.2.1修改配置文件/etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=1
#是否只读,1 只读, 0 读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库db01
#binlog-do-db=db013.2.2重启MySQL服务器
systemctl restart mysqld3.2.3登录mysql,创建远程连接的账号,并授予主从复制权限
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';3.2.4通过指令,查看二进制日志坐标

show master status;
字段含义说明:
file : 从哪个日志文件开始推送日志文件
position : 从哪个位置开始推送日志
binlog_ignore_db : 指定不需要同步的数据库 3.3从库配置
3.3.1. 修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=13.3.2. 重新启动MySQL服务
systemctl restart mysqld3.3.3. 登录mysql,设置主库配置
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',SOURCE_LOG_POS=663;上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
CHANGE MASTER TO MASTER_HOST='192.168.200.200', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000004',MASTER_LOG_POS=663;也就是把source换成master
SOURCE_HOST 主库IP地址 MASTER_HOST
SOURCE_USER 连接主库的用户名 MASTER_USER
SOURCE_USER 连接主库的用户名 MASTER_USE
SOURCE_LOG_FILE binlog 日志文件名 MASTER_LOG_FILE
SOURCE_LOG_POS binlog 日志文件位置 MASTER_LOG_POS3.3.4. 开启同步操作
start replica ; #8.0.22之后
start slave ; #8.0.22之前3.3.5. 查看主从同步状态
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前3.4测试
在主库 192.168.200.200 上创建数据库、表,并插入数据
在从库 192.168.200.201 中查询数据,验证主从是否同步
三、分库分表
1、介绍
1.1背景
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
- 1. IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
- 2. CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。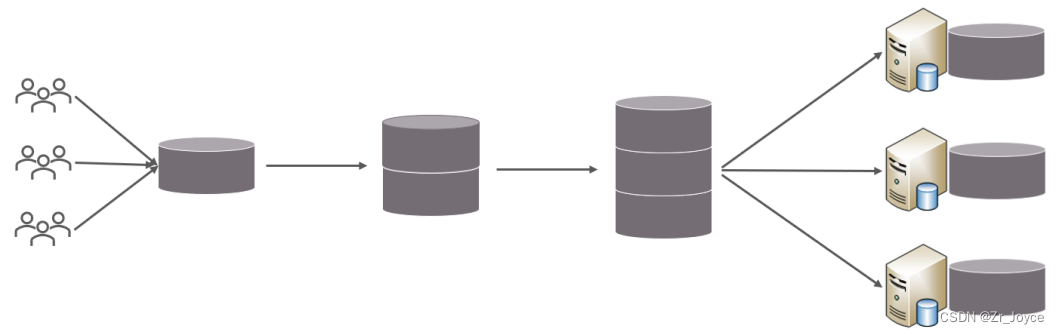 分库分表的核心思想是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
分库分表的核心思想是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
1.2拆分策略
分库分表的形式,主要是两种:垂直拆分和水平拆分。而拆分的粒度,一般又分为分库和分表,所以组成的拆分策略最终如下: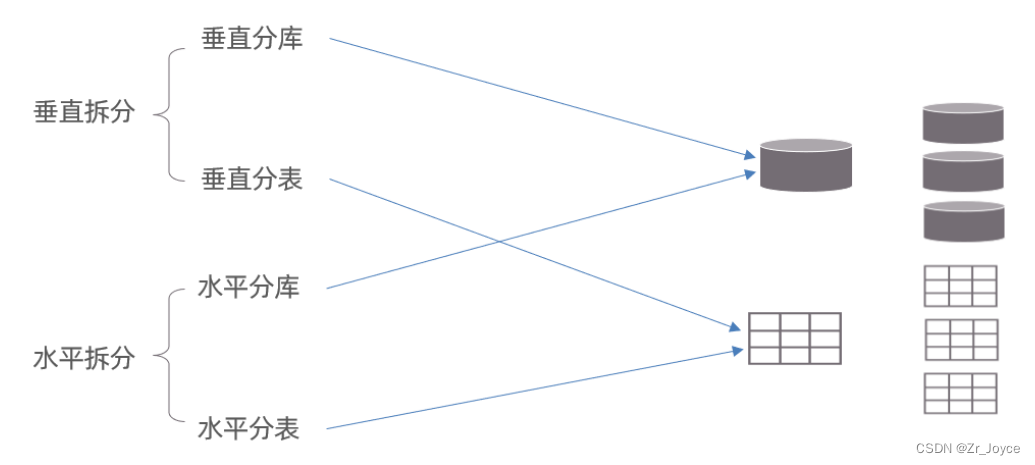
1.3垂直拆分
1.3.1垂直分库
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。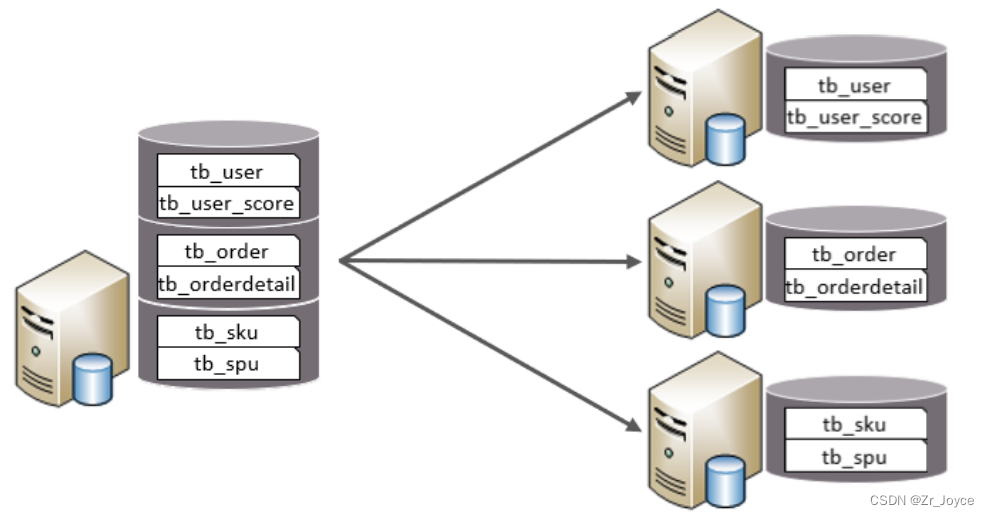
特点:
- 每个库的表结构都不一样。
- 每个库的数据也不一样。
- 所有库的并集是全量数据。
1.3.2垂直分表
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。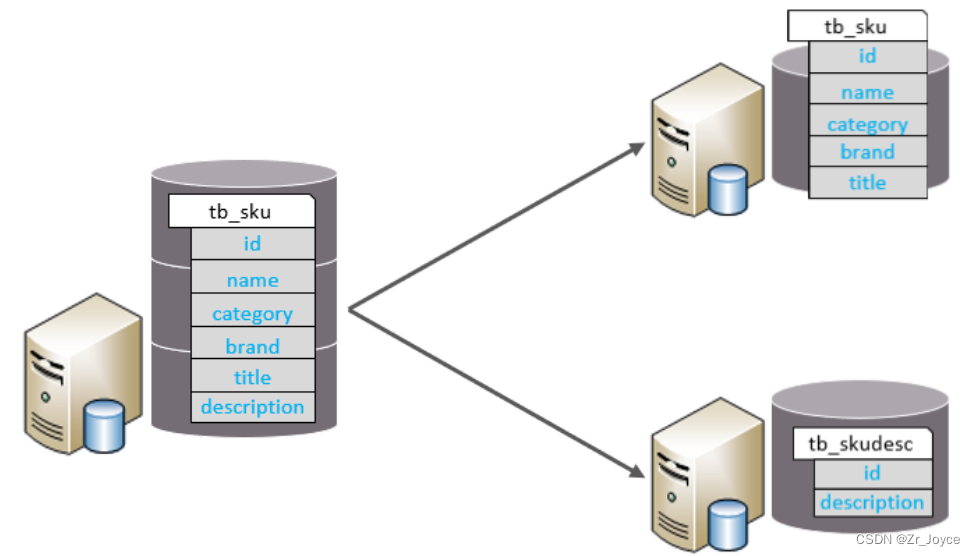
特点:
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
1.4水平拆分
1.4.1水平分库
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。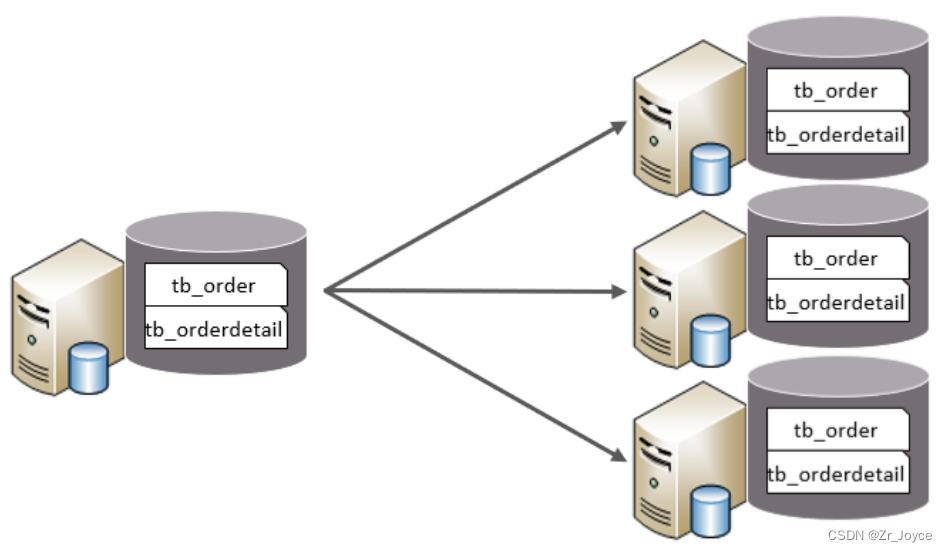
特点:
- 每个库的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全量数据。
1.4.2水平分表
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。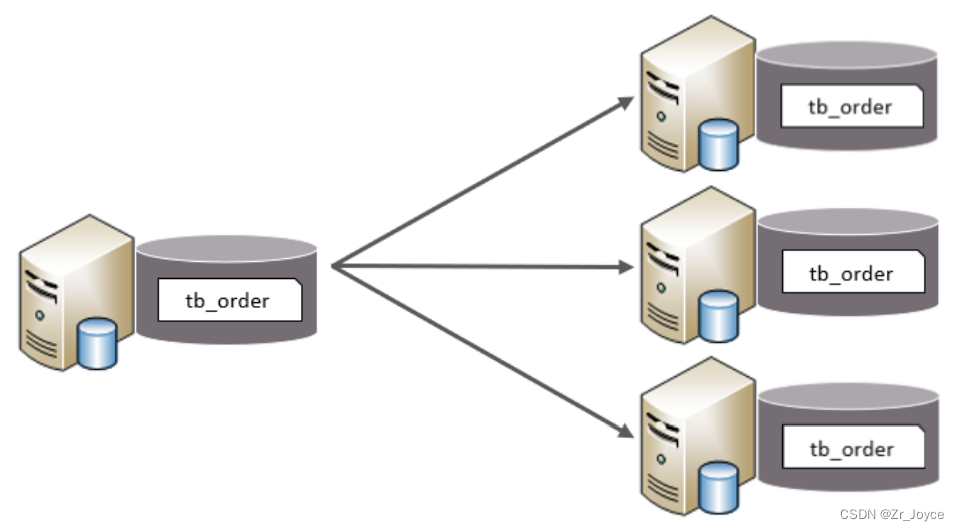
特点:
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
在业务系统中,为了缓解磁盘IO及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;
具体是分库,还是分表,都需要根据具体的业务需求具体分析。
1.5实现技术
- shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
- MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
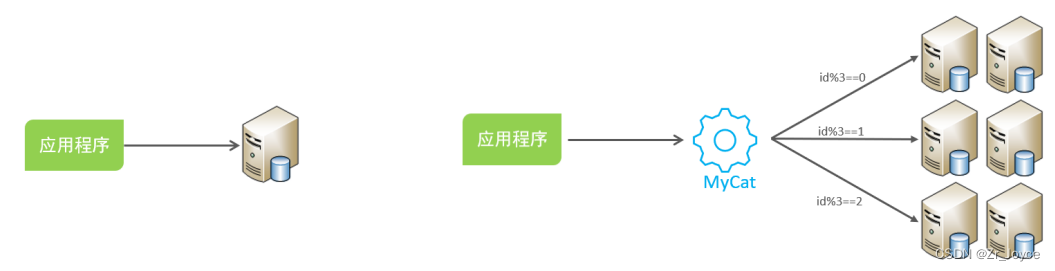
2、Mycat概述
2.1 介绍
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器里面存储了什么数据,都无需关心。 具体的分库分表的策略,只需要在MyCat中配置即可。
优势:
- 性能可靠稳定
- 强大的技术团队
- 体系完善
- 社区活跃
2.2 安装
Mycat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境,下面
MyCat在Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
- MySQL
- JDK
- Mycat
服务器
安装软件
说明
10.0.0.201 JDK、Mycat MyCat中间件服务器 10.0.0.201 MySQL 分片服务器 10.0.0.209 MySQL 分片服务器 10.0.0.210 MySQL 分片服务器
2.3 mycat的目录介绍
- bin : 存放可执行文件,用于启动停止mycat
- conf: 存放mycat的配置文件
- lib: 存放mycat的项目依赖包(jar)
- logs: 存放mycat的日志文件
2.4 mycat 结构与概念
在MyCat的整体结构中,分为两个部分:上面的逻辑结构、下面的物理结构。

在MyCat的逻辑结构主要负责逻辑库、逻辑表、分片规则、分片节点等逻辑结构的处理,而具体的数据存储还是在物理结构,也就是数据库服务器中存储的。
3、Mycat入门
3.1 需求
由于 tb_order 表中数据量很大,磁盘IO及容量都到达了瓶颈,现在需要对 tb_order 表进行数据分片,分为三个数据节点,每一个节点主机位于不同的服务器上, 具体的结构,参考下图:
3.2 环境准备
准备3台服务器:
- 192.168.200.210:MyCat中间件服务器,同时也是第一个分片服务器。
- 192.168.200.213:第二个分片服务器。
- 192.168.200.214:第三个分片服务器。
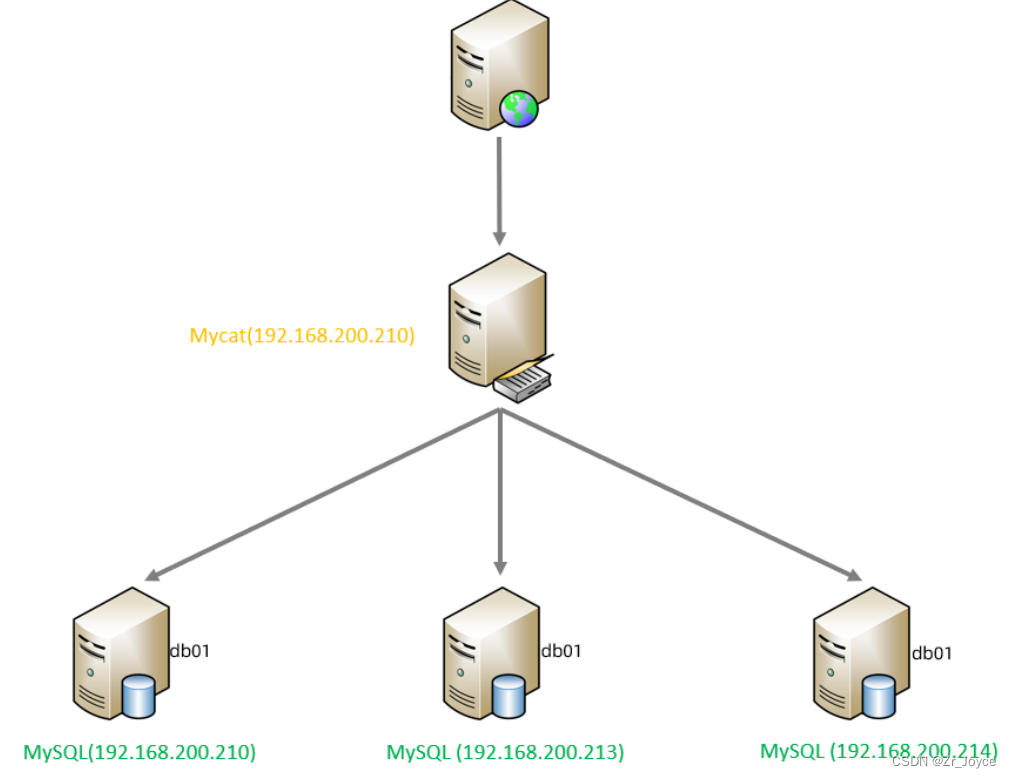
并且在上述3台数据库中创建数据库 db01 。
3.3.3 配置
1). schema.xml
在schema.xml中配置逻辑库、逻辑表、数据节点、节点主机等相关信息。具体的配置如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100">
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://10.0.0.201:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="110420" />
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://10.0.0.209:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="110420" />
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://10.0.0.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="110420" />
</dataHost>
</mycat:schema>2). server.xml
需要在server.xml中配置用户名、密码,以及用户的访问权限信息,具体的配置如下:
<user name="root" defaultAccount="true">
<property name="password">110420</property>
<property name="schemas">DB01</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110" >
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">110420</property>
<property name="schemas">DB01</property>
<property name="readOnly">true</property>
</user>
</mycat:server> 上述的配置表示,定义了两个用户 root 和 user ,这两个用户都可以访问 DB01 这个逻辑库,访问密码都是110420,
但是root用户访问DB01逻辑库,既可以读,又可以写,但是user用户访问DB01逻辑库是只读的。
3.3.4 测试
3.3.4.1 启动
配置完毕后,先启动涉及到的3台分片服务器,然后启动MyCat服务器。切换到Mycat的安装目录,执行如下指令,启动Mycat:
#启动
bin/mycat start
#停止
bin/mycat stopMycat启动之后,占用端口号 8066
3.3.4.2 测试
1). 连接MyCat
通过如下指令,就可以连接并登陆MyCat。
mysql -h 10.0.0.201 -P 8066 -uroot -p110420 2). 数据测试
然后就可以在MyCat中来创建表,并往表结构中插入数据,查看数据在MySQL中的分布情况。
创建表结构:
CREATE TABLE TB_ORDER (
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ;
插入数据:
INSERT INTO TB_ORDER(id,title) VALUES(1,'goods1');
INSERT INTO TB_ORDER(id,title) VALUES(2,'goods2');
INSERT INTO TB_ORDER(id,title) VALUES(3,'goods3');
INSERT INTO TB_ORDER(id,title) VALUES(5000001,'goods5000001');
INSERT INTO TB_ORDER(id,title) VALUES(10000000,'goods10000000');
INSERT INTO TB_ORDER(id,title) VALUES(10000001,'goods10000001');
INSERT INTO TB_ORDER(id,title) VALUES(15000000,'goods15000000');
INSERT INTO TB_ORDER(id,title) VALUES(15000001,'goods15000001');经过测试,我们发现,在往 TB_ORDER 表中插入数据时:
- 如果id的值在1-500w之间,数据将会存储在第一个分片数据库中。
- 如果id的值在500w-1000w之间,数据将会存储在第二个分片数据库中。
- 如果id的值在1000w-1500w之间,数据将会存储在第三个分片数据库中。
- 如果id的值超出1500w,在插入数据时,将会报错。
为什么会出现这种现象,数据到底落在哪一个分片服务器到底是如何决定的呢? 这是由逻辑表配置时
的一个参数 rule 决定的,而这个参数配置的就是分片规则。
4、Mycat配置
4.1 schema.xml
schema.xml 作为MyCat中最重要的配置文件之一 , 涵盖了MyCat的逻辑库 、 逻辑表 、 分片规则、分片节点及数据源的配置。
主要包含以下三组标签:
- schema标签
- datanode标签
- datahost标签
4.1.1 schema标签
1). schema 定义逻辑库
schema 标签用于定义 MyCat实例中的逻辑库, 一个MyCat实例中, 可以有多个逻辑库 , 可以通过 schema 标签来划分不同的逻辑库。
MyCat中的逻辑库的概念,等同于MySQL中的database概念,需要操作某个逻辑库下的表时, 也需要切换逻辑库(use xxx)。
核心属性:
- name:指定自定义的逻辑库库名
- checkSQLschema:在SQL语句操作时指定了数据库名称,执行时是否自动去除;true:自动去除,false:不自动去除
- sqlMaxLimit:如果未指定limit进行查询,列表查询模式查询多少条记录
2). schema 中的table定义逻辑表
table 标签定义了MyCat中逻辑库schema下的逻辑表 , 所有需要拆分的表都需要在table标签中定义 。
核心属性:
- name: 定义逻辑表表名,在该逻辑库下唯一
- dataNode: 定义逻辑表所属的dataNode,该属性需要与dataNode标签中name对应;多个dataNode逗号分隔
- rule: 分片规则的名字,分片规则名字是在rule.xml中定义的
- primaryKey:逻辑表对应真实表的主键
- type: 逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,就是普通表;全局表,配置为 global
4.1.2 datanode标签
核心属性:
- name:定义数据节点名称
- dataHost:数据库实例主机名称,引用自 dataHost 标签中name属性
- database:定义分片所属数据库
4.1.3 datahost标签
该标签在MyCat逻辑库中作为底层标签存在, 直接定义了具体的数据库实例、读写分离、心跳语句。
核心属性:
- name: 唯一标识,供上层标签使用
- maxCon/minCon 最大连接数/最小连接数
- balance: 负载均衡策略,取值 0,1,2,3
- writeType: 写操作分发方式(0:写操作转发到第一个writeHost,第一个挂了,切换到第二个;1:写操作随机分发到配置的writeHost)
- dbDriver: 数据库驱动,支持 native、jdbc
4.2 rule.xml
rule.xml中定义所有拆分表的规则, 在使用过程中可以灵活的使用分片算法, 或者对同一个分片算法使用不同的参数, 它让分片过程可配置化。主要包含两类标签:tableRule、Function。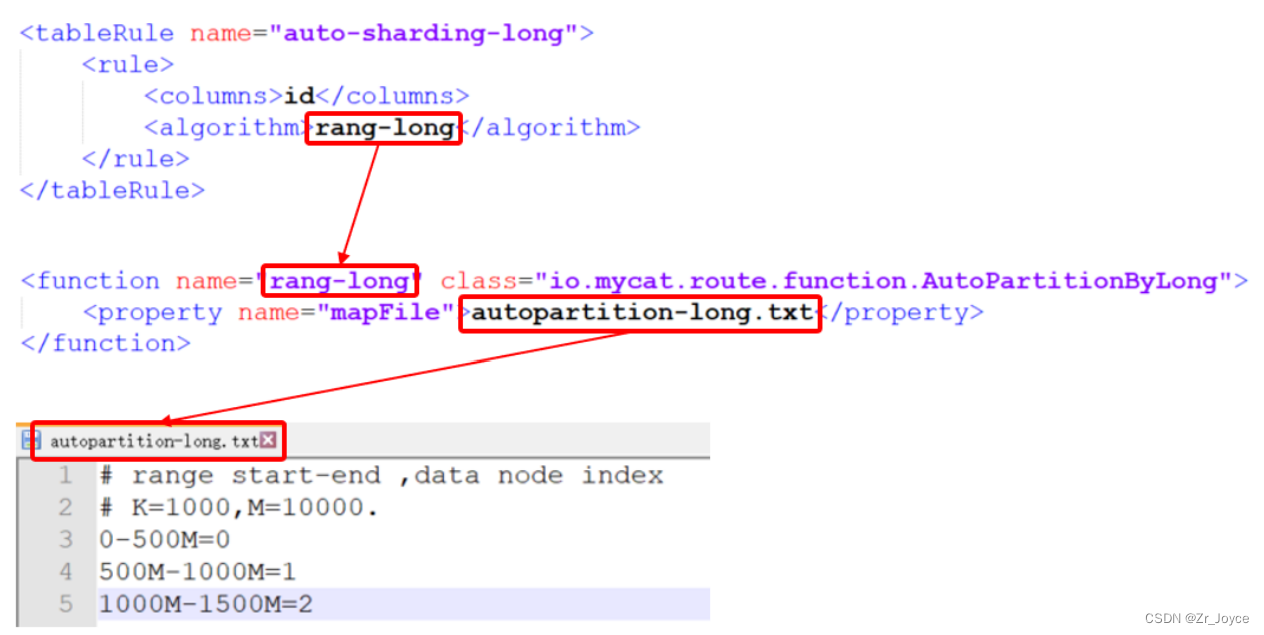
4.3 server.xml
server.xml配置文件包含了MyCat的系统配置信息,主要有两个重要的标签:system、user。
1). system标签
主要配置MyCat中的系统配置信息,对应的系统配置项及其含义,如下:
属性 | 取值 | 含义 |
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin 0,1 | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ; 开启之后, MyCat会自动统计SQL语句的执行 情况 ; mysql -h 127.0.0.1 -P 9066 -u root -p 查看MyCat执行的SQL, 执行 效率比较低的SQL , SQL的整体执行情况、读 写比例等 ; show @@sql ; show @@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0 为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文 件,1 为数据库方式,2 为时间戳列方式,默 认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ或者 mycatseq进入序列 匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字 段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开 启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB 的SQL解析器, 在MyCat1.3后增加了Druid 解析器, 所以要设置defaultSqlParser属 性来指定默认的解析器; 解析器有两个 : druidparser 和 fdbparser, 在 MyCat1.4之后,默认是druidparser, fdbparser已经废除了 | |
| processors | 1,2.... | 指定系统可用的线程数量, 默认值为CPU核心 x 每个核心运行线程数量; processors 会 影响processorBufferPool, processorBufferLocalPercent, processorExecutor属性, 所有, 在性能 调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认 值为4096字节, 也会影响BufferPool长度, 如果一次性获取字节过多而导致buffer不够 用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享 businessExecutor固定线程池的大小; MyCat把异步任务交给 businessExecutor 线程池中, 在新版本的MyCat中这个连接池使 用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将 关闭资源并回收, 默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为 REPEATED_READ , 对应数字为3 READ_UNCOMMITED=1; READ_COMMITTED=2; REPEATED_READ=3; SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时, 将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的使用端口, 默认9066 |
2). user标签
配置MyCat中的用户、访问密码,以及用户针对于逻辑库、逻辑表的权限信息,具体的权限描述方式及配置说明如下:
在测试权限操作时,我们只需要将 privileges 标签的注释放开。 在 privileges 下的schema标签中配置的dml属性配置的是逻辑库的权限。
在privileges的schema下的table标签的dml属性中配置逻辑表的权限。
5、Mycat分片规则
1.垂直分库
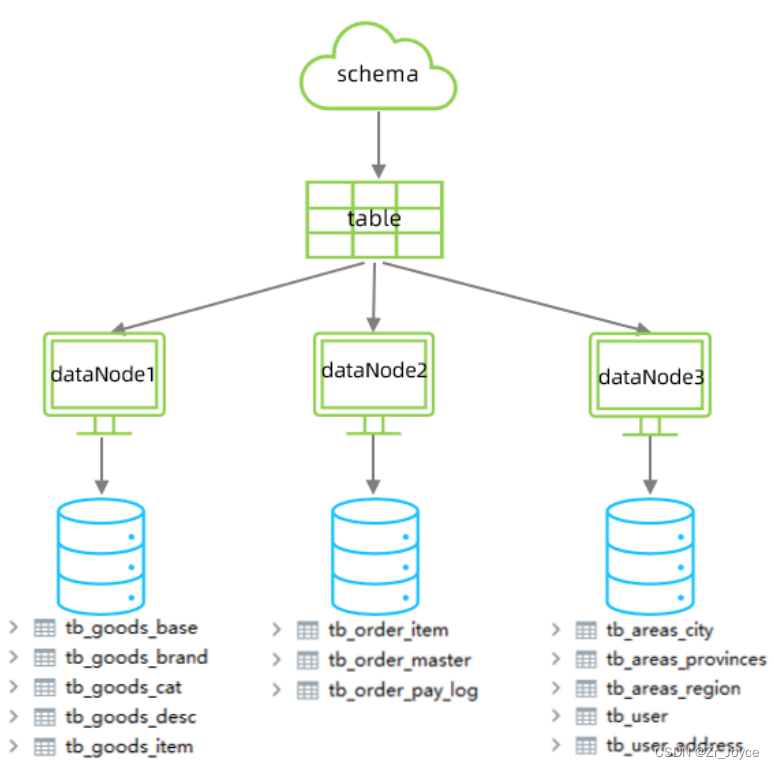
在业务系统中, 涉及以下表结构 ,但是由于用户与订单每天都会产生大量的数据, 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下。
现在考虑将其进行垂直分库操作,将商品相关的表拆分到一个数据库服务器,订单表拆分的一个数据库服务器,用户及省市区表拆分到一个服务器。
最终结构如下:
导入数据并查看表结构
查询用户的收件人及收件人地址信息(包含省、市、区)
select ua.user_id, ua.contact, p.province, c.city, r.area , ua.address fromtb_user_address ua,tb_areas_city c , tb_areas_provinces p ,tb_areas_region rwhere ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id =r.areaid ;成功
查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o, tb_areas_provinces p ,
tb_areas_city c , tb_areas_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND
o.receiver_region = r.areaid ;
失败,因为MyCat在执行该SQL语句时,需要往具体的数据库服务器中路由,而当前没有一个数据库服务器完全包含了订单以及省市区的表结构,造成SQL语句
使用全局表解决:
对于省、市、区/县表tb_areas_provinces , tb_areas_city , tb_areas_region,是属于数据字典表,在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。修改schema.xml中的逻辑表的配置,修改 tb_areas_provinces、tb_areas_city、tb_areas_region 三个逻辑表,增加 type 属性,配置为global,就代表该表是全局表,就会在所涉及到的dataNode中创建给表。对于当前配置来说,也就意味着所有的节点中都有该表了。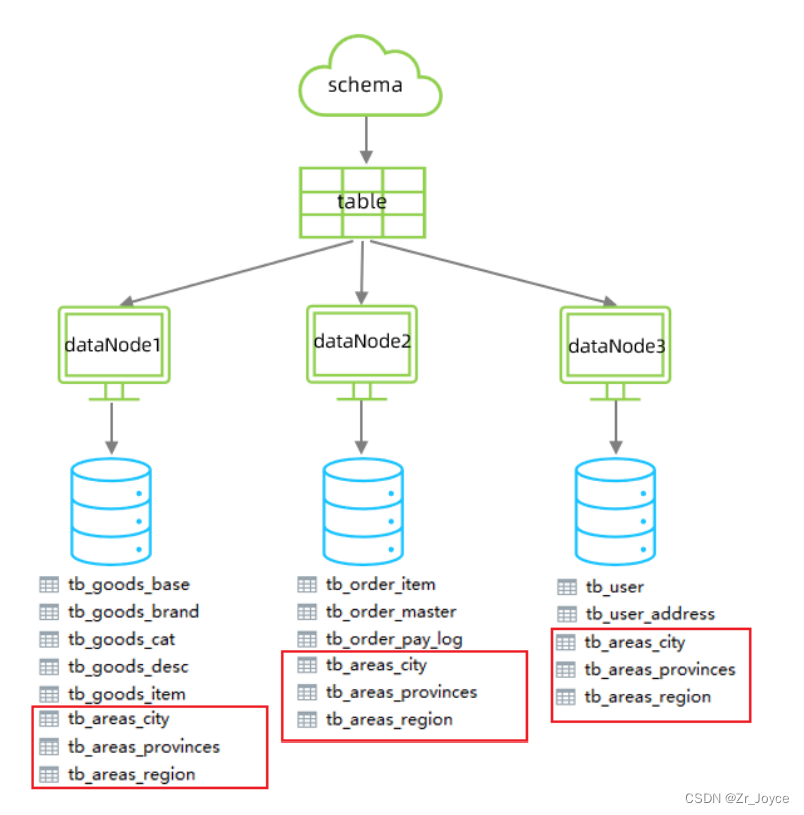
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>配置完成后重新启动mycat服务并重复sql语句,成功执行
2.水平分表
在业务系统中, 有一张表(日志表), 业务系统每天都会产生大量的日志数据 , 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分。
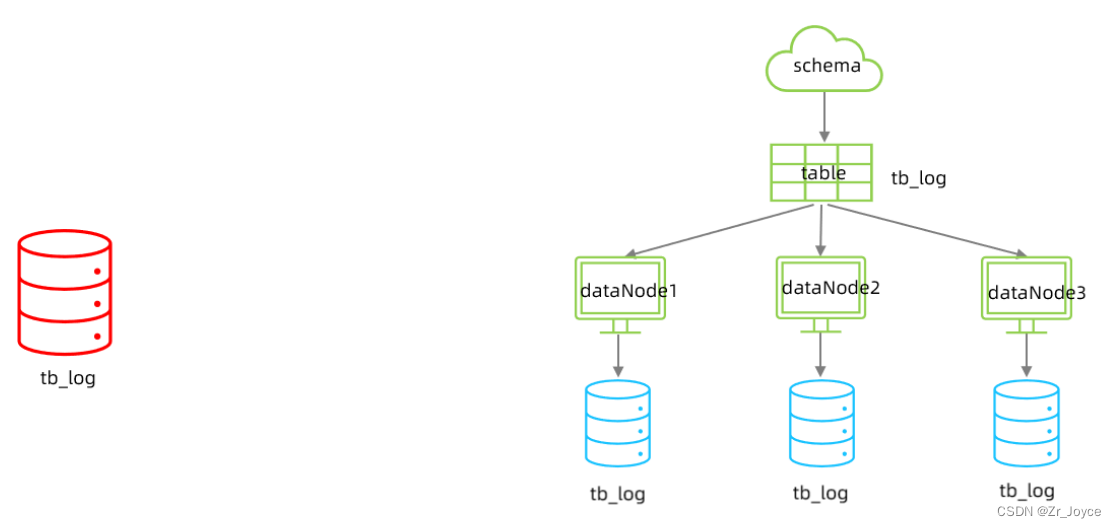
2.1 schema.xml
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />
</schema>
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
2.2 server.xml
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING,ITCAST</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110" >
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>3.分片规则:
3.1范围分片
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片。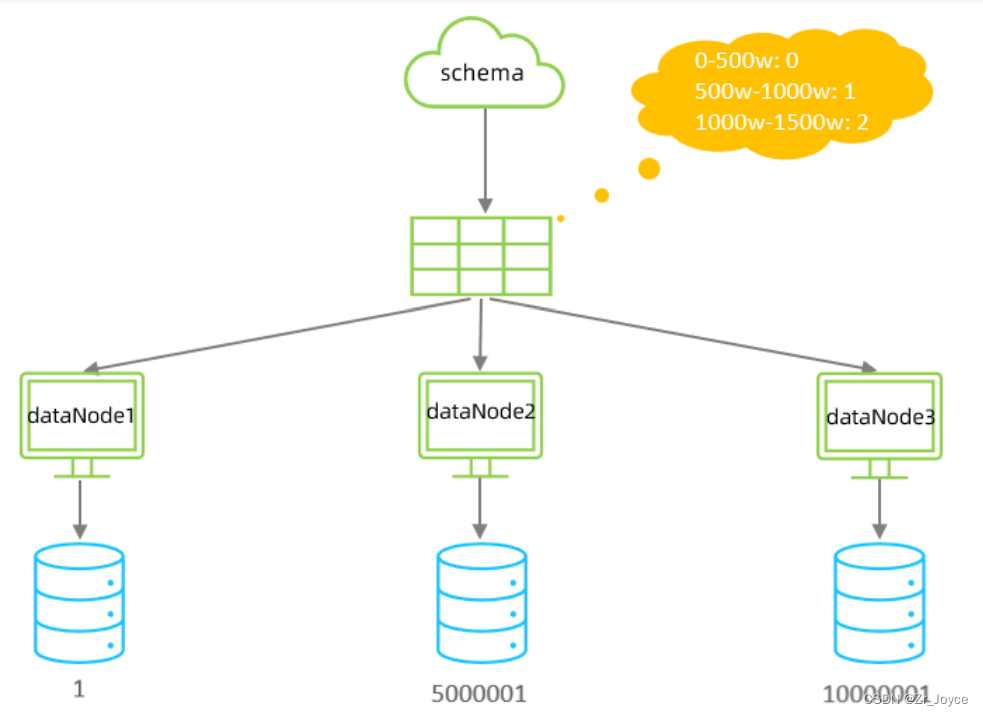
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
mapFile 对应的外部配置文件
type 默认值为0 ; 0 表示Integer , 1 表示String
defaultNode 默认节点 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。在rule.xml中配置分片规则时,关联了一个映射配置文件 autopartition-long.txt,该配置文件的配置如下:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2含义:0-500万之间的值,存储在0号数据节点(数据节点的索引从0开始) ; 500万-1000万之间的数据存储在1号数据节点 ; 1000万-1500万的数据节点存储在2号节点 ;
该分片规则,主要是针对于数字类型的字段适用
3.2取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果,来决定该数据属于哪一个分片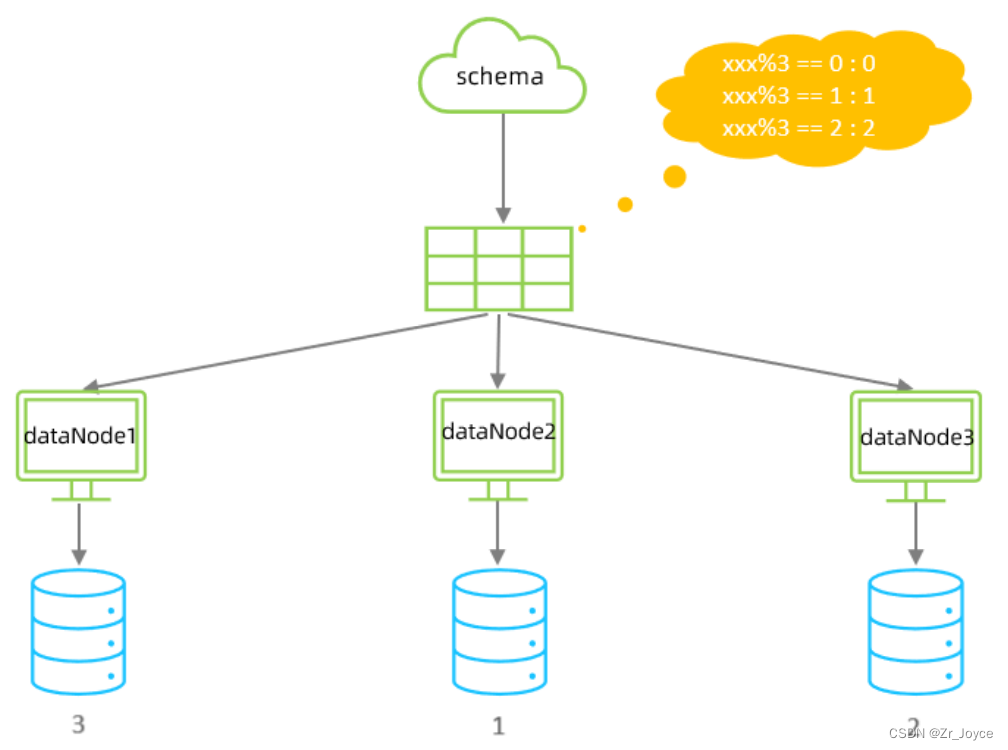
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
count 数据节点的数量该分片规则,主要是针对于数字类型的字段适用
3.3一致性hash算法
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置,有效的解决了分布式数据的拓容问题。
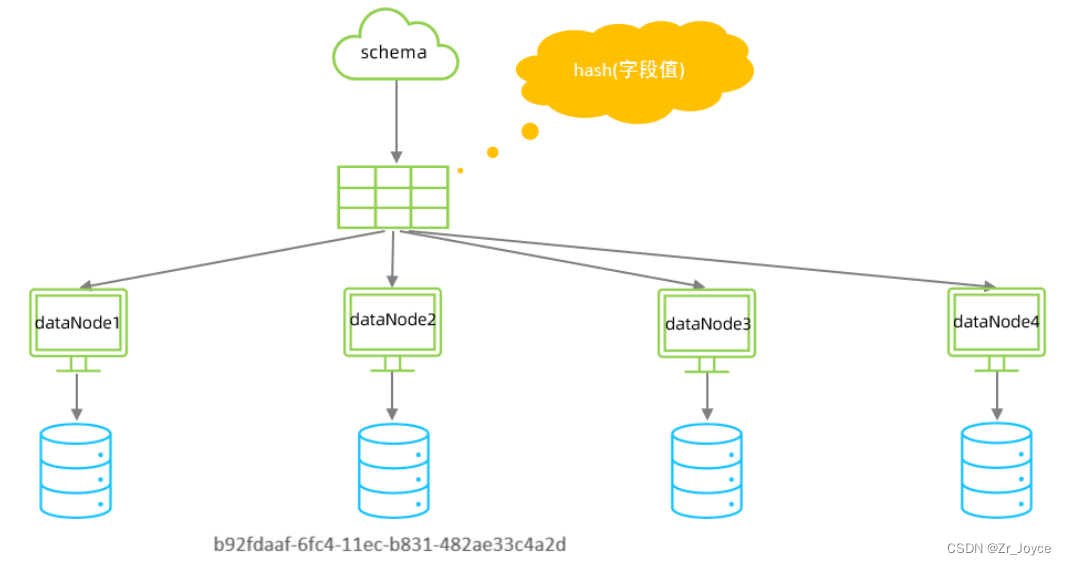
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
seed 创建murmur_hash对象的种子,默认0
count 要分片的数据库节点数量,必须指定,否则没法分片
virtualBucketTimes 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍;virtualBucketTimes*count就是虚拟结点数量 ;
weightMapFile 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替
bucketMapPath 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西3.4枚举分片
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 本规则适用于按照省份、性别、状态拆分数据等业务 。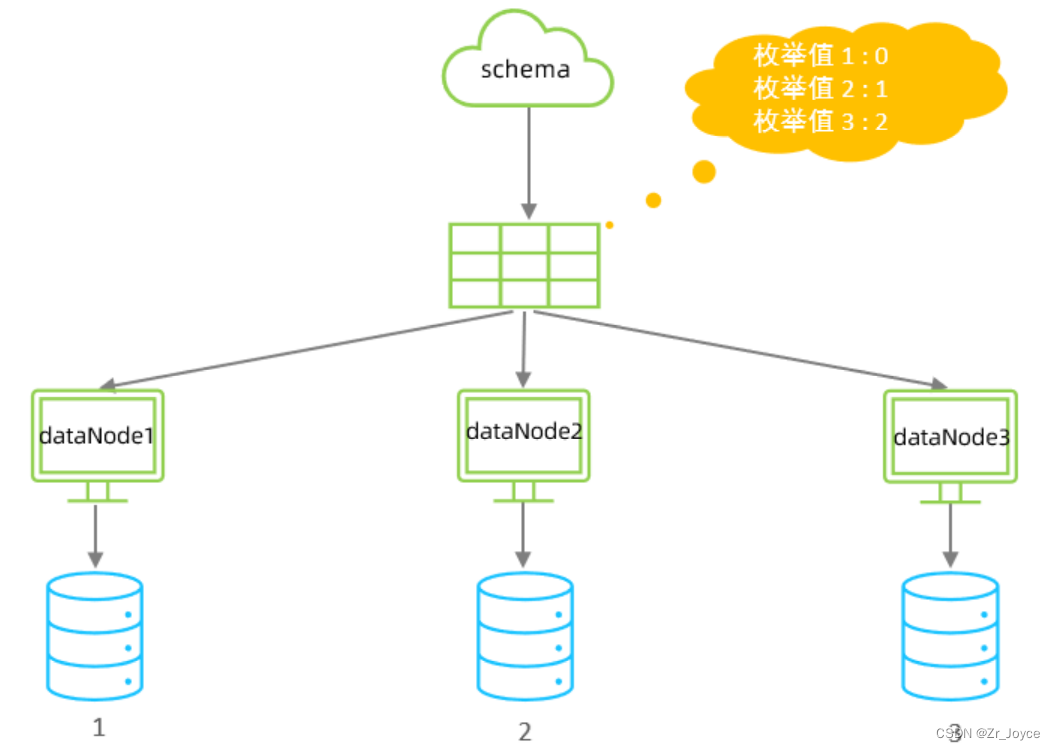
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
mapFile 对应的外部配置文件
type 默认值为0 ; 0 表示Integer , 1 表示String
defaultNode 默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ;默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。
3.5应用指定算法
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
startIndex 字符子串起始索引
size 字符长度
partitionCount 分区(分片)数量
defaultPartition默认分片(在分片数量定义时, 字符标示的分片编号不在分片数量内时,使用默认分片)
如:id=05-100000002 , 在此配置中代表根据id中从 startIndex=0,开始,截取siz=2位数字即05,05就是获取的分区,如果没找到对应的分片则默认分配到defaultPartition 。
3.6固定hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。
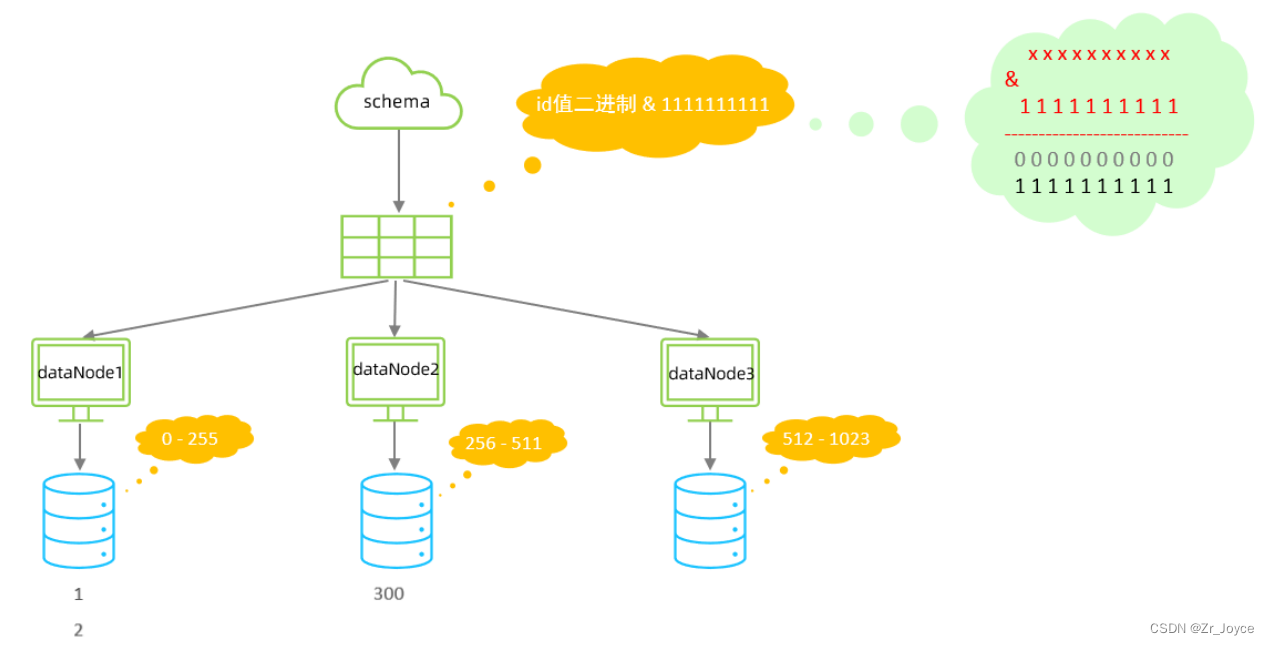
特点:
- 如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的
- 分片,降低事务处理的难度。
- 可以均匀分配,也可以非均匀分配。
- 分片字段必须为数字类型。
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
partitionCount 分区(分片)数量
partitionLength 分片范围列表约束 :
- 分片长度 : 默认最大2^10 , 为 1024 ;
- count, length的数组长度必须是一致的 ;
以上分为三个分区:0-255,256-511,512-1023
3.7字符串hash解析
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片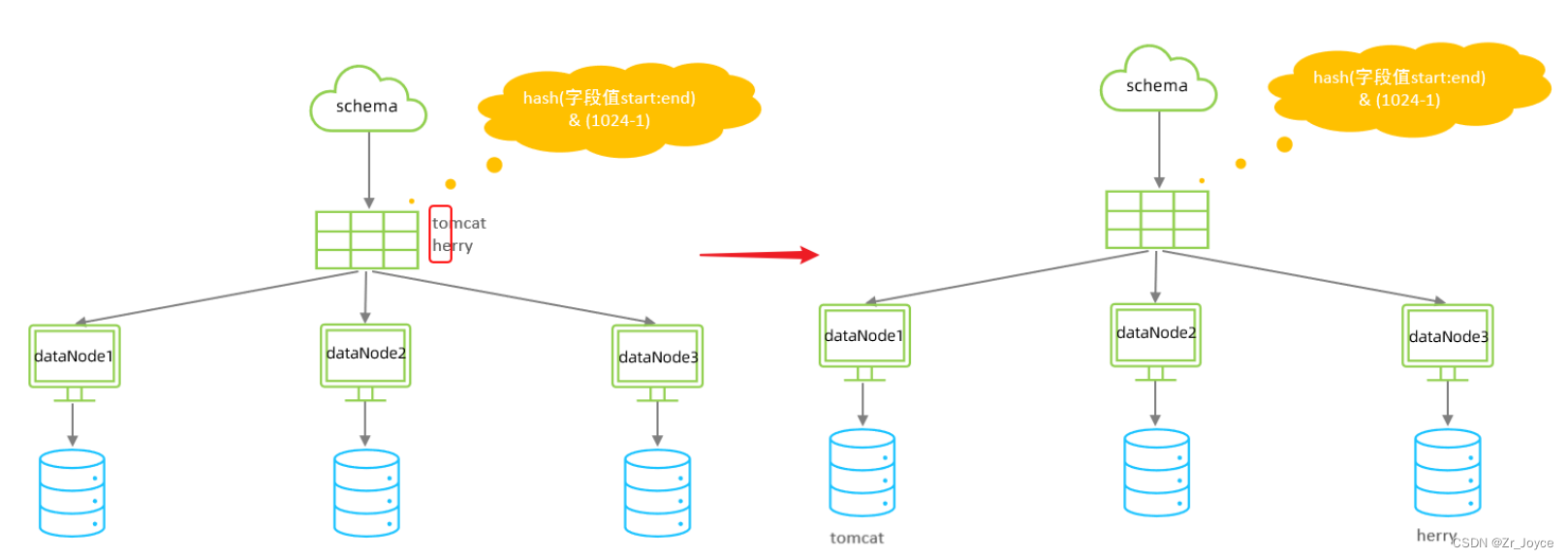
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
partitionCount 分区(分片)数量
partitionLength hash求模基数 ; length*count=1024 (出于性能考虑)
hashSlice hash运算位 ,根据子字符串的hash运算 ; 0代表 str.length(), -1代表 str.length()-1 ,大于0只代表数字自身 ;可以理解为substring(start,end),start为0则只表示0
3.8按天分片
按照日期及对应的时间周期来分片。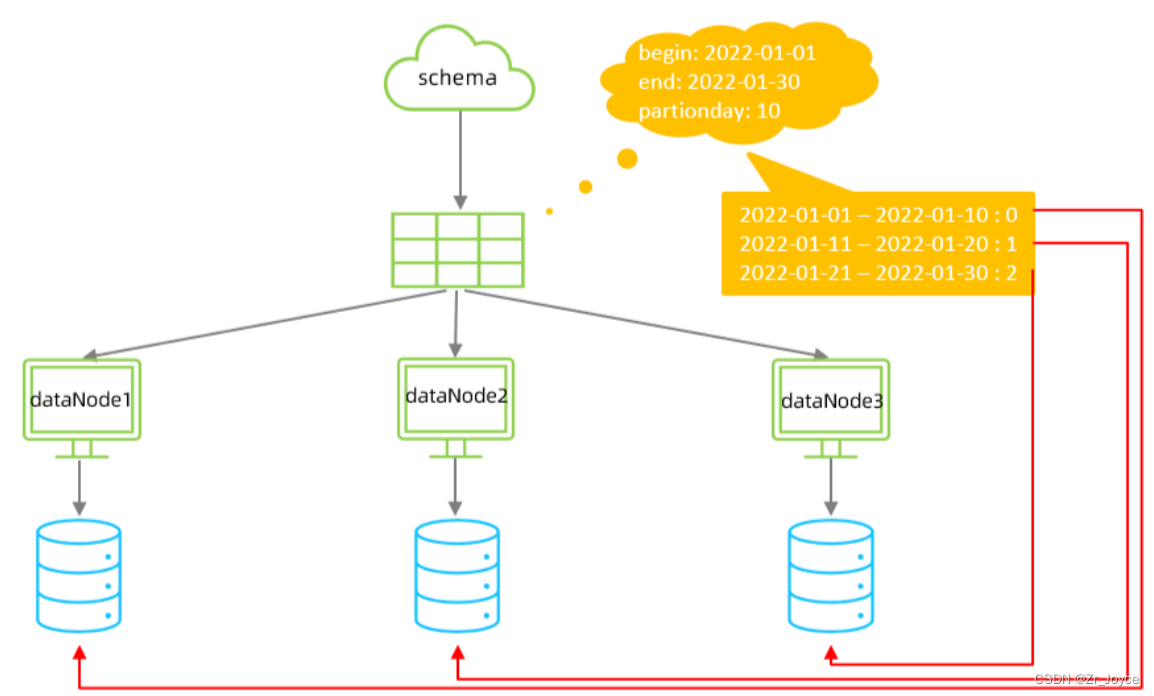
配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
dateFormat 日期格式
sBeginDate 开始日期
sEndDate 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
sPartionDay 分区天数,默认值 10 ,从开始日期算起,每个10天一个分区
3.9按自然月分片
使用场景为按照月份来分片, 每个自然月为一个分片。

配置属性的各种含义:
columns 标识将要分片的表字段
algorithm 指定分片函数与function的对应关系
class 指定该分片算法对应的类
dateFormat 日期格式
sBeginDate 开始日期
sEndDate 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
注意:以上规则我均未列出具体的schema.xml和rule.xml实现
6、Mycat管理及监控
四、读写分离
1、介绍
读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力。
通过MyCat即可轻易实现上述功能,不仅可以支持MySQL,也可以支持Oracle和SQL Server。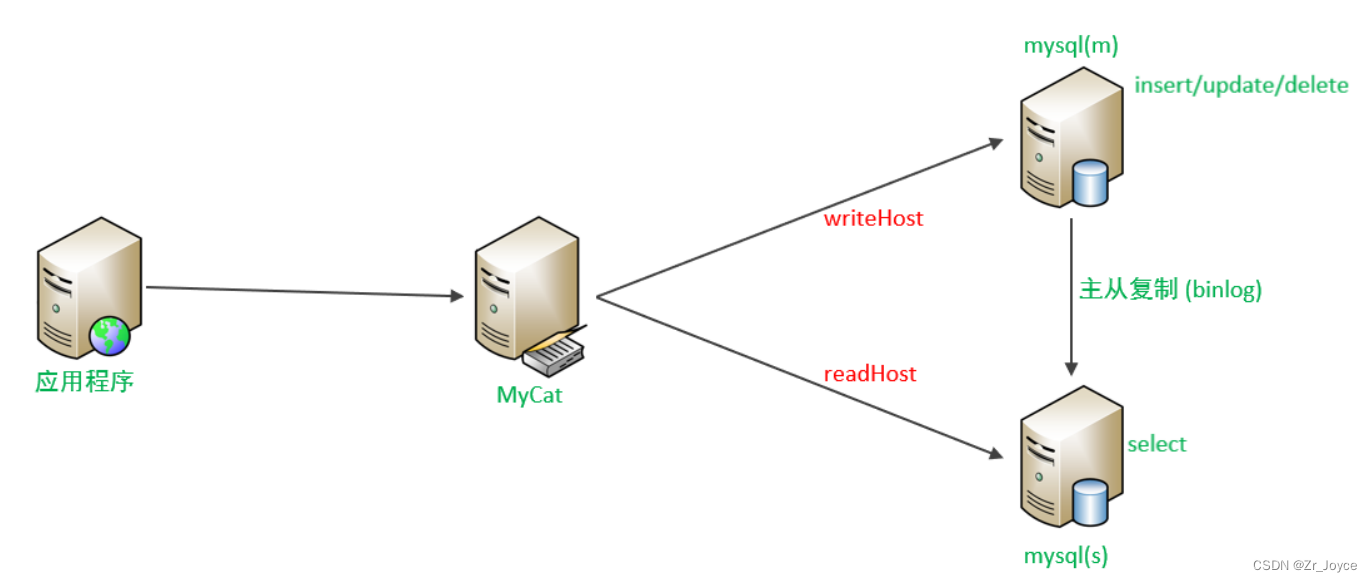
2、一主一从
MySQL的主从复制,是基于二进制日志(binlog)实现的。
 3、一主一从读写分离
3、一主一从读写分离
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控制。
3.1schema.xml配置
<!-- 配置逻辑库 -->
<schema name="ITCAST_RW" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema>
<dataNode name="dn7" dataHost="dhost7" database="itcast" />
<dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0"dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" >
<readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</writeHost>
</dataHost>上述配置的具体关联对应情况如下:
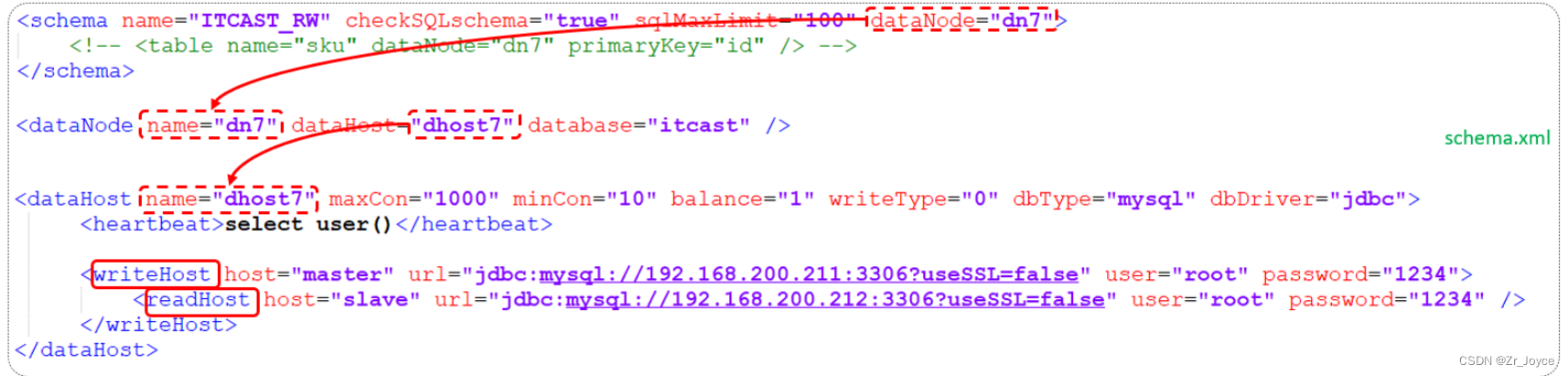
writeHost代表的是写操作对应的数据库,readHost代表的是读操作对应的数据库。 所以我们要想实现读写分离,就得配置writeHost关联的是主库,readHost关联的是从库。而仅仅配置好了writeHost以及readHost还不能完成读写分离,还需要配置一个非常重要的负责均衡的参数 balance,取值有4种,具体含义如下:
- 0 不开启读写分离机制 , 所有读操作都发送到当前可用的writeHost上
- 1 全部的readHost 与 备用的writeHost 都参与select 语句的负载均衡(主要针对于双主双从模式)
- 2 所有的读写操作都随机在writeHost , readHost上分发
- 3 所有的读请求随机分发到writeHost对应的readHost上执行, writeHost不负担读压力
在一主一从模式的读写分离中,balance配置1或3都是可以完成读写分离的。
而在该模式下,如果主节点宕机,业务系统只能读而不能写,这个问题可以由双主双从来解决:
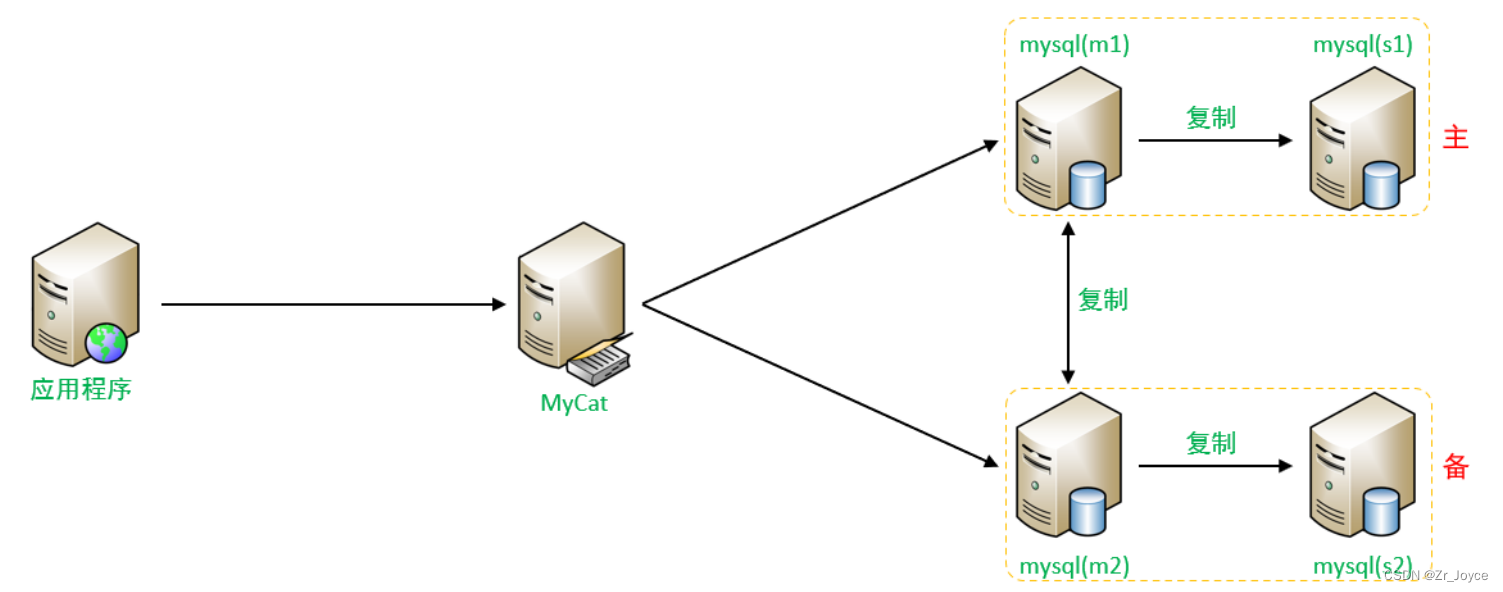
4、双主双从
一个主机 Master1 用于处理所有写请求,它的从机 Slave1 和另一台主机 Master2 还有它的从机 Slave2 负责所有读请求。
当 Master1 主机宕机后,Master2 主机负责写请求,Master1 、Master2 互为备机。架构图如下:
5、双主双从读写分离
MyCat控制后台数据库的读写分离和负载均衡由schema.xml文件datahost标签的balance属性控制,通过writeType及switchType来完成失败自动切换的。
1)schema.xml
配置逻辑库:
<schema name="ITCAST_RW2" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema>
配置数据节点:
<dataNode name="dn7" dataHost="dhost7" database="db01" />
配置节点主机:
<dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" >
<readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</writeHost>
<writeHost host="master2" url="jdbc:mysql://192.168.200.213:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" >
<readHost host="slave2" url="jdbc:mysql://192.168.200.214:3306?
useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8"
user="root" password="1234" />
</writeHost>
</dataHost>属性说明:
balance="1"
代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡 ;
writeType
- 0 : 写操作都转发到第1台writeHost, writeHost1挂了, 会切换到writeHost2上;
- 1 : 所有的写操作都随机地发送到配置的writeHost上 ;
switchType
- -1 : 不自动切换
- 1 : 自动切换
2)user.xml
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING,ITCAST,ITCAST_RW2</property>