大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程。本文主要介绍关键词抽取样例数据、GRU模型模型构建与训练、命名实体识别(NER)、模型评估与应用,项目的目标是通过训练一个GRU模型来实现准确和鲁棒的关键词抽取,并通过集成NER模型提高关键词抽取的效果。这个项目提供了一个完整的流程,可以根据实际需求进行调整和扩展。
目录:
1.GRU模型介绍
2.NER方式提取关键词
3.NER方式的代码实现
4.总结
1.GRU模型介绍
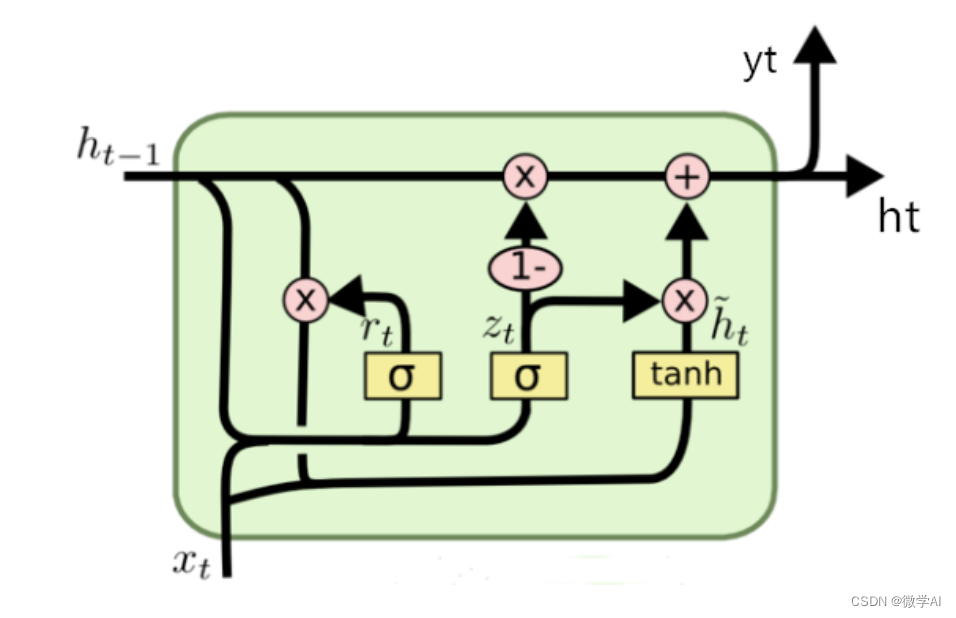
GRU是一种递归神经网络的变种,用于处理序列数据的建模任务。与传统的RNN结构相比,GRU引入了门控机制,以解决长期依赖问题,并减轻了梯度消失和爆炸问题。
GRU模型的主要组成部分包括:
1.输入门(Input Gate):决定了输入信息中有哪些部分需要被更新到隐藏状态。它通过一个sigmoid函数将输入数据与先前的隐藏状态进行组合,输出一个介于0和1之间的值,表示更新的权重。
2.更新门(Update Gate):控制是否更新隐藏状态的值。它通过一个sigmoid函数评估当前输入和先前隐藏状态,以确定是否将新信息与之前的隐藏状态进行组合。
3.重置门(Reset Gate):评估当前输入和先前隐藏状态,决定隐藏状态中要保留的信息和要忽略的信息。该门可以通过一个sigmoid函数和一个tanh函数获得两个不同的输出,然后将它们相乘,得到最终的重置门结果。
4.隐藏状态(Hidden State):用于存储序列中的信息,并在每个时间步传递和更新。隐藏状态根据输入和先前的隐藏状态进行更新。通过使用输入门和重置门对先前隐藏状态进行加权组合,然后使用tanh函数得到新的候选隐藏状态。最后,更新门确定如何将新的候选隐藏状态与先前的隐藏状态进行组合来获得最终的隐藏状态。
GRU模型在序列建模任务中具有以下优势:
处理长期依赖:GRU模型通过使用门控机制可以选择性地更新和保留序列中的信息,从而更好地处理长期依赖关系。
减轻梯度问题:由于门控机制的存在,GRU模型能够有效地减轻梯度消失和梯度爆炸等问题,提高模型的训练效果和稳定性。
参数较少:相比长短时记忆网络(LSTM),GRU模型的参数更少,更容易训练和调整。
2.NER方式提取关键词
NER可以用于关键词抽取,通过识别文本中的命名实体,从中提取出关键词。与传统的关键词抽取方法相比,NER具有以下优势:
1.精确性:NER可以准确定位文本中的具体实体,提供更精确的关键词抽取结果。
2.上下文理解:NER不仅仅是简单地提取词语,还能够根据上下文理解实体的含义,提高关键词抽取的准确性。
3.适应多领域:由于NER对上下文的理解能力,它可以用于不同领域的关键词抽取,如新闻、医学、法律等。
NER的工作流程通常包括以下步骤:
1.数据准备:收集并准备标注好的训练数据,其中标注好的数据应包含实体的起始位置和对应的标签。
2.特征提取:从文本中选择适当的特征来表示实体,如词性、上下文等。这些特征通常用于训练模型。
3.模型训练:使用标注好的训练数据,训练一个机器学习模型,如条件随机场(Conditional Random Field, CRF)、循环神经网络(Recurrent Neural Networks, RNN)等。
4.标注预测:使用训练好的模型,对新的文本进行预测,并标注出实体的位置和类别。
5.后处理:根据任务需求,对NER的结果进行后处理,如过滤掉不相关的实体、合并相邻的实体等。
6.关键词抽取:从提取出的实体中,选择具有关键意义的实体作为关键词。
3.NER方式的代码实现
import torch
import torch.nn as nn
from torch.optim import Adam
# 定义模型
class KeywordExtractor(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(KeywordExtractor, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, input):
embedded = self.embedding(input)
output, hidden = self.gru(embedded)
output = self.linear(output.view(-1, self.hidden_size))
return output.view(len(input), -1, output.size(1))
# 准备训练数据
train_data = [
("我 爱 北京", ["O", "O", "B-LOC"]),
("张三 是 中国 人", ["B-PER", "O", "B-LOC", "O"]),
("李四 是 美国 人", ["B-PER", "O", "B-LOC", "O"]),
("我 来自 北京", ["O", "O", "B-LOC"]),
("我 来自 广州", ["O", "O", "B-LOC"]),
("王五 去 英国 玩", ["B-PER", "O", "B-LOC", "O"]),
("我 喜欢 上海", ["O", "O", "B-LOC"]),
("刘东 是 北京 人", ["B-PER", "O", "B-LOC", "O"]),
("李明 来自 深圳", ["B-PER", "O", "B-LOC"]),
("我 计划 去 香港 旅行", ["O", "O","O", "B-LOC", "O"]),
("你 想去 法国 吗", ["O", "O", "B-LOC", "O"]),
("福州 是 你的 家乡 吗", ["B-LOC", "O", "O", "O", "O"]),
("张伟 和 王芳 一起 去 新加坡", ["B-PER", "O", "B-PER", "O", "O", "B-LOC"]),
# 其他训练样本...
]
# 构建词汇表
word2idx = {"<PAD>": 0, "<UNK>": 1}
tag2idx = {"O": 0, "B-LOC": 1, "B-PER":2}
for sentence, tags in train_data:
for word in sentence.split():
if word not in word2idx:
word2idx[word] = len(word2idx)
for tag in tags:
if tag not in tag2idx:
tag2idx[tag] = len(tag2idx)
idx2word = {idx: word for word, idx in word2idx.items()}
idx2tag = {idx: tag for tag, idx in tag2idx.items()}
# 超参数
input_size = len(word2idx)
output_size = len(tag2idx)
hidden_size = 128
num_epochs = 100
batch_size = 2
learning_rate = 0.001
# 实例化模型和损失函数
model = KeywordExtractor(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = Adam(model.parameters(), lr=learning_rate)
# 准备训练数据的序列张量和标签张量
def prepare_sequence(seq, to_idx):
idxs = [to_idx.get(token, to_idx["<UNK>"]) for token in seq.split()]
return torch.tensor(idxs, dtype=torch.long)
# 填充数据
def pad_sequences(data):
# 计算最长句子的长度
max_length = max(len(item[0].split()) for item in data)
aligned_data = []
for sentence, tags in data:
words = sentence.split()
word_s = words + ['O'] * (max_length - len(tags))
sentence = ' '.join(word_s)
aligned_tags = tags + ['O'] * (max_length - len(tags))
aligned_data.append((sentence, aligned_tags))
return aligned_data
# 训练模型
for epoch in range(num_epochs):
for i in range(0, len(train_data), batch_size):
batch_data = train_data[i:i + batch_size]
batch_data = pad_sequences(batch_data)
inputs = torch.stack([prepare_sequence(sentence, word2idx) for sentence, _ in batch_data])
targets = torch.LongTensor([tag2idx[tag] for _, tags in batch_data for tag in tags])
# 前向传播
outputs = model(inputs)
loss = criterion(outputs.view(-1, output_size), targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, len(train_data) // batch_size, loss.item()))
# 测试模型
test_sentence = "李明 想去 北京 游玩"
with torch.no_grad():
inputs = prepare_sequence(test_sentence, word2idx).unsqueeze(0)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 2)
tags = [idx2tag[idx.item()] for idx in predicted.squeeze()]
print('输入句子:', test_sentence)
print('关键词标签:', tags)
运行结果:
Epoch [99/100], Step [3/6], Loss: 0.0006
Epoch [99/100], Step [5/6], Loss: 0.0002
Epoch [99/100], Step [7/6], Loss: 0.0002
Epoch [99/100], Step [9/6], Loss: 0.0006
Epoch [99/100], Step [11/6], Loss: 0.0006
Epoch [99/100], Step [13/6], Loss: 0.0009
Epoch [100/100], Step [1/6], Loss: 0.0003
Epoch [100/100], Step [3/6], Loss: 0.0006
Epoch [100/100], Step [5/6], Loss: 0.0002
Epoch [100/100], Step [7/6], Loss: 0.0002
Epoch [100/100], Step [9/6], Loss: 0.0005
Epoch [100/100], Step [11/6], Loss: 0.0006
Epoch [100/100], Step [13/6], Loss: 0.0009
输入句子: 李明 想去 北京 游玩
关键词标签: ['B-PER', 'O', 'B-LOC', 'O']
4.总结
命名实体识别(NER)是自然语言处理中的一项技术,目的是从文本中识别和提取出具有特定意义的命名实体。这些命名实体可以是人名、地名、组织机构名、时间、日期等具有特定含义的词汇。
NER的任务是将文本中的每个词标注为预定义的命名实体类别,常见的类别有人名(PERSON)、地名(LOCATION)、组织机构名(ORGANIZATION)等。通过NER技术,可以提取出文本中的关键信息,帮助理解文本的含义和上下文。
NER的核心思想是结合机器学习和自然语言处理技术,利用训练好的模型对文本进行分析和处理。通常使用的方法包括基于规则的方法、统计方法和基于机器学习的方法。其中,基于机器学习的方法在大规模标注好的数据集上进行训练,通过学习识别命名实体的模式和规律,从而提高识别的准确性。
NER在实际应用中有广泛的应用场景,包括信息抽取、智能搜索、问答系统等。通过NER技术提取出的关键词可以被用于进一步的信息处理和分析,有助于提高对文本的理解和处理效果。
总之,命名实体识别(NER)是一项重要的自然语言处理技术,能够从文本中提取出具有特定含义的命名实体。它在各种应用场景中发挥着重要作用,为文本分析和信息提取提供了有力的支持。