map
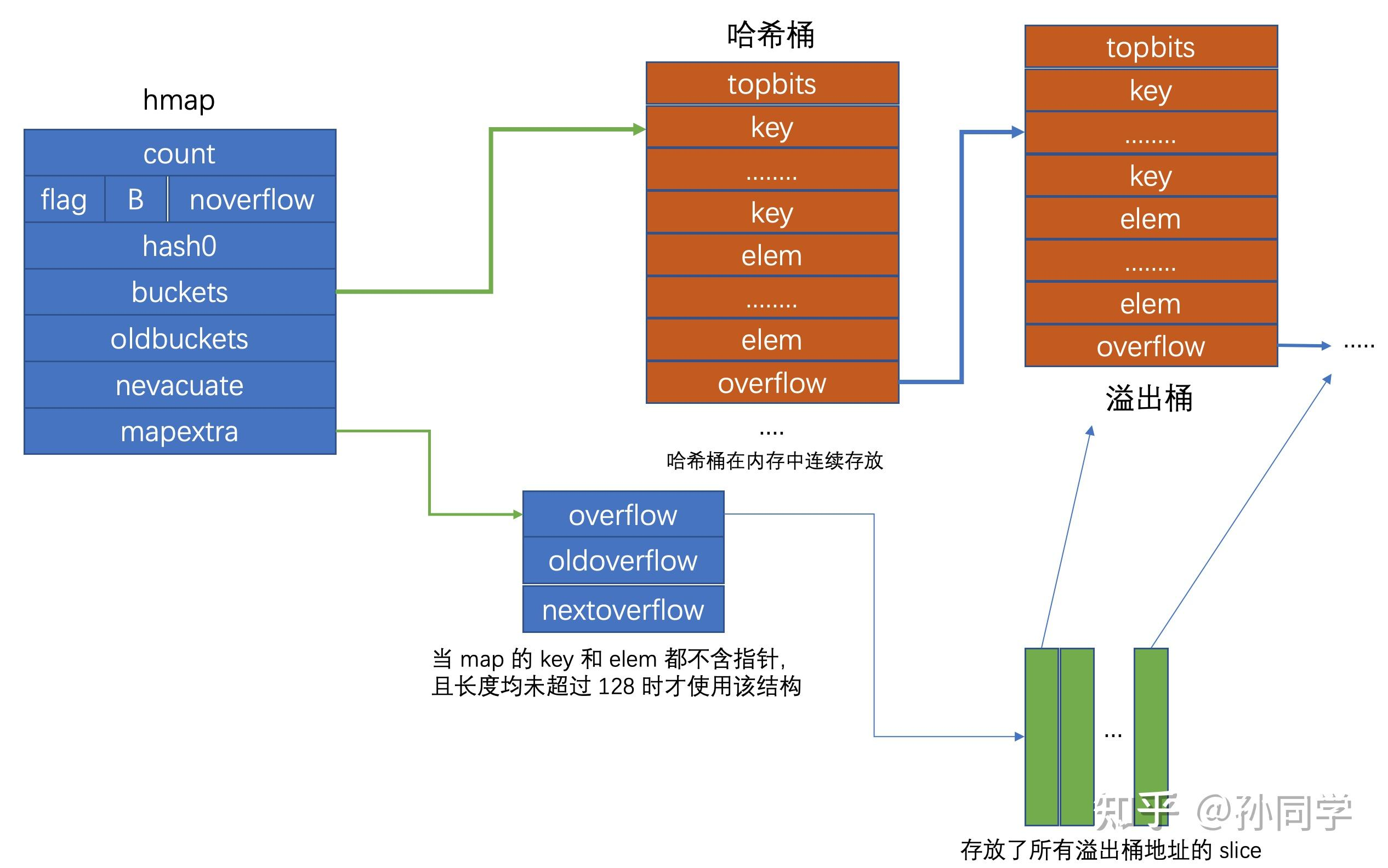
go map 的底层结构 hmap,的四个元素
然后再讲一下 buckets 的元素,讲一下 hash 冲突,和解决方法
再讲一下,增量扩容和等量扩容
再讲一下增删改查的过程,就查询过程
map 基础
向值为 nil 的 map 添加元素会发生 panic,说白了就是给声明但是没初始化的map添加元素
查询时候,如果没这个元素,会返回对应的零值,例如 int 的零值 0
一开始用 make 初始化时候,指定容量,可以有效的减少内存分配的次数,提升性能
查询语法if v, ok := m[“apple”];ok {}
删除语法:delete(m,“apple”) 空也不报错
添加和修改是一样的就是:m[“apple”] = “red”
len 也可以查长度
不是原子性的,并发不安全,多个协程同时操作一个 map 会产生读写冲突,panic,不过可以通过加锁或者 sync.map 实现并发安全
实现原理
1、数据结构
使用 Hash 表作为底层实现,一个 Hash 表可以有多个 bucket,每个 bucket 保存了一个或多个键值对,像,redis 是默认一个,go 是6.5个,多了会扩容
我们常说的 hash 桶就是 bucket,
type Map struct {
Key *Type
Elem *Type
Bucket *Type
Hmap *Type
Hiter *Type
}
// hmap 简化版本
type hmap struct {
count int // 元素个数,kv个数
B uint8 // bucket 数组大小,其实就是 bmap
buckets unsafe.Pointer // 指针指向 bucket 数组,数组长 2 的 B 次方
oldbuckets unsafe.Pointer // 老旧 bucket 数组,用于扩容
......
}
type bmap struct {
tophash [bucketCnt]uint8 // 存储 hash 值的高 8 位,就是长度为 8 的整型数组
date []byte // kkkkkkvvvvvv数据,这样可以节省内存,避免了内存对齐
overflow *bmap // 溢出 bucket 的地址,指向了下一个 bucket 将冲突的键连接起来
}
2、hash 冲突
当两个或以上数量的键被 hash 到同一个 bucket 时候,我们称这些键发生了冲突
Go 使用了链地址法解决冲突
因为每个 bucket 可以存放八个键值对,当同一个 bucket 存放超过 8 个键值对时候就会创建一个 bucket,用类似链表的方式将 bucket 连接起来,使用 *bucket 指向溢出的那部分
3、负载因子
负载因子 = 键数量 / bucket 数量
负载因子过大过小都不好
-过小,空间利用率较小
-过大,冲突严重,存取效率低
当负载因子过大,需要申请更多的 bucket 并且对所有的键值对重新排列,使其均匀的分配在 bucket,这个过程叫 rehash
每个 hash 表对负载因子的容忍度大小不一样,go 6.5 因为go的 bucket 可以存八个,redis 是1个
4、扩容
扩容有增量扩容,和等量扩容,都是对于负载因子过大的情况,对 go 就是当一个 bucket 有7/8个元素时候
增量扩容:
会新建一个 bucket ,新的 bucket 大小是原来两倍,然后把旧的 bucket 数组中的数据逐渐的搬迁到新的 bucket 数组
不过可能出现一个情况,当有数亿个元素时候,考虑到一次性搬迁会有很大延时,所有 go 用逐级搬迁策略,就是每次访问 map 都会搬迁一下,两个键值对
那它是如何处理数组指针呢?就是让 hmap 中 oldbuckets 指针指向原 buckets 数组,然后申请新的 buckets 数组,长度为原来两倍,之后的迁移工作就是将 oldbuckets 元素逐渐搬迁到新的 buckets ,搬迁完毕就可以释放 oldbuckets 数组
等量扩容:
这个不扩容,甚至内存释放了一些,意思是,不扩容的情况下,实行了类似增量扩容中搬迁的动作
因为在某些情况下,极端情况,我们删除了一些元素,很多哈,导致最后的元素集中于一个 bucket ,而这个 bucket 有很多的溢出 bucket 桶,删除后这些桶都空了,这时候等量扩容,就是使得 bucket 数量不变,但是重新组织后的 overflow 的 Bucket 数量减少,节省了空间,提高了查询效率
5、查询
查询就是:根据键的 Hash 值确定一个 bucket ,查它看有没有该元素
查询:
根据 key 值计算 Hash 值
取 Hash 值低位与 hmap.B 取模确定 bucket 位置
取 Hash 值高位,在 tophash 数组查询,如果tophash[i]的hash值与计算的一样,就去获取 tophash[i] 的key值
当前 bucket 没找到就去溢出bucket找
如果当前处于搬迁中,优先从 oldbucket 找
那么添加删除都差不多了,就不赘述了
参考自:《Go 专家编程》