1、HTTP概述
1、什么是HTTP
超文本传输协议(Hyper Text Transfer Protocol,HTTP)
HTTP是一个基于请求与响应的、无状态的应用层协议,用于在两点之间传输超文本数据,常基于TCP/IP协议传输数据。
设计HTTP的初衷是为了提供一种发布和接收HTML页面的方法。
2、HTTP的特点
- 基于TCP/IP协议:连接可以保证安全可靠,但内容就无法保证安全隐私了。
- 基于请求响应模型:一次请求对应一次响应
- 无状态的:每次请求之间相互独立
3、HTTP的优缺点
优点:
- 简单:HTTP的报文格式是header+body,头部信息也是简单的key-value形式,易于解析
- 灵活且易于扩展:HTTP工作在应用层,下层可以随意变化。而且HTTP的请求方法、状态码、头字段等组成部分都可以自定义,即插即用
- 应用广泛且跨平台
缺点,都属于双刃剑:
- 无状态:
- 好处:服务器不需要保存每个HTTP连接的状态,减轻服务器的压力,把资源都用于提供服务
- 坏处:完成有关联性的操作时比较麻烦,可以用Cookie、Session解决,手动维护状态
- 明文传输
- 好处:方便解析、调试
- 坏处:容易被他人获取请求或响应的内容,不安全
HTTP最大的缺点就是不安全,体现在:
- 通信使用明文,不加密,内容可能被窃取
- 不会对通信双方的身份进行验证,可能访问到伪装的站点
- 无法验证报文的完整性、正确性,通信内容可能被篡改
HTTP的安全问题,在HTTPS上得到了解决,引入了SSL/TSL层,获得了极致的安全。
4、为什么有了TCP还需要HTTP
- 分层结构,TCP负责端到端的传输,HTTP专注于应用层的逻辑。上层服务不应该去强耦合底层协议,协议是会升级和淘汰的
- TCP已经负责了很多事情,再给它加字段加功能会导致TCP过于庞大,难以升级和维护
- 直接面向TCP开发网络应用,不利于专注于业务的开发,可能会深陷于协议的细节中
2、HTTP请求
1、HTTP请求报文组成
HTTP请求报文由4部分组成(请求行+请求头+请求空行+请求体)
下面是一个POST方法的请求报文:
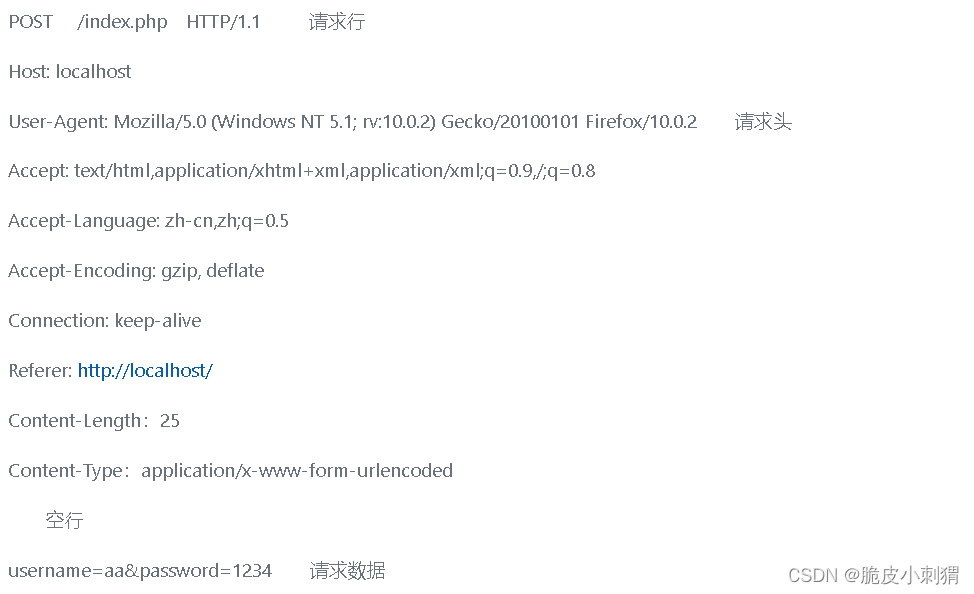
1、请求行
请求行分为三个部分:请求方法、请求地址URL和HTTP协议版本,它们之间用空格分割。例如,GET /index.html HTTP/1.1。
1、请求方法
HTTP/1.1 定义的请求方法有8种:

最常用的两种是GET和POST。
2、URL
URI:统一资源标识符,在网络上唯一标识一个资源
URL:统一资源定位符,是一种资源位置的抽象唯一识别方法。
组成:<协议>://<主机>:<端口>/<路径>
端口和路径有时可以省略(HTTP默认端口号是80)

URL是URI的子集,它不仅唯一标识的一个资源,还提供了对该资源的访问方式。
3、协议版本
协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1、HTTP/2、HTTP/3
2、请求头
请求头部为请求报文添加了一些附加信息,由键值对组成,每行一对,名和值之间使用冒号分隔。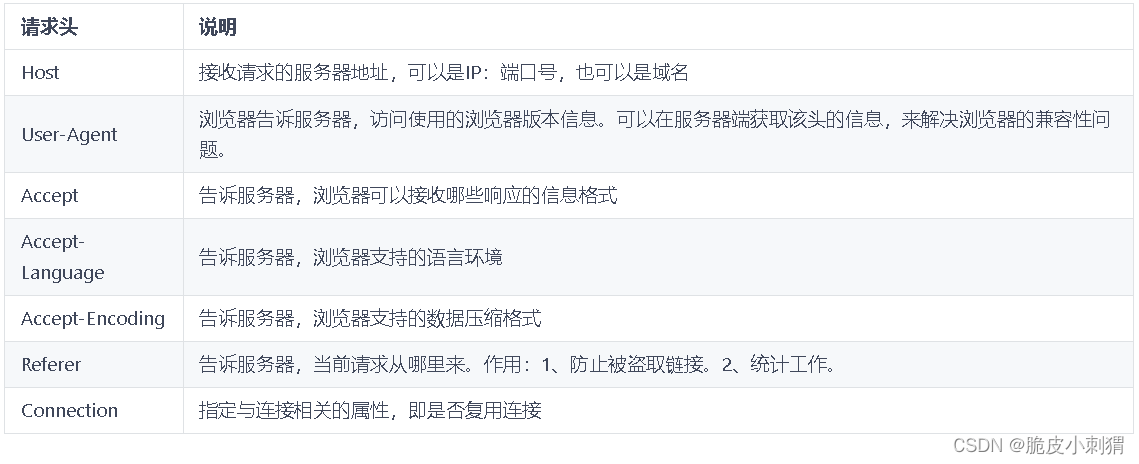
3、请求空行
请求头部的最后会有一个空行,表示请求头部结束,接下来为请求数据。
4、请求体
请求数据不在GET方法中使用,而在POST方法中使用。POST方法适用于需要客户填写表单的场合。
与请求数据相关的最常使用的请求头部是Content-Type和Content-Length。
2、GET与POST
1、两者的区别
GET
-
GET的含义是,从服务器获取指定的资源,要求服务器将目标资源放在响应报文的数据部分发送给客户端。
-
GET方式的请求不包含请求体部分,在URL后面使用一个问号分隔,然后把请求参数和对应的值直接附加在后面,这种方式的弊端是:
- 参数长度受限制,不能传送大量数据
- 不适合传送私密数据
-
GET也可以有请求体,但是RFC定义GET的作用是请求资源,所以根据这个语义,GET不需要请求体。
POST
- POST的含义是,根据请求体的内容,对服务器的指定资源做相应的处理。
- 将请求参数以键值对的形式封装在请求体中,好处是:
- 浏览器不会对请求体大小做限制,可以传输大量数据
- 数据不会直接展示在URL中,相对安全一些。但是HTTP是明文传输,抓个包就能看到了。
- POST的URL也是可以带参数的,但一般没人这么做
2、它们是安全与幂等性吗
安全:请求不会破坏服务器的资源
幂等:多次发起相同的请求,返回结果都是相同的
结论:
-
请求本身不能体现什么,得看它们具体做了什么事情。
-
GET方法一般用来读数据,是只读的,所以安全、幂等。
- 所以可以给GET请求的响应做缓存,可以把响应的内容缓存在浏览器,也可以缓存在代理服务器
-
POST一般用来新增或修改数据,所以不安全、不幂等
- 所以浏览器一般不会缓存POST请求的响应
-
但是实际开发中,可以用GET请求来完成数据的修改和删除,也可以用POST来完成数据的查询
那么此时GET就是不安全不幂等的,POST就是安全幂等的,所以还是要根据实际使用来确定。
3、HTTP响应
1、什么是响应
响应内容是服务器返回给浏览器的内容。
当服务器收到浏览器的请求后,会发送响应消息给浏览器,浏览器根据响应内容来作出显示。
2、响应报文格式
HTTP响应与HTTP请求相似,也由4个部分构成:
- 响应行
- 响应头
- 响应空行
- 响应体
看一个简单的响应报文:
响应行:
HTTP/1.1 200 OK
响应头:
Server: Apache-Coyote/1.1
Content-Type: text/html;charset=UTF-8
Content-Length: 624
Date: Mon, 03 Nov 2014 06:37:28 GMT
响应空行
响应体
解析:
响应行:
- HTTP/1.1 200 OK:响应协议为HTTP1.1,状态码为200,表示请求成功,OK是对状态码的解释;
响应头:
- Server: Apache-Coyote/1.1:服务器的版本信息;
- Content-Type: text/html;charset=UTF-8:响应体是html文件,使用的编码为UTF-8;
- Content-Length: 624:响应体为724字节;
- Set-Cookie: JSESSIONID=C97E2B4C55553EAB46079A4F263435A4; Path=/hello:响应给客户端的Cookie;
- Date: Mon, 03 Nov 2014 06:37:28 GMT:响应的时间,这可能会有8小时的时区差;
响应空行:
- 和请求空行一样,用途是分隔响应头和响应体。
响应体:
- 响应体有时是一个html文件,浏览器可以直接访问。
- 如果访问的是一个jsp页面,响应返回的也是一个html文件。
服务器将该jsp翻译成了一个html,然后再响应给浏览器。响应体的类型,由响应头的Content-Type指出。
3、HTTP的常见字段
1、请求字段
- Host:客户端发送请求时,用来指定服务器的域名。
- Host: www.A.com
- Accept:客户端告诉服务器,自己接收什么格式的数据
- Accept: */* ,代表任何格式都可以
- Accept-Encoding:客户端告诉服务器自己支持的压缩方式
- Accept-Encoding: gzip, deflate
- User-Agent:客户端告诉服务器,自己的浏览器信息
- Referer:客户端告诉服务器,当前请求的来源地址,可以做防盗链或统计工作
- Connection:使用TCP长连接
2、响应字段
- Content-Type:服务器告诉客户端,本次响应的格式
- Content-Type: text/html; charset=utf-8
- Content-Length:本次响应的字节长度
- Content-Length: 1000
- Content-Encoding:指定服务器返回的数据的压缩方式
- Content-Encoding: gzip
- Connection:使用TCP长连接
- Connection: keep-alive
- Set-Cookie:服务器发给客户端的Cookie
3、响应行的状态码
响应状态码由三位数字组成,表示服务器对请求的响应结果。
相当于服务器和浏览器单方面的暗号,浏览器接收到这三位数字,就明白了服务器的含义。
HTTP响应状态码的第一个数字定义了响应的类别,后面两位没有具体分类,第一个数字有五种可能的取值,具体介绍如下所示:
| 分类 | 分类描述 |
|---|---|
| 1xx | 提示信息,服务器收到了请求,但需要客户端继续执行操作 |
| 2xx | 成功,报文被成功接收并处理 |
| 3xx | 重定向,资源位置发生变动,需要客户端重新发送请求 |
| 4xx | 客户端发生错误,发来的请求报文有误,服务器无法处理。 |
| 5xx | 服务器发生错误,服务器在处理请求的过程中发生了错误 |
常用的具体状态码如下:
| 状态码 | 含义 |
|---|---|
| 200 | 请求成功,浏览器会把响应回来的信息显示在浏览器端。 |
| 302 | 表示重定向。比如说浏览器访问一个资源,服务器响应给浏览器一个302的状态码,并且通过响应头Location发送了一个新的url,告诉浏览器去请求这个url。这就是重定向。 |
| 304 | 第一访问一个资源后,浏览器会将该资源缓存到本地,第二次再访问该资源时,如果该资源没有发生改变,那么服务器响应给浏览器304状态码,告诉浏览器使用本地缓存的资源。 |
| 404 | 客户端错误的一种,比如说在浏览器端请求一个不存在的资源,这时浏览器端会出现404状态码。 |
| 405 | 客户端错误的一种,表示当前的请求方式不支持。比如说服务器端只对GET请求做了处理,而客户端的请求是post方式的,这个时候会出现405状态码。 |
| 500 | 服务器端错误,比如说服务器端代码出现空指针等异常,浏览器就会收到服务器发送的500状态码。 |
300系列详解
- 301:永久移动,服务器自动将请求转到新的地址
- 302:重定向,服务器返回浏览器一个新的地址,浏览器再次访问这个地址去获得数据
- 304:服务器告诉浏览器资源未修改,使用本地缓存
4、响应头
格式:
- 响应头名称:值
- 例如,Server : Apache-Coyote/1.1
常用的响应头:
| 响应头名称 | 含义 |
|---|---|
| Content-Type | 服务器告诉客户端,本次响应体的数据格式以及编码格式(字符集) |
| Content-Disposition | 服务器告诉客户端,以什么格式打开响应体数据。 |
详解:
- Content-Disposition
- 默认值为in-line,在当前页面打开。
- 也可以设置为attachment,以附件形式打开响应体,用于文件下载。
5、响应体
响应体就是传输的数据。
4、资源跳转的不同方式
请求转发(forward)、请求重定向(redirect)、定时刷新都可以实现资源的跳转,但它们有一些区别。
1、资源跳转方式的区别
-
请求转发:
-
一次请求,一次响应
-
地址栏不变
-
只能在服务器内部同一应用跳转,不能转发到别的服务器
-
-
请求重定向:
-
两次请求,两次响应,不同的request对象(每次请求服务器都会创建新的request对象)
-
地址栏发生了改变
-
既可以在服务器内,也可以不同服务器不同应用上跳转
-
-
定时刷新:
- 两次请求,两次响应,不同的request对象
- 地址栏发生了改变
- 可以用于服务器内部的资源跳转,也可以用于不同应用和不同服务器之间的资源跳转
- 定时刷新和请求重定向的区别是,
定时刷新可以设置时间间隔,比如实现“登录成功,5秒后返回首页”的操作。
2、资源跳转方式的实现过程
一句话总结:转发是服务器行为,重定向是客户端行为。为什么这样说呢,这就要看两个动作的工作流程:
转发过程:
- 客户浏览器发送http请求
- web服务器接受此请求
服务器调用内部的一个方法在容器内部完成请求处理和转发动作- 将目标资源发送给客户
在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。
转发行为是浏览器只做了一次访问请求。
重定向过程:
- 客户浏览器发送http请求
- web服务器接受后发送302状态码,以及对应新的location给客户浏览器
客户浏览器发现是302响应,则自动再发送一个新的http请求,请求url是新的location地址服务器根据此请求寻找资源并发送给客户端
既然是浏览器重新发出了请求,则就没有什么request传递的概念了。
在客户浏览器路径栏显示的是其重定向的路径,客户可以观察到地址的变化的。
重定向行为中,浏览器做了至少两次的访问请求。
在重定向的过程中,传输的信息会被丢失。
3、转发和重定向的功能区别
转发:客户端提交了请求,服务器根据内部逻辑,跳转多个地址,给客户端返回最终结果。
重定向:客户端提交了请求,服务器返回302状态码和新的地址,要求客户端再次发出请求,客户端请求新的地址后,服务器返回最终结果。
简单来说,转发属于服务器内部的事情,比如一件事情A做了一半,发送给B继续做,最后完成。对于客户端而言,它只知道自己最早请求的那个A,而不知道中间的B,甚至C、D。
而重定向是,请求发送给A,A判断这件事无法完成,要求客户端再去访问B,B发现可以做,就完成了。这个时候浏览器可以看到地址变了,而且历史的回退按钮也亮了。重定向可以访问自己web应用以外的资源。
生活中的例子:
假设你去办理某个执照,
转发:你先去了A局,A局看了以后,知道这个事情其实应该B局来管,但是他没有把你退回来,而是让你坐一会儿,自己到后面办公室联系了B的人,让他们办好后,送了过来。
重定向:你先去了A局,A局的人说:“这个事情不归我们管,去B局”,然后,你就从A退了出来,自己乘车去了B局。






![LeetCode[327]区间和的个数](https://img-blog.csdnimg.cn/a1b92d7512b84a83b8f92567f84e2aad.png)