大家好,基于LLM的聊天机器人可以通过前端访问,而且它们涉及到大量且昂贵的服务器端API调用。但如果可以让LLM完全在浏览器中运行——利用底层系统的计算能力呢?这样,LLM的全部功能都将在客户端可用——无需担心服务器的可用性、基础设施等问题,WebLLM是一个旨在实现这一目标的项目。
接下来跟随本文更深入地了解驱动WebLLM的因素以及搭建这个项目的挑战,本文还将研究WebLLM的优点和局限性。
什么是WebLLM
WebLLM是一个使用WebGPU和WebAssembly等技术的项目,能够完全在浏览器中运行LLM和LLM应用程序。使用WebLLM,你可以通过WebGPU利用底层系统的GPU在浏览器中运行LLM聊天机器人。
它使用了Apache TVM项目的编译器堆栈,并使用最近发布的WebGPU。除了3D图形渲染等功能外,WebGPU API还支持通用GPU计算(GPGPU计算)。
搭建WebLLM的挑战
由于WebLLM完全在客户端上运行,没有任何推理服务器,因此该项目面临以下挑战:
-
大型语言模型使用Python框架进行深度学习,这些框架本身也支持利用GPU进行张量操作。
-
在搭建可完全在浏览器中运行的WebLLM时,我们将无法使用相同的Python框架。而必须探索能够在Web上运行LLM的其他技术栈,同时仍然使用Python进行开发。
-
运行LLM应用程序通常需要大型推理服务器,但当所有内容在客户端——即在浏览器中运行时,用户就不能再使用大型推理服务器。
-
需要对模型的权重进行智能压缩,使其适合于可用的内存。
WebLLM如何工作
WebLLM项目使用底层系统的GPU和硬件能力,在浏览器中运行大型语言模型。机器学习编译过程通过利用TVM Unity和一系列的优化,将LLM的功能嵌入浏览器端。

该系统是用Python开发的,并使用TVM运行时在Web上运行,通过运行一系列优化,将其嵌入到Web浏览器中。
首先,将LLM的功能嵌入到TVM的IRModule中。对IRModule中的函数运行多个转换,以获取经过优化和可运行的代码,TensorIR是用于优化具有张量计算的程序的编译器抽象。此外,使用INT-4量化来压缩模型的权重,使用TypeScript和emscripten(将C和C++代码转换为WebAssembly的LLVM编译器)实现了TVM运行时。
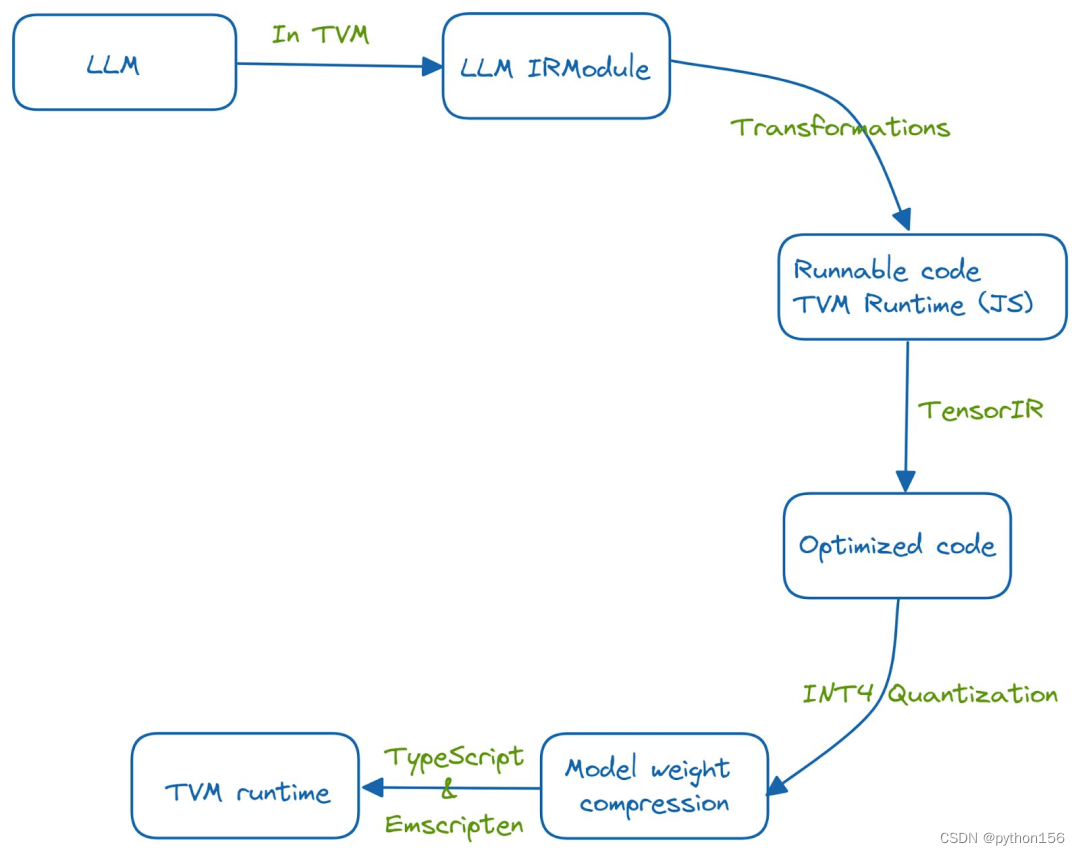
在第一次运行模型时,加载模型需要一些时间。由于在第一次运行后缓存已完成,因此后续运行速度会更快,开销也更小。

WebLLM的优点和局限性
优点
除了探索Python、WebAssembly和其他技术栈之间的协同作用外,WebLLM还具有以下优点:
-
在浏览器中运行LLMs的主要优点是隐私保护。由于在这种以隐私为先的设计中完全消除了服务器端,用户不再需要担心数据被滥用。由于WebLLM利用底层系统的GPU计算能力,用户也不必担心数据被恶意实体获取。
-
用户可以为日常活动构建个人AI助手,因此WebLLM项目提供了高度个性化的服务。
-
WebLLM的另一个优点是成本降低。用户不再需要昂贵的API调用和推理服务器,WebLLM使用底层系统的GPU和处理能力,因此运行WebLLM只需要一小部分成本就可以了。
局限性
以下是WebLLM的一些局限性:
-
尽管WebLLM缓解了围绕输入敏感信息的担忧,但仍然容易受到浏览器的攻击。
-
还有进一步的改进空间,例如添加对多个语言模型和浏览器选择的支持。目前,此功能仅在Chrome Canary和最新版本的Chrome中可用,将这一功能扩展到更多支持的浏览器集合将是很有帮助的。
-
由于浏览器运行的稳健性检查,使用WebGPU的WebLLM不具备GPU运行时的本地性能。你可以选择禁用运行稳健性检查的标志,以提高性能。

![LeetCode[327]区间和的个数](https://img-blog.csdnimg.cn/a1b92d7512b84a83b8f92567f84e2aad.png)