开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1050人左右 1 + 2 + 3)新人会进入3群
在获得一些新的问题中,关于子事务的问题是我第一个想在 review的,关于子事务,首先在PG中一直被强调的子事务性能不是很好的口碑下,到底为什么还会有使用的子事务的情况,这是因为有着方面的需求。
举例,在一个事务中如果报错的情况下,我们的事务会怎样

postgres=*# select 13 / 0;
ERROR: division by zero
postgres=!# select 'could we still work';
ERROR: current transaction is aborted, commands ignored until end of transaction block
postgres=!#
为什么要使用子查询,这个问题在上面的事务工作的情况下,一目了然因为在整个事务的设计中,很可能会报错,但是我将事务设计是按照一个连贯的逻辑来设计的,也就是即使出现了错误,我也希望这个事务通过某个功能来继续有选择的执行。
那么核心点是错误与继续工作,我们在PG的事务中换一个写法
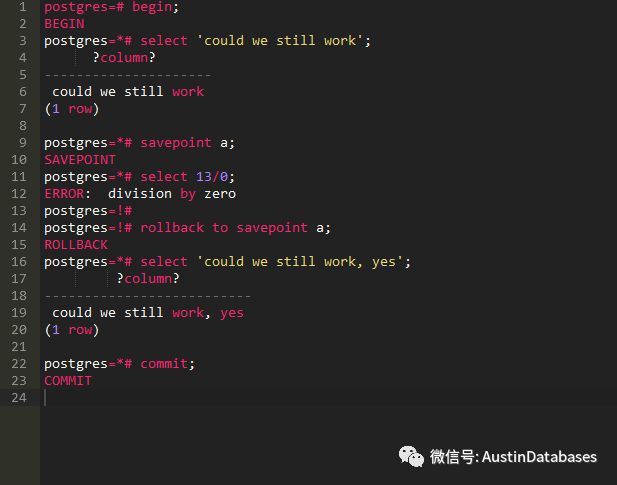
postgres=# begin;
BEGIN
postgres=*# select 'could we still work';
?column?
---------------------
could we still work
(1 row)
postgres=*# savepoint a;
SAVEPOINT
postgres=*# select 13/0;
ERROR: division by zero
postgres=!#
postgres=!# rollback to savepoint a;
ROLLBACK
postgres=*# select 'could we still work, yes';
?column?
--------------------------
could we still work, yes
(1 row)
postgres=*# commit;
COMMIT
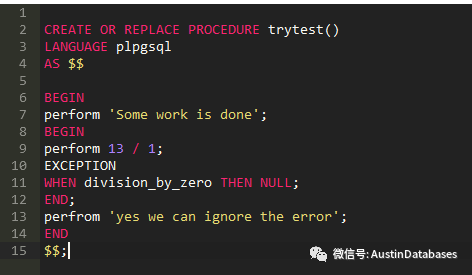
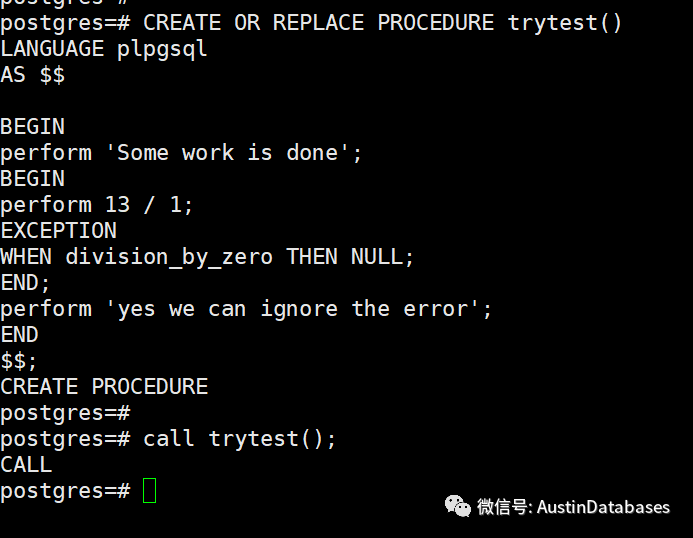
我们可以看上面的这个实例,在这个虽然这里我并没有使用 savepoint 但是我达到了一个类似的效果,就是如果我部分的子事务错误了,通过判断我可以跳过,继续执行。
那么问题来了,我们为什么要提出一个避讳子事务的事情,或者说save point的问题。
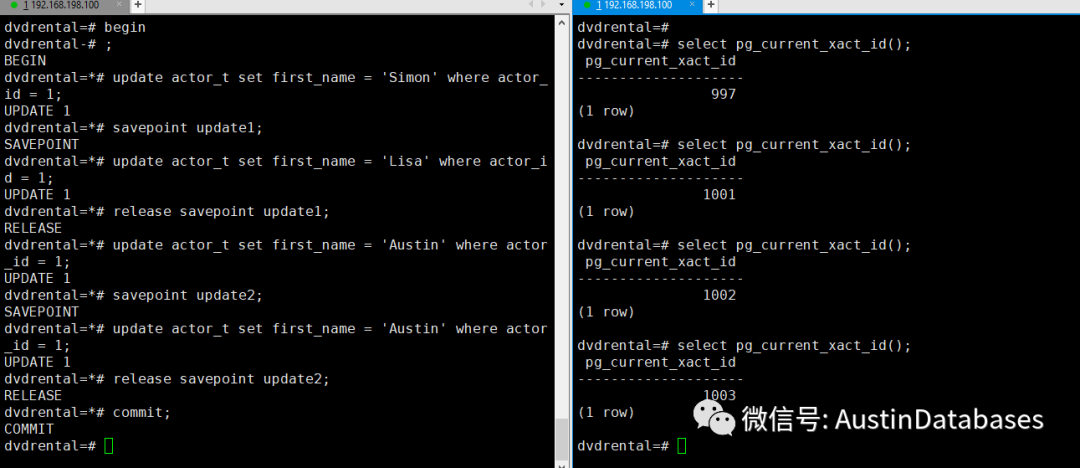
首先我们都已经了解了POSTGRESQL MVCC的机制下,除了有global的事务XID,同时如果你在事务中启用了 SAVEPOINT 则还会产生关于这个事务里的子事务的事务ID,这就会导致一个问题的发生,每个子事务都开始使用大量的使用自己的事务ID来进行分配,来完成嵌套事务。我用一个简单的例子就可以掩饰通过 save point后导致的情况。
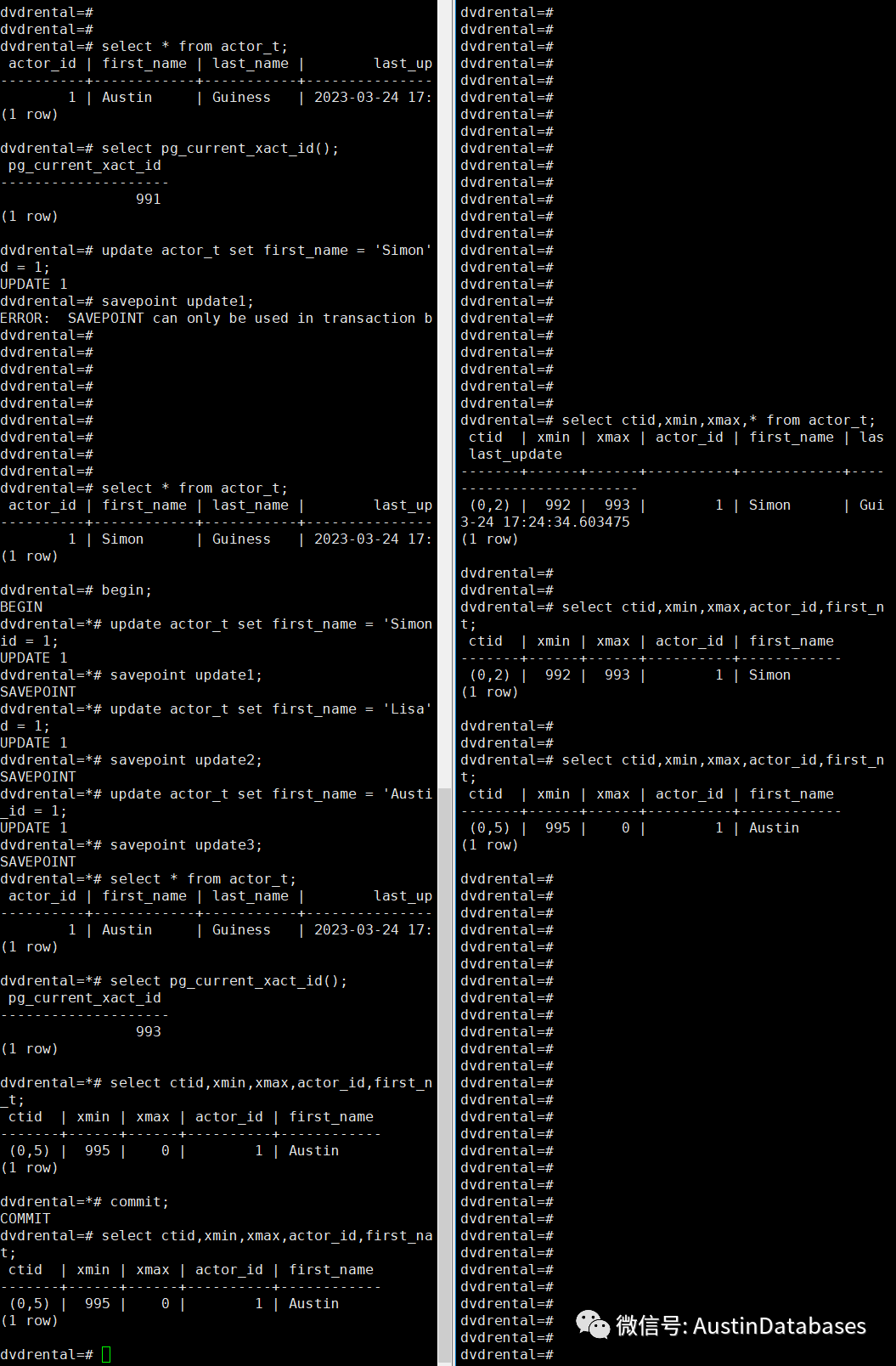
从上图想说明一个问题,在一个事务内对一个行进行了三次改变,并且进行了三次的 save point , 则从事务内看产生了针对修改行的三个变化行,从侧面的图也可以看出,最早为在事务中的ctid 是 0,2 后面是 ctid (0,5)则整体在事务运行中,会有行的多个版本。
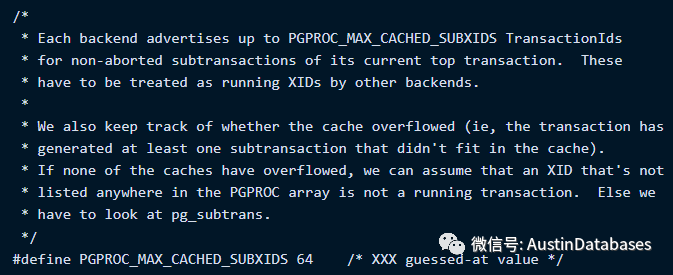
这就导致一些问题存在,一个事务中可以存在更多的在COMMIT 后的死行,同时导致事务运行中MVCC 会承接更多的对于其他事务在这个事务中的数据的可见性的判断的消耗。除此以外从源代码中PG对于子事务的也有相关的限制。系统在子事务运行中,还要时刻判断子事务事务溢出了,这里默认在代码中最大的子事务的最大数量是64个。
除此以外,在savepoint的使用中,还要注意,savepoint的 产生, 回滚和释放等几个事情。尤其在使用了子事务后,注意可以在事务中就对不在需要的 savepoint进行释放,而不是等到最后在进行commit 的时候才进行释放。
那么这里针对POSTGRESQL的 SAVEPOINT 有什么建议
1 尽量不要使用POSTGRESQL 的SAVEPOINT
2 如果使用可以采用 begin exception end 的方案来替换一些在事务里面对于出现问题后的跳过或有选择的跳过的方法。
3 如果必须使用SAVEPOINT 请注意不要太依赖,同时积极的在事务内进行SAVEPOINT的释放,同时注意你的最大同时可以存在的SAVEPOINT 是64。
最后还是那句话,数据库功能有和没有伤害的持续大量的使用是两个概念。