文章目录
- 优先级队列
- 仿函数
- 适配器模式
- 堆知识储备
- 反向迭代器
- 代码(反向迭代器)
- 代码(优先级队列)
优先级队列
仿函数
仿函数,它不是函数(其实是个类),但用法和函数一样。既然是个类,就可以存储很多变量和其它的信息,然后实现纯函数实现不了的功能。所以在一些需要函数作为参数的地方可以用仿函数代替,平常我们经常见到类重载 operator[],而仿函数主要重载 operator(),可以摒弃掉 C 语言那套函数指针用法,减少了指针使用的出错性,同时可以使代码更加美观。
适配器模式
适配器模式:又叫作变压器模式,它的功能是将一个类的接口变成客户端所期望的另一种接口,从而使原本因接口不匹配而导致无法在一起工作的两个类能够一起工作,属于结构型设计模式
优先级队列的数据结构本质是堆,而堆逻辑结构是一个二叉树,而存储结构是个数组连续空间。我们可以选择用某种容器来实现它,即用适配器模式,vector 作为缺省值,便能很好满足需求,若我们想用别的容器来实现,也可以手动传参控制。
有了仿函数和适配器模式,我们就可以控制代码的实现逻辑。我们通过仿函数,控制传参来,实现大小堆,避免把大小堆的代码写死。先看模板参数:

堆知识储备
向上调整法,传入的参数作为孩子,然后跟双亲比较向上交换(前提是前面的元素构成堆)。向上调整建堆,模仿的是数组元素一个一个尾插的过程,时间复杂度为 O(N*logN)
向下调整法,传入的参数作为双亲,然后与孩子比较向下交换(前提是下面的元素构成堆)。向下调整建堆,在原有数组的基础上,从倒数第一个非叶子结点,开始向下调整建堆,当双亲逐渐从倒数第一个非叶子结点下标减为 0 时,堆就建好了,时间复杂度为 O(N),时间复杂度小,因为最后一层叶子结点,不需要向下调整
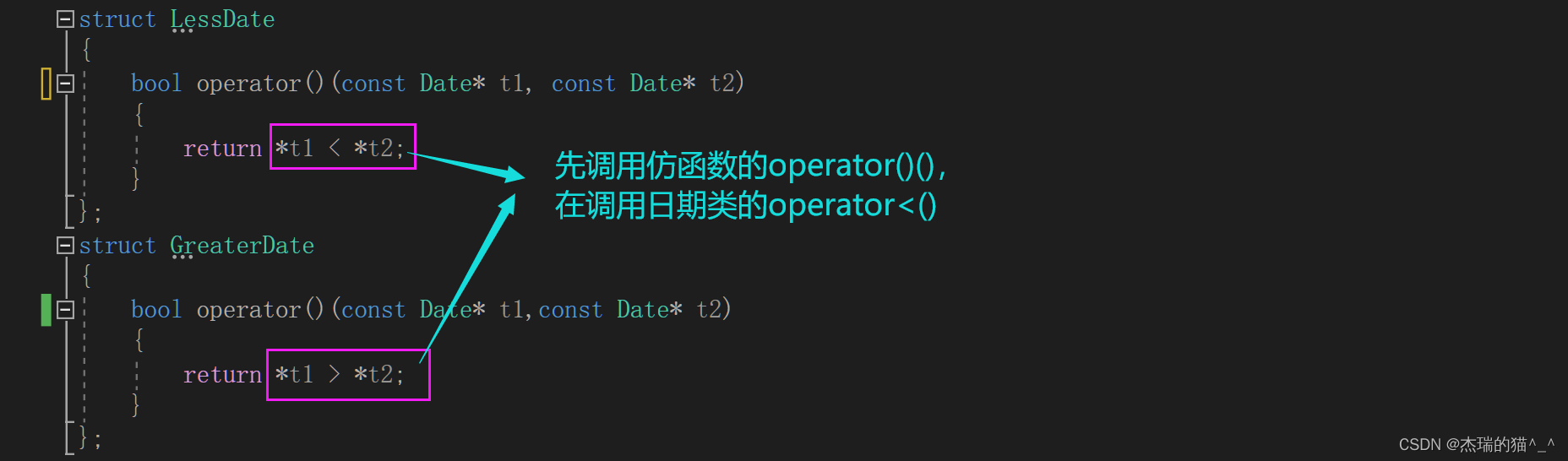
有了以上知识储备,我们可以轻松实现一个优先级队列,仿函数我们也可以自己调用库里面的 less(大堆), greater(小堆) ,如果对象是自定义类型,我们也可以用库里里面的仿函数解决,因为仿函数可以调用自定义类型的 operator> 等重载,但是如果对象是自定义类型的指针,指针是内置类型,不能重载,我们便只能自己写仿函数 像下面这样:
反向迭代器
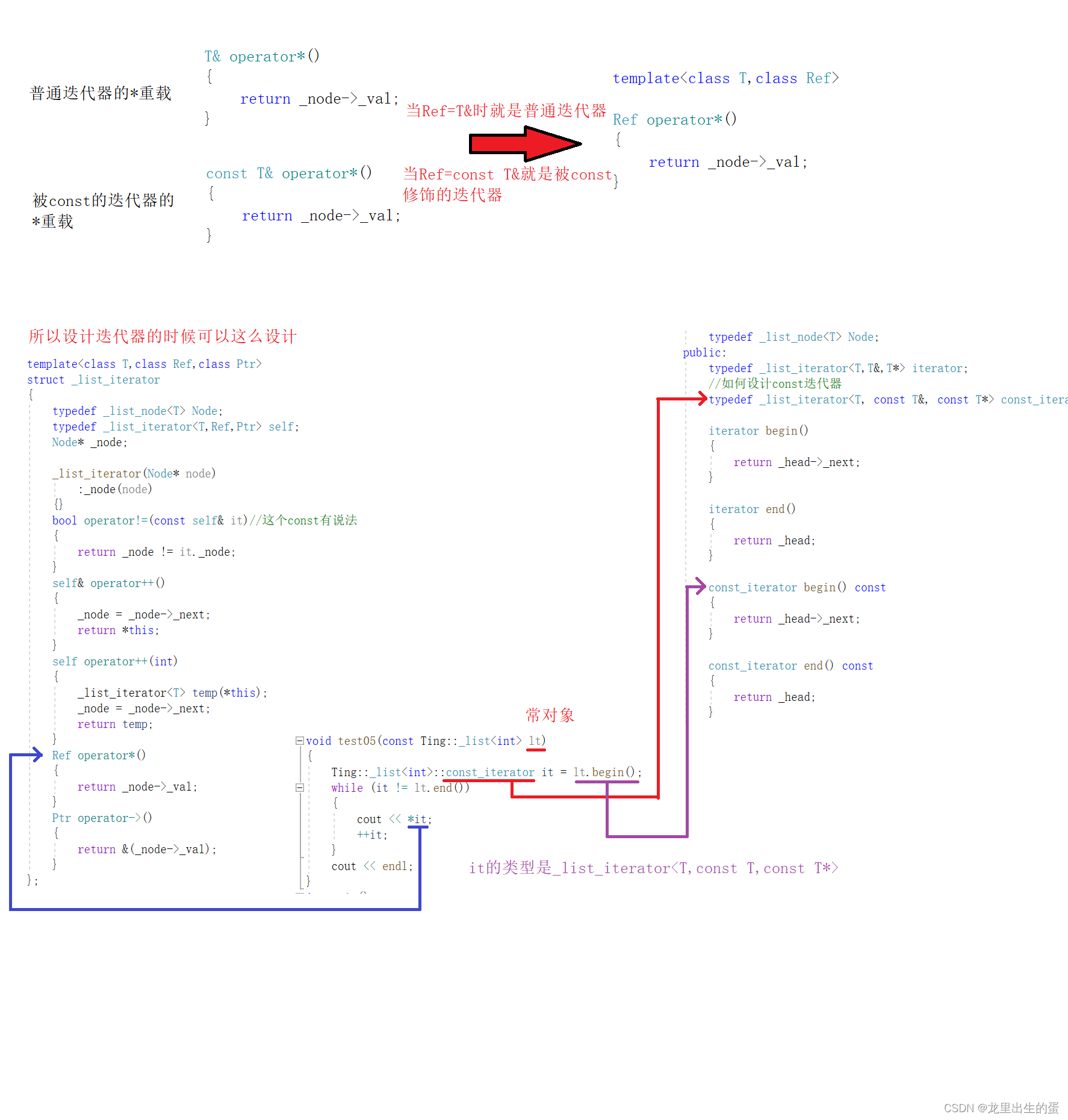
反向迭代器被封装成为一个大类,正向迭代器模板参数都是对象,而它的模板参数是各种容器的正向迭代器。成员变量是正向迭代器,即专门针对正向迭代器实现反向迭代器,因为我们还没有学萃取,所以我们多定两个模板参数 Ref 和 Ptr ,反向迭代器的 ++ 调用正向迭代器的 - -,反向迭代器的 - - 调用正向迭代器的 ++

库里实现
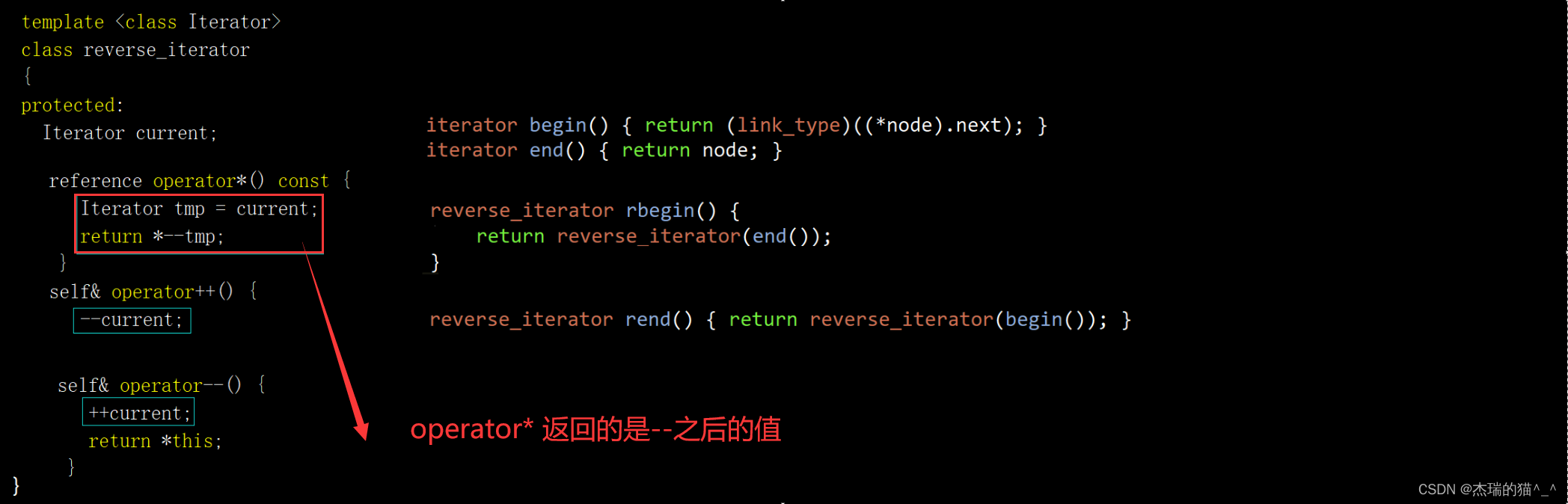
这里我们看到库里面先 - - 在返回,为什么要这么设计呢?因为正向迭代器和方向迭代器是镜像对称的,就像下面这样。先 - - 在返回刚好弥补了我们对迭代器 rbegin() 的解引用行为,同时保持一致,不让 rend() 进行解引用操作

代码(反向迭代器)
#pragma once
namespace Me
{
template<class Iterator, class Ref, class Ptr>
struct ReverseIterator
{
typedef ReverseIterator<Iterator, Ref, Ptr> Self;
Iterator _it;
ReverseIterator(const Iterator& it)
:_it(it)
{}
Ref operator*()
{
Iterator tmp = _it;
return *(--tmp);
}
Ptr operator->()
{
return &(operator*());
}
Self& operator++()
{
--_it;
return *this;
}
Self& operator--()
{
++_it;
return *this;
}
bool operator==(const Self& s) const
{
return _it == s._it;
}
bool operator!=(const Self& s) const
{
return _it != s._it;
}
};
}
代码(优先级队列)
#pragma once
#include <vector>
namespace Me
{
//仿函数 Less大堆,Greater小堆
template<class T>
struct Less
{
bool operator()(const T& t1, const T& t2)
{
return t1 < t2;
}
};
template<class T>
struct Greater
{
bool operator()(const T& t1, const T& t2)
{
return t1 > t2;
}
};
template<class T,class container=vector<T>,class compare=Less<T>>
class priority_queue
{
private:
//向下调整
void AdjustDown(int parent)
{
compare cmp;
int child = parent * 2 + 1;
while (child < size())
{
// 替代之前的大堆写法:if (child + 1 < _heap.size() && _heap[child + 1] > _heap[child])
if (child + 1 < _heap.size() && cmp(_heap[child],_heap[child+1]))
{
child++;
}
if ( cmp(_heap[parent], _heap[child]) )
{
swap(_heap[parent], _heap[child]);
parent = child;
child = child * 2 + 1;
}
else
{
break;
}
}
}
//向上调整建堆
void AdjustUp(int child)
{
compare cmp;
int parent = (child - 1) / 2;
while (child > 0)
{
if ( cmp(_heap[parent],_heap[child]) )
{
swap(_heap[parent], _heap[child]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
public:
priority_queue()
{}
template <class InputIterator>
priority_queue(InputIterator first, InputIterator last)
{
while (first != last)
{
_heap.push_back(*first);
first++;
}
//从倒数第一个非叶子结点向下调整建堆
for (int i = (_heap.size() - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(i);
}
}
bool empty() const
{
return _heap.empty();
}
size_t size() const
{
return _heap.size();
}
const T& top() const
{
return _heap[0];
}
void push(const T& x)
{
_heap.push_back(x);
AdjustUp(_heap.size() - 1);
}
void pop()
{
swap(_heap[0], _heap[_heap.size() - 1]);
_heap.pop_back();
AdjustDown(0);
}
private:
//成员变量是个vector实现的堆
container _heap;
};
}