目录
1. 复制6个redis配置文件到当前目录下
2. 启动每个节点
3. 判断集群是否可用
4. 初始化集群
5. 查看集群信息
6. 获取与插槽对应的节点
(1)手动重定向
(2)自动重定向
7. 故障恢复
需求:配置一个三主三从的集群系统:
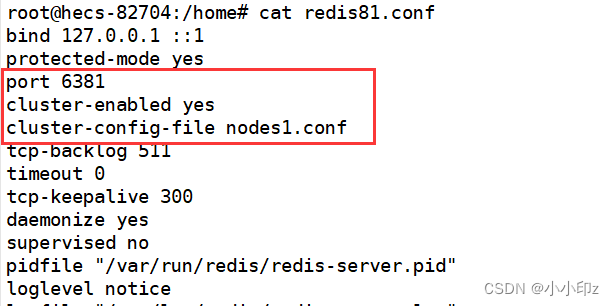
1. 复制6个redis配置文件到当前目录下:

配置文件内容如下:
redis81.conf 对应的端口就是6381,节点的持久化文件为 nodes1.conf
redis82.conf 对应的端口就是6382,节点的持久化文件为 nodes2.conf
以此类推...
2. 启动每个节点:
redis-server redis81.conf
redis-server redis82.conf
redis-server redis83.conf
redis-server redis84.conf
redis-server redis85.conf
redis-server redis86.conf3. 判断集群是否可用
4. 初始化集群:
下面启动命令中,create参数表示要初始化集群,--replicas 1 表示每个主数据库拥有从数据库的个数为1,所以集群共有3个主数据库和3个从数据库。
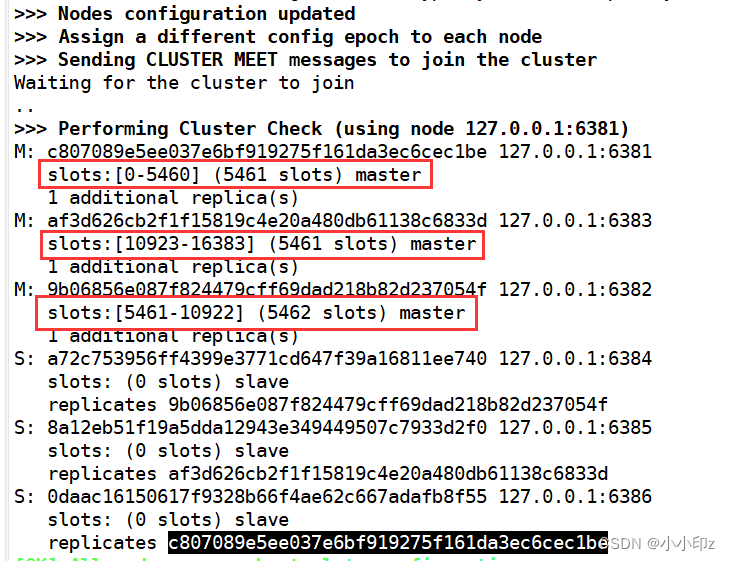
根据Redis集群节点信息,我们可以看到已经形成了一个Redis集群,并且具有以下节点配置:
节点
127.0.0.1:6381是一个主节点,。它负责处理槽范围0-5460的数据。节点
127.0.0.1:6382是另一个主节点,负责处理槽范围5461-10922的数据。节点
127.0.0.1:6383是第三个主节点,负责处理槽范围10923-16383的数据。节点
127.0.0.1:6384是节点127.0.0.1:6382的从节点,用于复制槽范围5461-10922的数据。节点
127.0.0.1:6385是节点127.0.0.1:6383的从节点,用于复制槽范围10923-16383的数据。节点
127.0.0.1:6386是节点127.0.0.1:6381的从节点,用于复制槽范围0-5460的数据。整个集群中每个主节点都有一个从节点,因此形成了三主三从的Redis集群配置。
root@hecs-82704:~$ redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:6385 to 127.0.0.1:6381
Adding replica 127.0.0.1:6386 to 127.0.0.1:6382
Adding replica 127.0.0.1:6384 to 127.0.0.1:6383
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: c807089e5ee037e6bf919275f161da3ec6cec1be 127.0.0.1:6381
slots:[0-5460] (5461 slots) master
M: 9b06856e087f824479cff69dad218b82d237054f 127.0.0.1:6382
slots:[5461-10922] (5462 slots) master
M: af3d626cb2f1f15819c4e20a480db61138c6833d 127.0.0.1:6383
slots:[10923-16383] (5461 slots) master
S: a72c753956ff4399e3771cd647f39a16811ee740 127.0.0.1:6384
replicates 9b06856e087f824479cff69dad218b82d237054f
S: 8a12eb51f19a5dda12943e349449507c7933d2f0 127.0.0.1:6385
replicates af3d626cb2f1f15819c4e20a480db61138c6833d
S: 0daac16150617f9328b66f4ae62c667adafb8f55 127.0.0.1:6386
replicates c807089e5ee037e6bf919275f161da3ec6cec1be
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
..
>>> Performing Cluster Check (using node 127.0.0.1:6381)
M: c807089e5ee037e6bf919275f161da3ec6cec1be 127.0.0.1:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: af3d626cb2f1f15819c4e20a480db61138c6833d 127.0.0.1:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 9b06856e087f824479cff69dad218b82d237054f 127.0.0.1:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: a72c753956ff4399e3771cd647f39a16811ee740 127.0.0.1:6384
slots: (0 slots) slave
replicates 9b06856e087f824479cff69dad218b82d237054f
S: 8a12eb51f19a5dda12943e349449507c7933d2f0 127.0.0.1:6385
slots: (0 slots) slave
replicates af3d626cb2f1f15819c4e20a480db61138c6833d
S: 0daac16150617f9328b66f4ae62c667adafb8f55 127.0.0.1:6386
slots: (0 slots) slave
replicates c807089e5ee037e6bf919275f161da3ec6cec1be
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
分配完成后,根据哈希槽算法会为每个主数据库分配插槽,分配插槽的过程其实就是分配哪些键由哪些节点负责。
关于插槽的分配:
在一个集群中,所有的键会被分配给16384个插槽,而每个主数据库会负责处理其中的一部分插槽,如:
可以看到6381节点负责处理0~5460这5461个插槽,6382负责处理5641~10922这部分插槽..
5. 查看集群信息:

6. 获取与插槽对应的节点
(1)手动重定向
当客户端向集群中的任意一个节点发送命令后,该节点会判断相应的键是否在当前节点中,如果键在该节点中,就会像单机实例一样正常处理该命令;如果键不在该节点中,就会返回一个MOVE重定向请求,告诉客户端这个键目前由哪个节点负责,然后客户端将同样的请求向目标节点重新发送一次以获得结果,如插入一个 set name minmin
在6381节点插入:,会提示 name 这个键应该在 6382 的节点上插入:

在6382节点插入:

(2)自动重定向
Redis命令行客户端提供了集群模式来支持自动重定向,使用 -c 参数来启用:

这里补充一个问题:
对于redis集群的主从复制,当我们在主节点插入数据后,在该主节点对应的从节点去获取刚才插入的数据仍然会报重定向的错误,例如:
在6382节点上插入一条与学校相关的数据,键是 school,值是 CHD

然后到该节点对应的从节点去获取(6382节点的从节点是6386) ,会发现有重定向错误:
其实从库已经将主库的数据复制过去了,这是因为:Redis Cluster集群中的从节点,官方默认设置的是不分担读请求的、只作备份和故障转移用,当有请求读向从节点时,会被重定向到对应的主节点来处理

解决办法:
在get数据之前先使用命令readonly,这个readonly告诉 Redis Cluster 从节点客户端愿意读取可能过时的数据并且对写请求不感兴趣

7. 故障恢复
将主节点 6382 下线:

查看集群的节点信息:

- 节点
127.0.0.1:6382是一个主节点,状态显示为master,fail,表示该节点是一个故障的主节点。- 节点
127.0.0.1:6384是一个从节点,从主节点127.0.0.1:6382复制槽范围5461-10922的数据。在主节点127.0.0.1:6382下线后,从节点127.0.0.1:6384成为了一个独立的主节点。
可以看到集群的故障恢复机制是生效的。