背景
为了进一步优化APP性能,最近针对如何提高应用对CPU的资源使用、以及在多线程环境下如何提高关键线程的执行优先级做了技术调研。本文是对技术调研过程的阶段性总结,将分别介绍普通应用如何调控App频率、如何将指定线程绑定到特定CPU、如何通过提升线程优先级获得更多CPU时间片的执行。
CPU调频
概念
通常更高的cpu频率代表了更快的运行速度,一个设备可能包含多个cpu,以我目前使用的Mi 11 Pro为例,它的CPU为8核分别为,1 x 2.84GHz (ARM 最新Cortex X1 核心)+3 x 2.4GHz (Cortex A78)+4 x 1.8GHz (Cortex A55) 。 这里列出的CPU频率为CPU物理理论上的最大频率,在实际运行过程中cpu的频率范围为governor动态控制的。目前的Androd设备普遍采用 schedutil gover进行调频控制,它会根据运行过程的CPU负载进行调频,不过默认的调频存在一些限制,比如调频之间的间隔需>10ms, 并且根据schedutil的升频计算公式,并不保证能直接升频到最高频率。

在实际应用中,如果我们已经知道接下来需要执行高cpu负载任务,通过提前主动升频来提升性能,就能减少卡顿或者提高任务的执行耗时。
在Android 系统可以通过 echo [频率] > /sys/devices/system/cpu/cpu*/cpufreq/scaling_setspeed 来修改目标CPU的频率,但这需要root权限才能执行。对于普通的应用程序,经过调研发现,高通提供了一套针对高通芯片的性能控制SDK Performance , 利用这个套机制可以实现CPU频率等资源的管理。
高通提供的这套SDK分为多个模块, 关于详细的介绍可以参考文章:https://juejin.cn/post/7141196697555714079
总之我们需要知道,在Java层 /android/util/BoostFramework.java类封装了一些基本的API提供给framework层调用。
由于这是高通CPU平台特定的特定实现,在aosp开源代码中无法直接搜索到该类,不过经过一番搜索,从其他开源系统中我找到了这个类的实现.

实现
通过阅读BoostFramework的源码,可以发现其实现主要是对 QPerformance.jar 和UxPerformance.jar中的API进行了一层反射调用包装。那么一样的,我们也可以通过封装对 BoostFrameWork类的调用提供我提频能力。
不过这些函数似乎并不是默认公开的内容,直接通过google搜索 并没有找到关于BoostFramwork或者高通Performance API的相关信息。 最后还是通过其他各种关键字检索,终于找到了部分有效信息
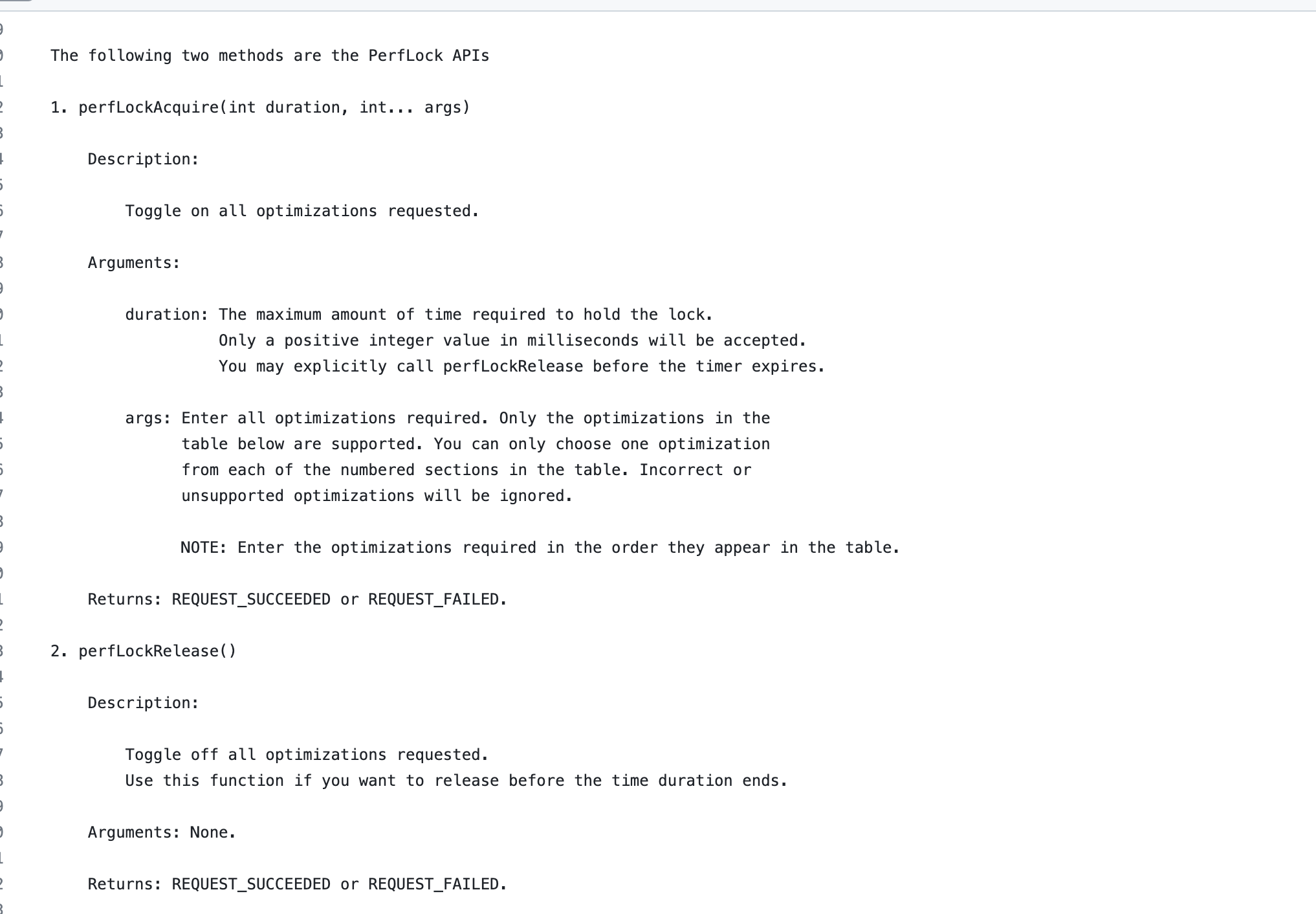

通过对应API文档及使用示例得知perfLocakAcquire 该函数接受 2个参数,第一个参数为持续时间、第二个参数为一个int数组,表示具体的操作,数组中的内容为 k-v 结构形式,比如 [config1,value,config2,value] . 该函数执行时会返回一个 PerfLock句柄,后续通过调用 perfLockReleaseHandler 可以提前取消之前的操作。
这里简单罗列一些配置项对应的值
/**
* 是否允许CPU进入深度低功耗模式, 对应 /dev/cpu_dma_latency, 默认空,不允许则设置为1
*/
const val MPCTLV3_ALL_CPUS_PWR_CLPS_DIS = 0x40400000
/**
* 对应控制小核最小频率
*/
const val MPCTLV3_MIN_FREQ_CLUSTER_LITTLE_CORE_0 = 0x40800100
/**
* 对应控制小核最大频率
*/
const val MPCTLV3_MAX_FREQ_CLUSTER_LITTLE_CORE_0 = 0x40804100
/**
* 对应控制大核最小频率
*/
const val MPCTLV3_MIN_FREQ_CLUSTER_BIG_CORE_0 = 0x40800000
/**
* 对应控制大核最大频率
*/
const val MPCTLV3_MAX_FREQ_CLUSTER_BIG_CORE_0 = 0x40804000
/**
* 对应控制超大核最小频率
*/
const val MPCTLV3_MIN_FREQ_CLUSTER_PLUS_CORE_0 = 0x40800200;
/**
* 对应控制超大核最小频率
*/
const val MPCTLV3_MAX_FREQ_CLUSTER_PLUS_CORE_0 = 0x40804200
/**
* 不太清楚,似乎是调度加速
*/
const val MPCTLV3_SCHED_BOOST = 0x40C00000;
完整的配置项可以参见github:https://github.com/Knight-ZXW/AppOptimizeFramework/blob/master/docs/qualcomms.txt
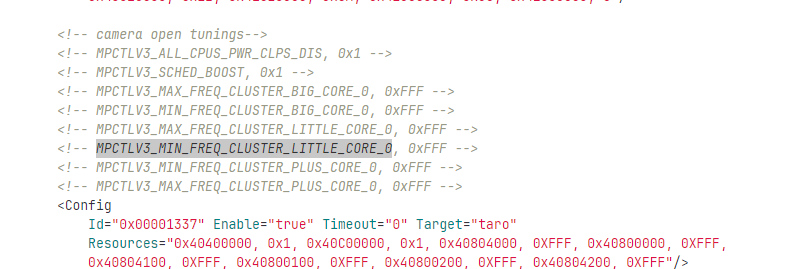
另外,如何确定我们的设备包含高通的这套性能调控SDK呢? 可以通过查看你的Android设备存储路径/system/framework/路径,如果包含了 QPerformance.jar 及 QXPerformance.jar 就表示接入了SDK。

根据上面的知识点,最终该工具类完整的实现代码如下
- 首先在init 函数中反射并获取 "android.util.BoostFramework”类的相应函数
- 提供 boostCpu 函数,该函数传入一个参数,表示提升cpu频率持续多久,该函数内部调用perfLockAcquire 函数 将所有CPU频率提升到最高值
- 提供 stopBoost 函数,该函数会将前面调用的boostCpu 效果提前取消
package com.knightboost.optimize.cpuboost
import android.content.Context
import java.lang.reflect.Method
import java.util.concurrent.CopyOnWriteArrayList
class QcmCpuPerformance : CpuPerformance {
companion object {
const val TAG = "QcmCpuPerformance";
/**
* 是否允许CPU进入深度低功耗模式, 对应 /dev/cpu_dma_latency, 默认空,不允许则设置为1
*/
const val MPCTLV3_ALL_CPUS_PWR_CLPS_DIS = 0x40400000
/**
* 设置小核最小频率,十六进制
*/
const val MPCTLV3_MIN_FREQ_CLUSTER_LITTLE_CORE_0 = 0x40800100
/**
* 设置小核最大频率, 十六进制
*/
const val MPCTLV3_MAX_FREQ_CLUSTER_LITTLE_CORE_0 = 0x40804100
/**
* 设置大核最小频率,十六进制
*/
const val MPCTLV3_MIN_FREQ_CLUSTER_BIG_CORE_0 = 0x40800000
/**
* 设置大核最大频率,十六进制
*/
const val MPCTLV3_MAX_FREQ_CLUSTER_BIG_CORE_0 = 0x40804000
const val MPCTLV3_MIN_FREQ_CLUSTER_PLUS_CORE_0 = 0x40800200;
const val MPCTLV3_MAX_FREQ_CLUSTER_PLUS_CORE_0 = 0x40804200
/**
* 调度优化? 启动 值为01
*/
const val MPCTLV3_SCHED_BOOST = 0x40C00000;
}
var initSuccess = false
lateinit var acquireFunc: Method
lateinit var mPerfHintFunc: Method
lateinit var releaseFunc: Method
lateinit var frameworkInstance: Any
var boostHandlers = CopyOnWriteArrayList<Int>()
/**
* 配置: 请求将所有CPU核心频率拉满,并禁止进入深入低功耗模式
*/
private var CONFIGS_FREQUENCY_HIGH = intArrayOf(
MPCTLV3_SCHED_BOOST, 1,
MPCTLV3_ALL_CPUS_PWR_CLPS_DIS, 1,
MPCTLV3_MAX_FREQ_CLUSTER_BIG_CORE_0, 0xFFF,
MPCTLV3_MAX_FREQ_CLUSTER_LITTLE_CORE_0, 0xFFF,
MPCTLV3_MIN_FREQ_CLUSTER_BIG_CORE_0, 0xFFF,
MPCTLV3_MIN_FREQ_CLUSTER_LITTLE_CORE_0, 0xFFF,
MPCTLV3_MIN_FREQ_CLUSTER_PLUS_CORE_0, 0xFFF,
MPCTLV3_MAX_FREQ_CLUSTER_PLUS_CORE_0, 0xFFF,
)
var DISABLE_POWER_COLLAPSE = intArrayOf(MPCTLV3_ALL_CPUS_PWR_CLPS_DIS, 1)
/**
* 初始化CpuBoost 核心功能
*/
override fun init(context: Context): Boolean {
try {
val boostFrameworkClass = Class.forName("android.util.BoostFramework")
val constructor = boostFrameworkClass.getConstructor(Context::class.java)
?: return false
frameworkInstance = constructor.newInstance(context)
acquireFunc = boostFrameworkClass.getDeclaredMethod(
"perfLockAcquire", Integer.TYPE, IntArray::class.java
)
mPerfHintFunc = boostFrameworkClass.getMethod(
"perfHint", Int::class.javaPrimitiveType, String::class.java, Int::class.javaPrimitiveType, Int::class.javaPrimitiveType
)
releaseFunc = boostFrameworkClass.getDeclaredMethod(
"perfLockReleaseHandler", Integer.TYPE
)
initSuccess = true
return true
} catch (e: Exception) {
initSuccess = false
CpuBoostManager.boostErrorLog(TAG, "init failed", e)
return false
}
}
/**
* 提升所有核心CPU频率到最高频率
*/
override fun boostCpu(duration: Int): Boolean {
if (!initSuccess) return false
return try {
perfLockAcquire(duration, DISABLE_POWER_COLLAPSE)
perfLockAcquire(duration, CONFIGS_FREQUENCY_HIGH)
return true
} catch (e: Exception) {
CpuBoostManager.boostErrorLog(TAG, "boostCpuFailed", e)
false
}
}
/**
* Toggle off all optimizations requested Immediately.
* Use this function if you want to release before the time duration ends.
*
* 这个函数并不强制调用,只用于提前取消所有已配置的加速效果。
*/
override fun stopBoost() {
val handlers = boostHandlers.toTypedArray()
for (handler in handlers) {
try {
releaseFunc.invoke(frameworkInstance, handler)
} catch (e: Exception) {
e.printStackTrace()
}
}
}
/**
* Toggle on all optimizations requested.
* @param duration: The maximum amount of time required to hold the lock.
* Only a positive integer value in milliseconds will be accepted.
* You may explicitly call perfLockRelease before the timer expires.
* @param list Enter all optimizations required. Only the optimizations in the
* table below are supported. You can only choose one optimization
* from each of the numbered sections in the table. Incorrect or
* unsupported optimizations will be ignored.
*
* NOTE: Enter the optimizations required in the order they appear in the table.
*/
private fun perfLockAcquire(duration: Int, list: IntArray): Int {
val handler = acquireFunc.invoke(frameworkInstance, duration, list) as Int;
if (handler > 0) {
boostHandlers.add(handler)
}
return handler
}
}
验证
通过读取/sys/devices/system/cpu/cpu$cpuIndex/cpufreq/下的文件,可以获取对应cpu所能运行的最小、最大、以及当前的频率。
在提频前,当前设备的cpu频率信息如下
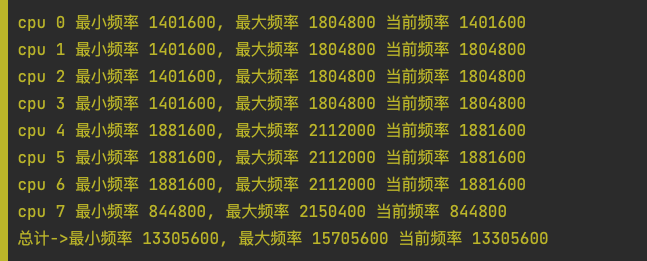
可以发现提频前,0-3 这些小核中,3个运行在最大调频频率,1个运行在最小调频频率,4-6中核都运行在最小频率,7号大核直接摸鱼运行在最小频率。
在提频后,运行数据如下:

可以看出,进行提频后,所有核心都运行在最大频率上,整机频率相比之前提升30%, 当然在实际运行过程中,提频前的工作频率并不会这么低,这里的数据是从CPU几乎空闲状态到直接满频的情况。
线程CPU亲和性
概念
根据wikipedia上的解释,通过设置CPU亲和性可以控制线程在哪些CPU上运行。
通过CPU亲和性的概念可以提高线程的运行效率,比如由于cpu存在缓存机制,通过cpu亲和性(CPU Affinity)让同一个线程被重新调度时,尽量调度到同一个处理器上,这样就可以可以避免不必要的 Cache Miss。 另一种情况,比如对于一组相同的任务,它们需要访问的内存大部分是相同的,如果控制这组任务调度在相同的CPU上,也可以共享相同的cache,从而提高程序的访问效率。
CPU亲和性分位2种,分别为软亲和性和硬亲和性。
- 软亲和性: linux系统会竟可能将一个进程保持在指定的CPU上运行,但不严格保证,当所指定的CPU非常繁忙时,它可以迁移到其他空闲CPU上执行
- 硬亲和性:linux系统允许指定某个进程运行在特定的一个或一组CPU上,并且只能运行在这些特定的CPU上。
在下文中,我们讨论的亲和性控制将只涉及到硬亲和性。
亲和性控制
API
在linux系统中,可以通过taskset命令或者程序中调用 sched_setaffinity 指定线程的cpu亲和性。
taskset的具体用法为 taskset [-ap] [mask] [PID]

这里的mask指的是CPU掩码,CPU掩码描述了具体哪些CPU,以8核CPU为例,
二进制 00000011 (十进制值为3), 表示CPU序号1 和2, 当调用命令 tasket -p 3 2001 表示序号为2001的进程将只会运行在 cpu 1 或2 上。 也就是说CPU掩码根据对应二进制位置及其0或1的值,表示某个线程的CPU相关亲和性。
当我尝试在 Android设备上直接调用 taskset命令,系统提示无权限。

为了进一步了解 taskset程序的实现,为后续我们自己实现CPU控制提供参考,这里研究了一下其实现代码。该工具的实现源码在 util-linux项目中。
上面提示的 failed to get xx's affinity其实是在调用 sched_getaffinity 函数时就失败了。 这里我的设备未Root,因此猜测原因为 sched_setaffinity 、sched_getaffinity 底层涉及的系统调用只有当前进程才有权限控制其自身的affinity属性。

通过其源码实现可以发现该工具实现就是套了层皮,底层实现还是调用的 sched_setaffinity函数。
应用层控制实现
有了上述背景,在native层编写一个cpu亲和性控制的函数就比较简单了,主要涉及到sched.h头文件的几个函数, 以下为最终实现示例代码
#include <jni.h>
#include "unistd.h"
#include "sched.h"
#include "android/log.h"
Java_com_knightboost_optimize_cpuboost_ThreadCpuAffinityManager_setCpuAffinity(JNIEnv *env,
jclass clazz,
jint tid,
jintArray cpu_set) {
if (tid <= 0) {
tid = gettid();
}
// 获取当前CPU核心数
int cpu_count = sysconf(_SC_NPROCESSORS_CONF);
jsize size = env->GetArrayLength(cpu_set);
jint bind_cpus[size];
env->GetIntArrayRegion(cpu_set, 0, size, bind_cpus);
cpu_set_t mask;
CPU_ZERO(&mask);
for (jint cpu : bind_cpus) {
if (cpu > 0 && cpu < cpu_count) {
CPU_SET(cpu, &mask); //设置对应cpu位置的值为1
} else {
__android_log_print(ANDROID_LOG_ERROR,
"TCpuAffinity",
"try bind illegal cpu index %d",cpu);
}
}
int code = sched_setaffinity(tid, sizeof(mask), &mask);
if (code == 0) {
// return success
return JNI_TRUE;
} else {
__android_log_print(ANDROID_LOG_ERROR,
"TCpuAffinity",
"setCpuAffinity() failed code %d",code);
// return failed
return JNI_FALSE;
}
}
该函数中,首先获取了当前的CPU核心数,接下来创建一个 cpu_set_t mask变量,调用宏函数 CPU_SET 将对应位置的二进制值设置为1, 最后调用 sched_setaffinity 设置相应线程的cpu亲和性。
在实际应用场景中,我们可以将某个线程需要执行繁重任务时,将它绑定到大核上,当任务执行结束时,再还原原始的cpu亲和性值或者将其cpu亲和性值重置为所有CPU。
验证
到目前所讲的都还是理论阶段,那么我们如何确认修改线程的CPU亲和性之后,这个线程确实被迁移到目标CPU上执行了呢?
在之前写过的一篇CPU相关的文章《Android 高版本采集系统CPU使用率的方式》中,我们提及了 stat文件记录了线程当前指向状态的相关信息。根据linux手册, 第 39 处的值就表示了该线程最后运行的CPU。

因此通过读取该文件,我们就可以获取线程所运行在哪个CPU上:
/**
* 获取目标线程最后运行在哪个CPU
*/
fun getLastRunOnCpu(tid:Int):Int{
var path = "/proc/${android.os.Process.myPid()}/task/${tid}/stat"
try {
val content = File(path).readText()
var arrays = StringUtil.splitWorker(content,' ')
var cpu = arrays[38]
return cpu.toInt()
}catch (e:Exception){
// this task may already have ended
return -1;
}
}
这里我们需要获取Java线程对应操作系统的线程id(tid),关于 tid 的获取可以参考之前的文章:https://juejin.cn/post/7138690370694545415
我们通过获取Java Thread对象的 nativePeer值,这个地址对应了Android native层的Thread对象指针地址,再根据tls_32bit_sized_values结构的tid属性偏移值,进行类型强转,从而获取系统线程id。
在Demo中,在修改目标线程CPU后,我们可以持续打印这个值,以验证绑核是否成功。
这里我尝试将目标线程的 affinity修改为大核(CPU序号7),打印结果如下

可以看到,在执行修改前,目标线程的cpu亲和性为0~7核心,且最近1秒基本运行在cpu核心2上,在修改CPU亲和性为 cpu7后, 目标线程只会运行在cpu7 上。 这验证了功能确实生效了。
线程优先级
概念
除了CPU频率、线程CPU亲和性,线程的优先级也会影响线程对cpu的使用,线程优先级更高意味该线程有更高的概率获得CPU的执行,分配到更多的CPU时间片。
实现
在Android平台下,可以通过Process.setThreadPriority(int tid, int priority) ,这适用于无法获取目标线程的Thread对象,只知道目标线程tid的情况。

当然,如果能够获取到Thread对象,也可以通过 Thred对象的 setPriority(int newPriority)设置。

需要注意的是,这2个函数优先级int值的定义和范围是不同的,第一个函数是Android系统提供的Java接口,它的取值范围为-1920 对应linux的 nice值, 而第二个函数是Java jdk提供的,它的优先级范围为110。
另外,Process.setThreadPriority(int tid, int priority) 这里的tid 需要的是实际的操作系统线程ID,而不是Java中Thread的id。
另一方面,Thread.setPriority(int newPriority) 函数设置的优先级并没有达到最大值,我们可以测试下使用Thread对象的设置优先级函数为最高值(Thread.MAX_PRIORITY) 之后的nice值 ,并和 Process.setThreadPriority进行比较,测试代码如下:
Thread{
var currentThread = Thread.currentThread()
var tid = ArtThread.getTid(currentThread)
Log.e("priorityTest","当前线程 $tid" +
" java优先级 ${currentThread.priority} nice值 ${ThreadUtil.getNice(tid)}")
currentThread.priority=Thread.MAX_PRIORITY;
Log.e("priorityTest","使用 Thread.setPriority 设置最高优级10 后 nice值 ${ThreadUtil.getNice(tid)}")
Process.setThreadPriority(tid,-20)
Log.e("priorityTest","使用 Process.setThreadPriority 设置最高优级-20 后 nice值 ${ThreadUtil.getNice(tid)}")
}.start()
测试结果如下:

由此可见,如果希望最大程度提高线程优先级的话,还是需要使用Process的相关函数。
那么这里为什么Android系统下通过Thread.setPriority 设置的最高优先级nice值为什么为-8呢?通过跟踪native层代码路径发现,这里Java线程优先级的1~10 对应的nice值使用了一个数组存储了对应的优先级,其中的最高优先级10对应的 ANDROID_PRIORITY_URGENT_DISPLAY 对应的nice值就为-8
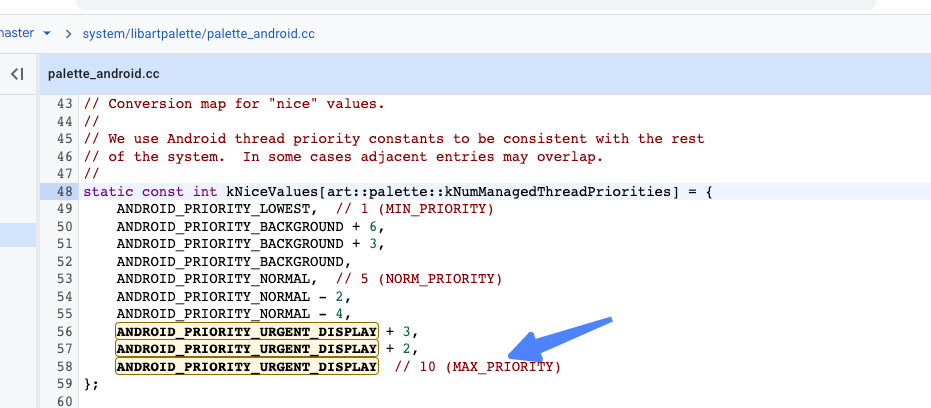
Android系统对于什么情况下使用什么nice值 完整定义如下:

验证
为了验证设置线程优先级对线程获得CPU时间片的提升效果,我们创建一组工作线程,并同时执行,每个线程会执行一个类似死循环的工作,这样每个线程都不会主动让出CPU,工作5秒后,计算当前线程得到CPU执行的时间。 为了更好对比线程优先级对CPU时间片分配的影响,我们将这组线程统一绑定到一个核心上,这样可以更好的观测线程优先级对CPU时间片分配的的影响。
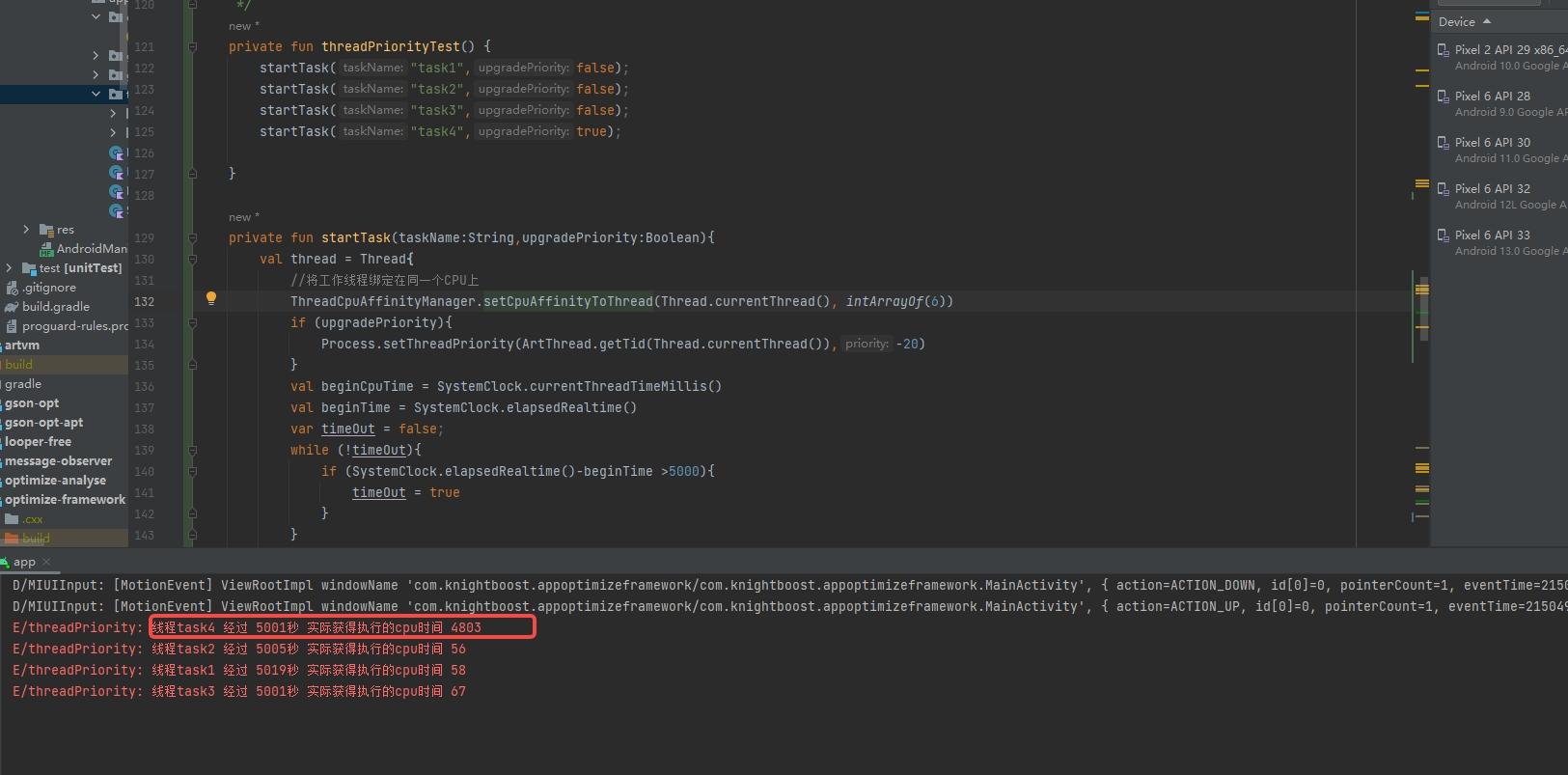
根据输出结果可以发现,优先级为-20的线程占用了cpu98%的执行时间,其他线程几乎没得到执行。
而如果将线程优先级修改为0,也就是默认的线程优先级,那么这4个线程将会得到几乎相同的执行时间。

从这个结果看,线程优先级的效果还是比较明显的。
不过在实际情况中,如果这些线程并没有特别指定在某个CPU执行,那么它们可能会在任何CPU上执行,系统会自动将线程调度到其他不繁忙的CPU上。
以下是指定了 task4的优先级,但并没有绑定CPU核的情况 输出的结果:

这里有2个信息
- 一开始task 2、3被分配cpu上,task 1、4被分配在cpu5上,由于我们的任务几乎是一个空循环任务,对CPU的使用率较高,此时每个任务都无法得到足够的CPU时间片执行,而1、4核心可能又几乎是空闲的,因此系统自动将部分线程迁移到空闲的CPU上执行
- 由于线程被分配的不同的CPU上,因此这几个线程之间不存在优先级比较关系,因此每个任务都得到了充足的cpu时间执行
从这里我们也可以看出,不合理的强绑定CPU核心, 有时候可能会起到反效果。
最后
本文只是分享了Android系统下自主控制cpu频率、线程指定核心和优先级的方式,不过这些能力需要具体落实到业务场景才能够获得实际的收益。
如果通过本文对你有所收获,可以来个点赞、收藏、关注三连,后续将分享更多性能监控与优化相关的文章。
也可以关注我的个人公众号:编程物语

本文相关测试实现代码已开源至: https://github.com/Knight-ZXW/AppOptimizeFramework
APM性能监控与优化专栏
性能优化专栏历史文章:
| 文章 | 地址 |
|---|---|
| 抖音消息调度优化启动速度方案实践 | https://juejin.cn/post/7217664665090080826 |
| 扒一扒抖音是如何做线程优化的 | https://juejin.cn/post/7212446354920407096 |
| 监控Android Looper Message调度的另一种姿势 | https://juejin.cn/post/7139741012456374279 |
| Android 高版本采集系统CPU使用率的方式 | https://juejin.cn/post/7135034198158475300 |
| Android 平台下的 Method Trace 实现及应用 | https://juejin.cn/post/7107137302043820039 |
| Android 如何解决使用SharedPreferences 造成的卡顿、ANR问题 | https://juejin.cn/post/7054766647026352158 |
| 基于JVMTI 实现性能监控 | https://juejin.cn/post/6942782366993612813 |
参考资料
- https://www.iteye.com/blog/429564140-2410445
- https://usermanual.wiki/Document/kba1807200050301qualcommandroidgoperformancetuningguide.1956213859/view
- https://lwn.net/Articles/792502/
- https://dumps.tadiphone.dev/dumps/oneplus/op516el1/-/blob/qssi-user-13-SKQ1.220519.001-S.202208250304-release-keys--ALLNET/vendor/etc/powerhint.xml
- https://deepinout.com/qcom-camx-debug-user-guide/camx-perf-debug-user-guide/qcom-perflock-usage.html
- http://www.manongzj.com/blog/31-sgltmktizd.html
- powerhint.xml、powerhint.xml
- https://en.wikipedia.org/wiki/Processor_affinity