文章目录
- 前言
- 一、什么是链表
- 二、链表的优点和缺点
- 三、链表节点的定义
- 四、初始化链表
- 五、链表的插入
- 1.头部插入
- 2.尾部插入
- 3.中间插入
- 六、遍历链表
- 七、释放链表
- 总结
前言
本篇文章带大家正式的来学习数据结构,数据结构是学习操作系统,和深入C语言必不可少的,所以这篇文章开始带大家学习数据结构的知识。
一、什么是链表
链表(Linked List)是一种常见的数据结构,用于存储和组织数据元素。它由一系列节点(Node)组成,每个节点包含存储的数据(或称为元素/值)以及指向下一个节点的引用(或链接/指针)。
链表中的节点可以通过指针连接在一起,形成一个链式结构,而不像数组那样在内存中连续存储。每个节点只需要存储指向下一个节点的引用,而不需要预先分配固定大小的内存空间。这使得链表具有动态性,能够高效地插入、删除节点,但对于随机访问则效率较低。
链表分为单向链表(Singly Linked List)和双向链表(Doubly Linked List)两种常见类型。
在单向链表中,每个节点的引用指向下一个节点,最后一个节点的引用为空(null)。从头节点(首节点)开始遍历链表,通过一次次跳转到下一个节点来访问或操作数据。
双向链表在单向链表的基础上添加了一个指向前一个节点的引用。这使得双向链表可以从头节点和尾节点两个方向遍历,增加了一些操作的灵活性,但也增加了一些额外的空间开销。
链表适用于频繁的插入和删除操作,而不需要频繁的随机访问。它在内存使用上可以比数组更灵活,但在访问速度上相对较慢。链表常用于实现其他高级数据结构,如队列、栈和图等。
需要注意的是,链表的节点并不需要连续的内存空间,可以在内存中分散存储。这与数组的存储方式不同,数组在内存中需要一段连续的空间来存储所有元素。这是链表与数组的主要区别之一。
二、链表的优点和缺点
链表的优点包括:
1.动态性:链表的大小可以根据需要动态地增长或缩小,不像数组需要预先分配固定大小的空间。
2.插入和删除操作高效:由于链表中的节点仅需修改相邻节点的指针,插入和删除节点的操作复杂度为O(1),效率很高。
3.内存利用率高:链表节点可以在内存中分散存储,可以充分利用零散的空间。
4.支持灵活的数据结构:链表可以用于实现其他高级数据结构,如队列、栈和图等。
链表的缺点包括:
1.随机访问效率低:由于链表的内存存储不是连续的,要访问特定位置的节点,必须从头节点开始遍历,直到达到目标位置,这使得随机访问的效率较低。时间复杂度为O(n)。
2.额外的存储空间:链表需要额外的指针来维护节点之间的连接关系,这会占用一定的存储空间。
3.不支持随机访问:由于链表的节点间没有直接的索引关系,不能像数组那样通过索引快速访问任意位置的节点。
4.需要遍历整个链表:若要访问链表中的所有节点,需要从头节点开始遍历整个链表,这会增加一定的时间开销。
综上所述,链表适合在插入和删除操作较频繁、对随机访问要求较低的场景下使用,而在需要频繁的随机访问和占用连续内存空间的场景中,数组可能是更好的选择。选择使用链表或数组取决于具体的应用需求和优化目标。
三、链表节点的定义
链表节点(Node)是链表中的基本组成单元,包含存储的数据(或称为元素/值)以及指向下一个节点(或前一个节点)的引用。
基本的链表节点定义通常包括以下成员:
1.数据(Data):节点存储的数据或元素值。
2.下一个节点引用(Next):指向链表中下一个节点的引用。在单向链表中,该引用指向链表中的后继节点;在双向链表中,该引用则指向链表中的下一个节点。
3.(可选)前一个节点引用(Previous):仅在双向链表中存在,指向链表中的前一个节点。
// 定义链表节点结构体
struct Node {
int data; // 节点存储的数据
struct Node* next; // 指向下一个节点的指针
};
四、初始化链表
在C语言中,初始化链表通常需要创建一个头节点并将其置为NULL,表示链表为空。
#include <stdio.h>
#include <malloc.h>
/* 定义链表节点 */
typedef struct node
{
int data; // 节点存储的数据
struct node* PNext; // 指向下一个节点的指针
}Node;
/* 初始化链表 */
Node* InitList(void)
{
Node* head = (Node*)malloc(sizeof(Node));
if (head != NULL)
{
head->data = 0;
head->PNext = NULL;
}
return head;
}
int main(void)
{
Node* Head = InitList();
return 0;
}
五、链表的插入
1.头部插入
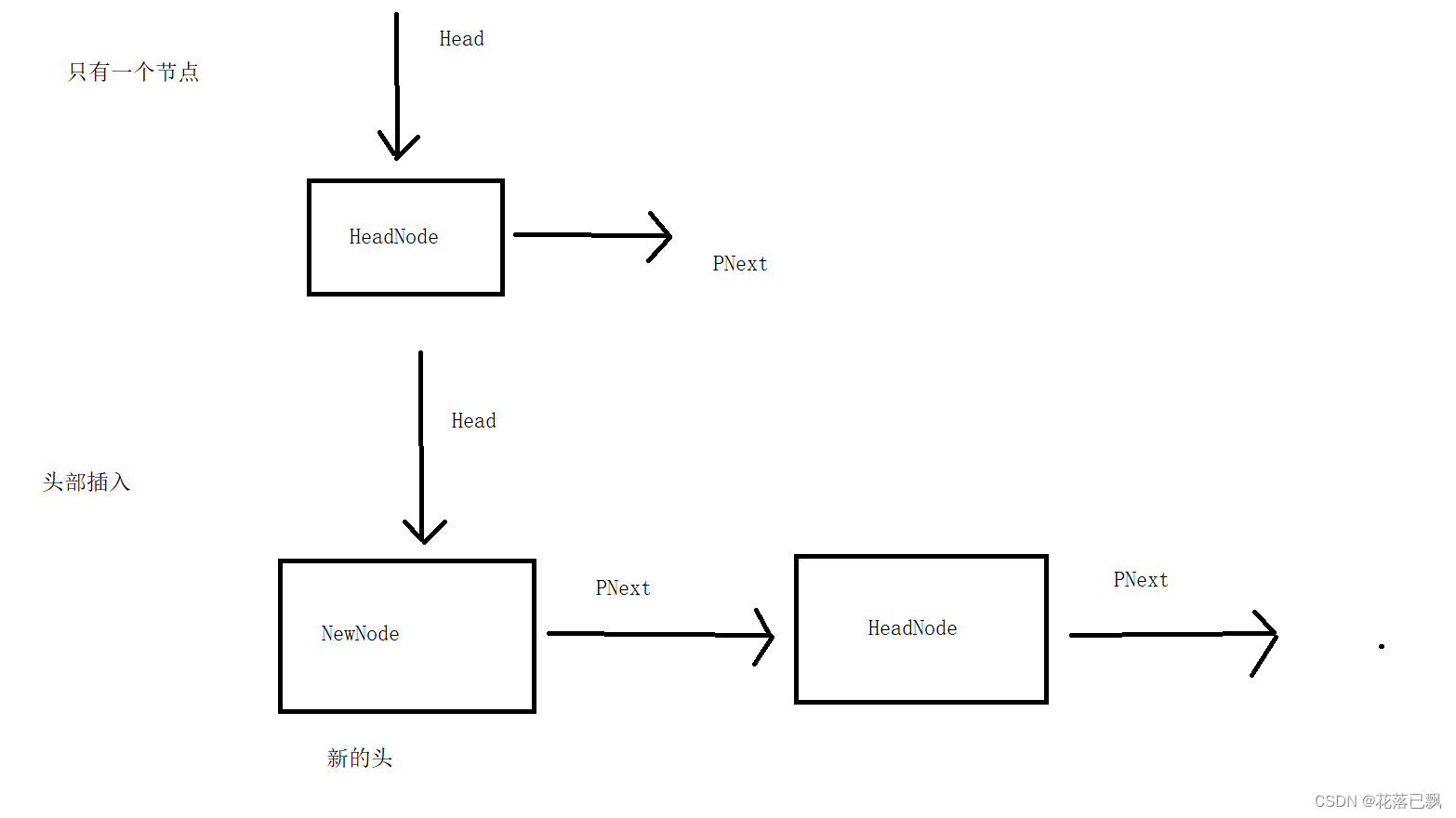
当我们在链表的头部插入节点时,意味着我们要将一个新的节点插入到链表的开头位置。
首先需要使用malloc函数来分配一个节点,有了节点后我们才可以进行插入操作。
进行头部插入只需要将新分配的节点的PNext指向原来的头指针,然后再将头指针指向新的节点。
这个时候新的节点就成为了头节点。
#include <stdio.h>
#include <malloc.h>
/* 定义链表节点 */
typedef struct node
{
int data; // 节点存储的数据
struct node* PNext; // 指向下一个节点的指针
}Node;
/* 初始化链表 */
Node* InitList(void)
{
Node* head = (Node*)malloc(sizeof(Node));
if (head != NULL)
{
head->data = 0;
head->PNext = NULL;
}
return head;
}
/* 头部插入 */
void HeadAdd(Node** HeadNode, int data)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
if (NewNode != NULL)
{
NewNode->data = data;
NewNode->PNext = *HeadNode;
*HeadNode = NewNode;
}
}
int main(void)
{
Node* Head = InitList();
HeadAdd(&Head, 1);
printf("%d\n", Head->data);//打印1
printf("%d\n", Head->PNext->data);//打印0
free(Head);
return 0;
}
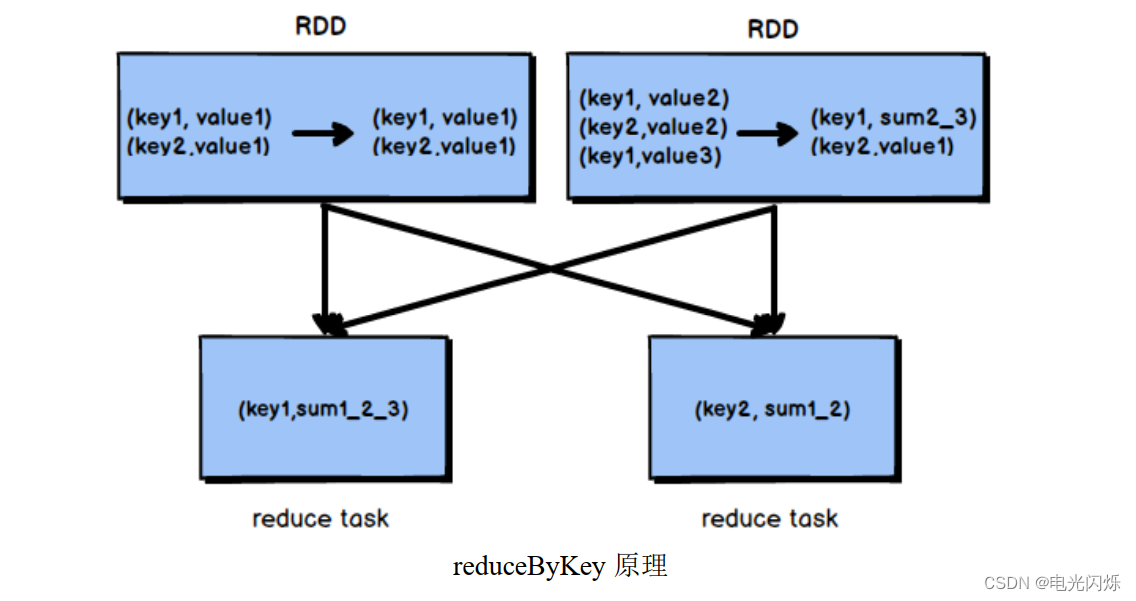
这里使用一张图来帮助大家理解:
2.尾部插入
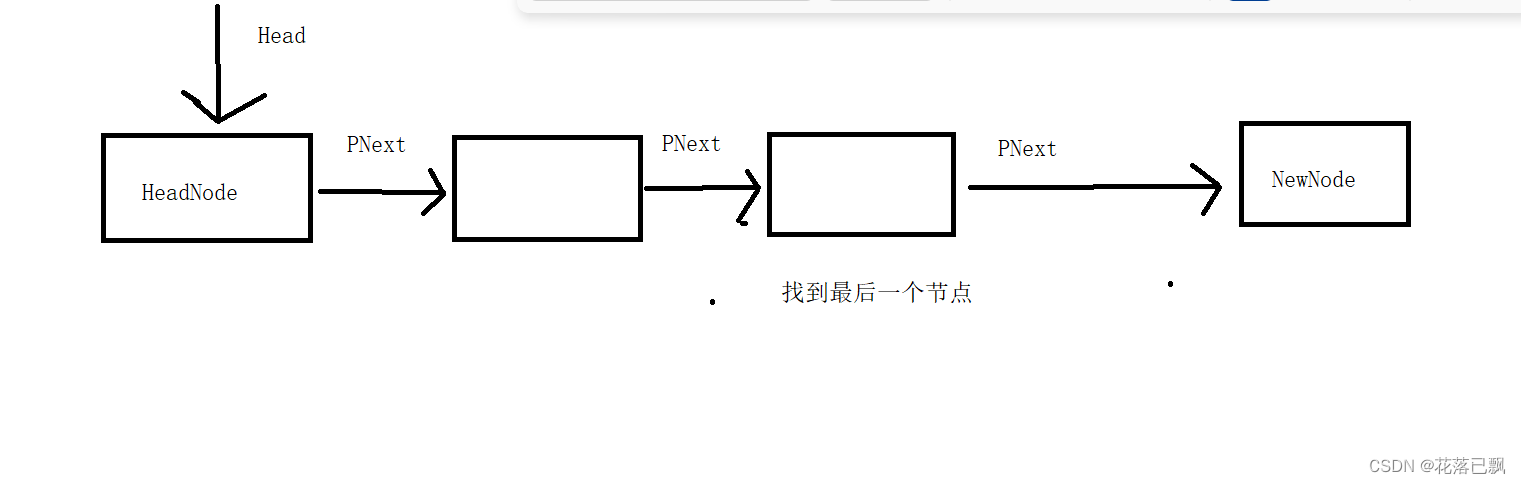
尾部插入要比头部插入稍微难一点,因为需要先找到最后的一个节点,然后将最后一个节点的下一个指针指向新的节点,这里就涉及到了链表的遍历了。我们放下面讲解。
#include <stdio.h>
#include <malloc.h>
/* 定义链表节点 */
typedef struct node
{
int data; // 节点存储的数据
struct node* PNext; // 指向下一个节点的指针
}Node;
/* 初始化链表 */
Node* InitList(void)
{
Node* head = (Node*)malloc(sizeof(Node));
if (head != NULL)
{
head->data = 0;
head->PNext = NULL;
}
return head;
}
/* 头部插入 */
void HeadAdd(Node** HeadNode, int data)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
if (NewNode != NULL)
{
NewNode->data = data;
NewNode->PNext = *HeadNode;
*HeadNode = NewNode;
}
}
/* 尾部插入 */
void TailAdd(Node** HeadNode, int data)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
if (NewNode != NULL)
{
NewNode->data = data;
NewNode->PNext = NULL;
/* 判断链表是否为空 */
if (*HeadNode == NULL)
{
*HeadNode = NewNode;
}
else
{
Node* current = *HeadNode;
while (current->PNext != NULL)
{
/* 遍历链表找出最后一个节点 */
current = current->PNext;
}
/* 将最后一个节点的下一个指针指向新的节点 */
current->PNext = NewNode;
}
}
}
int main(void)
{
Node* Head = InitList();
TailAdd(&Head, 1);
printf("%d\n", Head->data);//打印0
printf("%d\n", Head->PNext->data);//打印1
free(Head);
return 0;
}
3.中间插入
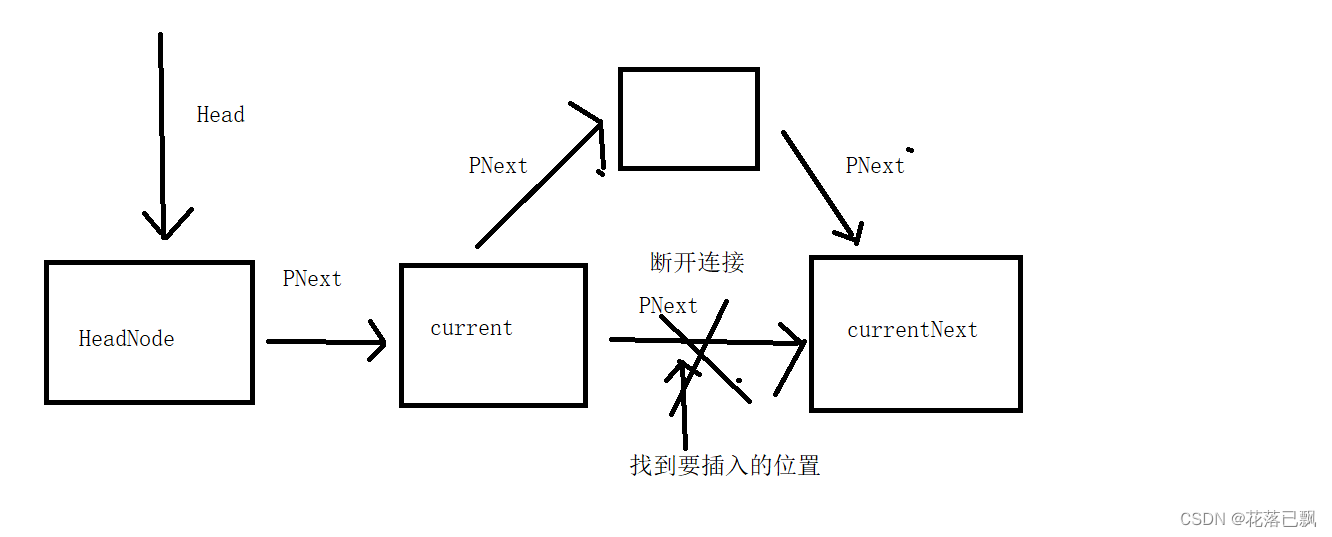
中间插入的话就会稍微复杂一点了,因为是在中间进行插入操作,首先需要找到对应的位置,并且需要关注前后两个节点的PNext指针指向。
/* 中间插入 */
void MiddleAdd(Node** HeadNode, int data, int index)
{
Node* NewNode = (Node*)malloc(sizeof(Node));
Node* current = *HeadNode;
int i = 0;
if (NewNode != NULL)
{
NewNode->data = data;
/* 判断链表是否为空 */
if (*HeadNode == NULL)
{
*HeadNode = NewNode;
}
else if (current->PNext == NULL)
{
/* 只有一个节点直接使用尾部插入 */
TailAdd(HeadNode, data);
}
else
{
for (i = 0; i < index - 1; i++)
{
/* 遍历链表找到要插入位置的前一个链表节点 */
current = current->PNext;
}
Node* currentNext = current->PNext;/* 记录要插入位置的下一个节点 */
current->PNext = NewNode;
NewNode->PNext = currentNext;
}
}
}
六、遍历链表
链表的遍历其实并不难,我们使用一个名为current的指针来追踪当前节点,初始化为*HeadNode。如果当前节点不为NULL,就继续移动current指针到下一个节点,遍历到链表的结尾。
/* 遍历链表 */
void TraverseList(Node* HeadNode)
{
Node* current = HeadNode;
while (current != NULL)
{
printf("Node data : %d\n", current->data);
current = current->PNext;//向后移动一个位置
}
}
七、释放链表
释放链表也是比较简单的,和遍历链表的操作有一些类似,只不过这里多了一步操作就是需要记录当前节点,当当前节点移动后对当前节点进行free释放,这样就可以完成链表的释放了。
/* 释放链表 */
void FreeList(Node* HeadNode)
{
Node* Nowcurrent = HeadNode;
Node* Oldcurrent = NULL;
while (Nowcurrent != NULL)
{
Oldcurrent = Nowcurrent;/* 记录当前链表节点 */
Nowcurrent = Nowcurrent->PNext;//向后移动一个位置
free(Oldcurrent);/* 释放当前链表节点 */
}
}
总结
本篇文章开始我们会开始使用C语言来讲解数据结构中的知识,希望大家可以跟着我好好的掌握这些知识,掌握了数据结构后对C语言的提高会有很大的帮助。
本篇文章的代码将同步到公众号中提供给大家使用。