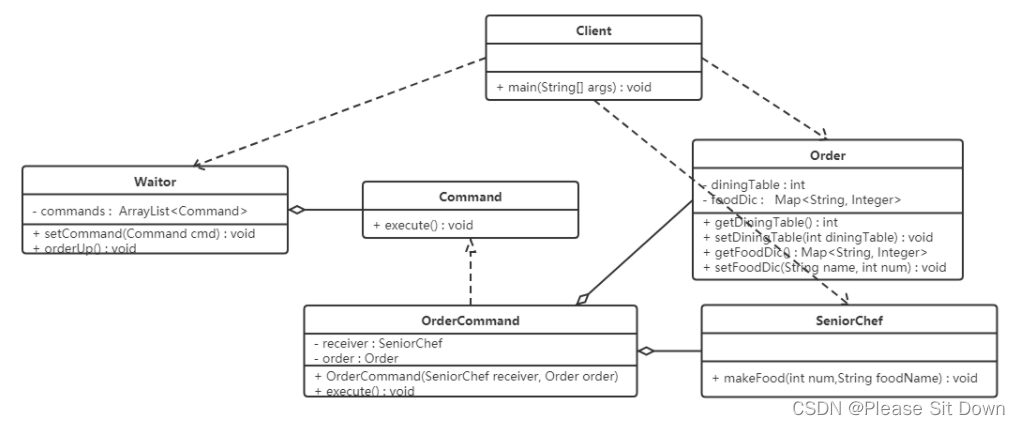
背景
host内核裁剪时会进行收益的比较,比如裁剪前用5.10最新内核得出内存数据,然后和裁剪后的内存数据进行对比。
在进行对比中,发现裁剪后的内存available比裁剪前多了10个G,有点不正常了,需要分析下这10个G到底是怎么多出来的
5.10 最新内核:

裁剪后的内核:


available计算方法:
available是通过 si_mem_available 函数获取的,分析 si_mem_available 就可以给出available计算方法
available = global_zone_page_state(NR_FREE_PAGES) - totalreserve_pages;
/*
* Not all the page cache can be freed, otherwise the system will
* start swapping. Assume at least half of the page cache, or the
* low watermark worth of cache, needs to stay.
*/
pagecache = pages[LRU_ACTIVE_FILE] + pages[LRU_INACTIVE_FILE];
pagecache -= min(pagecache / 2, wmark_low);
available += pagecache;
/*
* Part of the reclaimable slab and other kernel memory consists of
* items that are in use, and cannot be freed. Cap this estimate at the
* low watermark.
*/
reclaimable = global_node_page_state_pages(NR_SLAB_RECLAIMABLE_B) +
global_node_page_state(NR_KERNEL_MISC_RECLAIMABLE);
available += reclaimable - min(reclaimable / 2, wmark_low);通过代码可以大致概括 available = free + pagecache + kernel_reclaimable - totalreserve_pages
上面公式里的 free 是 "free 命令" 里看到的 free,另外pagecache和kernel_reclaimable 也都是大于0的,所以 available 比 free 大10G,肯定是出在 totalreserve_pages 上了,所以接下来需要分析 totalreserve_pages 是怎么计算的
static void calculate_totalreserve_pages(void)
{
struct pglist_data *pgdat;
unsigned long reserve_pages = 0;
enum zone_type i, j;
for_each_online_pgdat(pgdat) {
pgdat->totalreserve_pages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
long max = 0;
unsigned long managed_pages = zone_managed_pages(zone);
/* Find valid and maximum lowmem_reserve in the zone */
for (j = i; j < MAX_NR_ZONES; j++) {
if (zone->lowmem_reserve[j] > max)
max = zone->lowmem_reserve[j];
}
/* we treat the high watermark as reserved pages. */
max += high_wmark_pages(zone);
if (max > managed_pages)
max = managed_pages;
pgdat->totalreserve_pages += max;
reserve_pages += max;
}
}
totalreserve_pages = reserve_pages;
}calculate_totalreserve_pages 函数会遍历numa node下所有的zone,然后把zone下的 lowmem_reserve 和 zone的 watermark[WMARK_HIGH] (也就是内存回收的高水位) 相加,然后得到 totalreserve_pages;
zone下的 lowmem_reserve 和 zone 的内存回收高水位他们的值分别是多少,去哪里看呢,可以通过 /proc/zoneinfo 查看。
lowmem_reserve:
cat /proc/zoneinfo | grep protection 输出的就是lowmem_reserve,有两行,一行表示numa0, 一行表示numa1,数组里几个数字分别表示不同zone下的lowmem_reserve,具体是 dma zone, dma32 zone, normal zone, moveable zone, device zone。
[root@localhost /mnt]# cat /proc/zoneinfo | grep protection
protection: (0, 1221, 9401, 9401, 9401)
protection: (0, 0, 8180, 8180, 8180)
[root@localhost ~]# cat /proc/zoneinfo | grep protection
protection: (0, 1221, 9401, 9401, 9401)
protection: (0, 0, 8180, 8180, 8180)zoneinfo里的 protection就是 lowmem_reserve ,能看出5.10单机最新内核和我们裁剪过的内核,两者值是一样的
所以导致available不同的只可能是 watermark[WMARK_HIGH],所以接下来分析zone的高水位是怎么算出来的。
zone高水位值 high_wmark_pages:
zone的low水位和high水位是在 __setup_per_zone_wmarks 里设置的,需要分析 __setup_per_zone_wmarks 函数
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone) {
lowmem_pages += zone_managed_pages(zone);
}
for_each_zone(zone) {
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages);
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->_watermark[WMARK_MIN] = tmp;
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
zone->watermark_boost = 0;
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
spin_unlock_irqrestore(&zone->lock, flags);
}
}这个函数初步看会很比较迷糊,linux kernel的一些写法和普通的用户态程序相比会有些奇怪,mult_frac是用第一个参数乘以 第二个参数分子和第三个参数的分母组成的分数。
mult_frac(zone_managed_pages(zone), watermark_scale_factor, 10000) 的意思相当于 总内存 * watermark_scale_factor / 10000, watermark_scale_factor 表示是总内存的万分之几。
watermark_scale_factor 这是个内核参数,可以配置,也可以使用默认值。
于是sysctl -a | grep watermark_scale_factor 发现两个内核版本之间这个值果然不一样。
结论
我们新内核的代码把 watermark_scale_factor 改成了100,这样高水位内存值自然就上去了。
那为什么我们内核裁剪的内核available会多些了,在空闲内存都是25G的情况下,available增加必然和 watermark_scale_factor有关,因为我是基于master分支打的包,于是查看master的watermark_scale_factor相关改动,https://console.google./devops/icode/cbu/linux-5-10/commits/e35d40db5c44f1ceae7b240c547fcbc0e1a2fb1a/mm/page_alloc.c,原来前段时间解决pdd抖动
所以是因为这个改动导致的available减少10G的,并不是我们内核裁剪增加了10G的available
watermark_scale_factor 决定多少空闲内存的时候开始回收内存,
10, 是千分之一整个系统内存的时候开始回收,1T的物理机,也就是只剩下1G的时候开始回收,2g的时候结束回收。
100, 是百分之一整个系统内存的时候开始回收,1T的物理机,也就是只剩下10G的时候开始回收,20G的时候结束回收。
对于我们的1T的机器,只有30g左右不是内存大页,10g开始回收内存太频繁了。
最近内核大佬在解决pdd虚拟机抖动问题的时候把这个也解决了,所以下次出的5.10内核rpm包是不会有available和free差异很大的情况了。