文章目录
- 【半监督医学图像分割 2023 CVPR】PatchCL
- 摘要
- 1. 简介
- 2. 相关工作
- 2.1 半监督学习
- 2.2 对比学习
- 3. 方法
- 3.1 类感知补丁采样
- 3.2 伪标记引导对比损失
- 3.3 总体学习目标
- 3.4 伪标号生成与求精
- 4. 实验
- 5. 结果
【半监督医学图像分割 2023 CVPR】PatchCL
论文题目:Pseudo-label Guided Contrastive Learning for Semi-supervised Medical Image Segmentation
中文题目:伪标记引导的对比学习用于半监督医学图像分割
论文链接:CVPR 2023 Open Access Repository (thecvf.com)
论文代码:https://github.com/hritam-98/PatchCL-MedSeg
论文团队:
发表时间:
DOI:
引用:
引用数:
摘要
尽管最近在半监督学习(SemiSL)方面的工作在自然图像分割方面取得了巨大的成功,但从有限的注释中学习鉴别性表征的任务在医学图像中一直是一个公开的问题。对比学习(CL)框架使用相似性测量的概念,这对分类问题是有用的,然而,他们未能将这些高质量的表示转移到准确的像素级分割中。为此,我们提出了一个新颖的基于patch的半监督医学图像分割框架,而不使用任何明确的前提任务。我们利用了对比学习和半监督学习的力量,其中半监督学习产生的伪标签通过提供额外的指导来帮助CL,而在CL中学习的鉴别性类别信息导致了准确的多类分割。
此外,我们制定了一个新的损失,协同鼓励所学表征的类间可分离性和类内紧凑性。一个新的patch间语义差异映射,使用平均patch熵,在拟议的分类法框架中被用来指导阳性和阴性的采样。在三个公开的多模态数据集上的实验分析表明,与最先进的方法相比,我们提出的方法具有优越性。
1. 简介
医学图像的准确分割为临床医生提供了突出的、有洞察力的信息,以便进行适当的诊断、疾病的发展和适当的治疗计划。随着最近神经网络的兴起,有监督的深度学习方法在多种医学图像分割任务中取得了一流的性能[11, 36, 41]。这可以归功于大型注释数据集的可用性。但是,大规模地获得像素注释往往是费时的,需要专业知识,并产生巨大的成本,因此缓解这些要求的方法是非常便利的。
基于半监督学习(SemiSL)的方法是实现这一目标的有希望的方向,需要非常少量的注释,并为很大一部分未标记的数据产生伪标签,这些伪标签被进一步利用来训练分割网络[32, 33]。近年来,这些方法因其在下游任务(如分割、物体检测等)中的优异表现而被广泛认可,不仅在自然场景图像中,在生物医学图像分析中也是如此[3, 4, 64]。传统的SemiSL方法采用回归、像素交叉熵(CE)或平均平方误差(MSE)损失项或其变体。但是,这些损失都没有规定类内紧凑性和类间可分离性,限制了它们的全部学习潜力。最近在医学视觉中采用自我组合策略的SemiSL方法[14,44]由于其在分割任务中的最先进的性能而受到关注。然而,它们是为单一的数据集设计的,不能跨领域通用。
无监督领域适应性(UDA)[18, 61]可以用来解决这个问题,例如,Xie等人[60]提出了一个高效的UDA方法,采用自我训练策略来释放学习潜力。然而,这些方法大多严重依赖丰富的源标签,因此在临床部署中,在有限的标签下产生不合格的性能[71]。表征学习是另一种有希望的从有限的注释中学习的方法,在大型源域中为借口任务训练的模型可以转移到目标域的下游任务中。目前,表征学习的进展被归结为对比学习(CL)的上升[23],其目的是在一个投影嵌入空间的指定锚点上区分相似的样本(正面)和不相似的样本(负面)。这个想法通过从大规模的无标签数据中学习有用的表征,在自我监督范式中取得了实质性的进展[9, 43, 57]。嵌入空间的基本思想是将语义相似的样本拉到一起,并将不相似的样本推开,在EM嵌入空间中。这是通过适当地设计一个目标函数来实现的,该函数也被称为对比性损失函数,它优化了不同数据点之间的相互信息。此后,从借口任务中学到的信息可以被转移到下游任务中,如分类[62]、分割[53, 66]等。
尽管近年来CL框架取得了巨大的成功,但也不是没有问题,其中大致包括:
(a) [15]中报告了采样偏差和加剧的类碰撞,因为语义相似的实例由于无指导地选择负面样本而被强行对比[9],导致性能不达标;
(b) 正如[21]中建议的那样,在CL中,将在源域的现有大规模数据集(例如ImageNet)上为某些借口任务训练的模型适应目标域的特定下游任务,是一种常见和理想的做法。然而,异质数据集的重大领域转移往往会损害整体性能[73],特别是在医学图像中;
© 设计一个合适的借口任务可能具有挑战性,而且往往不能在不同的数据集上通用[37]。这些问题中的第一个可以通过获得标记的样本来解决。例如,[27]显示,包括标签可以显著提高分类性能,但这是在完全监督的情况下。最近有一些尝试来部分解决后两个问题,这些尝试在第2节中强调。
我们的建议和贡献从这些尚未解决的问题中汲取动力,我们旨在通过几个新颖的贡献来利用CL在SEMISL领域的潜力:
- 我们通过利用CL和SemiSL的力量提出了一种新的端到端分割范式。在我们的案例中,半监督学习中生成的伪标签通过为度量学习策略提供额外的指导来帮助对比学习,而CL中重要的类区分性特征学习则提升了SemiSL的多类分割性能。因此,SemiSL在医学图像分割任务中对CL有帮助,反之亦然。
- 我们提出了一种新的伪标签引导对比损失(PLGCL),它可以在不对借口任务进行任何显式训练的情况下挖掘类别区分特征,从而证明了在多个领域的推广能力。
- 我们采用了一个基于补丁的CL框架,其中正负补丁是从一个基于熵的度量中采样的,该度量是由在SEMISL设置中获得的伪标记指导的。 这防止了(类冲突),即CL中语义相似的实例之间的强烈和无指导的对比。
- 通过对来自不同领域的三个数据集的评价,证明了该方法的有效性,增强了该方法的推广性和鲁棒性。
2. 相关工作
2.1 半监督学习
基于SemiSL的方法从大量未标记的样本中提取有用的表征,同时对少数标记的样本进行监督学习。现有的SemiSL方法采用的策略包括伪标签[35,42]、一致性正则化[4,26]、熵最小化[22, 49]等。基于伪标签的方法采用在已标记的数据上进行模型训练,然后在未标记的数据集上生成伪标签。然后使用不确定性引导的细化[50]、随机传播[16]等方法对生成的伪标签的质量进行微调。由于采购用于语义分割的像素注释成本很高,基于一致性的方法对增强的输入图像[17]或增强的特征嵌入[39]执行一致的预测,而不使用注释。熵的最小化使模型在未标记的数据上输出低熵的预测[20]。整体性的方法也采用这些方法的组合来完成各种任务[6, 46]。
另一种在半监督医学图像分割中广泛使用的方法是Mean Teacher[47],它鼓励学生和教师模型之间的一致预测。 近年来,它被推广到多个SEMISL算法中。 于等人。 [65]提出了一个不确定性引导的均值教师框架(UA-MT),结合转换一致性来提高性能。 王等人。 [52]提出了一个三不确定性引导的均值教师框架,定义了两个辅助任务:在均值教师网络上重建符号距离场和预测符号距离场,以帮助模型学习显著特征以获得更好的预测。 杭等人。 [22]在均值教师网络上采用了全局-局部结构感知熵最小化方法。 自训练方法[60,66]包含了来自未标记数据的预测的额外信息,这些信息可以用来改进模型的性能。 然而,现有的大多数半监督分割方法都没有明确地强调类间可分性问题,从而无意中限制了它们的性能,我们在本文中试图解决这一问题。
2.2 对比学习
近年来,出现了几种强大的(非)相似性学习方法,采用对比性损失来完成各种计算机视觉任务[12, 13, 37, 40]。大多数以前的分类方法都是在自我监督的预训练中使用,以设计一个强大的特征提取器,然后将其转移到下游任务中[9, 54]。对于生成阳性对,这些方法在很大程度上依赖于数据增强,这一点得到了[2, 67]的支持,不过值得注意的是,大量的阴性对对于这些方法的成功至关重要[8]。
Zhao等人[69]设计了一种CL策略来挖掘图像级和斑块级表示之间的关系特征。
最近,Wang等人[55]证明了跨图像对比学习在医学图像分割中的优势。
然而,在这种情况下,CL的一个主要缺点是类碰撞问题[1,72] --由于天真的CL目标的不知情的负选择,语义相似的斑块被强行对比。如[28]所示,这大大损害了多类情况下的分割性能。我们的工作旨在缓解这一问题,提出了一种新的半监督式分割中的一致性正则化的整合。与Boserup等人[7]需要额外的置信度网络不同,我们利用伪标签对正反两方面的查询进行基于熵的抽样,进行对比学习。
最近的一些进展在半监督环境中使用对比学习[21,25,68],其中以分类任务为借口训练的模型可以有效地转移到分割任务中。 然而,它们都没有有效地利用来自SEMISL的伪标签来精化CL,反之亦然。 此外,这些方法的成功依赖于精心设计的借口任务,以及在借口任务域和最终分割域之间最小化的域转移。
本文试图通过在半监督环境中有效地利用对比学习来设计一个端到端的切分框架来解决这些问题。
柴坦尼亚等人。 [10]提出了一种基于局部对比学习的基于伪标签指导的自我训练策略。 然而,尚不清楚他们提出的像素级CL如何在没有仔细选择正负的情况下学习鉴别特征。
此外,他们的方法缺乏任何伪标签精化策略,而伪标签精化策略是生成伪标签质量的基础,与度量学习方案直接相关。 此外,它们的像素级CL框架还存在内存不足的问题,限制了它们对一小部分像素进行子采样,并抑制了模型学习全局信息的能力。 针对这些问题,我们提出了以伪标签为指导的分块对比学习算法,并联合优化SEMISL中的CL损失和一致性损失,在学习特征表示的同时对伪标签进行精化。
3. 方法
给出了一个标记图像集 I L \mathbb{I}_L IL及其对应的标记集 Y L \mathbb{Y}_{L} YL和一个未标记图像集 I U {\mathbb I}_U IU,它们分别包含 N L N_{L} NL和 N U N_{U} NU个数的图像(其中 N L < < N U \mathcal{N}_L<<\mathcal{N}_U NL<<NU),我们引入了一种基于伪标记的片状对比学习策略,该策略旨在从 I L \mathbb{I}_L IL和 I U \mathbb{I}_U IU中学习信息。
我们提出的方法可以分为四个步骤:
首先,我们定义了以有效利用(真或伪)标记为指导的贴片生成(第3.1节),
然后我们提出了一个新的对比损失函数(第3.2节)。
之后,我们定义了总体学习目标(3.3小节),
最后在3.4小节中描述了伪标签生成和精化策略。
3.1 类感知补丁采样
让我们用 I i I_i Ii表示一个小批量的第 i t h i^{th} ith幅图像,包含 M M M个像素,其中图像中的第 m t h m^{th} mth个像素用 I i ( m ) I_{i}(m) Ii(m)表示 m ∈ [ 1 , M ] m\in[1,M] m∈[1,M]。
我们提出的框架使用编码器和解码器网络 E S \mathcal{E}_S ES和 D S \mathcal{D}_S DS,分别以 θ E , S \theta_{\mathcal{E},S} θE,S和 θ D , S \theta_{\mathcal{D},S} θD,S为参数,从 I i I_i Ii中生成伪标签 Y i ′ Y_i' Yi′,它可以等效地表示为类信任度 C i A C_iA CiA,即 [ E S , D S ] : I i → C i [{\mathcal{E}}_{S},{\mathcal{D}}_{S}]:I_{i}\rightarrow C_{i} [ES,DS]:Ii→Ci。
这里 C i = { C i k ( m ) } C_{i}=\{C_{i}^{k}(m)\} Ci={Cik(m)}, C i k ( m ) C_{i}^{k}(m) Cik(m)表示图像 I I I_I II的像素 M M M属于类 k k k的置信度,其中 k = { 1 , 2 , . . K } , K ( ≥ 1 ) k=\{1,2,..K\},K(\geq1) k={1,2,..K},K(≥1)表示分割图中的类的数量。此后,这个置信图与 L i L_i Li相乘,得到出席的图像 I i ′ k = I i ⊙ C i k I_{i}^{'k}= I_{i}\odot C_{i}^{k} Ii′k=Ii⊙Cik,其中( ⊙ \odot ⊙)表示元素相乘。这个被关注的图像会被生成patch,其中第 k k k类的第 i i i个被关注图像的第j个补丁用 P i , j k P_{i,j}^{k} Pi,jk来表示。
给定一个来自类 K K K的anchor patch,所有包含类 K K K的对象(或它的某些部分)的patch都被视为正的,而所有来自其他类( K − 1 K-1 K−1)的补丁都被视为负的。
大量patch的适当取样对对比学习至关重要。 我们可以根据它们的类置信度对斑块进行采样,例如,一个patch的平均置信度
P
i
,
j
k
P_{i,j}^k
Pi,jk计算如下:
A
v
g
i
,
j
k
=
∑
m
∈
P
i
,
j
k
C
i
k
(
m
)
∣
P
i
,
j
k
∣
.
Avg_{i,j}^k=\frac{\sum\limits_{m\in P_{i,j}^k}C_i^k(m)}{|P_{i,j}^k|}.
Avgi,jk=∣Pi,jk∣m∈Pi,jk∑Cik(m).
高的平均patch置信度表明斑块
P
i
,
j
k
P_{i,j}^k
Pi,jk更有可能包含属于
k
k
k类的物体(或其一部分),而接近于0的值则表示相反。
介于两者之间的值表示任何一个方向的不确定性。然而, A v g i , j k Av g_{i,j}^{k} Avgi,jk只是基于patch对 k k k类的信心,它忽略了两个重要的项目:(i)patch的强度外观信息和(ii) k k k类与其他( K − 1 K-1 K−1)类之间的信心不确定性。
因此,我们建议根据出席的图像
I
i
′
k
I_{i}^{'k}
Ii′k来计算平均patch熵。对于一个patch
P
i
,
j
k
P_{i,j}^{k}
Pi,jk来说,它的平均patch熵是由出席图像
I
i
′
k
I_{i}^{'k}
Ii′k中的像素强度值计算出来的,表示为:
E
n
t
i
,
j
k
=
∑
m
∈
P
i
,
j
k
F
(
I
i
′
k
(
m
)
)
∣
P
i
,
j
k
∣
,
w
h
e
r
e
F
(
x
)
=
−
x
log
(
x
)
−
(
1
−
x
)
log
(
1
−
x
)
\begin{gathered} E n t{}_{i,j}^{k}=\frac{ \sum_{m\in P_{i,j}^{k}} \mathcal{F}(I^{'k}_i(m)) }{|P_{i,j}^{k}|},\mathbf{where} \\ \mathcal{F}(x)=-x\log(x)-(1-x)\log(1-x) \end{gathered}
Enti,jk=∣Pi,jk∣∑m∈Pi,jkF(Ii′k(m)),whereF(x)=−xlog(x)−(1−x)log(1−x)
是熵函数,
I
i
′
k
(
m
)
I_i^{'k}(m)
Ii′k(m)是贴片内第
m
t
h
m^{th}
mth个像素的强度值。
E
n
t
i
,
j
k
Ent_{i,j}^{k}
Enti,jk反映了图像
i
i
i中贴片
j
j
j的三种信息:属于
K
K
K类的置信度、关于其他
(
K
−
1
)
(K-1)
(K−1)类的不确定性和来自II的强度显现(注意,
I
i
′
k
=
I
i
⊙
C
i
k
I_{i}^{'k}=I_{i}\odot C_{i}^{k}
Ii′k=Ii⊙Cik)。
因此,对于给定的K类锚点块,所有ENTK I值为N最近的块都被认为是正的,其余的都被认为是负的。 这些贴片通过编码器 E S {\mathcal{E}}_{S} ES和投影头 H S \mathcal{H}_{S} HS来获得特征嵌入,然后在下面的部分中用于对比损失公式。 锚点的嵌入被认为是查询,这与来自其他补丁的所有其他嵌入(被认为是键)进行了对比,这是我们对比学习的基础。 这一整体管道如图1(a)所示。
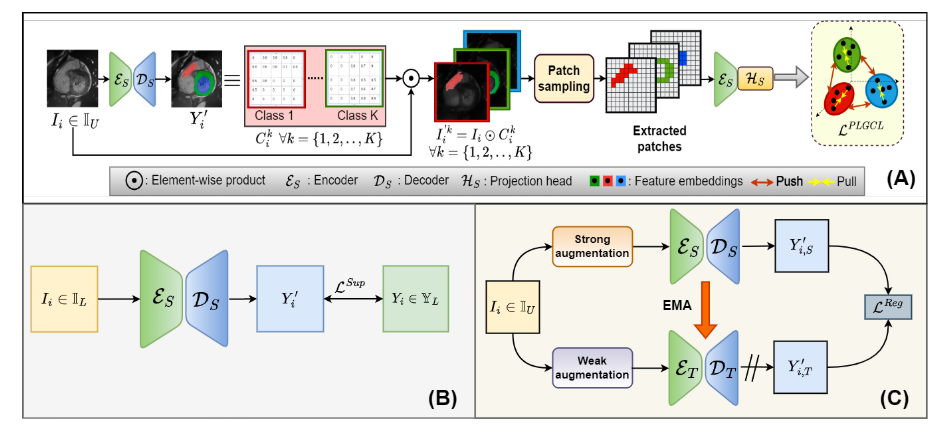
我们提出的方法的总体工作流程。
(a)我们提出的伪标签引导对比学习策略(详见第3.1和3.2小节);
(b)利用有监督损失 L S u p \mathcal{L}^{Sup} LSup从标记图像 I i ∈ I L I_{i}\in\mathbb{I}_{L} Ii∈IL中学习学生编码器ES和解码器DS;
©计算教师模型(编码器 E T {\mathcal{E}}_{T} ET和解码器 D T {\mathcal{D}}_{T} DT)对弱增广的未标记图像 I i ∈ I U I_{i}\in\mathbb{I}_{U} Ii∈IU的预测与学生模型对强增广的预测之间的正则化损失 L R e g \mathcal{L}^{Reg} LReg。 使用来自学生分支的指数移动平均(EMA)更新 E T {\mathcal{E}}_{T} ET和 D T {\mathcal{D}}_{T} DT的权重。
3.2 伪标记引导对比损失
我们提出了一种新的伪标签引导的对比性损失(PLGCL),假设无标签集IU有伪标签 Y U ′ \mathbb{Y}_U' YU′(伪标签的生成将在3.4小节中解释)和有标签的样本( I L , Y L \mathbb{I}_{L},\mathbb{Y}_{L} IL,YL)。
以前的工作,如JCL[8],只对给定查询的阳性样本分布计算InfoNCE损失[38]的期望值。在我们的案例中,由于存在着以类为单位的信息,我们可以对正负键的类条件的联合分布进行InfoNCE的期望值,这是PLGCL的基础。
让 k k k类的第 u u u个查询patch表示为 P u P_u Pu,如果 v v v是正的(即它与补丁Pu具有相同的伪/真类),其对应的第 v v v个密钥补丁为 P v k + P_{v}^{k_+} Pvk+;
否则,表示为
P
v
k
−
P_{v}^{k_-}
Pvk−(不同于k类的负密钥补丁)。我们把
P
u
,
P
v
k
+
,
P
v
k
−
P_{u},P_{v}^{k_{+}},P_{v}^{k_{-}}
Pu,Pvk+,Pvk−的嵌入分别表示为
f
u
,
f
v
k
+
,
f
v
k
−
f_{u},f_{v}^{k+},f_{v}^{k-}
fu,fvk+,fvk−, 这样
{
f
u
,
f
v
k
+
,
f
v
k
−
}
←
H
S
(
E
S
(
{
P
u
,
P
v
k
+
,
P
v
k
−
}
)
)
\{f_{u},f_{v}^{k_{+}},f_{v}^{k_{-}}\}\leftarrow {\cal H}_{S}({\cal E}_{S}(\{P_{u},P_{v}^{k_{+}},P_{v}^{k_{-}}\}))
{fu,fvk+,fvk−}←HS(ES({Pu,Pvk+,Pvk−}))。设
f
v
k
+
∼
p
(
⋅
∣
k
+
)
f_{v}^{k_{+}}\sim p(\cdot|k_{+})
fvk+∼p(⋅∣k+)和
f
v
k
−
∼
p
(
⋅
∣
k
−
)
f_{v}^{k_{-}}\sim p(\cdot |k_{-})
fvk−∼p(⋅∣k−),InfoNCE损失相对于联合分布J,在所有类条件密度
p
(
⋅
∣
k
+
)
p(\cdot|k_{+})
p(⋅∣k+)和
p
(
⋅
∣
k
−
)
p(\cdot|k_{-})
p(⋅∣k−)上的期望值表示为:
L
=
−
E
J
log
exp
(
f
u
T
⋅
f
v
k
+
/
τ
)
exp
(
f
u
T
⋅
f
v
k
+
/
τ
)
+
∑
∑
exp
(
f
u
T
⋅
f
v
k
−
/
τ
)
L=-\mathbf{E}_{\mathcal{J}}\log\frac{\exp(f_{u}^{T}\cdot f_{v}^{k_{+}}/\tau)}{\exp(f_{u}^{T}\cdot f_{v}^{k_{+}}/\tau)+\sum\sum\exp(f_{u}^{T}\cdot f_{v}^{k_{-}}/\tau)}
L=−EJlogexp(fuT⋅fvk+/τ)+∑∑exp(fuT⋅fvk−/τ)exp(fuT⋅fvk+/τ)
其中τ是温度参数[12]。 方程4的闭式上界可导出如下:
L
=
E
J
[
log
(
exp
(
f
u
T
⋅
f
v
k
+
/
τ
)
+
∑
k
−
∑
v
exp
(
f
u
T
⋅
f
v
k
−
/
τ
)
)
]
−
E
p
(
⋅
∣
k
+
)
(
f
u
T
⋅
f
v
k
+
/
τ
)
\begin{aligned} L&=\mathbf{E}_{\mathcal{J}}\bigg[\log\Big(\exp(f_u^T\cdot f_v^{k_+}/\tau) \\ &+\sum_{k_-}\sum_v\exp(f_u^T\cdot f_v^{k_-}/\tau))\bigg]-\mathbf{E}_{\operatorname{p}(\cdot|k_+)}\left(f_u^T\cdot f_v^{k_+}/\tau\right) \\ \end{aligned}
L=EJ[log(exp(fuT⋅fvk+/τ)+k−∑v∑exp(fuT⋅fvk−/τ))]−Ep(⋅∣k+)(fuT⋅fvk+/τ)
最后一个方程是利用凹函数上的Jensen不等式得到的,即
E
[
log
(
⋅
)
]
≤
log
[
E
(
⋅
)
]
\mathbf{E}[\log(\cdot)]\quad\leq\quad\log[\mathbf{E}(\cdot)]
E[log(⋅)]≤log[E(⋅)]。 现在,在所有类条件密度
p
(
⋅
∣
k
+
)
p(\cdot|k_{+})
p(⋅∣k+)和
p
(
⋅
∣
k
−
)
p(\cdot|k_{-})
p(⋅∣k−)上,利用高斯性假设[8],我们将它们参数化为
f
v
k
+
∼
N
o
r
m
(
μ
f
v
k
+
,
σ
f
v
k
+
)
f_{v}^{k_{+}}\sim Norm(\mu_{f_{v}^{k_{+}}},\sigma_{f_{v}^{k_{+}}})
fvk+∼Norm(μfvk+,σfvk+)和
f
v
k
−
∼
N
o
r
m
(
μ
f
v
k
−
,
σ
f
v
k
−
)
f_{v}^{k_{-}}\sim Norm(\mu_{f_{v}^{k_{-}}},\sigma_{f_{v}^{k_{-}}})
fvk−∼Norm(μfvk−,σfvk−)。其中
μ
μ
μ和
σ
σ
σ分别表示均值和协方差矩阵。 利用
E
x
(
e
a
T
x
)
=
e
a
T
μ
+
1
2
a
T
σ
a
\mathbf{E}_{x}(e^{a^{T}x})=e^{a^{T}\mu+\frac{1}{2}a^{T}\sigma a}
Ex(eaTx)=eaTμ+21aTσa,当
x
∼
N
o
r
m
(
μ
,
σ
)
x\sim Norm(\mu,\sigma)
x∼Norm(μ,σ)和
E
g
(
a
,
b
,
c
,
.
.
)
h
(
a
)
=
E
g
(
a
)
h
(
a
)
,
\mathbf{E}_{g(a,b,c,..)}h(a)=\mathbf{E}_{g(a)}h(a),
Eg(a,b,c,..)h(a)=Eg(a)h(a),,则方程4的上界导致我们的贴片式伪标记引导的对比损失:
L
u
P
L
G
C
L
=
log
[
exp
(
f
u
T
μ
f
v
k
+
/
τ
+
λ
2
τ
2
f
u
T
σ
f
v
k
+
f
u
)
+
ζ
∑
k
−
e
x
p
(
f
u
T
μ
f
v
k
−
/
τ
+
λ
2
τ
2
f
u
T
σ
f
v
k
−
f
u
)
]
−
f
u
T
μ
f
v
k
+
/
τ
\begin{aligned} \mathcal{L}_{u}^{PLGCL}=\log\left[\exp\left(f_{u}^{T}\mu_{f_{v}^{k+}}/\tau+\frac{\lambda}{2\tau^{2}}f_{u}^{T}\sigma_{f_{v}^{k+}}f_{u}\right)\right. \\ \left.+\zeta\sum_{k_{-}}exp\left(f_{u}^{T}\mu_{f_{v}^{k_{-}}}/\tau+\frac{\lambda}{2\tau^{2}}f_{u}^{T}\sigma_{f_{v}^{k_{-}}}f_{u}\right)\right]-f_{u}^{T}\mu_{f_{v}^{k_{+}}}/\tau \end{aligned}
LuPLGCL=log[exp(fuTμfvk+/τ+2τ2λfuTσfvk+fu)+ζk−∑exp(fuTμfvk−/τ+2τ2λfuTσfvk−fu)
−fuTμfvk+/τ
其中ζ是一个缩放因子,源于
∑
v
\sum_{v}
∑v,即对某一特定类别的所有负嵌入进行求和。如[8]所述,在训练的后期阶段,统计数据的信息量更大,因此λ被用来缩放稳定训练的
σ
f
k
+
\sigma_{f^{k}+}
σfk+的效果。所提出的损失
L
P
L
G
C
L
\mathcal{L}^{PLGCL}
LPLGCL依赖于从
f
v
k
+
,
f
v
k
−
f_{v}^{k_{+}},f_{v}^{k_{-}}
fvk+,fvk−中对
μ
f
v
k
+
,
σ
f
v
k
+
,
μ
f
v
k
−
,
σ
f
v
k
−
\mu_{f_{v}^{k+}},\sigma_{f_{v}^{k+}},\mu_{f_{v}^{k-}},\sigma_{f_{v}^{k-}}
μfvk+,σfvk+,μfvk−,σfvk−的合理估计。我们通过基于熵的抽样策略准确估计正数和负数来解决这个问题(3.1小节)。
3.3 总体学习目标
与所提出的CL框架一起,我们的方法可以在半监督环境中从图像中挖掘重要的像素级信息,为此我们使用了StudentTeacher网络[47]。 我们将学生编码器和解码器分别表示为
E
S
,
D
S
\mathcal{E}_{S},\mathcal{D}_{S}
ES,DS,参数化为
θ
E
,
S
,
θ
D
,
S
\theta_{{\cal E},S},\theta_{{\cal D},S}
θE,S,θD,S,教师编码器-解码器模型
E
T
,
D
T
{\mathcal{E}}_{T},{\mathcal{D}}_{T}
ET,DT,参数化为
θ
E
,
T
,
θ
D
,
T
\theta_{\mathcal{E},T},\theta_{\mathcal{D},T}
θE,T,θD,T。 设学生投影头表示为
H
s
\mathcal{H}_{s}
Hs,参数化为
θ
H
,
S
\theta_{\mathcal{H},S}
θH,S。 在学生-教师网络中,我们将无标记图像的一致性代价
I
i
∈
I
U
I_{i}\in\mathbb{I}_{U}
Ii∈IU定义为学生和教师模型输出之间的交叉熵(CE)损失:
L
i
R
e
g
=
C
E
[
D
S
(
E
S
(
I
i
s
)
)
,
D
T
(
E
T
(
I
i
w
)
)
]
\mathcal{L}_{i}^{Reg}=CE\Big[\mathcal{D}_{S}\Big(\mathcal{E}_{S}(I_{i}^{s})\Big),\mathcal{D}_{T}\Big(\mathcal{E}_{T}(I_{i}^{w})\Big)\Big]
LiReg=CE[DS(ES(Iis)),DT(ET(Iiw))]
其中
I
i
s
I_{i}^{s}
Iis和
I
i
w
I_{i}^{w}
Iiw代表输入
I
i
I_i
Ii的强增强和弱增强。此外,我们计算来自学生编码器-解码器网络的标记样本
I
i
∈
I
L
I_{i}\in\mathbb{I}_{L}
Ii∈IL的预测和可用的地面真相
Y
i
∈
Y
L
Y_{i}\in\mathbb{Y}_{L}
Yi∈YL之间的监督CE损失为:
L
i
S
u
p
=
C
E
[
D
S
(
E
S
(
I
i
)
)
,
Y
i
]
\mathcal{L}_i^{Sup}=CE\Big[\mathcal{D}_S\Big(\mathcal{E}_S(I_i)\Big),Y_i\Big]
LiSup=CE[DS(ES(Ii)),Yi]
最终目标函数可归结为:
L
i
t
o
t
a
l
=
1
∣
B
L
∣
∑
I
i
∈
B
L
L
i
S
u
p
+
β
1
∣
B
U
∣
∑
I
i
∈
B
U
L
i
R
e
g
+
γ
1
∣
B
∣
∑
I
i
∈
B
L
i
P
L
G
C
L
\begin{aligned}\mathcal{L}_i^{total}=\frac{1}{|\mathcal{B}_L|}\sum_{I_i\in\mathcal{B}_L}\mathcal{L}_i^{Sup}+\beta\frac{1}{|\mathcal{B}_U|}\sum_{I_i\in\mathcal{B}_U}\mathcal{L}_i^{Reg}\\+\gamma\frac{1}{|\mathcal{B}|}\sum_{I_i\in\mathcal{B}}\mathcal{L}_i^{PLGCL}\end{aligned}
Litotal=∣BL∣1Ii∈BL∑LiSup+β∣BU∣1Ii∈BU∑LiReg+γ∣B∣1Ii∈B∑LiPLGCL
其中
B
\mathcal{B}
B为被抽样的小批量;
B
L
\mathcal{B}_{L}
BL、
B
U
\mathcal{B}_{U}
BU分别为小批中的标记和未标记样品,
∣
⋅
∣
\left|\cdot\right|
∣⋅∣为设定基数。 在训练期间,使用SGD优化器通过最小化方程8更新学生网络参数,而使用指数移动平均(EMA)更新教师网络参数,如下:
θ
E
,
T
(
t
+
1
)
←
α
θ
E
,
T
(
t
)
+
(
1
−
α
)
θ
E
,
S
(
t
+
1
)
θ
D
,
T
(
t
+
1
)
←
α
θ
D
,
T
(
t
)
+
(
1
−
α
)
θ
E
,
S
(
t
+
1
)
\begin{gather} \theta_{\mathcal{E},T}(t+1)\leftarrow\alpha\theta_{\mathcal{E},T}(t)+(1-\alpha)\theta_{\mathcal{E},S}(t+1) \\ \theta_{\mathcal{D},T}(t+1)\leftarrow\alpha\theta_{\mathcal{D},T}(t)+(1-\alpha)\theta_{\mathcal{E},S}(t+1) \end{gather}
θE,T(t+1)←αθE,T(t)+(1−α)θE,S(t+1)θD,T(t+1)←αθD,T(t)+(1−α)θE,S(t+1)
其中t跟踪步数,α是“平滑系数”[47]或“动量系数”[23]。
3.4 伪标号生成与求精
如图1所示,我们的方法包括三个部分:(a)伪标记引导的对比学习,(b)未标记样本的一致性正则化,©标记样本的监督学习。 对比学习部分需要伪标签作为输入。 为此,我们使用一个小的半监督预热阶段50个历元来生成伪标记,仅使用方程8中的 L R e g \mathcal{L}^{Reg} LReg和 L S u p \mathcal{L}^{Sup} LSup。 分别在学生模型和教师模型中生成图像 I i ∈ I U I_{i}\in\mathbb{I}_{U} Ii∈IU的弱增广和强增广。 我们使用一致性损失LREG(参见等式6)来加强两个获得的输出之间的一致性。 此外,我们还计算了学生模型Y′i对图像 I i ∈ I L I_{i}\in\mathbb{I}_{L} Ii∈IL的分割输出与可用的地面真值 Y i ∈ Y i . Y_{i}\in\mathbb{Y}_{i}. Yi∈Yi.之间的监督CE损失 L S u p \mathcal{L}^{Sup} LSup。
预热训练产生初始伪标签,在预热阶段后引入对比损耗LPLGCL,对模型进行训练,并对伪标签进行细化直至收敛。 使用当前网络参数和计算损失的梯度迭代更新学生模型的参数,而使用来自学生模型的EMA更新教师网络参数(等式9和等式10)。 算法1总结了总体工作流程。
4. 实验
5. 结果
在本文中,我们通过有效地利用伪标签,在Semisl环境中提出了一种新的CL策略。 据我们所知,这是首次尝试在半监督环境中使用一致性正则化和伪标记将CL集成到半监督医学图像分割中。 在多个领域的三个医学分割数据集上,所提出的模态不可知模型的性能优于SOTA方法,证明了该模型的有效性和可推广性。