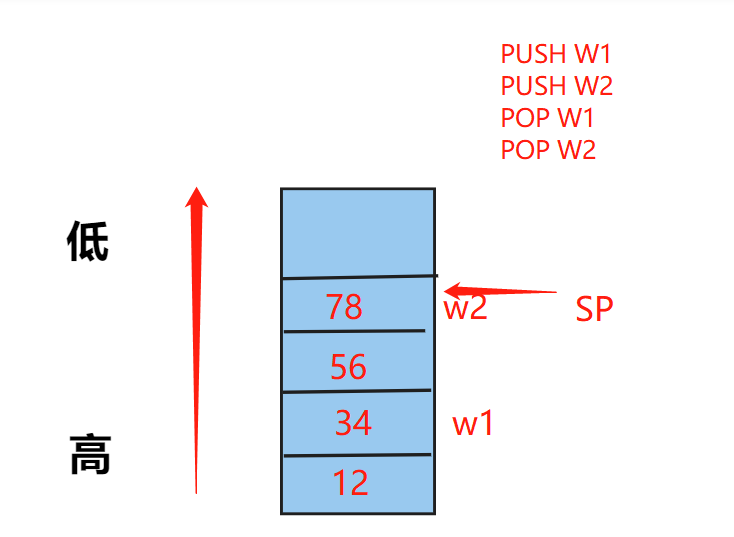
神经网络有许多影响模型性能的超参数。一个最基本的超参数是学习率(LR),它决定了在训练步骤之间模型权重的变化程度。在最简单的情况下,LR值是0到1之间的固定值。
选择正确的LR值是具有挑战性。一方面较大的学习率有助于算法快速收敛,但它也会导致算法在最小值附近跳跃而没有达到它,甚至在它太大时跳过它。另一方面,较小的学习率可以更好地收敛到最小值,但是如果优化器太小,可能需要太长时间才能收敛,或者陷入停滞。
什么是学习率调度器?
一种帮助算法快速收敛到最优的解决方案是使用学习率调度器。学习率调度器在训练过程中根据预先定义的时间表调整学习率。
通常,学习率在训练开始时设置为比较高的值,允许更快的收敛。随着训练的进行,学习率会降低,使收敛到最优,获得更好的性能。在训练过程中降低学习率也称为退火或衰减。
学习率调度器有很多个,并且我们还可以自定义调度器。本文将介绍PyTorch中不同的预定义学习率调度器如何在训练期间调整学习率
学习率调度器
对于本文,我们使用PyTorch 1.13.0版本。你可以在PyTorch文档中关于学习率调度器的细节。
import torch
在本文末尾的附录中会包含用于可视化PyTorch学习率调度器的Python代码。
1、StepLR
在每个预定义的训练步骤数之后,StepLR通过乘法因子降低学习率。
from torch.optim.lr_scheduler import StepLR
scheduler = StepLR(optimizer,
step_size = 4, # Period of learning rate decay
gamma = 0.5) # Multiplicative factor of learning rate decay

2、MultiStepLR
MultiStepLR -类似于StepLR -也通过乘法因子降低了学习率,但在可以自定义修改学习率的时间节点。
from torch.optim.lr_scheduler import MultiStepLR
scheduler = MultiStepLR(optimizer,
milestones=[8, 24, 28], # List of epoch indices
gamma =0.5) # Multiplicative factor of learning rate decay

3、ConstantLR
ConstantLR通过乘法因子降低学习率,直到训练达到预定义步数。
from torch.optim.lr_scheduler import ConstantLR
scheduler = ConstantLR(optimizer,
factor = 0.5, # The number we multiply learning rate until the milestone.
total_iters = 8) # The number of steps that the scheduler decays the learning rate

如果起始因子小于1,那么学习率调度器在训练过程中会提高学习率,而不是降低学习率。
4、LinearLR
LinearLR -类似于ConstantLR -在训练开始时通过乘法因子降低了学习率。但是它会在一定数量的训练步骤中线性地改变学习率,直到它达到最初设定的学习率。
from torch.optim.lr_scheduler import LinearLR
scheduler = LinearLR(optimizer,
start_factor = 0.5, # The number we multiply learning rate in the first epoch
total_iters = 8) # The number of iterations that multiplicative factor reaches to 1

5、ExponentialLR
ExponentialLR在每个训练步骤中通过乘法因子降低学习率。
rom torch.optim.lr_scheduler import ExponentialLR
scheduler = ExponentialLR(optimizer,
gamma = 0.5) # Multiplicative factor of learning rate decay.

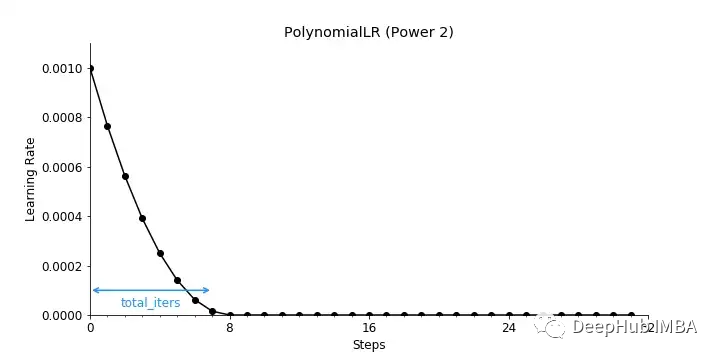
6、PolynomialLR
PolynomialLR通过对定义的步骤数使用多项式函数来降低学习率。
from torch.optim.lr_scheduler import PolynomialLR
scheduler = PolynomialLR(optimizer,
total_iters = 8, # The number of steps that the scheduler decays the learning rate.
power = 1) # The power of the polynomial.
下图为power= 1时的学习率衰减结果。

power= 2时,学习率衰减如下所示。
7、CosineAnnealingLR
CosineAnnealingLR通过余弦函数降低学习率。
可以从技术上安排学习率调整以跟随多个周期,但他的思想是在半个周期内衰减学习率以获得最大的迭代次数。
from torch.optim.lr_scheduler import CosineAnnealingLR
scheduler = CosineAnnealingLR(optimizer,
T_max = 32, # Maximum number of iterations.
eta_min = 1e-4) # Minimum learning rate.

两位Kaggle大赛大师Philipp Singer和Yauhen Babakhin建议使用余弦衰减作为深度迁移学习[2]的学习率调度器。
8、CosineAnnealingWarmRestartsLR
CosineAnnealingWarmRestartsLR类似于CosineAnnealingLR。但是它允许在(例如,每个轮次中)使用初始LR重新启动LR计划。
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
scheduler = CosineAnnealingWarmRestarts(optimizer,
T_0 = 8,# Number of iterations for the first restart
T_mult = 1, # A factor increases TiTi after a restart
eta_min = 1e-4) # Minimum learning rate

这个计划调度于2017年[1]推出。虽然增加LR会导致模型发散但是这种有意的分歧使模型能够逃避局部最小值,并找到更好的全局最小值。
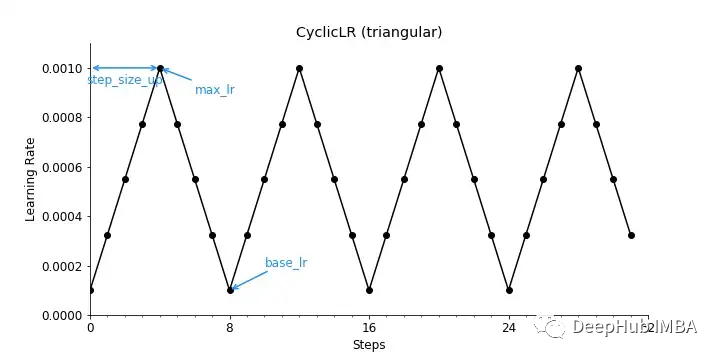
9、CyclicLR
CyclicLR根据循环学习率策略调整学习率,该策略基于我们在前一节中讨论过的重启的概念。在PyTorch中有三个内置策略。
from torch.optim.lr_scheduler import CyclicLR
scheduler = CyclicLR(optimizer,
base_lr = 0.0001, # Initial learning rate which is the lower boundary in the cycle for each parameter group
max_lr = 1e-3, # Upper learning rate boundaries in the cycle for each parameter group
step_size_up = 4, # Number of training iterations in the increasing half of a cycle
mode = "triangular")
当mode = " triangle "时,学习率衰减将遵循一个基本的三角形循环,没有振幅缩放,如下图所示。
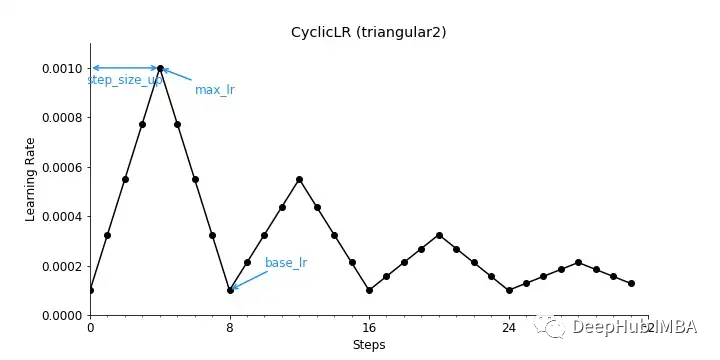
对于mode = " triangar2 ",所得到的学习率衰减将遵循一个基本的三角形循环,每个循环将初始振幅缩放一半,如下图所示。
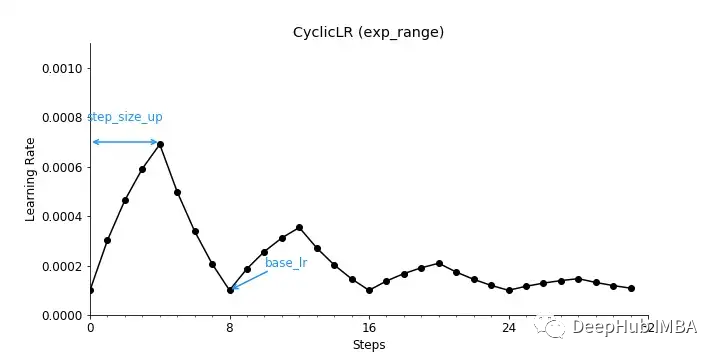
使用mode = “exp_range”,得到的学习率衰减将如下所示。
10、OneCycleLR
OneCycleLR根据1cycle学习率策略降低学习率,该策略在2017年[3]的一篇论文中提出。
与许多其他学习率调度器相比,学习率不仅在训练过程中下降。相反,学习率从初始学习率增加到某个最大学习率,然后再次下降。
from torch.optim.lr_scheduler import OneCycleLR
scheduler = OneCycleLR(optimizer,
max_lr = 1e-3, # Upper learning rate boundaries in the cycle for each parameter group
steps_per_epoch = 8, # The number of steps per epoch to train for.
epochs = 4, # The number of epochs to train for.
anneal_strategy = 'cos') # Specifies the annealing strategy
使用anneal_strategy = "cos"得到的学习率衰减将如下所示。

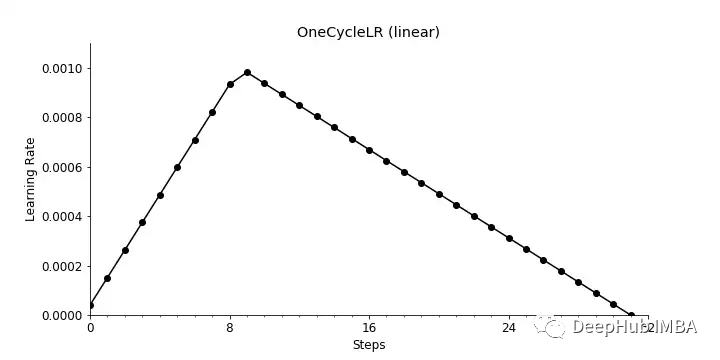
使用anneal_strategy = “linear”,得到的学习率衰减将如下所示。
11、ReduceLROnPlateauLR
当指标度量停止改进时,ReduceLROnPlateau会降低学习率。这很难可视化,因为学习率降低时间取决于您的模型、数据和超参数。
12、自定义学习率调度器
如果内置的学习率调度器不能满足需求,我们可以使用lambda函数定义一个调度器。lambda函数是一个返回基于epoch值的乘法因子的函数。
LambdaLR通过将lambda函数的乘法因子应用到初始LR来调整学习速率。
lr_epoch[t] = lr_initial * lambda(epoch)
MultiplicativeLR通过将lambda函数的乘法因子应用到前一个epoch的LR来调整学习速率。
lr_epoch[t] = lr_epoch[t-1] * lambda(epoch)
这些学习率调度器也有点难以可视化,因为它们高度依赖于已定义的lambda函数。
可视化汇总
以上就是PyTorch内置的学习率调度器,应该为深度学习项目选择哪种学习率调度器呢?
答案并不那么容易,ReduceLROnPlateau是一个流行的学习率调度器。而现在其他的方法如CosineAnnealingLR和OneCycleLR或像cosineannealingwarmrestart和CyclicLR这样的热重启方法已经越来越受欢迎。
所以我们需要运行一些实验来确定哪种学习率调度器最适合要解决问题。但是可以说的是使用任何学习调度器都会影响到模型性能。
下面是PyTorch中讨论过的学习率调度器的可视化总结。
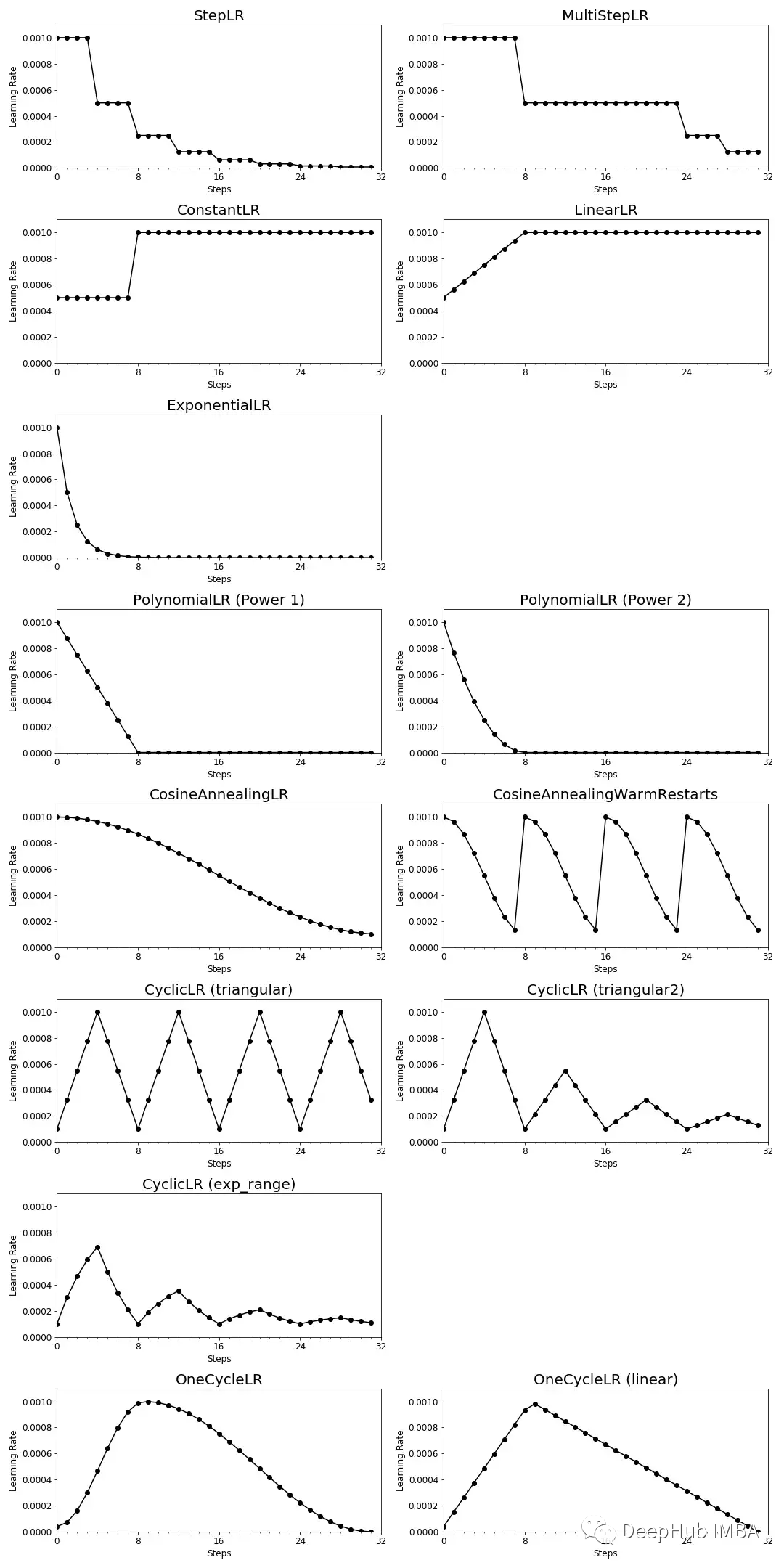
引用和附录
[1] Loshchilov, I., & Hutter, F. (2016). Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983.
[2] Singer, P. & Babakhin, Y. (2022) Practical Tips for Deep Transfer Learning. In: Kaggle Days Paris 2022.
[3] Smith, L. N., & Topin, N. (2019). Super-convergence: Very fast training of neural networks using large learning rates. In Artificial intelligence and machine learning for multi-domain operations applications (Vol. 11006, pp. 369–386). SPIE.
下面是来可视化学习率调度器的代码:
import torch
from torch.optim.lr_scheduler import StepLR # Import your choice of scheduler here
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
LEARNING_RATE = 1e-3
EPOCHS = 4
STEPS_IN_EPOCH = 8
# Set model and optimizer
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
# Define your scheduler here as described above
# ...
# Get learning rates as each training step
learning_rates = []
for i in range(EPOCHS*STEPS_IN_EPOCH):
optimizer.step()
learning_rates.append(optimizer.param_groups[0]["lr"])
scheduler.step()
# Visualize learinig rate scheduler
fig, ax = plt.subplots(1,1, figsize=(10,5))
ax.plot(range(EPOCHS*STEPS_IN_EPOCH),
learning_rates,
marker='o',
color='black')
ax.set_xlim([0, EPOCHS*STEPS_IN_EPOCH])
ax.set_ylim([0, LEARNING_RATE + 0.0001])
ax.set_xlabel('Steps')
ax.set_ylabel('Learning Rate')
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.xaxis.set_major_locator(MultipleLocator(STEPS_IN_EPOCH))
ax.xaxis.set_minor_locator(MultipleLocator(1))
plt.show()
https://avoid.overfit.cn/post/9987b70f3d1e47d5b6a0b5ff70d8133f
作者:Leonie Monigatti