💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee✨
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
- 前言
- 一、stack
- 二、queue
- 三、哪种容器适配stack和queue
- 四、容器适配器
- 4.1deque的介绍
- 4.2deque的优缺点
- 4.3为什么选择deque作为stack和queue的底层默认容器
- 五、总结
前言
我们前面几篇介绍了两个常见容器的具体使用和模拟实现,对底层应该是了解的七七八八了,今天学的栈和队列就相对来说比较简单,因为他是一个容器适配器,使用前面两个中的一种来模拟实现就好了,它的功能只是前面两个容器的特殊情况,而栈和队列的接口也相对来说比较的少,一会我会先通过库里面的接口来大家认识一下栈和队列有哪些接口,并且让大家更好的知道什么是容器适配器
一、stack

传什么容器,栈底层就使用什么容器进行实现,这个到模拟实现的再说。
创建对象:
stack<int> s;
stack<int,vector<int>> s1;
stack<int,list<int>> s2;
//这样的都可以,符合模板参数的就可以

我们库里面的栈就实现了这几个接口,因为根据栈的特性,我们只需要这几个功能函数就够了
构造函数

用什么容器进行构造,就要使用什么容器的适配器
vector<int> v(4, 10);
stack<int, vector<int>> s(v);
stack<int> s(v);//这样是错误的,因为默认适配的容器是deque的。
接下里看看各个功能
vector<int> v(4, 10);
stack<int, vector<int>> s(v);
s.push(1);
s.push(2);
s.push(3);
s.push(4);//入栈
cout << s.size() << endl;//计算栈里面多少个元素
while (!s.empty())//判断栈为不为空
{
cout << s.top() << " ";//取栈顶的元素
s.pop();//出栈
}
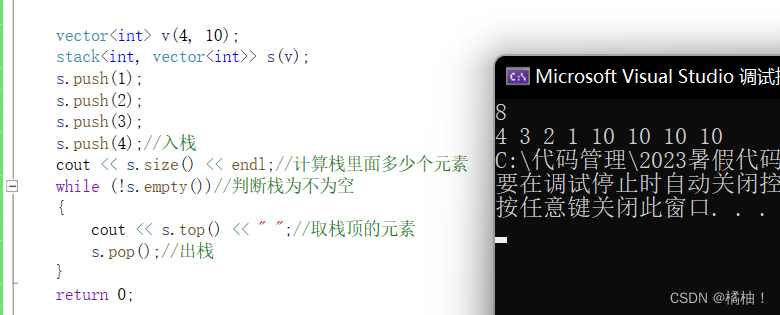
强调一点的是,我们的容器适配器要符合结构规则,再数据结构初阶,我们提到栈和队列都可以使用顺序表或者链表,但是分析之后,栈更合适用顺序表结构,队列更适合用链表结构,再库里面有的时候强制进行适配可能会出错,就好比队列,你要传vector容器就会报错,因为底层实现用的是list和deque共同的接口,而vector没有,才会导致出错,适配的本质就是传什么容器就用什么容器来模拟此容器,你也不能传一个树形结构的容器,这样肯定不行,所以大家这点要注意。
通过看源码来分析:

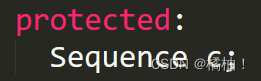

我们的c就是我们的容器,因为我们的deque,vector和list都有这些功能的接口,而且函数功能都是一样的,如果你传进来的容器没有此上面的函数接口就会报错。,接下来看queue就明白了
二、queue

创建对象:
queue<int> s;
queue<int,list<int>> s1;
queue<int,vector<int>> s2;//上面两个都可以,符合模板参数的就可以
//第三个就会出现问题,因为vector没有对应的接口
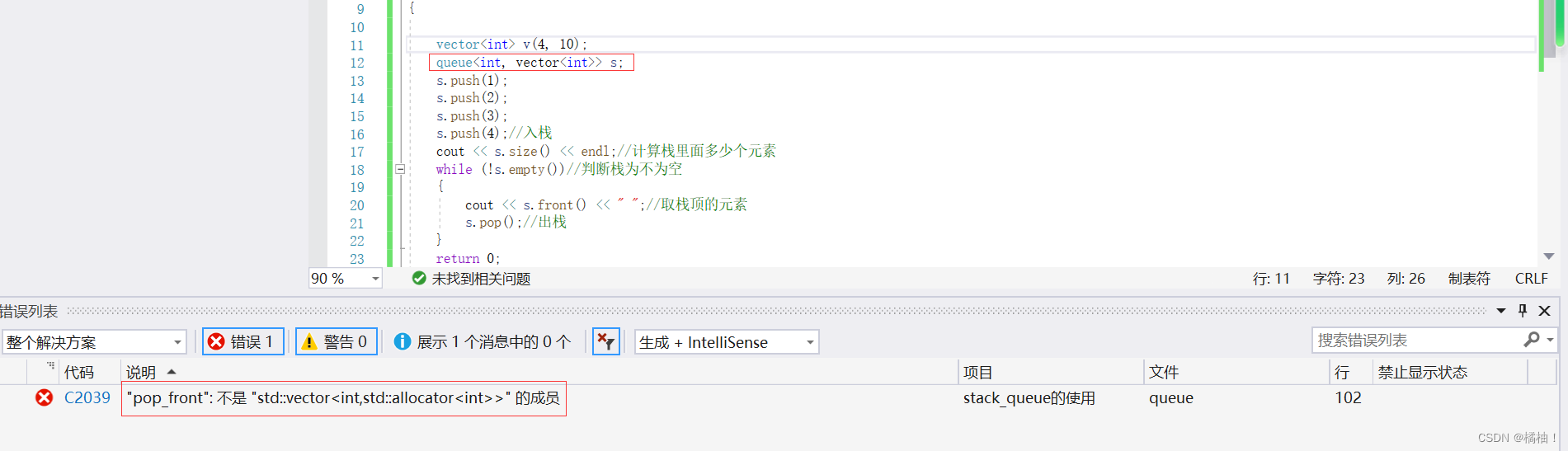
我们来看底层

我们看到这个pop_front再vector这个容器里面是没有这个接口的,但是再deque和list容器都有这个pop_frint接口的,所以不会报错,也明白我上面说的传的容器要适配此容器的功能特点
我们再来看看queue这个容器有哪些接口:

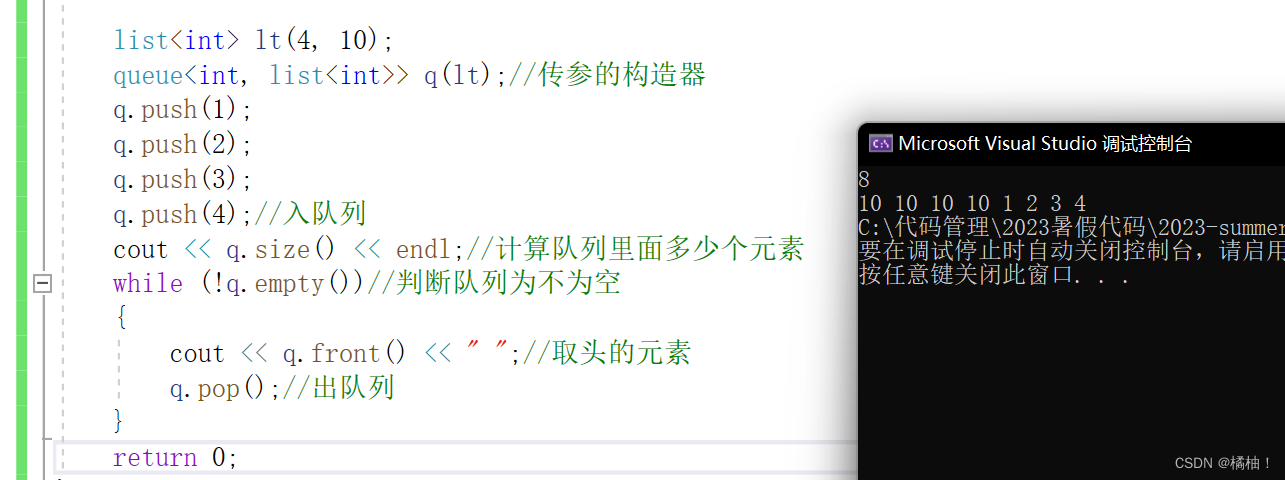
对于使用来说都是非常的简单,再数据结构初阶的时候就已经介绍过每个接口的含义了
三、哪种容器适配stack和queue
这就要通过stack和queue的特性做决定了。
栈:
我们的栈是先进后出的操作,都是再栈顶进行操作,就是在一个结构尾部进行操作,那我们的vector和list对于尾部的插入和删除的时间复杂度是一样的,使用vector会更好一些,因为vector是一段连续的内存空间,空间利用率高,空间碎片少。所以使用vector去适配栈结构会比较好一些
模拟实现:
#include<iostream>
#include<vector>
#include<list>
using namespace std;
namespace xdh
{
template<class T, class Container = vector<T>>
class stack
{
public:
stack() {}//可以不用写,因为成员变量是自定义类型,stack默认生成的构造函数会去调用自定义类型的构造函数,
//之前说到六大默认成员函数都是一样的道理
void push(const T& val)//入栈
{
_c.push_back(val);
}
void pop()//出栈
{
_c.pop_back();
}
T& top()//去栈顶元素
{
return _c.back();
}
const T& top() const
{
return _c.back();
}
size_t size() const//计算栈里面有多少个元素
{
return _c.size();
}
bool empty() const//判断栈是否为空
{
return _c.empty();
}
private:
Container _c;
};
}
xdh::stack<int> s;
xdh::stack<int,vector<int>> s;
xdh::stack<int, list<int>> s;
//这三种都是可以的
队列
我们的队列是先进先出的操作,我们的插入在队尾,删除在队头,对于这两个位置的插入和删除,vector在开头删除数据的代价非常大,虽然我们有时候需要取出队头队尾的数据,对于vector支持随机访问,所以这两个位置的数据非常好取出来,但是对于list这两个位置也非常好取出来,而list对于头部的删除操作效率非常高,相比较而言我们的队列使用list去适配会更好,而库里面直接是抹杀了vector这种适配,可以见到vector的头删的效率是多么低的,但是我们在模拟实现的时候可以改变接口函数,强制适配一下看看
模拟实现:
#include<iostream>
#include<vector>
#include<list>
using namespace std;
namespace xdh
{
template<class T,class Container=list<T>>
class queue
{
public:
queue(){}//可以不用写,因为成员变量是自定义类型,queue默认生成的构造函数会去调用自定义类型的构造函数,
//之前说到六大默认成员函数都是一样的道理
void push(const T& x)//入队列
{
_c.push_back(x);
}
void pop() //出队列
{
//代码1
_c.erase(_c.begin());//为了强制和vector进行适配
//代码2
//_c.pop_front();//库里面是这样的
}
T& back()//取队尾的数据
{
return _c.back();
}
const T& back()const
{
return _c.back();
}
T& front() //取队头的数据
{
return _c.front();
}
const T& front()const
{
return _c.front();
}
size_t size()const //计算队列的大小
{
return _c.size();
}
bool empty()const //判断队列是否为空
{
return _c.empty();
}
private:
Container _c;
};
}
我们将pop里面的代码换成代码1就可以强制适配vector容器了,但是库里面实现的代码2的风格,所以使用vector适配就会报错
四、容器适配器
前面提到好多次关于容器适配器,它具体是什么呢??
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:


我们发现从一开始我们的库里面实现的都不是像我们一开始默认使用的容器,他是使用deque的容器,当成栈和队列的默认容器,deque是什么,为什么选择它做默认适配器,我们来看看。
4.1deque的介绍
首先通过前面的的分析,想要成为stack和queue的适配容器,该有的优点不能少,不然就直接选择我刚才说到两种容易作为默认的不就行了,既然使用的deque,那么它肯定是有很多的优点,我们一起来看看:
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
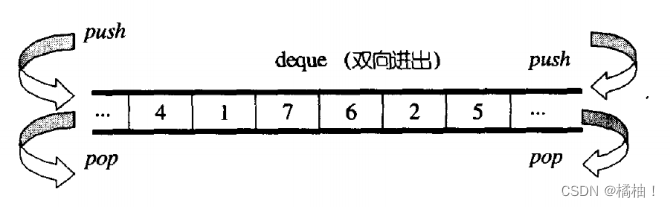


这么一看我们的deque好像是vector和list的结合体,支持头插头删,也支持随机访问,看上去是非常好的,但是当我们深入的去看的时候就发现也就那样,不然不就可以直接替代vector和list了嘛
我们来看deque的具体结构是啥样的:
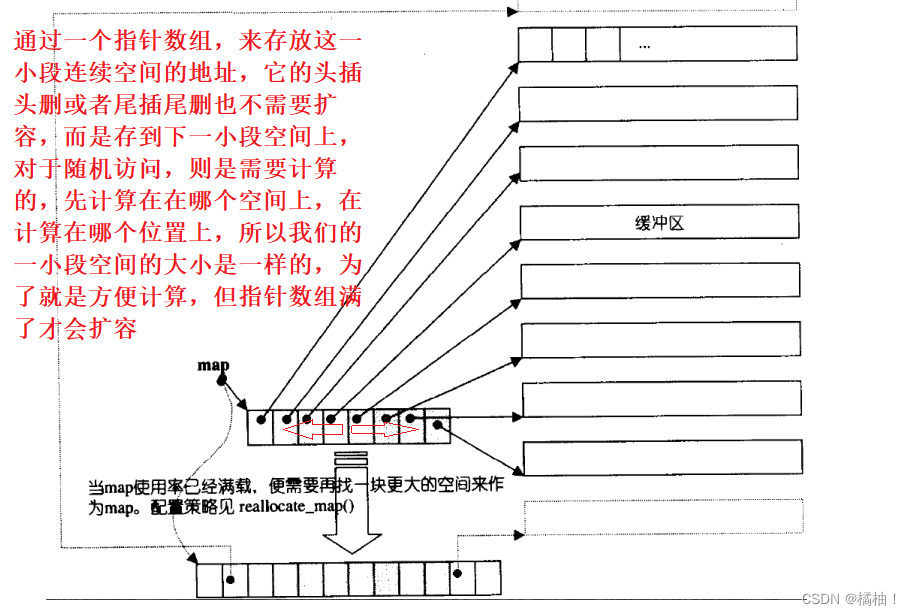
我们在来画图分析怎么存放数据的:
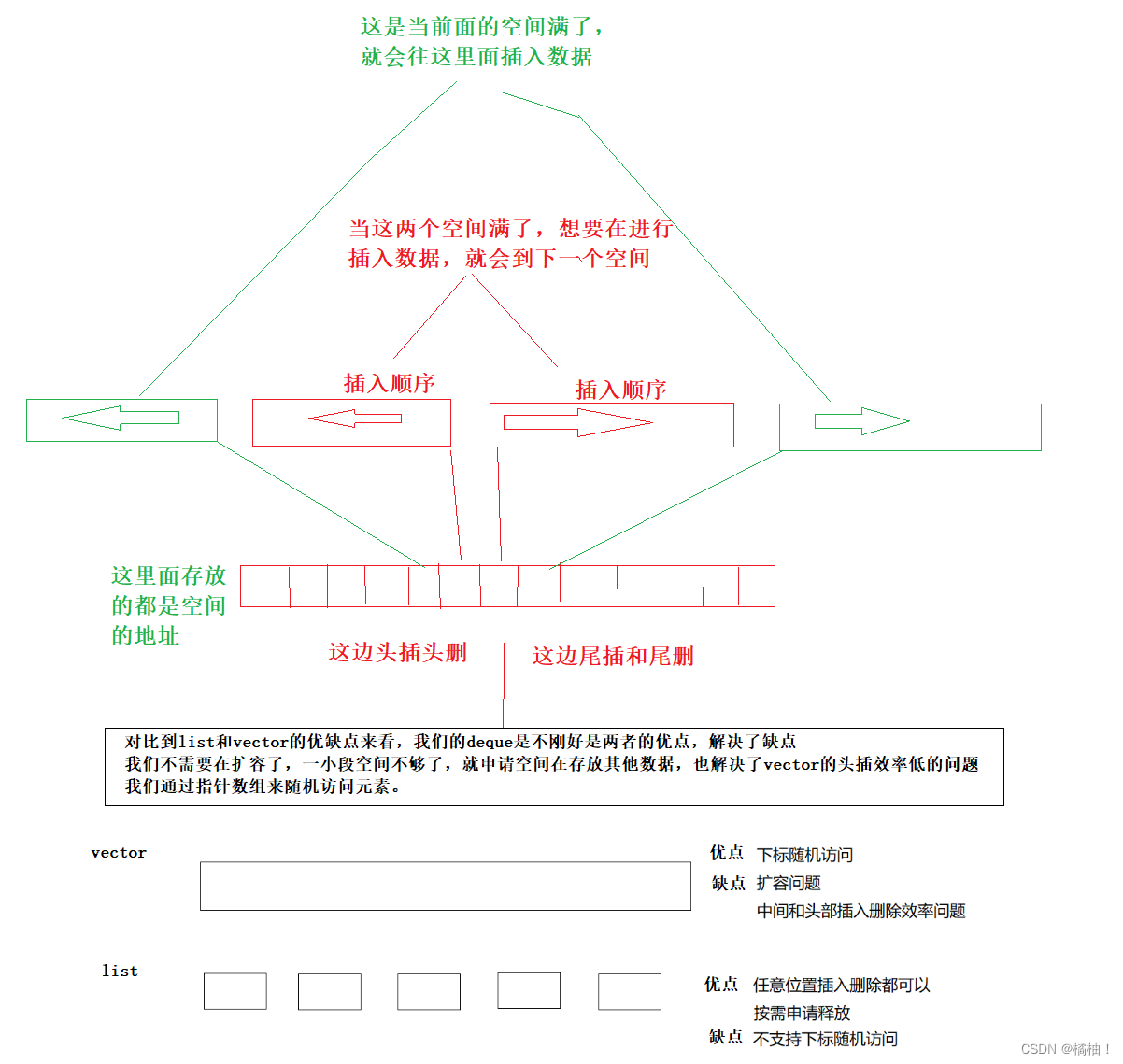
通过上面的图,我们发现虽然可以随机访问数据,但是要找到在哪个小的空间上,并且找到在哪个位置才能进行访问,而对于中间的插入是不友好的,是往满的空间进行扩容插入,还是想你开一个小的空间,那么指针数组的位置的值就要挪动,总之这样办法都是不好的。但是对于头插头删或者尾插尾删是优化的
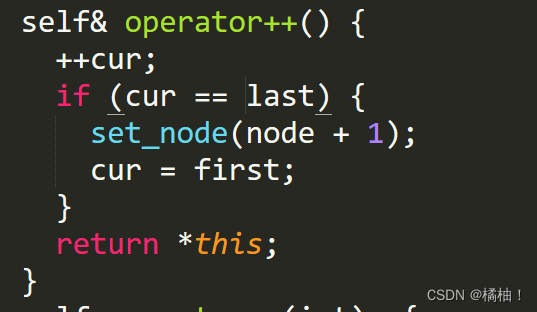
通过画图我们发现一小段的空间并不是连在一起的,按照STL的原则,遍历都可以使用迭代器,而且每个容器的用法都是一样的,那么那deque是如何借助其迭代器维护其假想连续的结构呢?
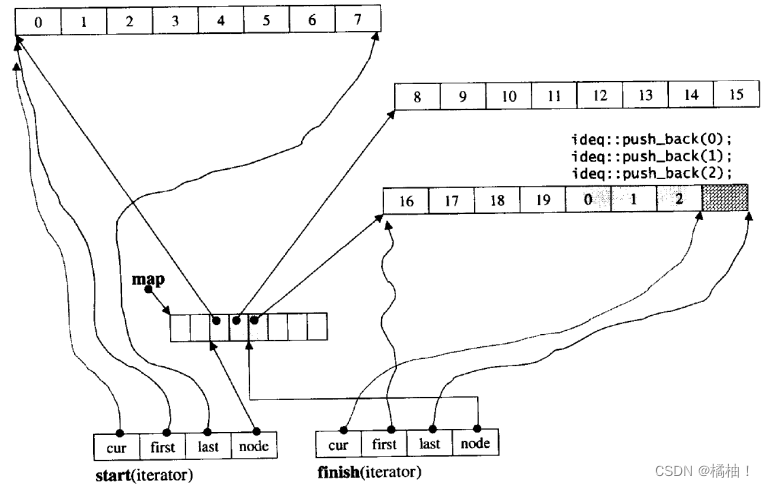
他的迭代器有四个指针,所以内部是非常的复杂,而且遍历的时候需要检查是否到达边界
通过源码我们需要检查小空间的边界条件,这样就导致效率低下
4.2deque的优缺点
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构==
4.3为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷
对于库里面的模拟是西安给的默认容器就是deque
五、总结
对于栈和队列的底层原理大家应该都清楚了吧,deque作为了解就可以,不需要深究,下一篇我将通过几个题目来让大家更好的使用栈和队列,我们下篇再见