文章目录
- 前言
- 处理数据
- 获取数据
- 筛选数据
- 将JSON数据转换为Python数据
- 筛选出横坐标数据和纵坐标数据
- 根据处理后的数据绘制折线图
- 整体代码展示
前言
前面我们学习了如何使用 pyecharts 模块绘制简单的折线图,那么今天我将为大家分享,如何根据提供的数据将数据进行处理并以折线图的形式展示出来。
处理数据
这是2020年美国、印度、日本三个国家的新冠确诊、治愈、死亡、新增确诊人数的数据。我会将这些数据上传到我的资源中,大家有需要可以去下载。

当我们看见这样的数据时会不会觉得顿时就不想看了,但是不急,其实只要我们细心,我们是能看出来里面的层次的。还有就是我们可以借助工具将数据的视图给展示出来以便我们更好的理解。
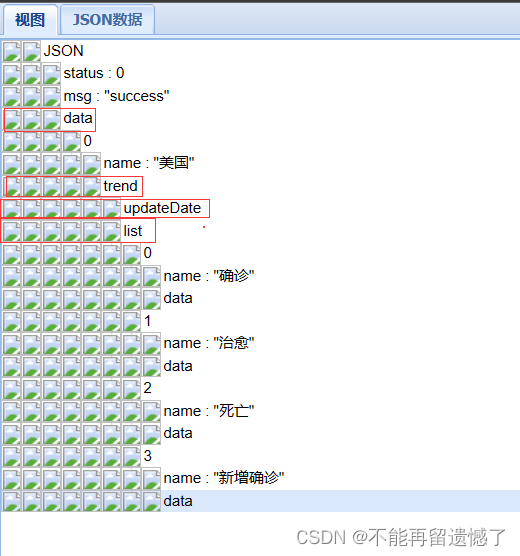
获取数据
我们首先需要使用文件操作拿到这三个文件中的数据。
# 打开我们的测试数据
f_us = open("D:/桌面/美国.txt", 'r', encoding='UTF8')
f_jp = open("D:/桌面/日本.txt", 'r', encoding='UTF8')
f_in = open("D:/桌面/印度.txt", 'r', encoding='UTF8')
# 读取数据
us_data = f_us.read()
jp_data = f_jp.read()
in_data = f_in.read()
因为我们的数据中有中文,所以我们需要明确读取的格式 UTF_8。
筛选数据
当我们拿到这些数据的时候,我们需要对数据进行处理。我们都知道 { } [ ] 数据代表的是 JSON 数据,但是文件中还有一些不属于 JSON 的数据,所以我们需要将他们给处理掉,并且我们只绘制2020年的数据,所以我们需要筛选掉没用的数据。


# 处理数据
us_data = us_data.replace('jsonp_1629344292311_69436(','') # 用空字符串来替换这些多余的数据
jp_data = jp_data.replace('jsonp_1629350871167_29498(','')
in_data = in_data.replace('jsonp_1629350745930_63180(','')
us_data = us_data[:-2] # 截取掉后面的 );
jp_data = jp_data[:-2]
in_data = in_data[:-2]
将JSON数据转换为Python数据
当我们过滤掉这些多余数据之后,我们需要将这些 JSON 数据转换为 python 数据。
# 将json数据转换为python数据
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
别忘了,我们使用 json.loads() 函数的时候,需要导入 json 模块。
筛选出横坐标数据和纵坐标数据
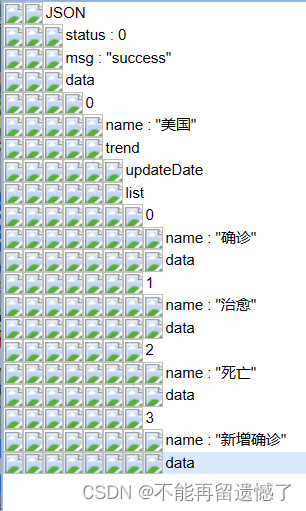
先获取到 trend 里面的数据。

us_trend = us_dict['data'][0]['trend']
jp_trend = jp_dict['data'][0]['trend']
in_trend = in_dict['data'][0]['trend']
获取横坐标日期updateDate数据

x_data = us_trend['updateDate'][:314] # 前314个数据表示2020年数据
获取纵坐标data数据

us_y_data = us_trend['list'][0]['data'][:314]
jp_y_data = jp_trend['list'][0]['data'][:314]
in_y_data = in_trend['list'][0]['data'][:314]
根据处理后的数据绘制折线图
先创建一个空白的折线图
from pyecharts.charts import Line
# 创建折线图
line = Line()
为空白折线图添加横纵坐标数据。
# 添加横纵坐标数据
line.add_xaxis(x_data)
line.add_yaxis('美国确诊人数',us_y_data)
line.add_yaxis('日本确诊人数',jp_y_data)
line.add_yaxis('印度确诊人数',in_y_data)
添加全局配置选项
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts
# 设置全局配置项
line.set_global_opts(title_opts=TitleOpts(title='2020年美国确诊人数',pos_left='center',pos_bottom='1%'),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
运行程序会生成一个 render,html 文件,我们运行它。
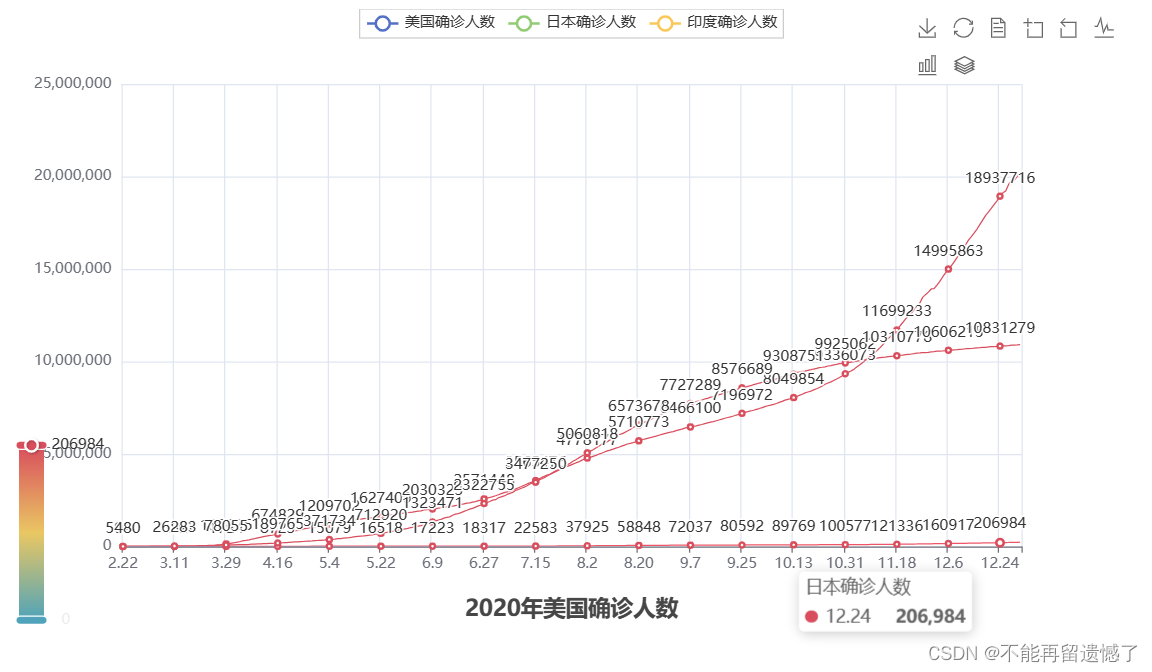
这里因为数据太多,看的图形很杂,我们可以设置系列配置选项来取消折线数据的显示。
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts,LabelOpts
# 添加横纵坐标数据
line.add_xaxis(x_data)
line.add_yaxis('美国确诊人数',us_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis('日本确诊人数',jp_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis('印度确诊人数',in_y_data,label_opts=LabelOpts(is_show=False))
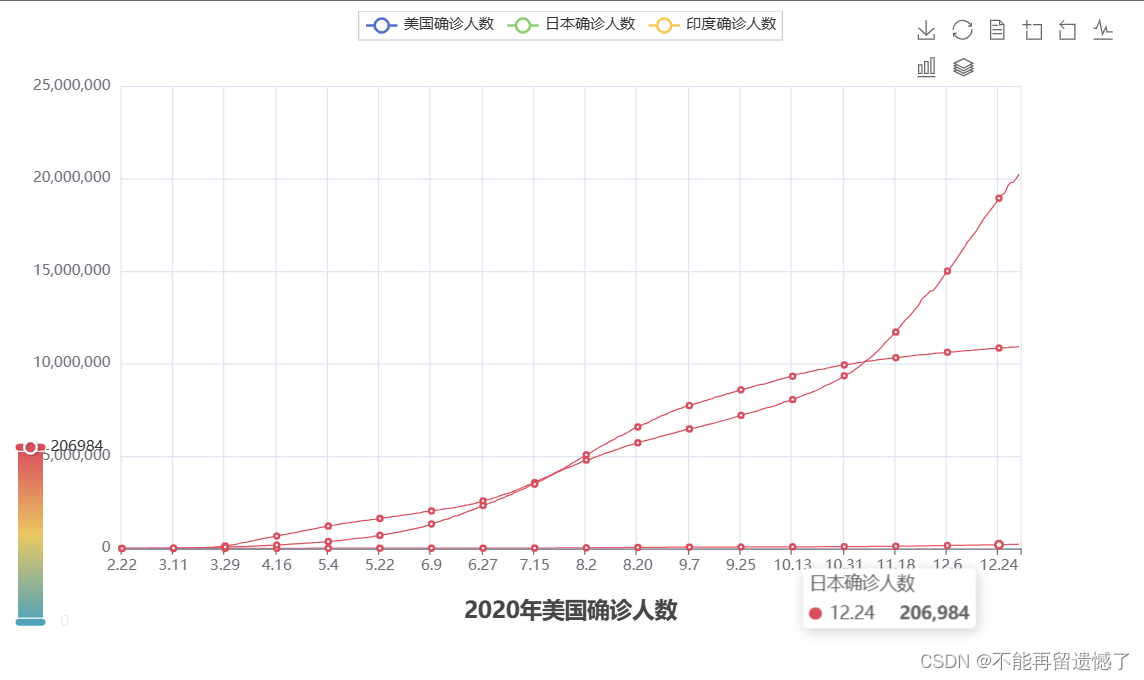
整体代码展示
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts,LabelOpts
# 打开我们的测试数据
f_us = open("D:/桌面/美国.txt", 'r', encoding='UTF8')
f_jp = open("D:/桌面/日本.txt", 'r', encoding='UTF8')
f_in = open("D:/桌面/印度.txt", 'r', encoding='UTF8')
# 读取数据
us_data = f_us.read()
jp_data = f_jp.read()
in_data = f_in.read()
# 处理数据
us_data = us_data.replace('jsonp_1629344292311_69436(','')
jp_data = jp_data.replace('jsonp_1629350871167_29498(','')
in_data = in_data.replace('jsonp_1629350745930_63180(','')
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# 将json数据转换为python数据
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取对应的横坐标与纵坐标数据
us_trend = us_dict['data'][0]['trend']
jp_trend = jp_dict['data'][0]['trend']
in_trend = in_dict['data'][0]['trend']
x_data = us_trend['updateDate'][:314]
us_y_data = us_trend['list'][0]['data'][:314]
jp_y_data = jp_trend['list'][0]['data'][:314]
in_y_data = in_trend['list'][0]['data'][:314]
# 创建折线图
line = Line()
# 添加横纵坐标数据
line.add_xaxis(x_data)
line.add_yaxis('美国确诊人数',us_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis('日本确诊人数',jp_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis('印度确诊人数',in_y_data,label_opts=LabelOpts(is_show=False))
# 设置全局配置项
line.set_global_opts(title_opts=TitleOpts(title='2020年美国确诊人数',pos_left='center',pos_bottom='1%'),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
line.render()