经济时间序列的分析通常需要提取其周期性成分。最近我们被客户要求撰写关于经济时间序列的研究报告,包括一些图形和统计输出。这篇文章介绍了一些方法,可用于将时间序列分解为它们的不同部分。它基于《宏观经济学手册》中Stock和Watson(1999)关于商业周期的章节,但也介绍了一些较新的方法,例如汉密尔顿(2018)替代HP滤波器,小波滤波和经验模态分解。
数据
我使用从1970Q1到2016Q4的美国对数实际GDP的季度数据来说明不同的方法。时间序列是通过 Quandl 及其相应的R包获得的。
#加载用于数据下载和转换的软件包
library(dplyr)
library(Quandl)
library(tidyr)
#下载数据
data <- Quandl("FRED/GDPC1", order = "asc",
start_date = "1970-01-01", end_date = "2016-10-01") %>%
rename(date = Date,
gdp = Value) %>%
mutate(lgdp = log(gdp)) # 获取对数library(ggplot2)
ggplot(data, aes(x = date, y = lgdp)) +
geom_line() +
theme_classic() 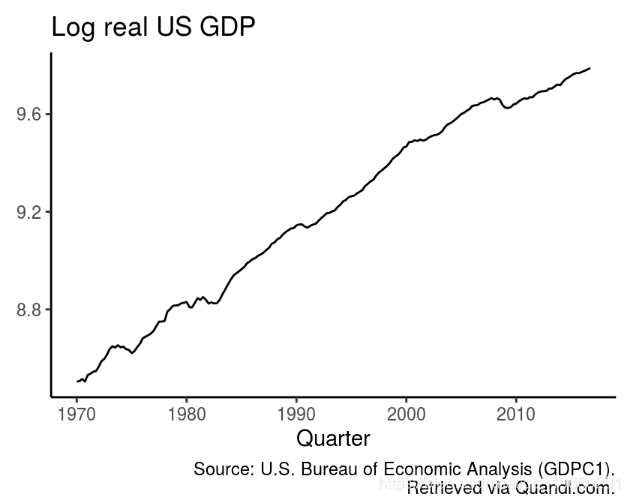
数据有明显的增长趋势,到现在似乎逐渐变小。此外,似乎或多或少有规律地围绕这一趋势波动。与趋势之间存在相对较长的持久偏差,可以将其视为周期性波动。
与线性趋势的偏差
从系列中提取趋势的第一种方法是在常数和趋势项上回归目标变量并获得拟合值。在下图中绘制。
# 添加趋势
data <- data %>%
mutate(trend = 1:n())
# 用常数和趋势估算模型
time_detrend <- fitted(lm(lgdp ~ trend, data = data))
names(time_detrend) <- NULL
# 将系列添加到主数据框
data <- data %>%
mutate(lin_trend = time_detrend)
# 为图创建数据框
temp <- data %>%
select(date, lgdp, lin_trend) %>%
gather(key = "Variable", value = "value", -date)
# 画图
ggplot(temp, aes(x = date, y = value, colour = Variable)) +
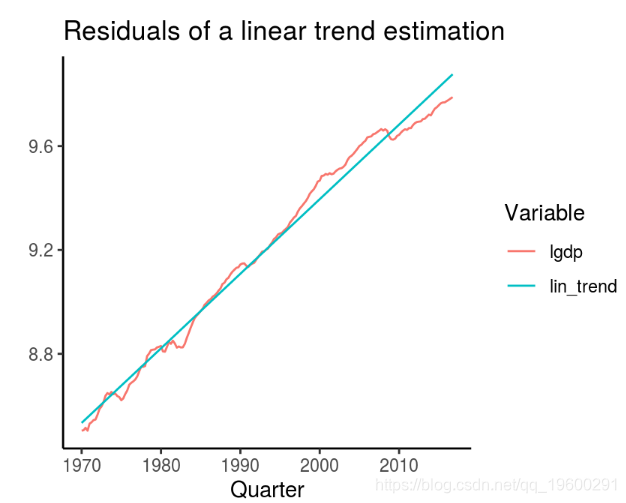
此方法相对有争议,因为它假定存在恒定的线性时间趋势。正如我们在上面看到的,鉴于趋势的增长率随着时间的推移持续下降,这不太可能。但是,仍然可以采用时间趋势的其他函数形式(例如二次项)来说明趋势的特殊性。该方法的另一个缺点是,它仅排除趋势,而不排除噪声,即序列中很小的波动。
Hodrick-Prescott过滤器
Hodrick和Prescott(1981)开发了一个过滤器,将时间序列分为趋势和周期性分量。与线性趋势相反,所谓的 HP过滤器可 估算趋势,该趋势会随时间变化。研究人员手动确定允许这种趋势改变的程度,即平滑参数λλ。
文献表明季度数据的值为1600。但是,也可以选择更高的值。下图绘制了由HP过滤器获得的实际GDP周期性成分的值,并将其与线性趋势下的序列的值进行比较。
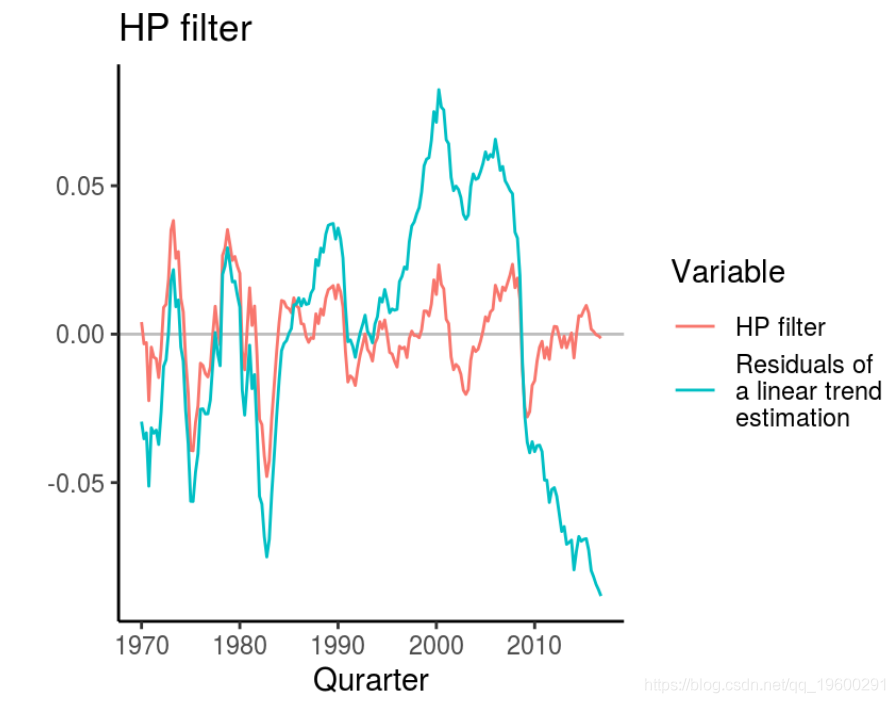
尽管HP过滤器在经济学中得到了广泛的应用,但它们的某些功能也受到了广泛的批评。
基于回归的HP过滤器
汉密尔顿(2018)还提出了另一种HP过滤器的方法。它可以归结为一个简单的回归模型,其中 时间序列的第 h 个前导根据时间序列的最新p值进行回归。
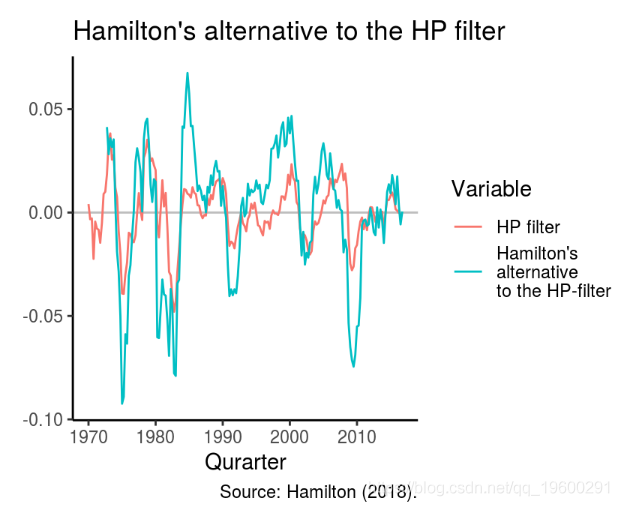
Baxter King过滤器
Baxter和King(1994,1999)提出了一种过滤器,其产生的结果与HP过滤器非常相似。另外,它从时间序列中去除了噪声,因此可以对周期分量进行平滑估计。该方法的一个相对严重的缺点是,平滑因子导致序列开始和结束时观测值的损失。当样本量较小且当前经济状况令人关注时,这可能是一个问题。
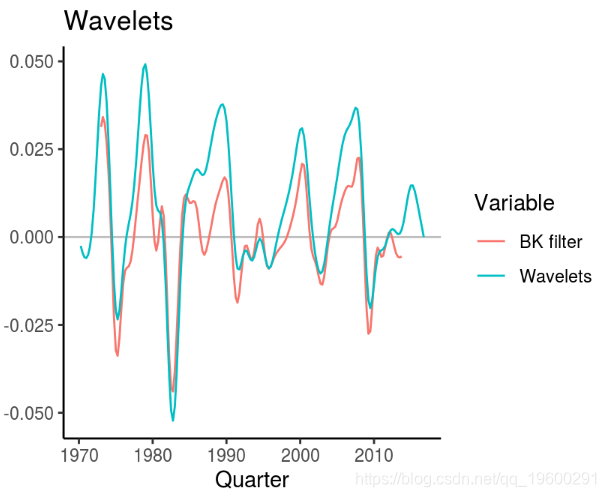
小波滤波器
Yogo(2008)提出使用小波滤波器从时间序列数据中提取业务周期。该方法的优点是该函数不仅允许提取序列的趋势,周期和噪声,而且还可以更明确地了解周期发生的时间段。
R中的方法实现也很简洁,但是在使用之前需要进行一些其他的数据转换。
# 计算对数GDP的一阶差分
data <- data %>%
mutate(dlgdp = lgdp - lag(lgdp, 1))
#获取数据
y <- na.omit(data$dlgdp)
#运行过滤器
wave_gdp <- mra(y, J = 5)
# 创建用于绘制的数据框
temp <- wave_gdp %>%
gather(key = "imf",
# 绘制mra输出
ggplot(temp, aes(x = date, y = value)) +
geom_line() +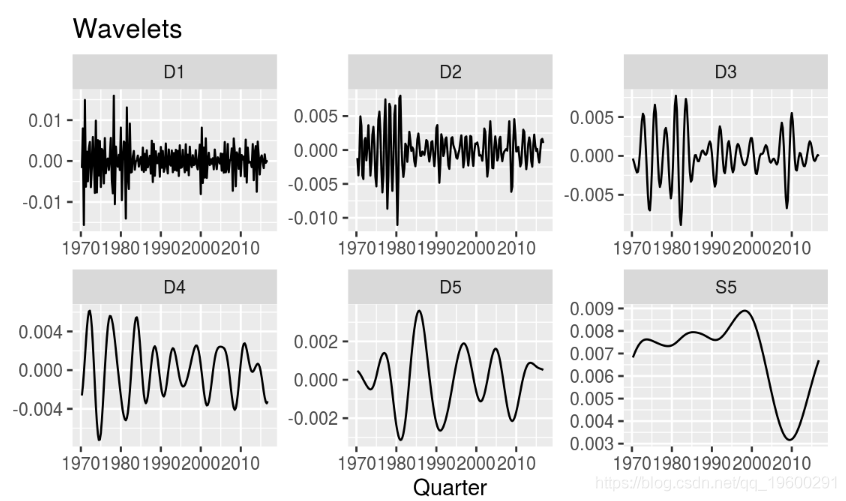
data <- data %>%
select(date, bk, wave) %>%
gather(key = "Variabl
ggplot(temp, aes(x = date, y = value, colour = Variable)) +
geom_hlin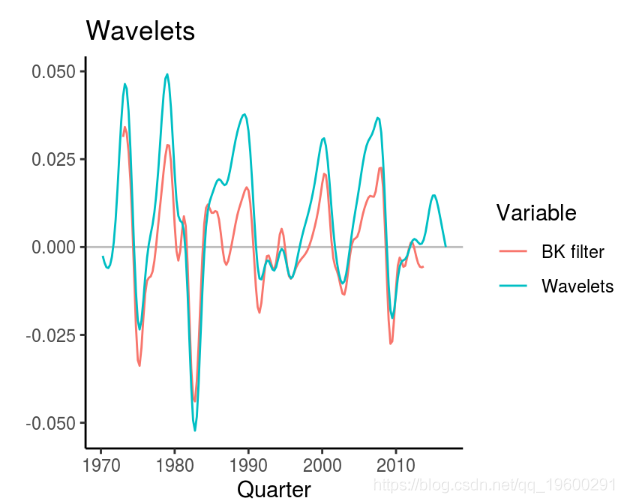
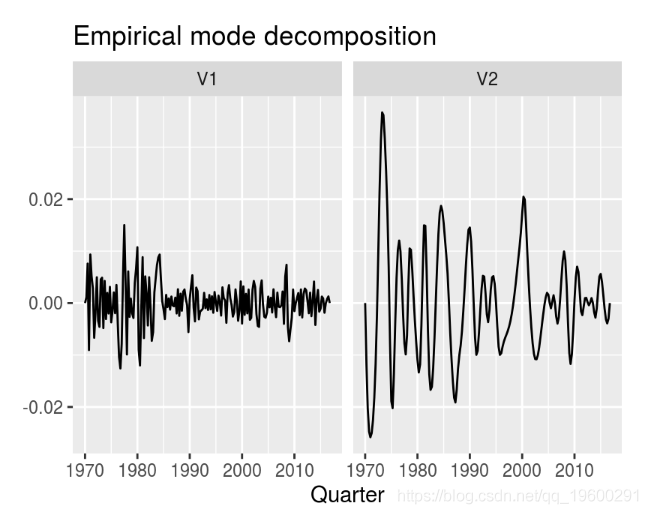
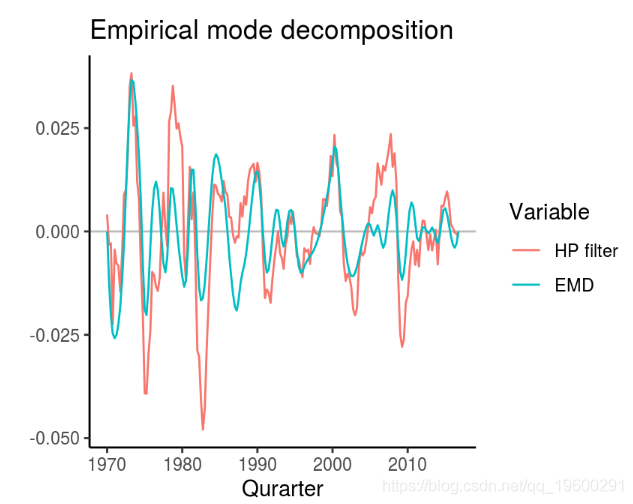
经验模态分解(EMD)
Kozic和Sever(2014)提出了经验模态分解作为商业周期提取的另一种方法,正如Huang等人(2014年)提出的那样。(1998)。 emd 函数可以在EMD 包中找到, 并且需要一个不同的时间序列,一个边界条件和一个指定的规则,在该点上迭代算法可以停止。滤波方法的结果与HP,BK和小波滤波相对不同。
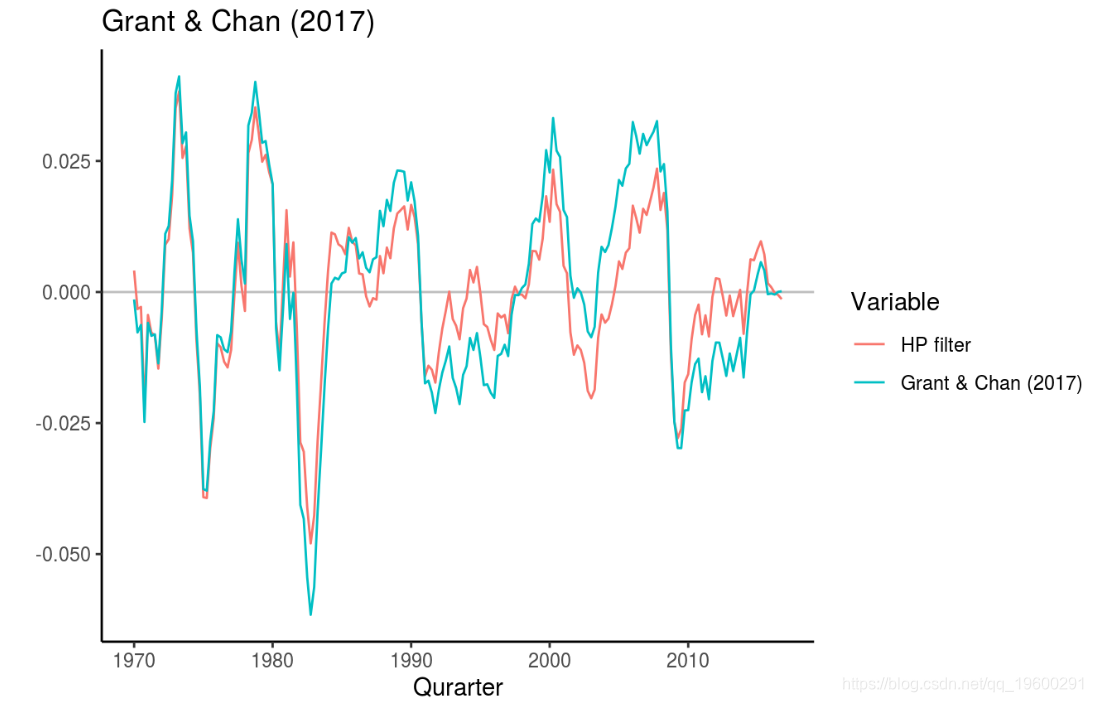
Chan(2017)
初始值
# X_gamma
x_gamma <- cbind(2:(tt +
# H_2
h2 <- diag(1, tt)
diag(h2[-1,
t)]) <- 1
h2h2 <- crossprod(h2)
# H_phi
h_phi <- diag(1, tt)
phi <- matrix(
# sigma tau的逆
s_tau_i <- 1 / .001
# sigma c的逆
s_c_i <- 1 / .5
# gamma
gamma <- t(rep(y[1], 2)) # 应该接近该序列的第一个值Gibbs 采样





![[carla] carla-ros-bridge 修改信号灯行为。](https://img-blog.csdnimg.cn/14511e36ff9f4223aaba60fdf116829e.png)