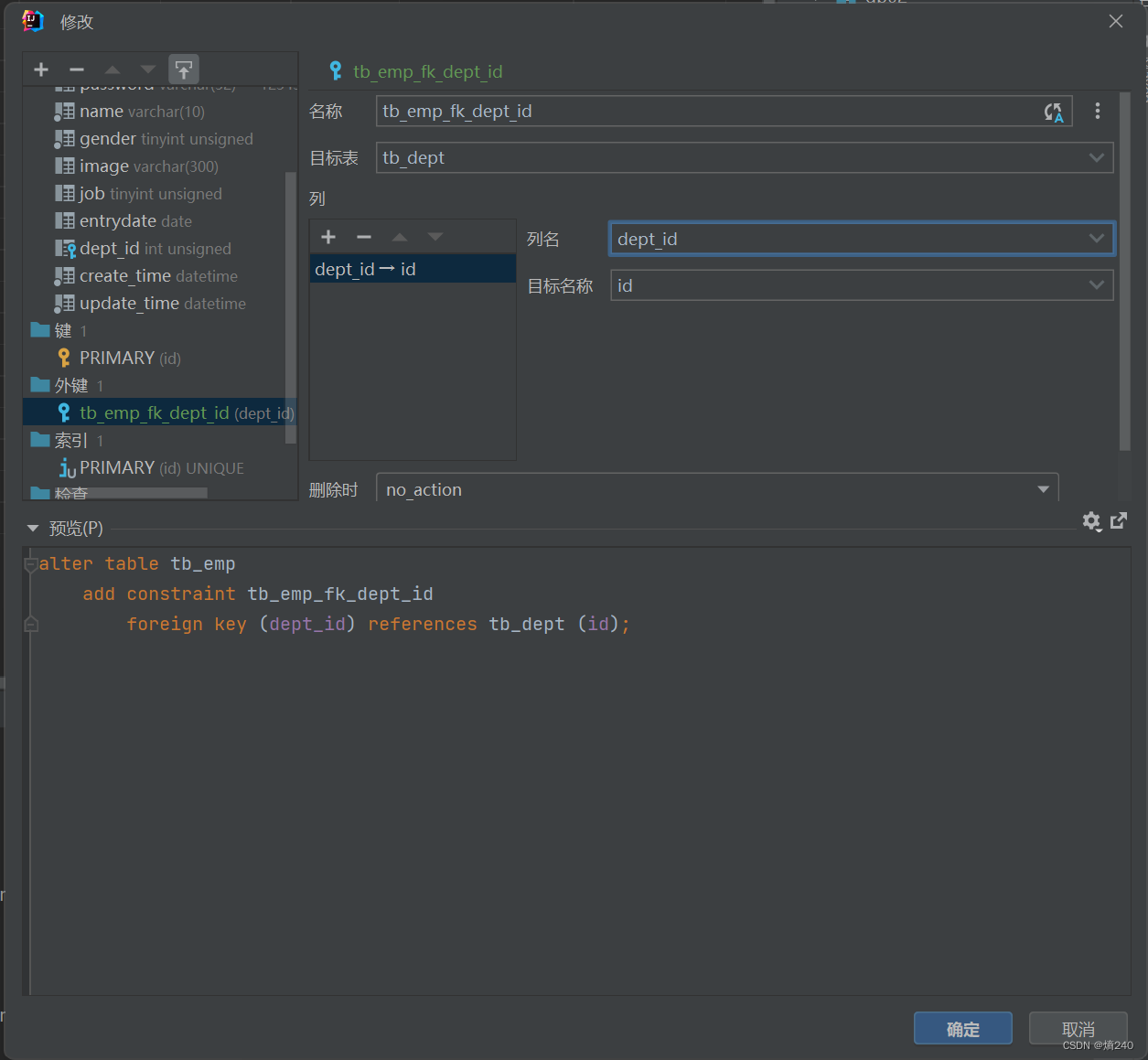
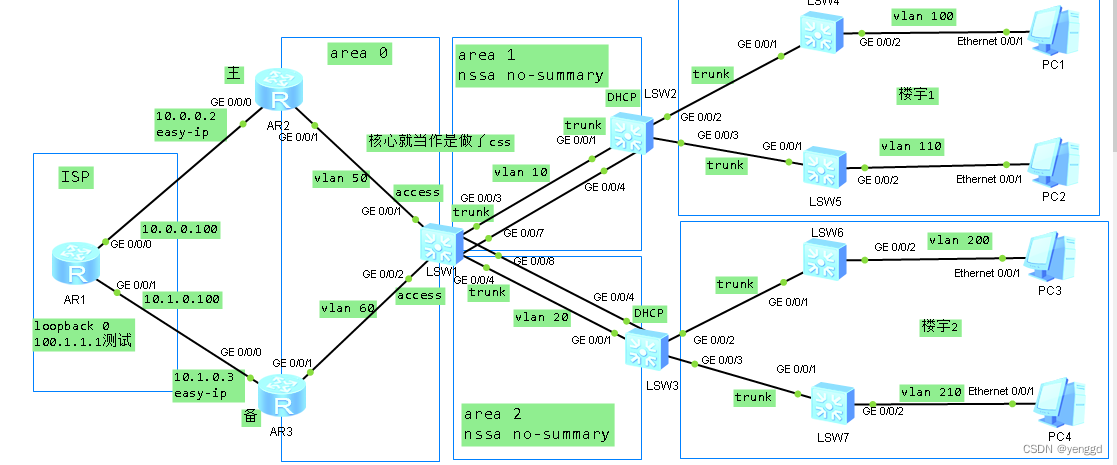
ArrayList的注意事项
1、在ArrayList中可以放任意元素,包括空值,任何元素,且可重复添加。
2、ArrayList底层是由数组来实现数据存储的
3、ArrayList基本等同于Vector,除了ArrayList是线程不安全(执行效率高),看源码
在多线程的情况下,不建议使用ArrayList。
ArrayList底层操作机制源码分析
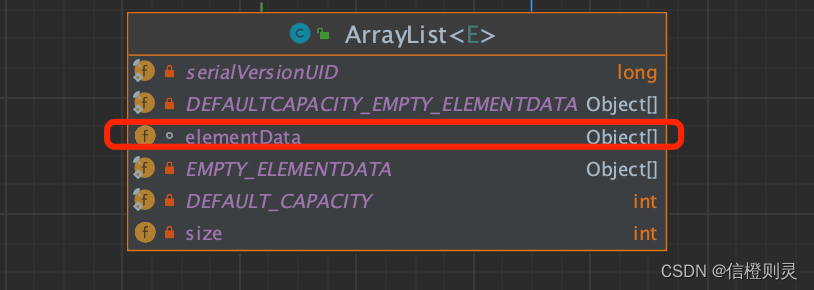
1、ArrayList 中维护了 一个Object类型的数组 elementData.
transient Object[] elementData;
transient: 表示瞬间、短暂的,表示该属性不会被序列化。
2、当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData的容量为0, 第一次添加,则扩容elementData为10,如果需要再次扩容的话,则扩容elementData为1.5倍
3、如果使用的是指定容量capacity的构造器,则初始的elementData容量为capacity,如果需要扩容,则扩容至当前elementData的1.5倍。
4、当添加元素时,先判断是否需要扩容,如果需要扩容,则调用grow方法。
重要、重要、重要!!!
上面的总结是基于之前的代码,现在新版本的源码已经改变,扩容机制也已经更改,可以看下面的👇🏻的源码分析。
源码解析
- 无参构造器创建
ArrayList list = new ArrayList();


示例代码,可将代码复制至idea进行调试总结
package com.zhang.test_package.list_;
import java.util.ArrayList;
public class ArrayListSource {
public static void main(String[] args) {
// 使用无参构造器,默认容量为0
ArrayList list = new ArrayList();
// ArrayList list1 = new ArrayList(8);
for (int i = 1; i <= 10; i++) {
list.add(i);
}
list.addAll(1, list);
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(123);
list.add(300);
list.add(null);
for (Object o :
list) {
System.out.println(o);
}
}
}
流程图:
小画桌-免费在线协作白板
Vector注意事项
1、Vector 中维护了一个Object类型的数组 elementData.
private Object[] elementData;
2、Vector是线程同步的,即支持线程安全,Vector类的操作方法中带有 synchronized
synchronized: 支持线程同步和互斥。
3、在开发中,如果需要线程同步安全时,优先使用Vector。
单线程的时候优先考虑使用ArrayList 方法(效率高)
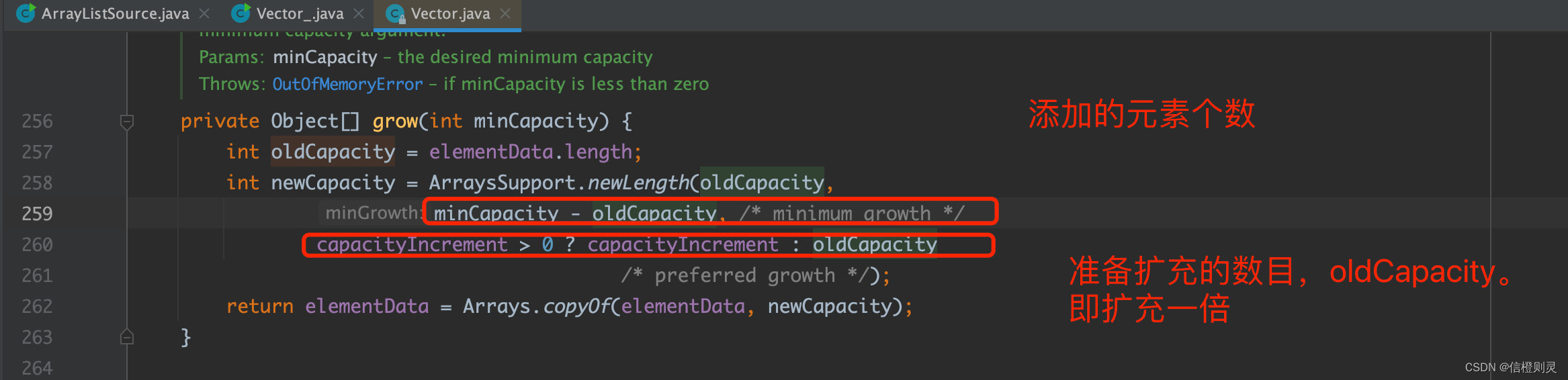
Vertor扩容机制

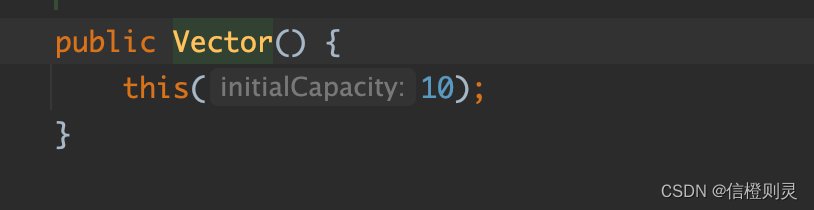
1、无参构造器,默认的 initialCapacity 为10

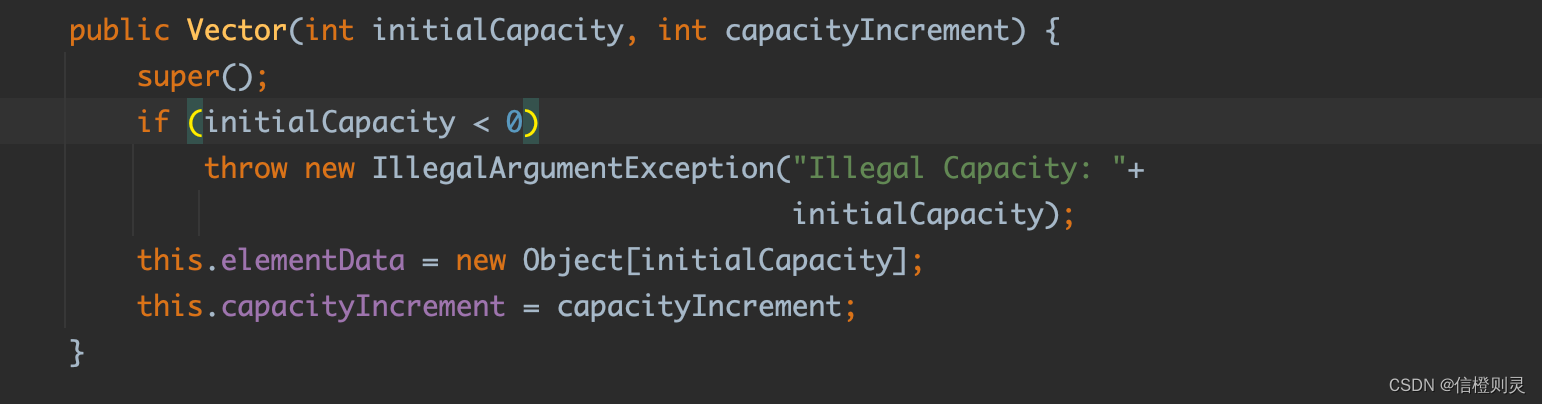
2、之后扩容按照2倍扩容
LinkedList的底层结构
1、LinkedList 底层实现了 双向链表 和 双端队列 特点
2、可以添加任意元素(元素可以重复),包括null
3、线程不安全,没有实现同步。
LinkedList底层操作机制
1、LinkedList底层维护了一个双向链表
2、LinkedList中维护了两个属性,first和last,分别指向 首节点和尾节点
3、每个节点(Node对象),里面又维护了 prev、next、item三个属性,其中通过prev指向前一个,通过next指向后一个节点,最终实现双向链表。
4、LinkedList 中的元素添加和删除,不是通过数组完成的,相对来说效率较高一些
package com.zhang.test_package.list_;
public class LinkedList01 {
public static void main(String[] args) {
Node c = new Node("C++");
Node java = new Node("java");
Node python = new Node("Python");
// 连接三个节点,形成双向链表
// c -> java -> python
c.next = java; // 头节点
java.next = python; // 尾结点
// python -> java -> c
python.pre = java;
java.pre = c;
Node first = c; // 让first引用指向jack,就是双向链表的头结点
Node last = python; //让last引用指向hsp,就是双向链表的尾结点
System.out.println("正向遍历");
while (first != null) {
System.out.println(first);
first = first.next;
}
System.out.println("反向遍历");
while (last != null) {
System.out.println(last);
last = last.pre;
}
System.out.println("添加元素");
}
}
class Node{
private Object item; // 保存节点处的数据
public Node next; // 下一个节点
public Node pre; // 上一个节点
public Node(Object item) {
this.item = item;
}
@Override
public String toString() {
// 此处的toString方法不能加next和pre,不然的话,next和pre也都是Node,会调用toString方法
// 最终StackOverFlowException
return "Node{" +
"item=" + item +
// ", next=" + next +
// ", pre=" + pre +
'}';
}
}
数据结构的知识做基础。建议多学习数据基础相关的知识。
LinkedList分析流程图:
小画桌-免费在线协作白板
LinkedList的增删改查
package com.zhang.test_package.list_;
import java.util.Iterator;
import java.util.LinkedList;
public class LinkedListCRUD {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
for (int i = 0; i < 1000; i++) {
linkedList.add(i);
}
// linkedList.add(1);
// linkedList.add(2);
// linkedList.add(3);
// linkedList.add(4);
// linkedList.add(5);
System.out.println(linkedList);
linkedList.remove(30);
linkedList.set(2, 10);
linkedList.get(2);
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
ArrayList和LinkedList比较
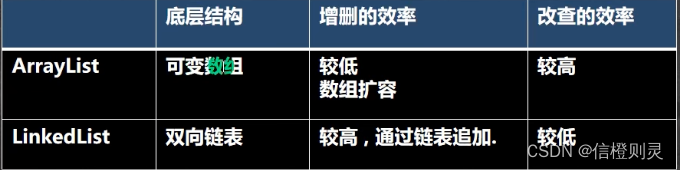
1、如果改查的操作多,选择ArrayList
2、如果增删的操作多,选择LinkedList
3、一般来说,在程序中,80%-90%的都是查询,因此大部分情况下选择ArrayList
4、在一个项目中,根据业务灵活选择,可以一个模块使用的是ArrayList,另一个模块是LinkedList.