图解java.util.concurrent并发包源码系列,原子类、CAS、AtomicLong、AtomicStampedReference一套带走
- 原子类
- 为什么要使用原子类
- CAS
- AtomicLong源码解析
- AtomicLong的问题
- ABA问题
- AtomicStampedReference
- 高并发情况下大量的CAS失败,导致CPU空转
往期文章:
- 人人都能看懂的图解java.util.concurrent并发包源码系列 ThreadPoolExecutor线程池
原子类
java.util.concurrent.atomic包中有各种各样的原子类,比如AtomicInteger、AtomicLong、AtomicLongArray、AtomicReference、AtomicStampedReference、LongAdder等,它们提供了对不同类型的变量的原子操作。
为什么要使用原子类
如果我们对一个方法内部的局部变量做操作,比如自增自减,那是不需要使用原子类的,因为此时操作该变量的只有一个线程,是线程安全的,对该变量的操作得到的结果必然与我们预期的结果一致。
public class Test {
public static void numAdd100() {
int num = 0;
for (int i = 0; i < 100; i++) {
num++;
}
// 打印的必然是100
System.out.println(num);
}
public static void main(String[] args) {
numAdd100();
}
}
但是我们对一个成员变量做自增自减操作呢?如果还是只有一个线程,那得到的结果还是与我们预期的结果是一致的,但是如果有多个线程同时操作这个变量,那么得到的结果就不一定和我们预期的结果一致了。
public class Test {
private static int num;
public static void addNum100() {
for (int i = 0; i < 100; i++) {
num++;
}
}
public static int getNum() {
return num;
}
public static void main(String[] args) throws InterruptedException {
// 100个线程,每个线程都对num变量加100
for (int i = 0; i < 100; i++) {
new Thread(() -> Test.addNum100()).start();
}
Thread.sleep(1000);
// 得到的结果就不一定的10000了
System.out.println(Test.getNum());
}
}
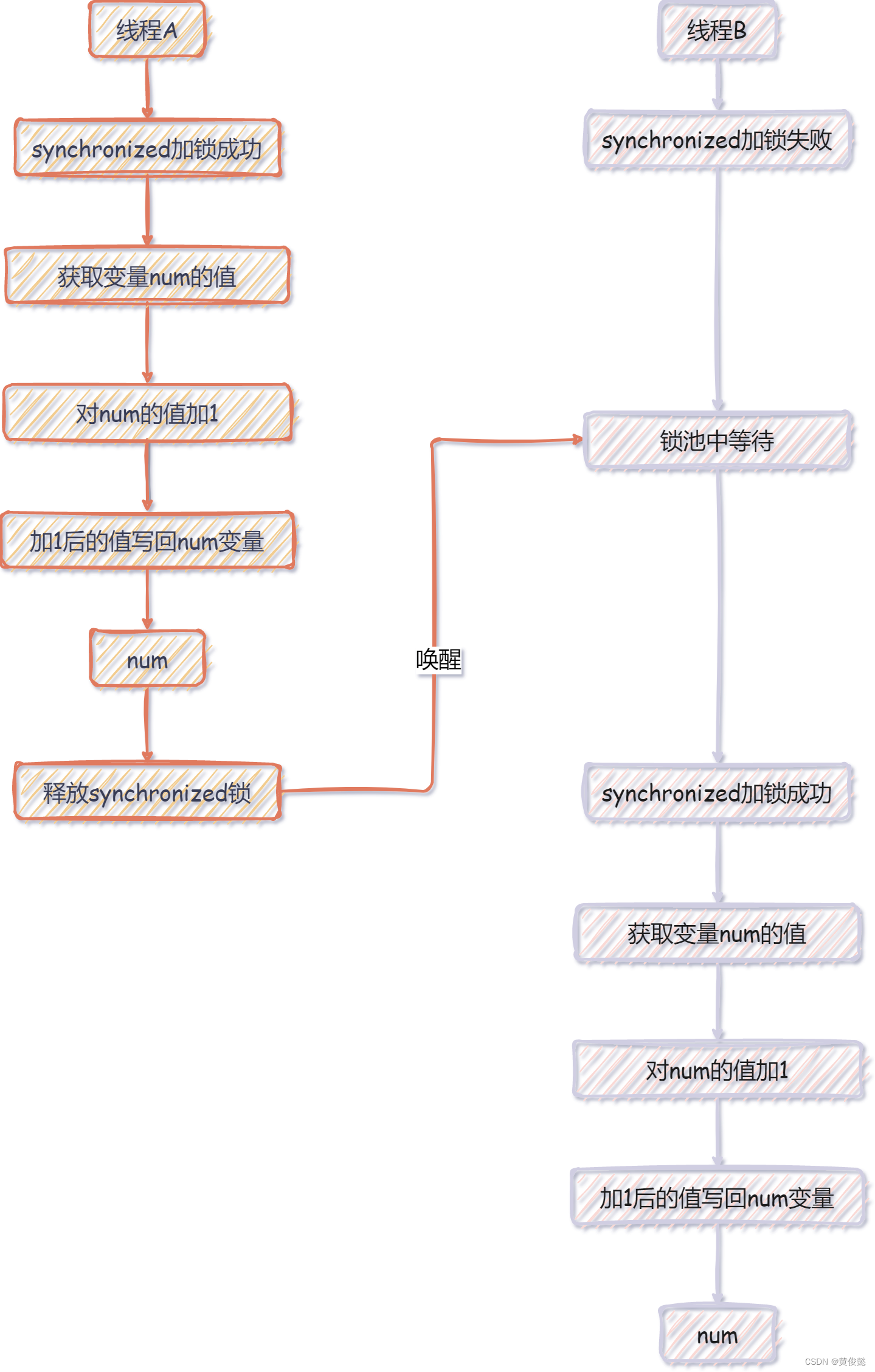
为什么会出现不一致呢?那是因为 num++ 这个操作不是原子的,它分成三步:获取变量num的值,对num的值加1,加1后的值写回num变量。
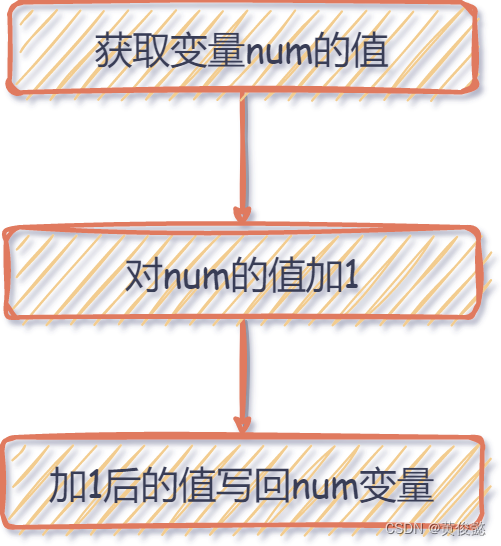
那如果同一时刻,有多个线程做这个 num++ 的操作,会出现什么情况呢?
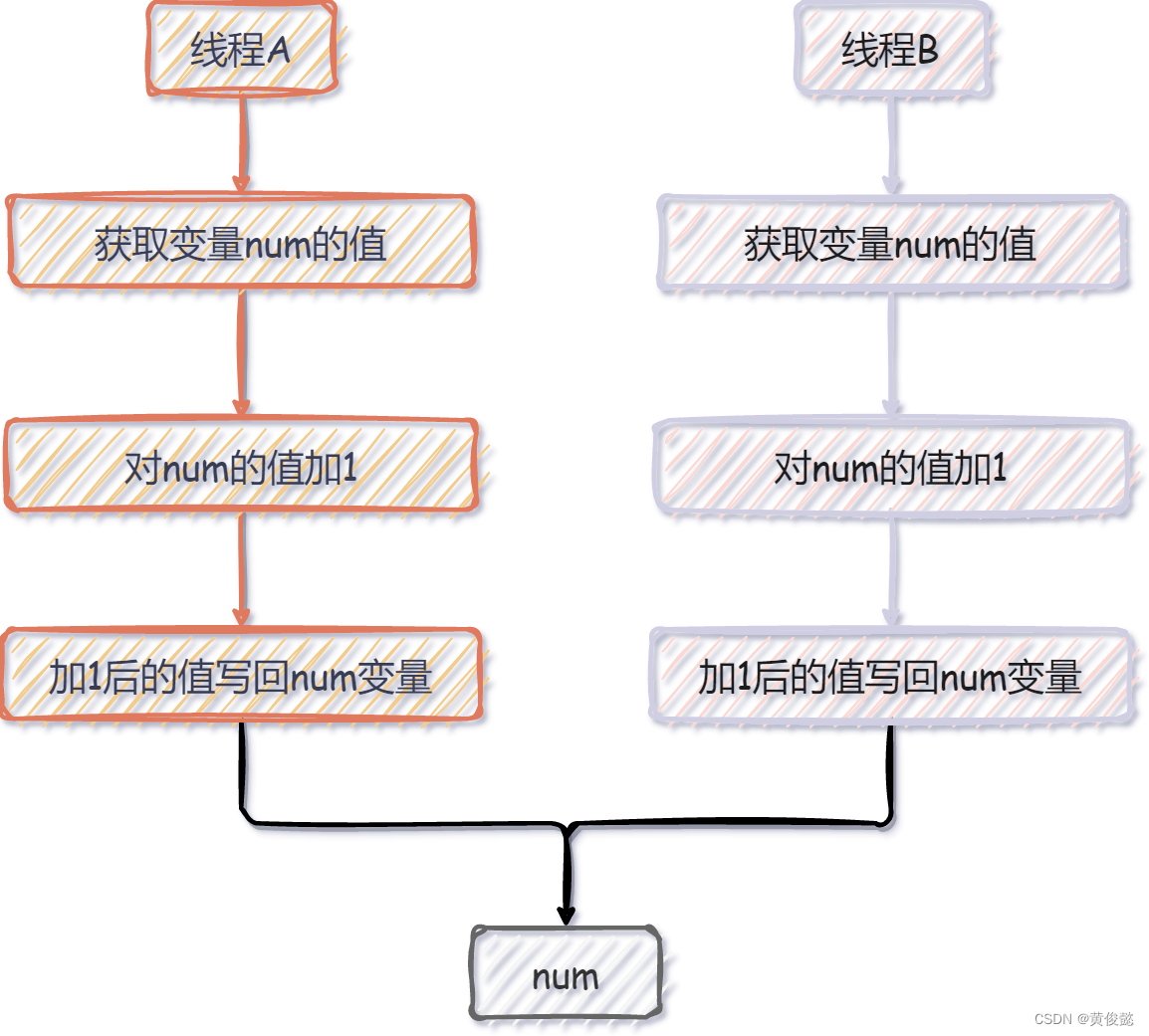
可以看到,加了两次,但是最后只有一次的结果,有一次的加1操作丢了,这样就出现了不一致。
造成这种现象的根本原因,其实就是因为我们对num这个变量没有任何保护措施,任何线程过来都可以随意对它进行操作。如果我们要避免上面的这种情况发生,就要对num这个变量添加一定的保护措施。
比如我们可以使用synchronized关键字,以加锁的方式对该变量进行操作,这样同一时刻就只有一个线程对num变量进行操作,其他获取不到锁的线程就要在锁池中进行等待。
public class Test {
private static Object object = new Object();
private static int num;
public static void addNum1() {
synchronized (object) {
num++;
}
}
public static int getNum() {
return num;
}
public static void main(String[] args) throws InterruptedException {
// 100个线程,每个线程都对num变量加100
for (int i = 0; i < 100; i++) {
new Thread(() -> {
for (int j = 0; j < 100; j++) {
Test.addNum1();
}
}).start();
}
Thread.sleep(1000);
// 得到的结果一定是10000
System.out.println(Test.getNum());
}
}
但是加synchronized锁这种操作是非常重的,它需要通过系统调用请求操作系统加互斥锁Mutex,性能会非常低下,因此还有另外一种方式,那就是使用原子类。
public class Test {
private static AtomicInteger num = new AtomicInteger();
public static void addNum100() {
for (int i = 0; i < 100; i++) {
num.incrementAndGet();
}
}
public static int getNum() {
return num.get();
}
public static void main(String[] args) throws InterruptedException {
// 100个线程,每个线程都对num变量加100
for (int i = 0; i < 100; i++) {
new Thread(() -> Test.addNum100()).start();
}
Thread.sleep(1000);
// 得到的结果就一定是10000
System.out.println(Test.getNum());
}
}
为什么使用了原子类可以有这种效果呢?那就是因为它内部使用了 自旋+CAS 的操作。
CAS
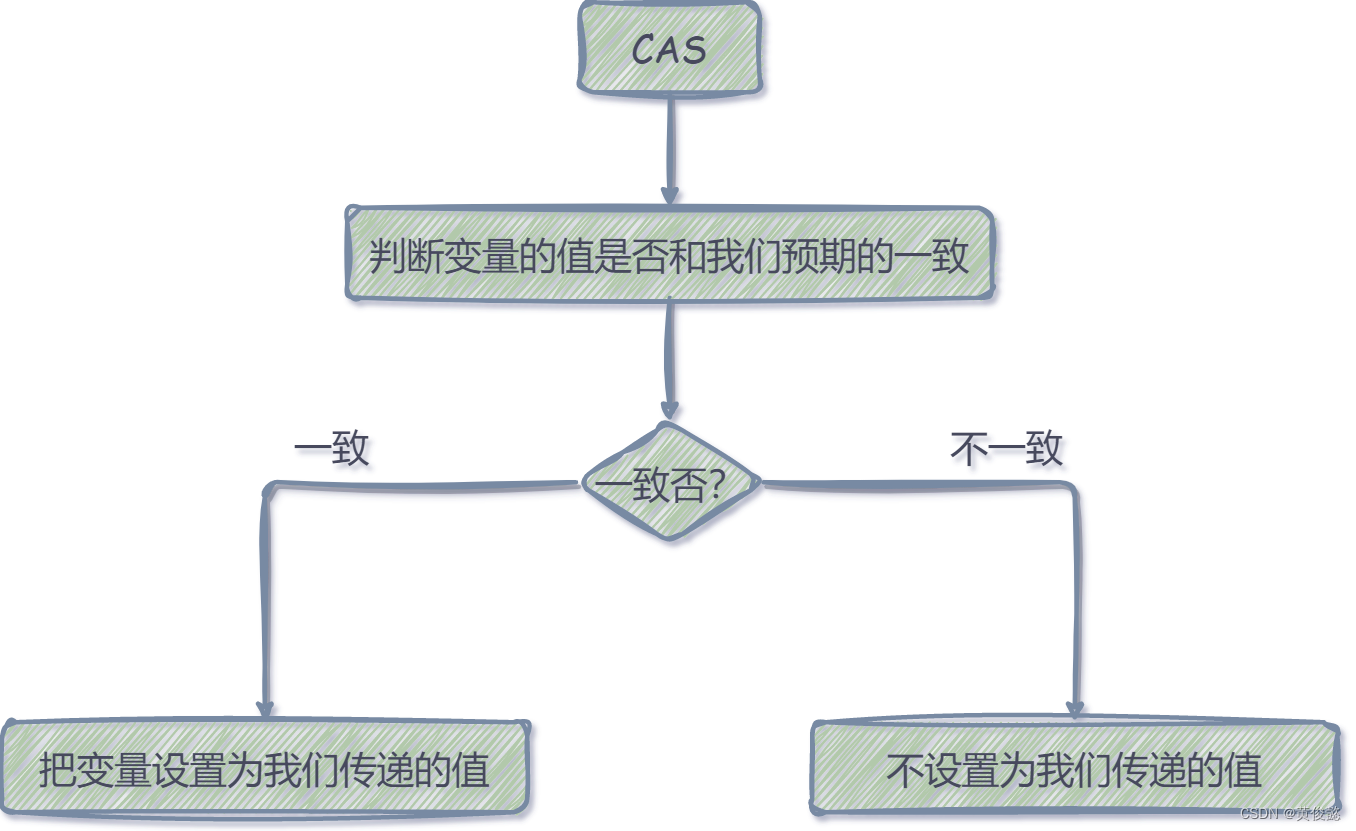
CAS就是比较并交换的意思(Compare And Swap)。在给一个变量赋值之前,会先判断这个变量的值是否和我们预期的一致,如果一致,则表示中间没有人修改过,那么就可以把变量设置为我们传递的值,如果变量的值和我们预期的不一致,表示中间有人修改过,那么就不设置为我们传递的值。
然后如果设置失败,我们可以通过自旋进行重试。我们可以获取到变量最新的值,我们更新预期的值为变量最新的值,再次进行CAS操作,直到成功为止,这就是自旋操作。CAS一般都会搭配自旋一起使用。
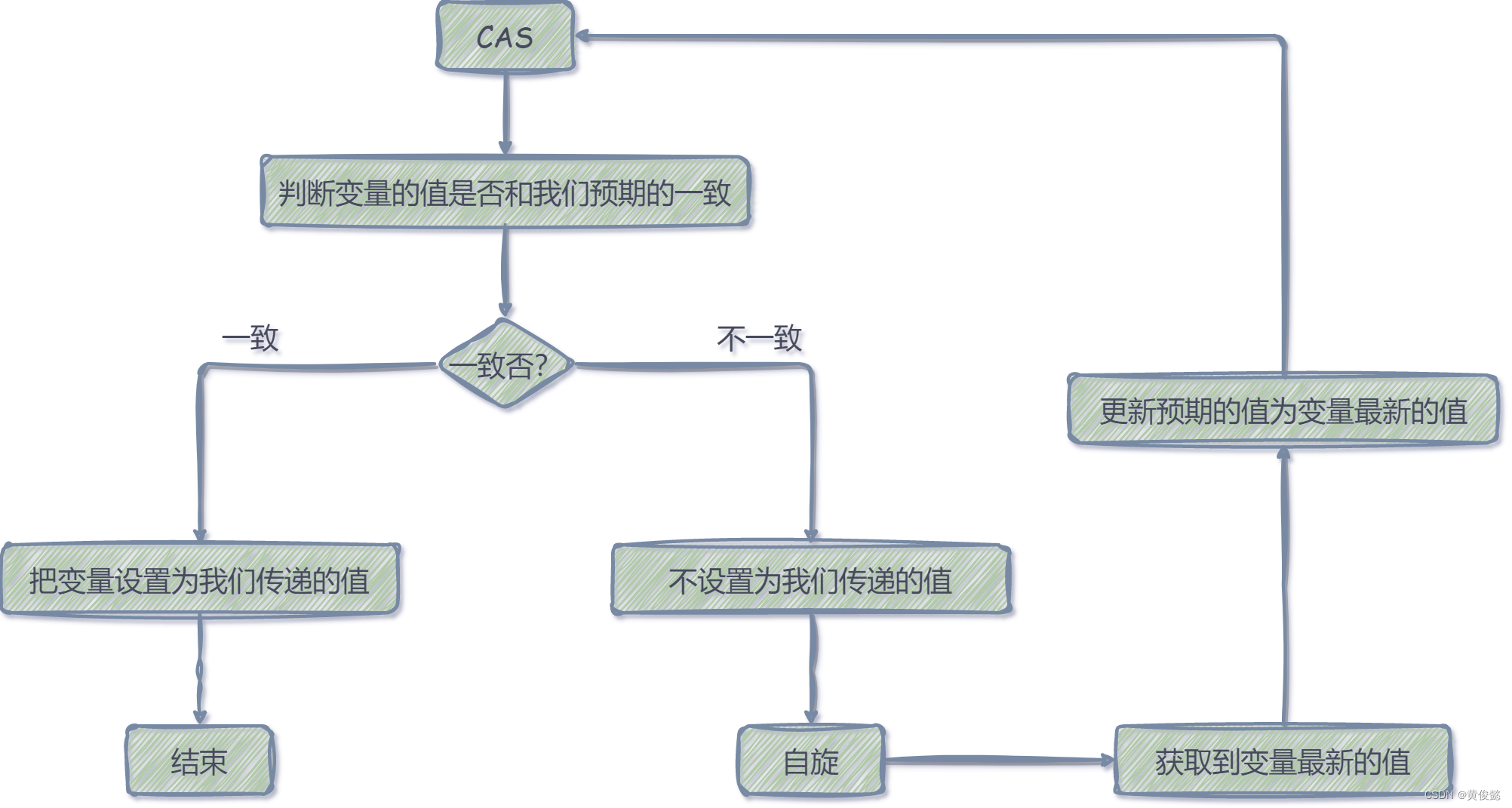
这样会有什么好处呢?那就是CAS失败的线程不用挂起,可以通过自旋进行重试,直到成功为止,这样性能会比加互斥锁要高。
事实上AtomicInteger、AtomicLong等原子类,使用的就是这样方式。
AtomicLong源码解析
我们来看看AtomicLong里面的源码,验证上面所说的那种自旋+CAS 的思想是否正确。
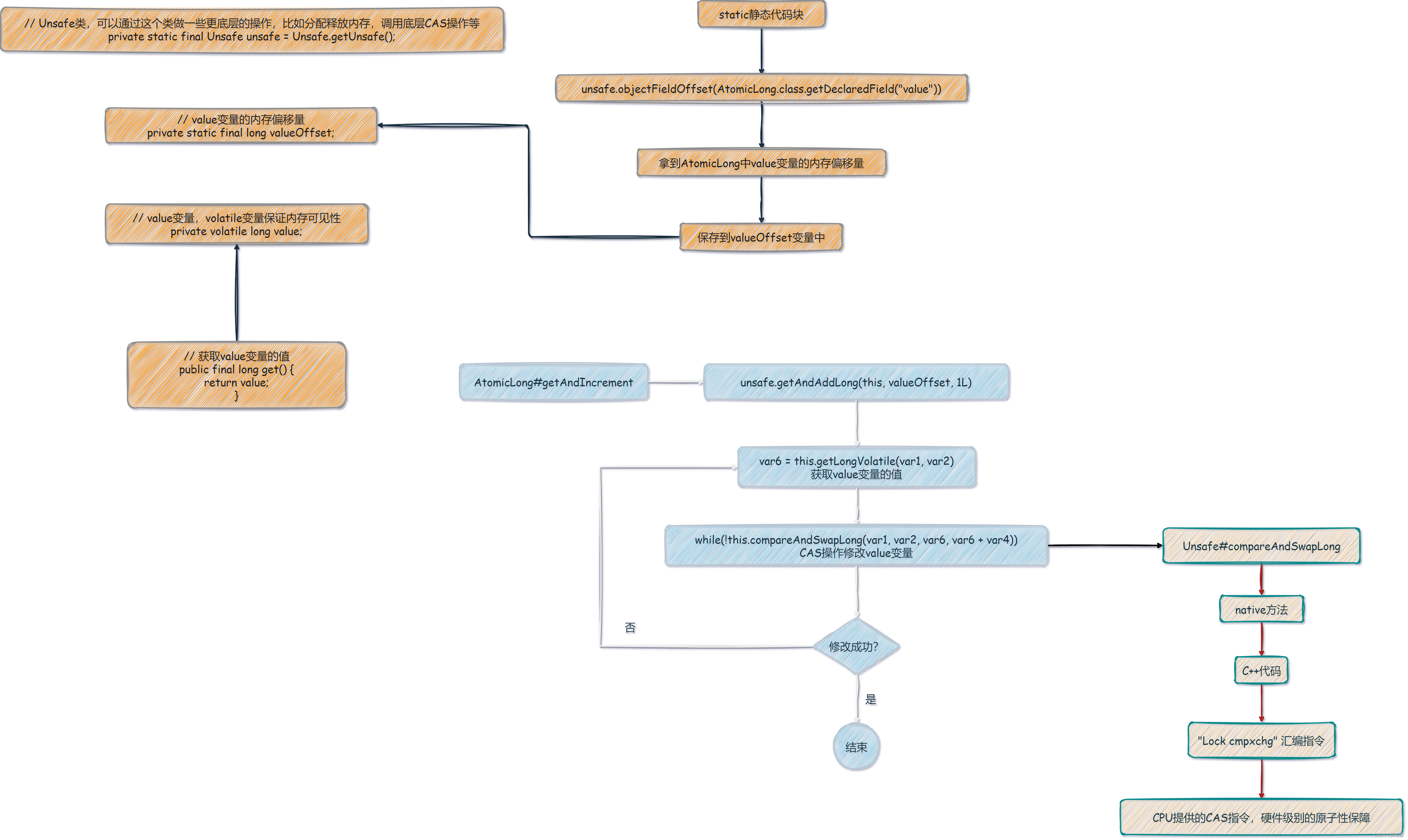
public class AtomicLong extends Number implements java.io.Serializable {
// Unsafe类,可以通过这个类做一些更底层的操作,比如分配释放内存,调用底层CAS操作等
private static final Unsafe unsafe = Unsafe.getUnsafe();
// value变量的内存偏移量
private static final long valueOffset;
static {
try {
// 通过unsafe对象初始化value变量的内存偏移量valueOffset
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// value变量,volatile变量保证内存可见性
private volatile long value;
// 获取value变量的值
public final long get() {
return value;
}
// 通过unsafe类进行自旋+CAS
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
}
首先解析这一句:
// Unsafe类,可以通过这个类做一些更底层的操作,比如分配释放内存,调用底层CAS操作等
private static final Unsafe unsafe = Unsafe.getUnsafe();
Unsafe类,可以通过这个类做一些更底层的操作,我们以内存分配和释放为例。C语言是可以通过malloc函数分配指定大小的内存,然后可以通过free函数释放内存,也就是C语言可以灵活的操作内存的分配和释放,而Java则不可以,只能new一个对象。但是我们可以通过Unsafe类,来分配和释放内存,Unsafe类提供了allocateMemory方法可以用于内存的分配,freeMemory方法进行内存的释放,它们都是native方法,会调用到底层的C++代码。
public native long allocateMemory(long var1);
public native void freeMemory(long var1);

那AtomicLong拿Unsafe类来做什么呢?就是调用Unsafe提供的compareAndSwapLong方法进行原子的CAS操作。如果我们自己写代码实现CAS的话,是无法保证原子性的,比如一个if判断变量是否符合预期,符合则赋值,这样一看就知道是非原子性的操作。
然后再来看这一段:
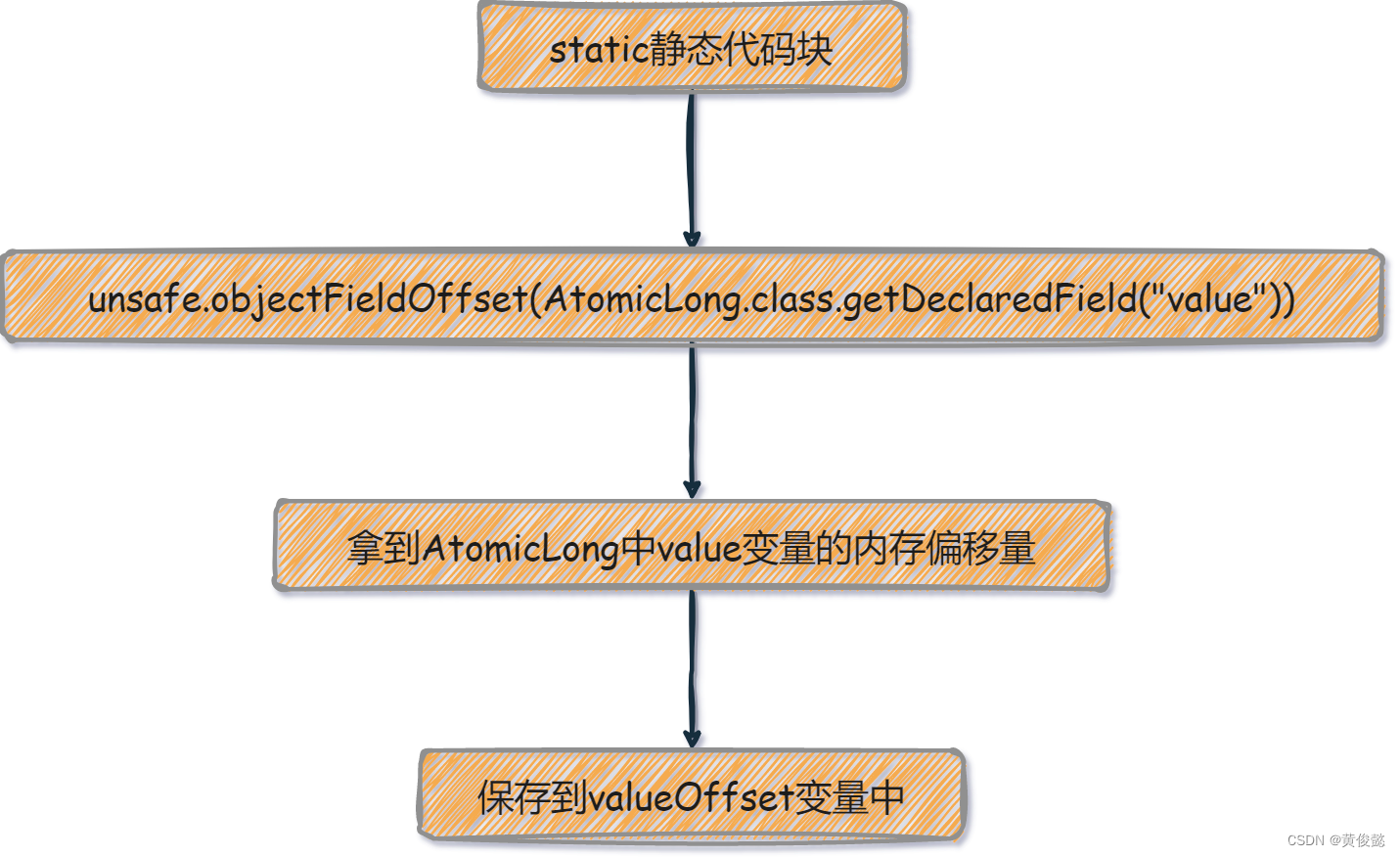
// value变量的内存偏移量
private static final long valueOffset;
static {
try {
// 通过unsafe对象初始化value变量的内存偏移量valueOffset
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
这一段的大体意思就是在初始化AtomicLong时就通过静态代码块,调用unsafe的objectFieldOffset方法拿到AtomicLong的value变量的内存偏移量,保存到valueOffset变量中。之所以要这么做,是因为当调用unsafe的compareAndSwapLong方法时需要提供value变量的内存偏移量。
然后再看这一句:
// value变量,volatile变量保证内存可见性
private volatile long value;
这个就是AtomicLong里面的value变量,通过volatile关键字修饰,保证它的内存可见性,一个线程修改了它的值,其他线程可以马上看到最新值。
然后再往下看:
// 通过unsafe类进行自旋+CAS
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
AtomicLong的getAndIncrement调用了unsafe的getAndAddLong方法,传递了valueOffset参数,我们进入unsafe的getAndAddLong方法看看:
/**
* 参数:
* var1:AtomicLong对象
* var2:valueOffset
* var4:1L
*/
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
// 调用了Unsafe的getLongVolatile获取value变量的值,赋值到var6,参数是AtomicLong对象和valueOffset
var6 = this.getLongVolatile(var1, var2);
// 调用了Unsafe的compareAndSwapLong方法进行CAS操作修改value变量,如果成功则退出while循环,不成功则自旋重试
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
可以看到是完全符合我们上面所说的自旋+CAS的思想。首先通过Unsafe的getLongVolatile方法,根据当前AtomicLong的内存地址和valueOffset内存偏移量,获取指定内存区域上的value值,然后通过Unsafe的compareAndSwapLong方法进行底层的CAS操作修改value值。
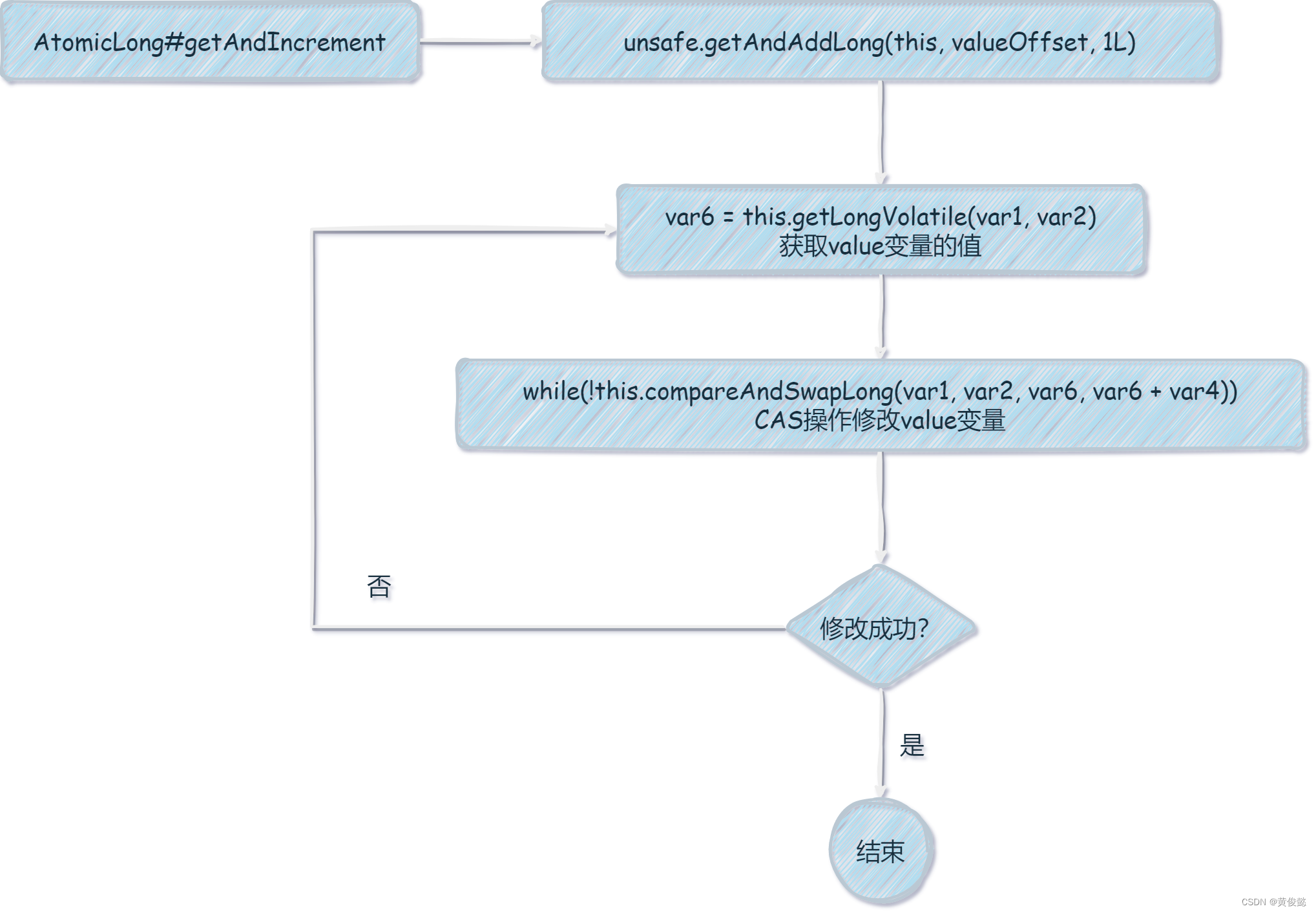
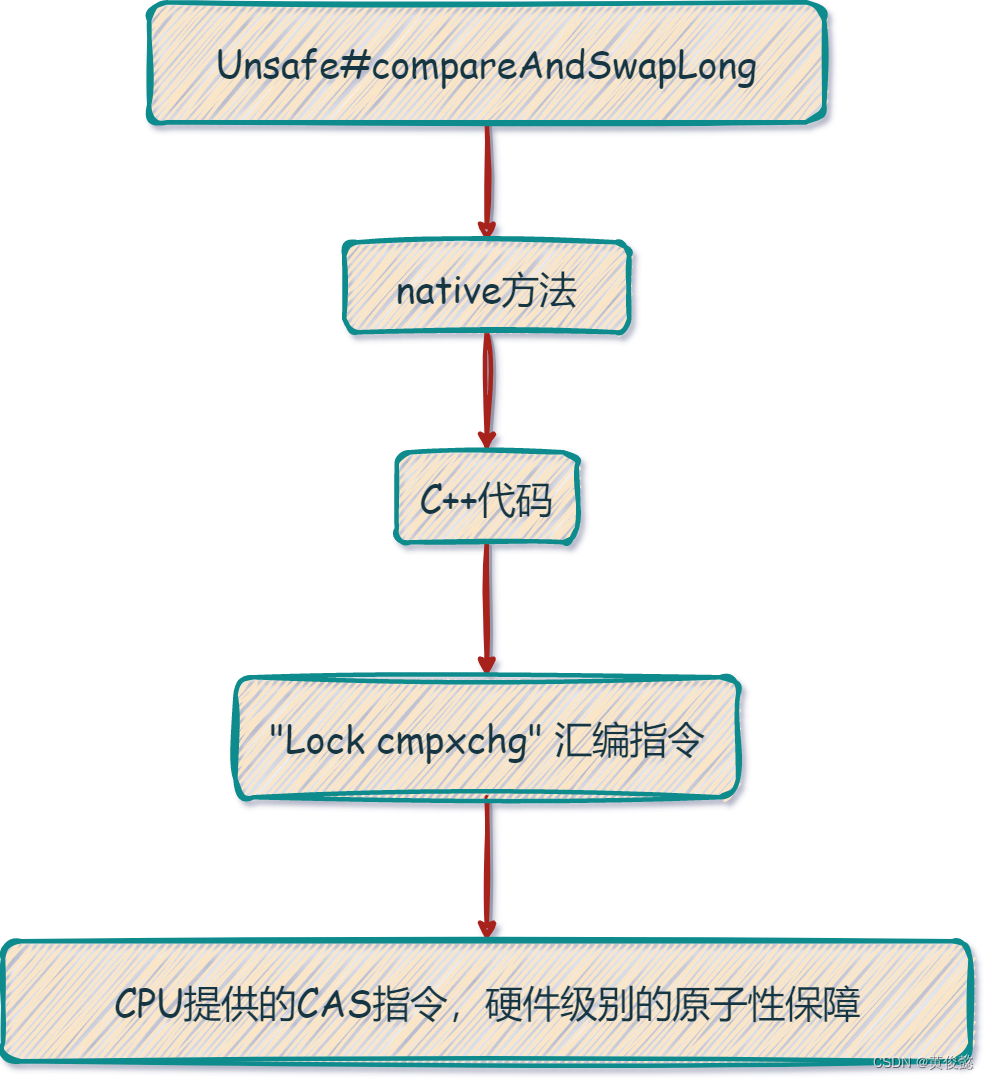
getLongVolatile和compareAndSwapLong都是native方法,会调用底层的C++代码。
public native long getLongVolatile(Object var1, long var2);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
然后底层C++的代码会调用 “Lock cmpxchg” 汇编指令,这个汇编指令会通过底层CPU提供的CAS指令进行CAS操作,提供硬件级别的原子性保障。
最后来一张大图对AtomicLong的源码做个总结:
AtomicLong的问题
上面介绍了AtomicLong的好处,但是AtomicLong也有一些明显的问题:
- ABA问题
- 高并发情况下大量的CAS失败,导致CPU空转
ABA问题
假设现在有两个线程,我们称为1号线程和2号线程,然后内存中有一个变量value。1号线程首先把value设置为A,然后2线程通过CAS设置为B,随后又通过CAS设置为A。然后此时1号线程过来要执行CAS操作,发现value仍然是A,它就以为value没有被修改过,而实际上value是已经被人修改过它,而它却无法感知到。这就是ABA问题。
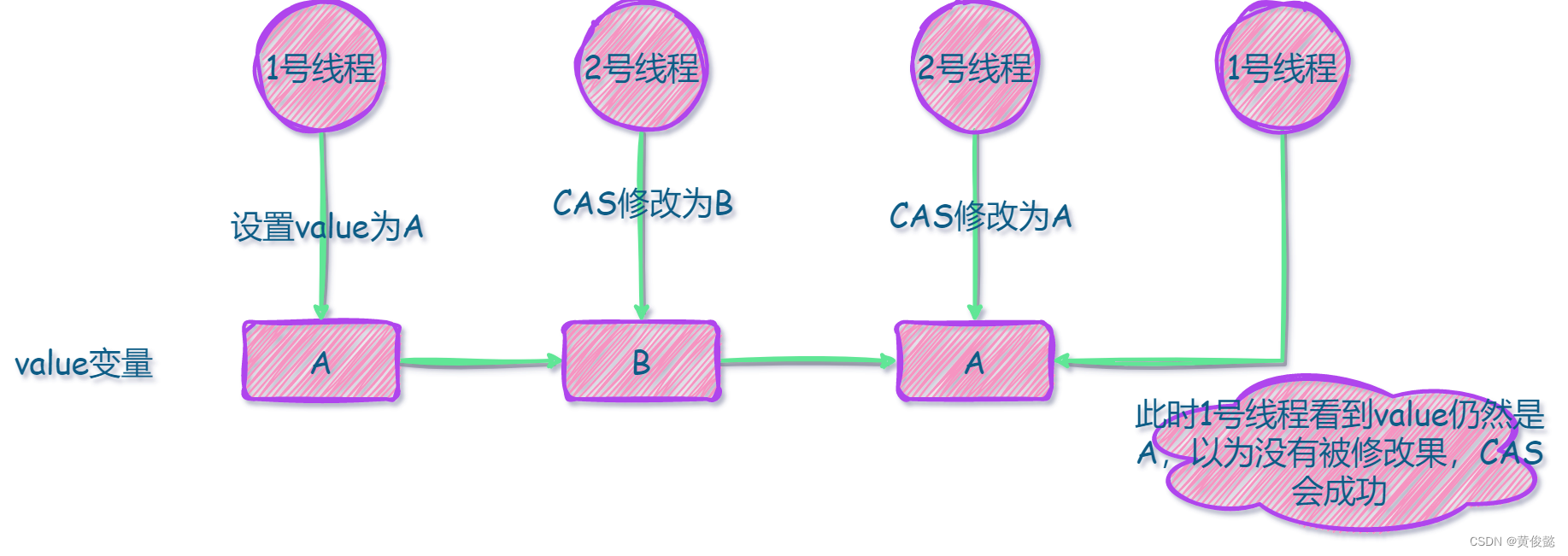
那如何避免这种问题呢?一种方法是保证value修改时顺序递增的,不允许把值改回去;另一种方法就是增加一个版本号或者时间戳来记录value修改的情况,AtomicStampedReference就是这种方法的实现。
AtomicStampedReference
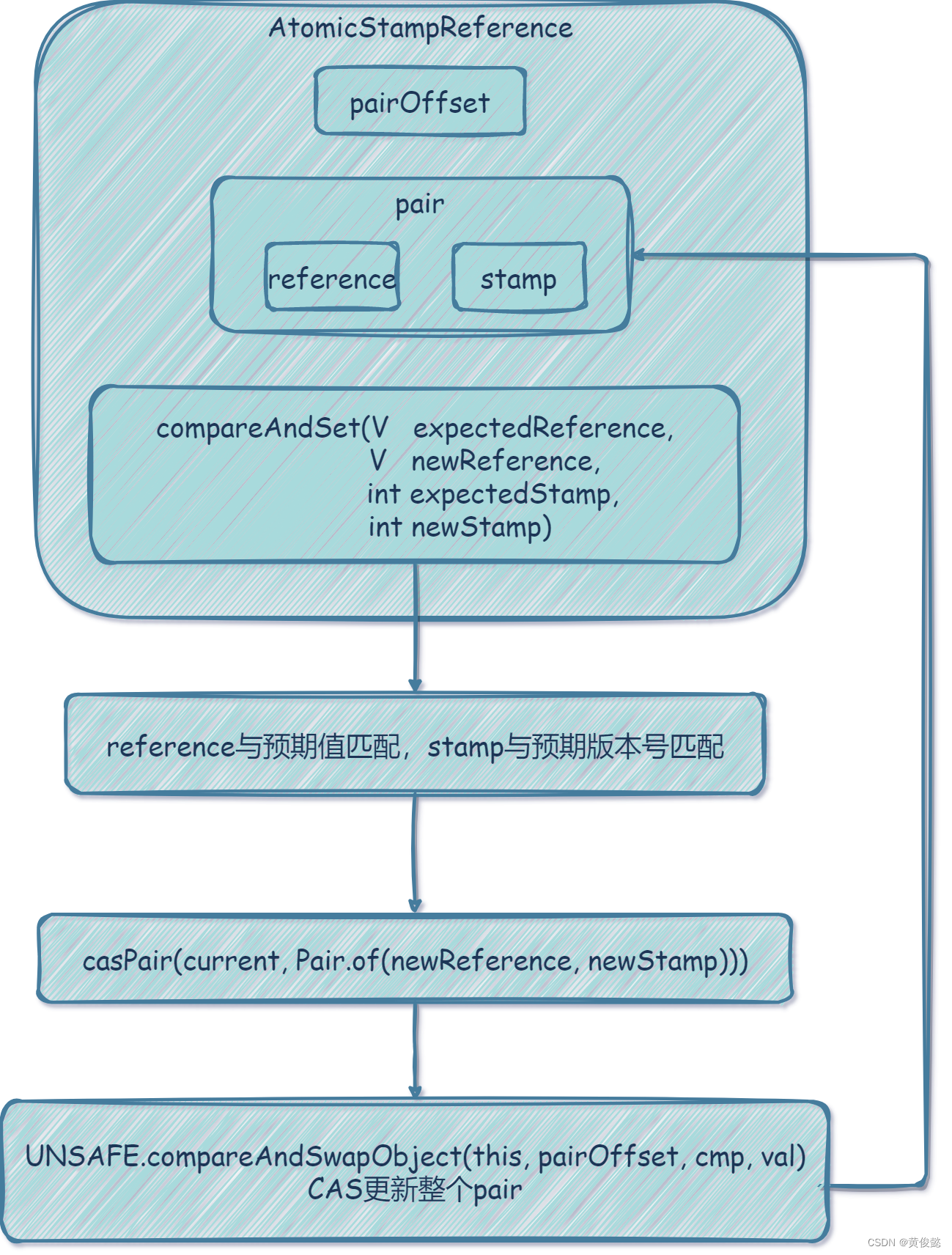
AtomicStampedReference提供了CAS原子更新一整个对象的功能,是AtomicReference的加强版,在AtomicReference的基础上增加了stamp版本号机制解决了ABA问题。
以下就是AtomicStampedReference的核心源码:
public class AtomicStampedReference<V> {
// 用一个Pair对象包装了我们的对象引用和stamp版本号
private static class Pair<T> {
// 我们的对象
final T reference;
// 版本号
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
// pair对象,包装了我们的对象引用和stamp版本号
private volatile Pair<V> pair;
// 获取我们的对象reference
public V getReference() {
return pair.reference;
}
// 获取当前版本号
public int getStamp() {
return pair.stamp;
}
// 通过Unsafe类的objectFieldOffset方法获取pair的内存偏移量pairOffset
private static final long pairOffset =
objectFieldOffset(UNSAFE, "pair", AtomicStampedReference.class);
/*
* CAS更新reference
* expectedReference:预期值
* newReference:reference与预期值expectedReference匹配,并且版本号也与预期的匹配,则更新为newReference
* expectedStamp:预期版本号
* newStamp:新的版本号,如果版本号stamp也与预期版本号expectedStamp匹配,则stamp更新为newStamp
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference && // reference与预期值expectedReference匹配
expectedStamp == current.stamp && // 版本号stamp与预期版本号expectedStamp匹配
((newReference == current.reference &&
newStamp == current.stamp) || // 版本号没变,就不更新了
casPair(current, Pair.of(newReference, newStamp))); // CAS更新pair对象
}
// 调用Unsafe的compareAndSwapObject进行CAS操作更新pair对象
private boolean casPair(Pair<V> cmp, Pair<V> val) {
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}
}
可以看到原理大体和AtomicLong、AtomicReference等相差不远,区别就是增加了一个stamp版本号,并且把需要原子性保障的对象值reference和版本号stamp包装成一个pair对象,外面的内存偏移量是pair对象在AtomicStampReference中的内存偏移量,CAS原子更新的是一整个pair对象。我们只要保证stamp是顺序递增的,就不会出现ABA问题,而reference可以随意修改,不需要保证顺序递增的语义。
高并发情况下大量的CAS失败,导致CPU空转
因为自旋+CAS这种机制,如果CAS失败是要自旋重试,如果在高并发情况下,许多线程同时进行CAS操作,只会有一个线程CAS成功,其他线程就要自旋重试,者就会有大量的线程在那里进行while循环,但是啥也没干,而此时CPU使用率却达到100%,者就严重浪费系统资源,并且使得系统响应速度变慢。
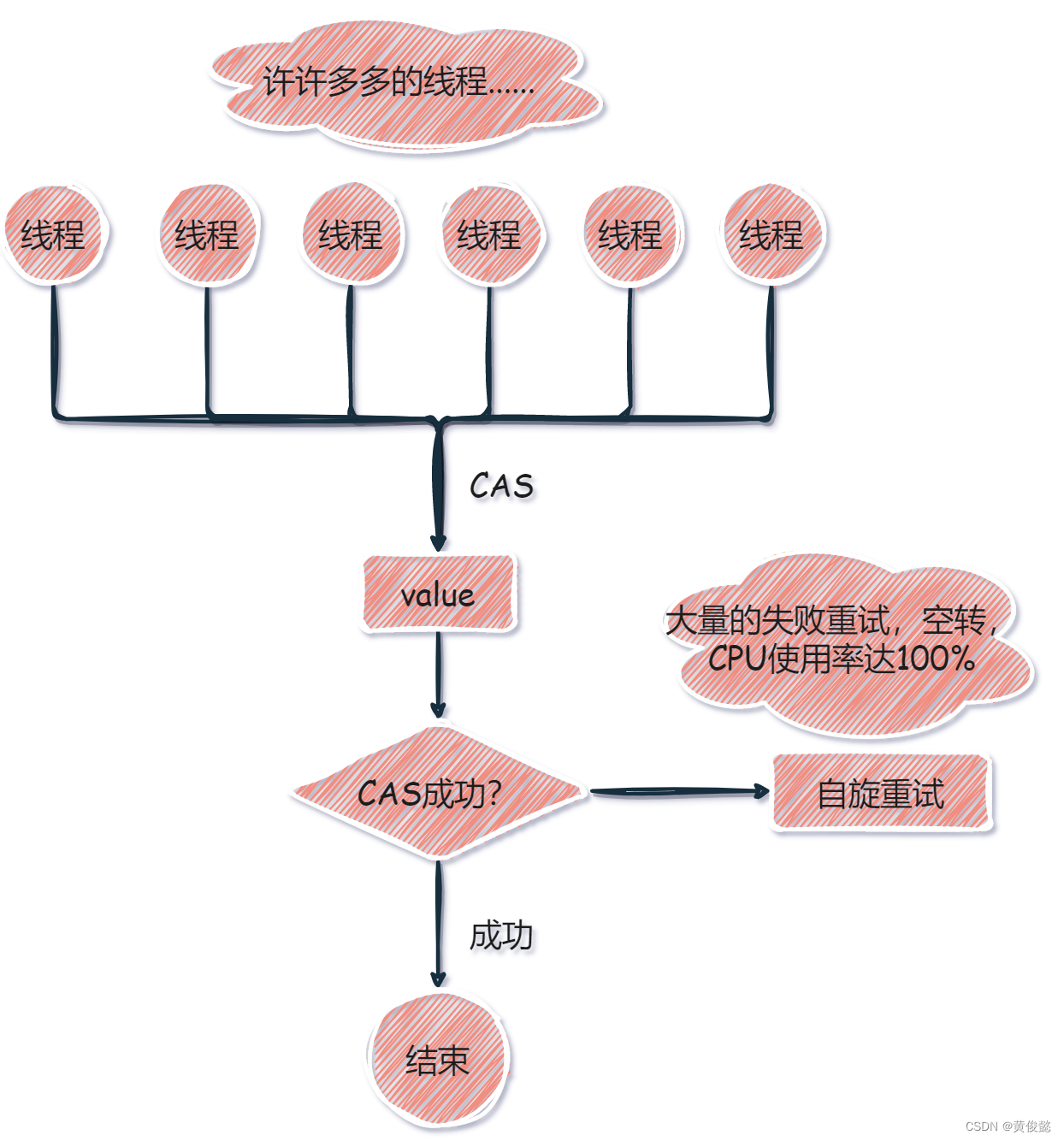
那如何解决这种问题呢?那就是使用LongAdder,至于LongAdder是如何解决这种问题的,就不在这里继续展开描述了,我们留到下一篇文章继续讲解。