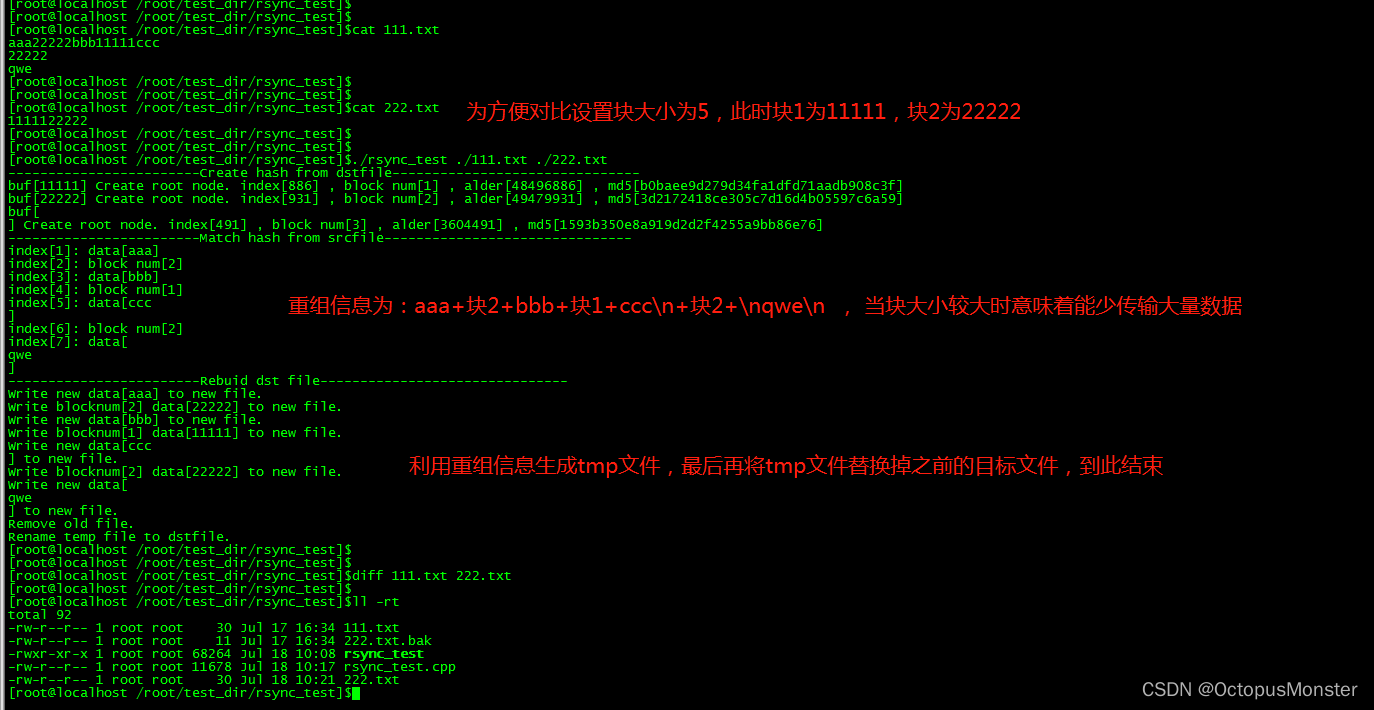
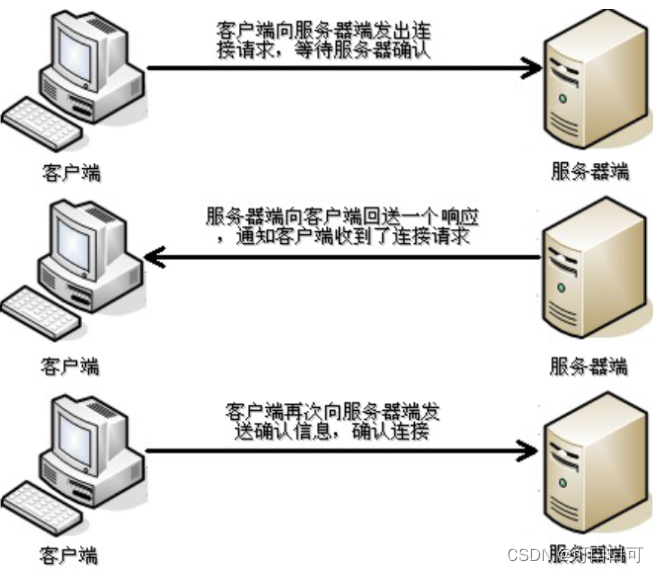
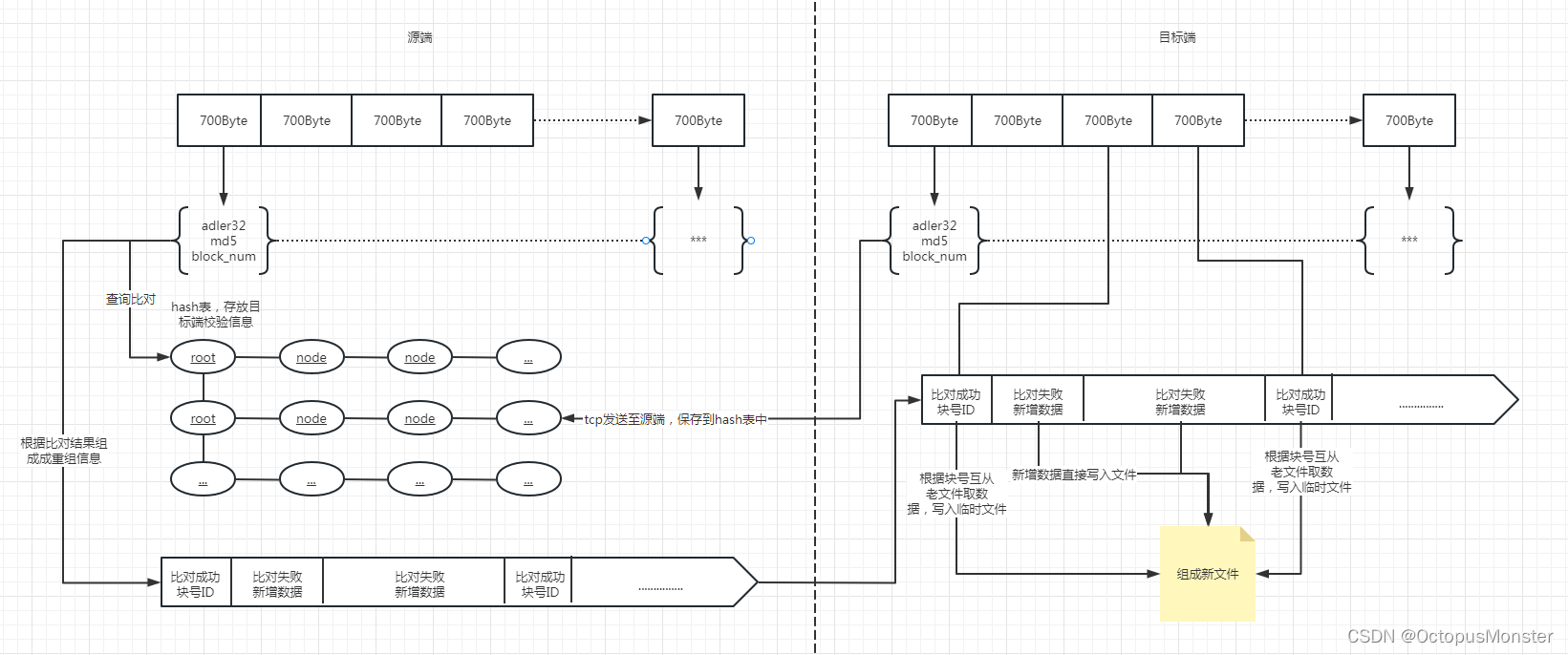
1、目标端将目标文件按700字节为大小分块计算强弱校验值(强:md5 弱:adler32,注:弱校验码计算量小速度快,先比对弱校验码,弱校验值一样再比对强校验码),再结合块号组成一个校验列表发给源端。
2、源端再将这些强弱校验信息利用散列函数存放入hash表(为了快速查询),源端一个字节一个字节逐个偏移文件指针比对块的校验值,组成重组信息发送给目标端。
3、目标端利用重组信息重新生成文件。
代码示例如下, demo中BLOCK_SIZE设置为5方便比较(源码中的默认大小为700),且用的散列函数为相对简单的除余法(源码中的散列函数为其他)。此demo仅本地单进程只处理本地文件,不涉及客户端和服务端。
文件:rsync_test.cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <openssl/md5.h>
#include <sys/types.h>
#include <vector>
#include <string>
using namespace std;
#define MOD_ADLER 65521
#define HASH_SIZE 1000
#define BLOCK_SIZE 5
//数据类型
enum enType
{
EN_DATA = 1,
EN_BLOCK_NUM,
};
//hash表节点定义
typedef struct stNode
{
unsigned int uAdlerValue;
char aMd5Value[32];
unsigned long long ullBlockNum;
struct stNode *pNext;
}tCheckNode;
//hash表根节点列表
tCheckNode * gHashTable[HASH_SIZE];
//散列函数
int GetHashIndex(unsigned int iNum);
//hash表初始化
void InitHashTable();
//hash表销毁
void DestroyHashTable();
//hash表增加节点
void AddNode(tCheckNode stNode);
//从hash表中查询是否存在匹配的adler弱校验值
bool MatchAdler(tCheckNode stNode);
//从hash表中查询是否存在匹配的md5强校验值,并返回该块号,没有则返回0
unsigned long long GetMatchMd5BlockNum(tCheckNode stNode);
//计算adler32弱校验码
unsigned int adler32(unsigned char *data, size_t len);
//计算md5强校验码
void calculateMD5(unsigned char* input , unsigned int len , unsigned char* md5Hash);
//转16进制可见字符串
void convertToHexString(unsigned char* md5Hash, char* md5String);
//获取目标文件校验信息,存入hash表
bool GetCheckInfo(char *aFilePath);
//比对源文件和hash表的校验值,获得重组信息放入vector
bool GetRebuildInfo(char *aSrcPath , vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo);
//打印重组信息
void PrintRebuildInfo(vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo);
//重组目标文件
bool Rebuild(char *aDstFile , vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo);
int GetHashIndex(unsigned int iNum)
{
return iNum%HASH_SIZE;
}
void InitHashTable()
{
int i = 0;
for(i = 0 ; i < HASH_SIZE ; i++)
{
gHashTable[i] = NULL;
}
}
void DestroyHashTable()
{
int i = 0;
for(i = 0 ; i < HASH_SIZE ; i++)
{
tCheckNode *pNow = gHashTable[i];
if(NULL != pNow)
{
while(1)
{
tCheckNode *pNext = pNow->pNext;
free(pNow);
pNow = pNext;
if(NULL == pNow)
break;
}
}
}
}
void AddNode(tCheckNode stNode)
{
int iIndex = GetHashIndex(stNode.uAdlerValue);
tCheckNode *pRoot = NULL;
tCheckNode *pNow = NULL;
if(NULL == pRoot)
{
//创建根节点
pRoot = (tCheckNode*)malloc(sizeof(tCheckNode));
memcpy(pRoot , &stNode , sizeof(tCheckNode));
gHashTable[iIndex] = pRoot;
printf("Create root node. index[%d] , block num[%llu] , alder[%u] , md5[%s]\n" , iIndex , stNode.ullBlockNum , stNode.uAdlerValue , stNode.aMd5Value);
}
else
{
//尾部追加节点
pNow = pRoot;
while(1)
{
if(pNow->pNext)
{
pNow = pNow->pNext;
}
else
{
pNow->pNext = (tCheckNode*)malloc(sizeof(tCheckNode));
memcpy(pNow->pNext , &stNode , sizeof(tCheckNode));
printf("Add new node. index[%d] , block num[%llu] , alder[%u] , md5[%s]\n" , iIndex , stNode.ullBlockNum , stNode.uAdlerValue , stNode.aMd5Value);
break;
}
}
}
}
bool MatchAdler(tCheckNode stNode)
{
int iIndex = GetHashIndex(stNode.uAdlerValue);
unsigned uAdler = stNode.uAdlerValue;
tCheckNode *pRoot = gHashTable[iIndex];
tCheckNode *pNow = NULL;
bool bFindFlag = false;
do{
if(NULL == pRoot)
{
break;
}
pNow = pRoot;
while(1)
{
if(NULL == pNow) //直到链表尾都没匹配
{
bFindFlag = false;
break;
}
else if(pNow->uAdlerValue == uAdler)
{
//printf("[%u]~[%u]\n" , pNow->uAdlerValue , uAdler);
bFindFlag = true;
break;
}
else
{
//printf("[%u]~[%u]\n" , pNow->uAdlerValue , uAdler);
pNow = pNow->pNext;
}
}
if(bFindFlag == false)
break;
return true;
}while(0);
return false;
}
unsigned long long GetMatchMd5BlockNum(tCheckNode stNode)
{
int iIndex = GetHashIndex(stNode.uAdlerValue);
unsigned uAdler = stNode.uAdlerValue;
tCheckNode *pRoot = gHashTable[iIndex];
tCheckNode *pNow = NULL;
bool bFindFlag = false;
do{
if(NULL == pRoot)
break;
pNow = pRoot;
while(1)
{
if(NULL == pNow) //直到链表尾都没匹配
{
bFindFlag = false;
break;
}
else if(pNow->uAdlerValue == uAdler && memcmp(stNode.aMd5Value , pNow->aMd5Value , 32) == 0)
{
bFindFlag = true;
break;
}
else
{
pNow = pNow->pNext;
}
}
if(bFindFlag == false)
break;
return pNow->ullBlockNum;
}while(0);
return 0;
}
unsigned int adler32(unsigned char *data, size_t len = 700)
{
unsigned int a = 1, b = 0;
size_t index;
for (index = 0; index < len; ++index)
{
a = (a + data[index]) % MOD_ADLER;
b = (b + a) % MOD_ADLER;
}
return (b << 16) | a;
}
void calculateMD5(unsigned char* input , unsigned int len , unsigned char* md5Hash)
{
MD5_CTX context;
MD5_Init(&context);
MD5_Update(&context, input, len);
MD5_Final(md5Hash, &context);
}
void convertToHexString(unsigned char* md5Hash, char* md5String)
{
for (int i = 0; i < MD5_DIGEST_LENGTH; i++) {
sprintf(&md5String[i * 2], "%02x", (unsigned int)md5Hash[i]);
}
}
bool GetCheckInfo(char *aFilePath)
{
FILE *fp = fopen64(aFilePath , "r");
if(NULL == fp)
{
puts("Func fopen64 error!");
return false;
}
unsigned char alBuf[BLOCK_SIZE+1] = {0};
int i = 0;
while(1)
{
memset(alBuf , 0 , BLOCK_SIZE);
fread(alBuf , BLOCK_SIZE , 1 , fp);
printf("buf[%s] " , alBuf);
i++;
unsigned int uAdler = adler32(alBuf , BLOCK_SIZE);
char alMd5Hex[32+1] = {0};
unsigned char alMd5[16+1] = {0};
calculateMD5(alBuf , BLOCK_SIZE , alMd5);
convertToHexString(alMd5 , alMd5Hex);
tCheckNode tNode;
memset(&tNode , 0 , sizeof(tCheckNode));
tNode.uAdlerValue = uAdler;
memcpy(tNode.aMd5Value , alMd5Hex , 32);
tNode.ullBlockNum = i;
AddNode(tNode);
if(feof(fp) == true)
break;
}
fclose(fp);
return true;
}
bool GetRebuildInfo(char *aSrcPath , vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo)
{
FILE *fp = fopen64(aSrcPath , "r");
if(NULL == fp)
{
puts("Func fopen64 error!");
return false;
}
unsigned char alBuf[BLOCK_SIZE+1] = {0};
bool bMatchFlag = false;
vector<unsigned char> vecBuffer;
int i = 1;
while(1)
{
memset(alBuf , 0 , BLOCK_SIZE);
unsigned long long ullMatchBlockNum = 0;
size_t iReadSize = fread(alBuf , 1 , BLOCK_SIZE , fp);
unsigned int uAdler = adler32(alBuf , BLOCK_SIZE);
char alMd5Hex[32+1] = {0};
unsigned char alMd5[16+1] = {0};
calculateMD5(alBuf , BLOCK_SIZE , alMd5);
convertToHexString(alMd5 , alMd5Hex);
tCheckNode tNode;
memset(&tNode , 0 , sizeof(tCheckNode));
tNode.uAdlerValue = uAdler;
memcpy(tNode.aMd5Value , alMd5Hex , 32);
tNode.ullBlockNum = i++;
//printf("Curr check value. block num[%llu] , alder[%u] , md5[%s]\n" , tNode.ullBlockNum , tNode.uAdlerValue , tNode.aMd5Value);
//比较adler
if(MatchAdler(tNode) == false)
{
bMatchFlag = false;
}
else
{
//比较md5
ullMatchBlockNum = GetMatchMd5BlockNum(tNode);
if(ullMatchBlockNum == 0)
{
bMatchFlag = false;
}
else
{
bMatchFlag = true;
}
}
if(bMatchFlag == false) //未比较成功偏移一字节
{
//保存需偏移的字节内容
if(feof(fp) == true)
{
for(int i = 0 ; i < iReadSize ; i++)
{
vecBuffer.push_back(alBuf[i]);
}
//记录新增内容
vecRebuildInfo.push_back(make_pair(EN_DATA , vecBuffer));
}
else
{
vecBuffer.push_back(alBuf[0]);
fseeko64(fp , 1-iReadSize , SEEK_CUR);
}
}
else
{
//记录新增内容
if(vecBuffer.size() != 0)
{
vecRebuildInfo.push_back(make_pair(EN_DATA , vecBuffer));
}
vecBuffer.clear();
//记录块号
char alTmp[100] = {0};
sprintf(alTmp , "%llu" , ullMatchBlockNum);
vecBuffer = vector<unsigned char>(alTmp , alTmp+strlen(alTmp));
vecRebuildInfo.push_back(make_pair(EN_BLOCK_NUM , vecBuffer));
vecBuffer.clear();
}
//读到文件尾跳出循环
if(feof(fp) == true)
break;
}
fclose(fp);
return true;
}
void PrintRebuildInfo(vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo)
{
int i = 1;
vector< pair<enType , vector<unsigned char> > >::iterator it = vecRebuildInfo.begin();
for(; it != vecRebuildInfo.end() ; it++)
{
printf("index[%d]: " , i++);
string sData(it->second.begin() , it->second.end());
if(it->first == EN_DATA)
{
printf("data[%s]\n" , sData.c_str());
}
else
{
printf("block num[%s]\n" , sData.c_str());
}
}
}
bool Rebuild(char *aDstFile , vector< pair<enType , vector<unsigned char> > > &vecRebuildInfo)
{
FILE *fp = fopen64(aDstFile , "r");
if(NULL == fp)
{
puts("Func fopen64 error!");
return false;
}
char alTmpFile[1024] = {0};
sprintf(alTmpFile , "%s.tmp" , aDstFile);
FILE *new_fp = fopen64(alTmpFile , "w");
if(NULL == new_fp)
{
puts("Func fopen64 error!");
fclose(fp);
return false;
}
for(const auto &vecNode : vecRebuildInfo)
{
if(vecNode.first == EN_DATA)
{
//新增数据
unsigned long long ullSize = vecNode.second.size();
char *pBuf = (char *)malloc(ullSize);
memset(pBuf , 0 , ullSize);
copy(vecNode.second.begin(), vecNode.second.end(), pBuf);
fwrite(pBuf , ullSize , 1 , new_fp);
printf("Write new data[%s] to new file.\n" , pBuf);
free(pBuf);
}
else
{
//已有数据
string sTmp(vecNode.second.begin() , vecNode.second.end());
int iBlockNum = atoi(sTmp.c_str());
char alBuf[BLOCK_SIZE+1] = {0};
//文件指针偏移
fseeko64(fp , BLOCK_SIZE*(iBlockNum-1) , SEEK_SET);
fread(alBuf , 1 , BLOCK_SIZE , fp);
fwrite(alBuf , BLOCK_SIZE , 1 , new_fp);
printf("Write blocknum[%d] data[%s] to new file.\n" , iBlockNum , alBuf);
}
}
fclose(fp);
fclose(new_fp);
remove(aDstFile);
puts("Remove old file.");
rename(alTmpFile , aDstFile);
puts("Rename temp file to dstfile.");
return true;
}
int main(int argc, char *argv[])
{
if(argc != 3)
{
puts("USAGE: ./rsync_test [src_file_path] [dst_file_path]");
return -1;
}
char alSrcPath[1024] = {0};
char alDstPath[1024] = {0};
strcpy(alSrcPath , argv[1]);
strcpy(alDstPath , argv[2]);
if(access(alSrcPath , F_OK) != 0)
{
puts("Src file must exist!");
return -2;
}
if(access(alDstPath , F_OK) != 0)
{
//直接复制
char alCmd[1024] = {0};
sprintf(alCmd , "cp -pf %s %s" , alSrcPath , alDstPath);
system(alCmd);
}
else
{
struct stat slStatTmp;
memset(&slStatTmp , 0 , sizeof(struct stat));
stat(alSrcPath, &slStatTmp);
time_t tSrcTime = slStatTmp.st_mtime;
unsigned long long ullSrcSize = slStatTmp.st_size;
stat(alDstPath, &slStatTmp);
time_t tDstTime = slStatTmp.st_mtime;
unsigned long long ullDstSize = slStatTmp.st_size;
if(tSrcTime != tDstTime || ullSrcSize != ullDstSize)
{
InitHashTable();
puts("------------------------Create hash from dstfile-------------------------------");
//先获取目标文件校验信息并放入hash表
if(GetCheckInfo(alDstPath) == false)
{
puts("Func GetCheckInfo error!");
return -3;
}
puts("------------------------Match hash from srcfile-------------------------------");
//按1字节偏移比对强弱校验值,并存入vector容器
vector< pair<enType , vector<unsigned char> > > vecRebuildInfo;
GetRebuildInfo(alSrcPath , vecRebuildInfo);
PrintRebuildInfo(vecRebuildInfo);
puts("------------------------Rebuid dst file-------------------------------");
Rebuild(alDstPath , vecRebuildInfo);
DestroyHashTable();
}
else
{
printf("Src file[%s] and dst file[%s] are the same.\n" , alSrcPath , alDstPath);
}
}
return 0;
}
编译:g++ rsync_test.cpp -o rsync_test -lcrypto -std=c++11
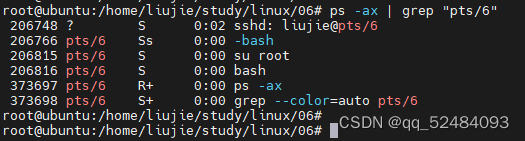
运行结果如下