目录
一、概述
二、基础了解
2.1 32位进程默认内存布局
2.2 brk & sbrk & mmap
三、内存管理
2.1 结构
2.1.1 main_arena 与 non_main_arena
2.1.2 malloc_chunk
2.1.3 空闲链表bins
2.1.4 初始化
2.2 内存分配与释放
三、ptmalloc、tcmalloc与jemalloc实现机制对比分析
一、概述
ptmalloc是开源 GNU C Library (glibc) 默认的内存管理器,当前大部分Linux服务端程序使用的是ptmalloc提供的malloc/free系列函数,而其在性能上远差于Meta的jemalloc和Google的tcmalloc
服务端程序调用ptmalloc提供的malloc/free函数申请和释放内存,ptmalloc提供对内存的集中管理,以尽可能达到:
-
用户申请和释放内存更加高效,避免多线程申请内存并发和加锁
-
寻求与操作系统交互过程中内存占用和malloc/free性能消耗的平衡点,降低内存碎片化,不频繁调用系统调用函数
为了内存分配函数malloc的高效性,ptmalloc会预先向操作系统申请一块内存供用户使用,并且ptmalloc会将已经使用的和空闲的内存管理起来;当用户需要释放内存free时,ptmalloc又会将回收的内存管理起来,根据实际情况决定是否回收给操作系统(内存池通性)
二、基础了解
2.1 32位进程默认内存布局

栈至顶向下扩展,堆至底向上扩展,mmap映射区域至顶向下扩展。mmap映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域
2.2 brk & sbrk & mmap
int brk(const void *addr)
void* sbrk(intptr_t incr)- 两者的作用都是扩展heap的上界
- brk()的参数设置为新的brk上界地址,成功返回1,失败返回0
- sbrk()的参数为申请内存的大小,返回heap新的上界brk的地址
void* mmap(void* addr, size_t length, int prot, int flags, int fd, off_t offset)
int munmap(void& addr, size_t length)- mmap第一种用法是映射此盘文件到内存中
- mmap第二种用法是匿名映射,不映射此盘文件,而向映射区申请一块内存,malloc使用的是第二种用法
- munmap用于释放内存
三、内存管理
2.1 结构
为了解决多线程锁争夺问题,将内存分配区分为主分配区 (main_area) 和非主分配区 (no_main_area)。同时,为了便于管理内存,对预申请的内存采用边界标记法划分成很多块 (chunk);ptmalloc内存分配器中,malloc_chunk是基本组织单元,用于管理(描述)不同类型的chunk,功能和大小相近的chunk串联成链表,被称为一个bin
2.1.1 main_arena 与 non_main_arena
内存分配器中,为了解决多线程锁争夺问题,分为主分配区main_area(分配区的本质就是内存池,管理着chunk)和非主分配区no_main_area
-
主分配区和非主分配区形成一个环形链表进行管理
-
每个分配区利用互斥锁使线程对于该分配区的访问互斥
-
每个进程只有一个主分配区,允许有多个非主分配区
-
ptmalloc根据系统对分配区的调用动态增加分配区的大小,分配区的数量一旦增加,则不会减少
-
主分配区可以使用brk()和mmap()来分配,而非主分配区只能使用mmap()来映射内存块
-
申请小内存时会产生很多内存碎片,ptmalloc在整理时也需对分配区做加锁操作
当一个线程需要使用malloc分配内存时,先查看该线程的私有变量中是否存在一个分配区,若是存在,会尝试对其进行加锁操作。若加锁成功,就会在使用该分配区分配内存;若是失败,就会遍历循环链表中获取一个未加锁的分配区。若是整个链表中都没有未加锁的分配区,则会开辟一个新的分配区,将其加入全局的循环链表并加锁,然后使用该分配区进行分配。当释放这块内存时,同样会先获取待释放内存块所在的分配区的锁。若是有其他线程正在使用该分配区,则必须等待其他线程释放该分配区互斥锁后才能进行内存释放
注意:
-
非主分配区虽然是mmap()分配,但是和大于128K直接使用mmap()分配没有任何关系。大于128K的内存使用mmap()分配,使用完之后直接用ummap()还给系统
-
每个线程在malloc会先获取一个area,使用area内存池分配各自的内存,存在竞争关系
-
为了避免竞争,可以使用线程局部存储的策略,thead cache(tcmalloc中的tc正是此意)
2.1.2 malloc_chunk
ptmalloc统一管理heap和mmap映射区域中空闲的chunk,当用户进行分配请求时,会先试图在空闲的chunk中查找和分割,从而避免频繁的系统调用,降低内存分配的开销。为了更好的管理和查找空闲chunk,在预分配的空间的前后添加了必要的控制信息
- prev_size: 若前一个chunk是空闲的,该域表示前一个chunk的大小;若不空闲,该域无意义(知道当前chunk地址,减去prev_size,便得到前一个chunk的地址,prev_size主要用于相邻空闲的chunk合并)
- size:当前chunk的大小,并且记录了如下一些其他属性
- 前一个chunk在使用中 (P = 1)
- 当前chunk是mmap映射区域分配 (M = 1) 或是heap区域分配 (M = 0)
- 当前chunk属于非主分配区 (A = 0) 或非主分配区 (A = 1)
- fd 和 bk: 只有该chunk空闲时才会存在,其作用是用于将对应的空闲chunk块加入到空闲chunk块链表中统一管理,若该chunk块被分配给应用程序使用,那么这两个指针也就没有用,所以此区域也被当作应用程序的使用空间
- fd_nextsize & bk_nextsize:当前chunk存在于large bins中,large bins中的空闲chunk是按照大小排序,若存在多个同一大小的chunk,增加这两个字段可以加快遍历空闲chunk,并查找满足需要的空闲chunk,fd_nextsize指向下一个比当前chunk大的第一个空闲chunk,bk_nextsize指向前一个比当前chunk小的第一个空闲chunk。若该chunk块被分配给应用程序使用,那么这两个指针也就没有用,所以此区域也被当作应用程序的使用空间
//ptmalloc源码中定义结构体malloc_chunk来描述这些块
struct malloc_chunk
{
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};使用中的chunk
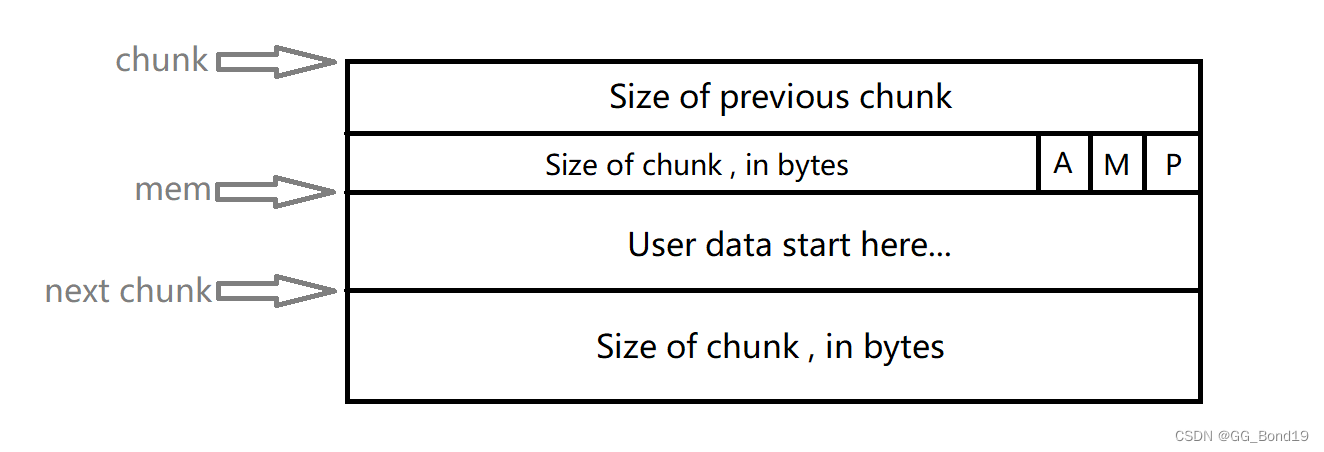
- chunk指针指向chunk开始的地址;mem指针指向用户内存块开始的地址
- P=0时,表示前一个chunk为空闲,prev_size才有效
- P=1时,表示前一个chunk正在被使用,prev_size无效。p主要用于内存块的合并操作。ptmalloc分配的第一个块总是将p设为1,以防程序引用到不存在的区域
- M=1为mmap映射区域分配;M=0为heap区域分配
- A=0为主分配区分配;A=1为非主分配区分配
空闲的chunk
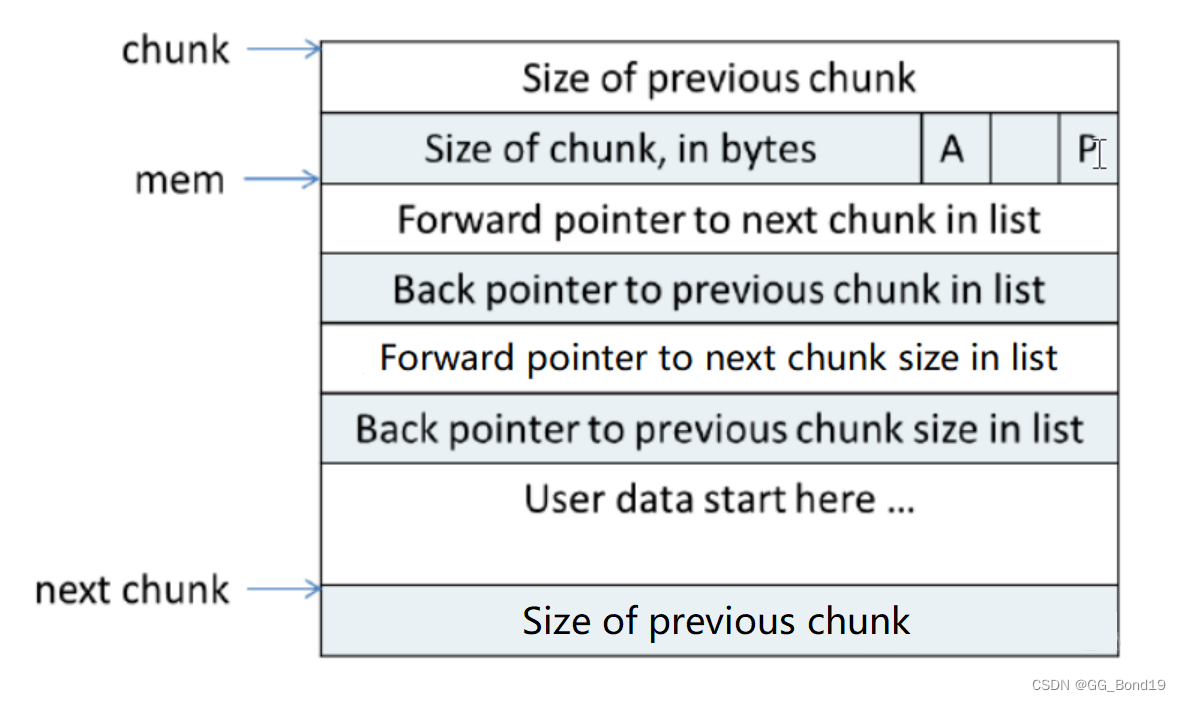
chunk空闲时,M状态不存在,只有AP状态。因为M表示是由brk还是mmap分配的内存,而mmap分配的内存free时直接munmap,不会放到空闲链表。原本是用户数据区的地方存储了四个指针。指针fd指向后一个空闲chunk,而bk指向前一个空闲的chunk,malloc通过这两个指针将大小相近的chunk连成一个双向链表
chunk中的空间复用
- 为了使chunk占用的空间最小,ptmalloc采用了空间复用。一个chunk在不同状态下,某些区域表现出来不同的意义,以此达到复用
- 空闲时,一个chunk至少需要 2个size_t和2个指针 大小的空间,用来存储prev_size、size、fd和bk,即16bytes
- 当一个chunk处于使用状态时,其下一个chunk的prev_size域肯定是无效的,所以这个空间也可以被当前chunk使用
所以,一个使用中的chunk的大小的计算公式为:in_use_size = (用户请求 + 8 - 4)
加8bytes是为了存储prev_size和size,但又因为向下一个chunk借了4bytes,所以减去4。因为空闲的chunk和使用中的chunk使用的是同一块空间,所以要取最大值作为实际的分配空间,即最终的分配空间为chunk_size = max(in_use_size,16)
特殊chunk
top chunk
- top chunk相当于分配区的顶部空闲内存,当bins都不能满足内存分配要求时,就会来top chunk上分配
- 当top chunk大小比用户所请求大小还大时,top chunk会分为两个部分,user chunk和remainder chunk(剩余大小)。其中remainder chunk成为新的top chunk
- 当top chunk大小小于用户所请求的大小时,top chunk就通过sbrk(main arena)或mmap(thread arena)系统调用来扩容
- 当分配的内存非常大(大于分配阈值,默认128k)时,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存时会直接交还给操作系统(chunk中M标志位为1)
- last remainder chunk是一种特殊的chunk,就像top chunk和mmaped chunk一样,不会在任何bins中找到这种chunk,当需要分配一个small chunk,但在small bins中找不到合适的chunk。若last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk
2.1.3 空闲链表bins
当用户free内存,ptmalloc并不会马上将内存交还给操作系统,而是被ptmalloc的空闲链表bins管理起来,当下次进程需要malloc内存时,ptmalloc就会从空闲的bins上寻找一块合适的内存块分配给用户使用,避免频繁的系统调用,降低内存分配的开销
ptmalloc将相似大小的chunk用双向链表连接起来,这样一个链表被称为一个bin,ptmalloc共维护了128个bin,每个bin都维护了大小相近的双向链表的chunk。基于chunk的大小,有下列几种可用bins:
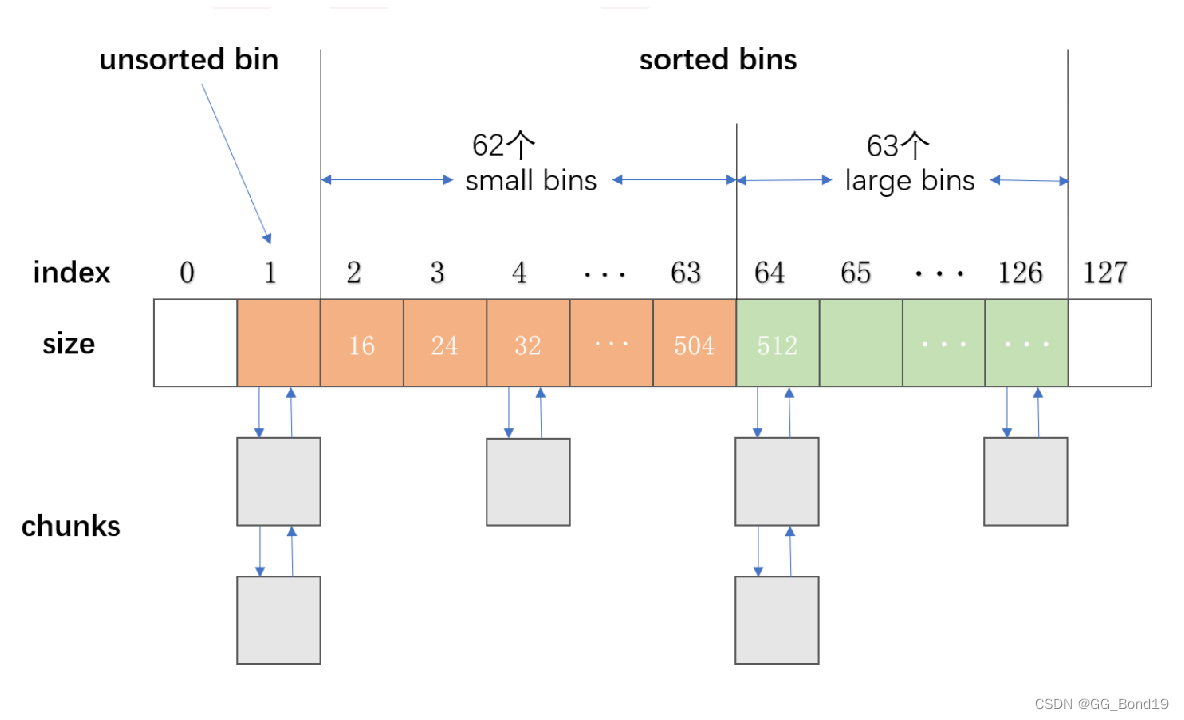
注意:32位平台下,bin[0]与bin[127]不存在。bin[1]为unsorted bins,bin[2]~bin[126]为sorted bins
unsorted bin
- unsorted bins的队列位于bins数组的第2个(下标为1),是bins的一个缓冲区,加快分配的速度
- 当用户释放的内存大于max_fast或者fast bins合并后的chunk都会首先进入unsorted bins,chunk大小无限制,任何大小chunk都可以进入。这种途径给予ptmalloc第二次机会重新使用最近free的chunk,寻找合适的bin的时间开销就省略了,因此分配和释放更快
- 用户malloc时,若fast bins没有找到合适的chunks,则malloc会先在unsorted bin中查找合适的空闲chunk。若没有合适的bin,ptmalloc会将unsorted bin上的chunk放入bins上,然后在bins上查找合适的空闲chunk
small bins
- 小于512bytes的chunk被称为small chunk,而保存small chunk的bin被称为small bin。下标从2开始,到63结束,共62个。small bin每个bin之间相差8 bytes,同一个small bin的chunk具有相同大小
- 每个small bin都包括一个空闲区块的双向循环链表,free掉的chunk添加在链表的前端,而所需chunk则从链表后端摘除
- 两个相连的空闲chunk会被合并成一个空闲chunk,合并消除了碎片化的影响但是减慢了free的速度
- 分配时,当small bin非空,相应的bin会摘除binlist中最后一个chunk并返回用户。在free一个chunk时,检查其前或其后的chunk是否空闲,若是则合并,即将chunk从所属的链表中摘除合并成一个新的chunk,新的chunk会添加在unsorted bin链表前端
large bins
- 大于512bytes的chunk被称为large chunk,而保存为large chunk的bin被称为large bin,位于small bins后面。下标从64开始,到126结束,共63个。large bins中的每个bin分别包含了一个给定范围内的chunk,其中的chunk按大小递减排序,大小相同则按照最近使用时间排列
- 两个相邻的空闲chunk会被合并成一个空闲chunk
- 分配时,遵循"smallest-first,best-fit",从顶部遍历到底部以找到一个大小最接近用户需求的chunk。一旦找到,相应chunk就会分成两块,user chunk(用户请求大小)返回给用户,remainder chunk剩余部分添加到unsorted bin
- free和small bin类似
fast bins
程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的chunk后,也许马上就会有另一个小块内存的请求,分配器又需从大的空闲内存中切分出一块,较为低效,故引入fast bins
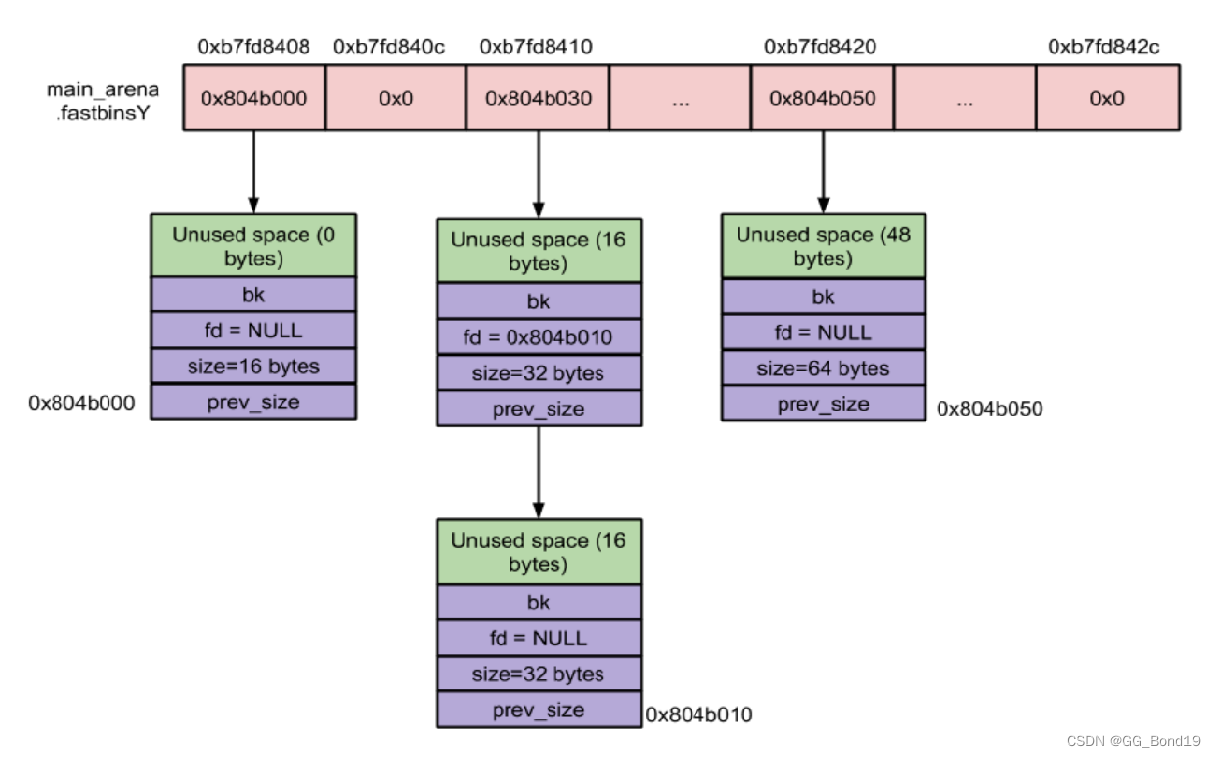
- fast bins是bins的高速缓冲区,大约有10个定长队列(bin)。每个fast bin都记录着一条free chunk的单链表(binlist,采用单链表是因为fast bin中链表的chunk不会被摘除的特点),增删chunk都发生在链表的前端
- 当用户释放一块不大于max_fast(默认值为64bytes)的chunk时,会默认放到fast bins上。当需要给用户分配的chunk小于等于max_fast时,malloc首先会到fast bins上寻找是否有合适的chunk。一定大小内的chunk无论是分配还是释放,都会在fast bins中过一遍。
- 分配时,binlist中被检索的第一个chunk将被摘除并返回给用户,free掉的chunk将被添加在索引到的binlist前端
2.1.4 初始化
- 在堆区中,start_brk指向heap的开始,而brk指向heap顶部。可以使用brk() & sbrk()来增加分配给用户的heap空间。在使用malloc前,brk的值等于start_brk,即heap大小=0
- ptmalloc在开始时,若请求的空间小于mmap分配阈值(默认为128KB)时,主分配区会调用sbrk()增加一块大小为(128KB + chunk_size)的空间作为heap,非主分配区会调用mmap映射一块大小为HEAP_MAX_SIZE(32位系统默认为1MB,64位系统默认为64MB)的空间作为sub-heap
- 当用户请求内存分配时,首先会在这个区域找一块合适的chunk给用户,当用户释放了heap中的chunk时,ptmalloc又会使用fast bins和bins来组织空闲chunk
- 若需要分配的chunk大小小于mmap分配阈值,而heap空间又不够,则此时主分配区会通过sbrk()调用来增加heap大小,非主分配区会调用mmap映射一块新的sub-heap,即增加top chunk的大小,每次heap增加的值都会对齐到4KB
- 当用户的请求超过mmap分配阈值,并且主分配区使用sbrk()分配失败的时候,或是非主分配区在top chunk中不能分配到需要的内存时,ptmalloc会尝试使用mmap()直接映射一块内存到进程内存空间。使用mmap()直接映射的chunk在释放时直接结束映射,不再属于进程的内存空间。任何对该内存的访问都会产生段错误。而在heap中或是sub-heap中分配的空间则可能会留在进程内存空间内,还可再次引用
2.2 内存分配与释放
内存分配malloc流程
1、获取分配区的锁,防止多线程冲突(每个进程有一个malloc管理器,而一个进程中的多个线程共享这一个管理器,有竞争)
2、计算出需要分配的内存的chunk实际大小
3、若chunk 的大小 < max_fast(64bytes),在fast bins上查找适合的chunk;若不存在,转到 5
4、若chunk 大小 < 512bytes,从small bins上去查找chunk,若存在,分配结束
5、需要分配的是一块大的内存,或者 small bins 中找不到 chunk:
- a. 遍历fast bins,合并相邻的chunk,并链接到unsorted bin中
- b. 遍历unsorted bin中的chunk:
- ①能够切割chunk直接分配,分配结束
- ②根据chunk的空间大小将其放入small bins或是large bins中,遍历完成后,转到6
6、需要分配的是一块大的内存,或者small bins和unsorted bin中都找不到合适的 chunk,且fast bins和unsorted bin中所有的chunk已清除:
- 从large bins中查找,遍历链表,直到找到第一个大小大于待分配的chunk进行切割,余下放入unsorted bin,分配结束
7、检索fast bins和 bins都没有找到合适的chunk,判断top chunk大小是否满足所需chunk的大小,从top chunk中分配
8、top chunk不能满足需求,需扩大 top chunk:
- 当top chunk大小大于用户请求时,top chunk会分为两部分:User chunk和remainder chunk,其中remainder chunk成为新的top chunk
- 当top chunk大小小于用户请求时,top chunk就通过sbrk()或者mmap()系统调用来扩容
- top chunk也不能满足分配要求时,若是主分配区,调用sbrk()增加top chunk大小;若是非主分配区,调用mmap来分配一个新的sub-heap,增加top chunk大小;或者使用mmap()来直接分配:
- 若所需分配的chunk大于等于mmap分配阈值,使用mmap系统调用为程序的内存空间映射一块chunk_size align 4KB大小的空间。然后将内存指针返回给用户
- 若所需分配的chunk小于等于mmap分配阈值,判断是否为第一次调用malloc,若是主分配区,则需要进行一次初始化工作,分配一块大小为(chunk_size + 128KB) align 4KB 大小的空间作为初始的heap。若已经初始化过了,主分配区则调用sbrk()增加heap空间,非主分配区则在top chunk中切割出一个chunk,使之满足分配需求,并将内存指针返回给用户
内存释放 free 流程
1、获取分配区的锁
2、若free 的是空指针,返回
3、若当前chunk是mmap映射区域映射的内存,调用munmap () 释放内存
4、若chunk与top chunk相邻,直接与top chunk合并,转到 8
5、若chunk 的大小 > max_fast,放入unsorted bin,并且检查是否有合并:
- a. 没有合并情况则free
- b. 有合并情况并且和top chunk相邻,转到 8
6、若chunk 的大小 < max_fast,放入fast bin,并且检查是否有合并:
- a.fast bin并没有改变chunk的状态,没有合并情况则free
- b. 有合并情况,转到 7
7、在fast bins,若相邻chunk空闲,则将这两个chunk合并,放入unsorted bin。若合并后的大小 > 64KB,会触发进行fast bins的合并操作,fast bins中的chunk将被遍历合并,合并后的chunk会被放到unsorted bin中。合并后的chunk和top chunk相邻,则会合并到top chunk中,转到8
8、若top chunk的大小 > mmap收缩阈值(默认为 128KB),对于主分配区,会试图归还top chunk中的一部分给操作系统
2.3 使用注意
为了避免Glibc内存暴增,需要注意:
- 后分配的内存先释放,因为ptmalloc收缩内存是从top chunk开始,若与top chunk相邻的chunk不能释放,top chunk以下的chunk都无法释放
- ptmalloc不适合用于管理长生命周期的内存,特别是持续不定期分配和释放长生命周期的内存,这将导致ptmalloc内存暴增
- 多线程分阶段执行的程序不适合用ptmalloc,这种程序的内存更适合用内存池管理
- 尽量减少程序的线程数量和避免频繁分配、释放内存。频繁分配,会导致锁的竞争,最终导致非主分配区增加,内存碎片增高,且性能降低
- 防止内存泄露,ptmalloc对内存泄露是相当敏感的,根据其内存收缩机制,若与top chunk相邻的那个chunk没有回收,将导致top chunk一下很多的空闲内存都无法返回给操作系统
- 防止程序分配过多内存,或是由于Glibc内存暴增,导致系统内存耗尽,程序因OOM被系统杀掉。预估程序可以使用的最大物理内存大小,配置系统的/proc/sys/vm/overcommit_memory,/proc/sys/vm/overcommit_ratio,以及使用ulimt –v限制程序能使用虚拟内存空间大小,防止程序因OOM被杀掉
三、ptmalloc、tcmalloc与jemalloc实现机制对比分析
ptmalloc(glibc malloc):
- ptmalloc是GNU C库(glibc)中的默认内存分配器,广泛用于Linux系统
- 基于Doug Lea的malloc实现,采用了多种技术,如自由链表、分离器和堆的延迟绑定等
- ptmalloc的特点是成熟、稳定,并且与GNU C库紧密集成
tcmalloc(Google malloc):
- tcmalloc是Google开发的内存分配器,主要用于Google的C++代码
- tcmalloc通过减少锁的竞争和减少内存碎片来提高性能
- 使用线程本地缓存(Thread-Caching Malloc)的概念,将内存分配的任务分散到不同的线程中,以减少对共享数据结构的竞争
- tcmalloc还有其他一些优化策略,如小对象合并、高效的分配器缓存等
jemalloc:
- jemalloc是一款通用的内存分配器,由FreeBSD社区开发,并逐渐被其他系统广泛采用
- jemalloc致力于提供高度可扩展性和低碎片化的内存分配
- 使用了多个技术,如分离的内存区域、伙伴分配器、线程本地缓存等
- jemalloc还提供了高级特性,如背景线程执行释放、空间利用统计和分析等
性能对比:
- ptmalloc在大多数情况下性能良好,但在多线程环境下可能存在一些竞争问题
- tcmalloc通过线程本地缓存和减少锁竞争,适用于高并发场景,尤其是多线程服务器应用
- jemalloc在可扩展性和碎片化方面表现出色,特别适用于大型内存分配和高负载场景
总结:
- ptmalloc适用于常规应用,与GNU C库集成紧密
- tcmalloc适用于高并发多线程环境,通过线程本地缓存减少竞争
- jemalloc适用于可扩展性和低碎片化要求高的场景,提供高级特性和统计信息


![[Java]重写equals为什么要重写hashcode???配合HashMap源码一起理解](https://img-blog.csdnimg.cn/42c749145e29456a8bdca0a824cb01ea.png)