事务的实现
- 简介
- 特性(ACID)
- 状态与分类
- 实现机制
- 日志机制
- redo log
- undo log
- 锁机制
- 如何使用
简介
有许多小伙伴初学事务还不太清楚是干什么的,那么我们在简介中一次性将事务给搞懂
首先我们先来简单的说一下事务是什么,以便更好的去了解它用通俗的概念来讲:事务就是一组最小的执行逻辑单元,可以使数据从一种状态转到另一种状态。
根据上面的概念,我们就可以推断出它是操作的数据,并且这组数据的状态只能有两种状态,那么就是要么操作成功,要么操作失败。那么我们就可以总结出如下四个特性
特性(ACID)
-
原子性(atomicity)
这组操作不能被分割,因为已经是最小执行单元了。 -
一致性(consistency)
事务执行前后,数据从一个合法状态转化为另外一个合法状态。 -
隔离性(isolation)
既然上面所说它是一个单元,那么这个事务在执行的时候就不会被其他的干扰到。 -
持久性(durability)
操作数据之后,那么这个操作完成之后就会被保存,在这里我们用提交来说明这个操作一旦提交之后,就会被保存起来。
状态与分类
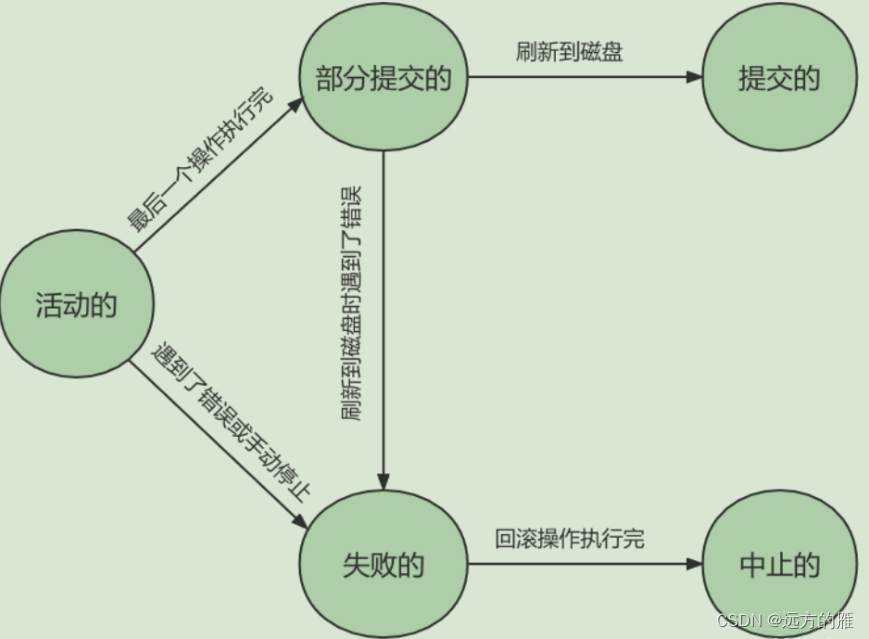
上面在讲到它的特性时候我们提了一下它的状态只有固定的几种,那么下面展开讲讲它的几种状态。
-
活动
活动也就是我们开始事务前的准备工作,这个时候我们将已经准备好的数据或操作要进行一个持久化操作。 -
部分提交的
在我们的事务中可能会包含许多的逻辑,那么这些逻辑如果全部执行完成我们就将这些状态称为部分提交的,但是到这里还是不算完成。 -
提交的
最后将上面完成的数据都保存到磁盘中,也就完成了我们的最后要的操作,这里我们就提交事务,标志着一个事务的完成。 -
失败的
当我们在提交的过程中遇到了什么问题,或者在最后要完成持久化操作中遇到了问题,那么就会来到失败的操作。 -
终止的
如果到这里,那么这个操作算是没有完成的,我们就需要将它进行恢复到原来的状态,这个操作我们称为回滚,然后就到了这个中止状态。
实现机制
上面我们看了,有那么多状态,进行这些操作的一般都是要对后台或者数据库进行操作(这里通常只有Mysql的Innodb才会去支持),那么需要实现上面的这些内容我们就需要一套较复杂的机制来操作。
日志机制
日志在这当中就启到了非常重要的作用:redo log与undo log,本篇博客我就不展开细讲这两种的具体实现,只做一个简单的概述。
redo log
首先在我们保存的Mysql数据库,它是由许多数据页来保存的,而每个数据页的大小有16kb,如果我们每一次都去操作数据页,那么就会照成频繁I/O这样对性能的损耗较大。那么这个时候redolog就登场了,我们每一次操作,就会被记录在redolog当中,这样即不会去担心宕机之后数据会丢失,也不会因为频繁的去操作数据页而照成性能阻塞。
这里可能会有小伙伴有疑问了,那么我们频繁的去写入日志,不也会照成性能的下降嘛,那么这里同样的也会在写入日志的时候加入一层redo log buffer,当达到一定的条件的时候,我们就会将日志在保存,这里俗称刷盘。那么这里的刷盘策略是可以设置的
innodb_flush_log_at_trx_commit
- = 0
事务提交的时候,不会被刷盘,而是每隔1s自动同步日志- = 1
每次提交事务就会刷盘(这个也是Innodb默认设置的)- = 2
表示将内容写入到日志中也就是redo.file
当然实际情况也挺复杂的,并且都是独立的线程,尽可能的减少对性能的影响
undo log
这个日志的出现主要就是为了解决上面状态出现需要回滚的时候该如何去处理的。
当我们去对这条记录进行改动的时候,undolog就会将这条插入的语句给保存起来,然后当需要回滚的时候,在执行上面的这些操作。
改动的内容一般有:语句的主键、插入、修改、删除
锁机制
那么这里的锁就很好理解了,就是将为了保证事务的原子性,在进行这个操作的时候,这个线程会被占用,而针对不同的业务需求又有不同需要,比如我们常说的应对脏读、幻读、不可重复读等。对此也设置了相应的隔离级别。
如何使用
那么上面我们说了这么多,为什么要使用事务呢,他能为我们提供什么价值?
- 首先最简单的就是它为数据提供了安全的操作,避免在多线程环境下的数据并发问题
- 而在我们java开发中,会有使用到@Transactional注解,可以让我们更好的使用