追梦之旅【数据结构篇】——C语言手撕八大经典排序😎
- 前言🙌
- 排序的认识
- 排序的稳定性:
- 排序的时间复杂度和空间复杂度以及如何选择适合的排序:
- 优化版选择排序
- 冒泡排序
- 普通版冒泡排序
- 升级版冒泡排序
- 直接插入排序
- 希尔排序
- 堆排序
- 快速排序
- 快速排序递归版(进行过三数取中优化+小区间优化)
- 快速排序递归版1——hoare
- 快速排序递归版2——挖坑法
- 快速排序递归版3——前后指针法
- 快速排序非递归1
- 快速排序非递归2
- 栈实现的头文件.h
- 栈实现的功能文件.c
- 归并排序
- 归并排序递归版
- 归并排序递归版1(进行过小区间优化)
- 归并排序非递归版
- 归并排序非递归版1(部分归并思路实现)
- 归并排序非递归版2(整体归并思路实现)
- 总结撒花

😎博客昵称:博客小梦
😊最喜欢的座右铭:全神贯注的上吧!!!
😊作者简介:一名热爱C/C++,算法等技术、喜爱运动、热爱K歌、敢于追梦的小博主!
😘博主小留言:哈喽!😄各位CSDN的uu们,我是你的博客好友小梦,希望我的文章可以给您带来一定的帮助,话不多说,文章推上!欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘

前言🙌
哈喽各位友友们😊,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!😘我仅已此文,手把手带领大家使用C语言手撕八大经典排序~ 都是精华内容,可不要错过哟!!!😍😍😍
排序的认识
排序分为内排序和外排序,这是根据数据在什么位置上进行排序而决定的。在内存中,对数据进行排序称为内排序;在外存中,对数据进行排序称为外排序。
经典的排序有以下几种:
- 直接插入排序(InsertSort)
- 希尔排序(ShellSort)
- 冒泡排序(BubbleSort)
- 堆排序(HeapSort)
- 选择排序(SelectSort)
- 快速排序(QuickSort)
- 归并排序(MergeSort)
- 计数排序(CountSort)
排序的稳定性:
其中,归并排序的身份比较特殊,它既可以做内排序,也可以做外排序。其余排序都是属于内排序的。
- 稳定的排序:直接插入排序,冒泡排序,堆排序,选择排序,快速排序,
- 不稳定的排序:希尔排序,归并排序,计数排序
排序的时间复杂度和空间复杂度以及如何选择适合的排序:
- 直接插入排序(InsertSort):时间复杂度:**O(n2),**空间复杂度:O(1)。但是,是n2 级别排序中可以说最好的排序。特别是当数据比较有序或者有序时,最好选择插入排序。但是如果数据一开始是逆序的,那就是最坏的情况。
- 希尔排序(ShellSort):这个排序的时间复杂度比较难计算,大约为O(N^1.3)。 时间复杂度O(1) 。其是在直接排序上的一个改良版解决了数据比较随机时,插入排序比较慢的缺点。
- 冒泡排序(BubbleSort):时间复杂度:O(N^2),空间复杂度:O(1) 。是比较经典的算法,适合小白入门学习的第一种算法。本篇文章对此进行一个优化,当数据本身就是有序的情况下,可将时间复杂度优化为O(n)。
- 堆排序(HeapSort): 时间复杂度:O(N*logn),空间复杂度:O(1) 。适合大数据量的排序,一般可以用来解决TopK的问题。
- 选择排序(SelectSort):时间复杂度:O(N^2),空间复杂度:O(1) 。是比较差的排序,比冒泡还差。这里是对选择排序进行了优化,一般情况下,整体测试性能变得和冒泡差不多了,甚至好一点。
- 快速排序(QuickSort):时间复杂度:O(N*logn),空间复杂度:O(logn) 。几乎什么情况都是可以使用快速排序。但是还是有一些特殊情况不适合。例如,最左边的值为最或者最大值,导致一开始选定的keyi为最值。从而恶化为O(n^2)的时间复杂度,也会有溢出的风险。还有就是全为相同数据的情况或者其他一些专门针对快排设计的数据,都会导致快排变“慢排”。这里进行了**三数取中,小区间优化,三路规划,随机数mid ,**解决了目前针对快排的绝大多数问题。
- 归并排序(MergeSort):时间复杂度:O(N*logn),空间复杂度:O(n) 。它是完全的二分分割思维,从理论上来,比快排还要快一点。但是由于需要拷贝,拷贝也会消耗性能的,因此其和快排差不多。归并排序还可以应用于外存上的排序场景,这是相对其他排序的一个优势。
- 计数排序(CountSort):时间复杂度:O(N),空间复杂度:O(max - min + 1 ) 。其性能的好坏取决这一组数据中大小的范围max - min 。在对一组大小比较集中的数据进行排序时,计数排序是一个非常好的选择。
优化版选择排序
传统的选择排序时,一次选定最小的值放到最左边,以此类推。这里优化的思路是:一次选定最小值和最大值,分别放到最左边和最右边。
//选择排序
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int maxi = left;
int mini = left;
//找出最大和最小的两个数的位置
for (int i = left; i <= right; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[left]);
if (maxi == left)
{
maxi = mini;
}
Swap(&a[maxi], &a[right]);
left++;
right--;
}
}
冒泡排序
普通版冒泡排序
// 普通版冒泡排序
void BubbleSort(int* a, int len)
{
for (int i = 0; i < len; i++)
{
for (int j = 0; j < len - i - 1; j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
}
}
}
}
升级版冒泡排序
这里是对冒泡排序最好的情况下进行一个优化,当遍历一遍数组发现是有序的,则直接跳出循环不在交换数据。这样可以将冒泡最好的情况下,优化为O(n)。
// 升级版冒泡排序
void BubbleSort(int* a, int len)
{
for (int i = 0; i < len; i++)
{
int flag = 1;
for (int j = 0; j < len - i - 1; j++)
{
if (a[j] > a[j + 1])
{
flag = 0;
Swap(&a[j], &a[j + 1]);
}
}
if (flag == 0)
break;
}
}
直接插入排序
直接插入排序的实现思路可以简单的理解为我们打扑克牌时,进行将牌从小到大排序的情况。每次取一个数,和前面的数比较,并将该数插入到合适的位置。这样可以保证,每一次取一个数据时,前面的数都是有效的。
//直接插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tem = a[end + 1];
while (end >= 0)
{
if (tem < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tem;
}
}
希尔排序
希尔排序主要是基于插入排序的思想,不同点是希尔排序其利用分组的思想。先进行预排序,将数据变得比较有序,再进行插入排序的方式。
//希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tem = a[end + gap];
while (end >= 0)
{
if (tem < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tem;
}
}
}
堆排序
堆排序是一个比较抽象的排序。逻辑上我们控制的是一个完全二叉树,物理上我们控制的是一个数组。这里采用向下调整算法。
运用的知识点和技巧:
- 排升序——建大堆
- 排降序——建小堆
- 左孩子 :child = parent * 2 + 1
- 右孩子:child = parent * 2 + 2。
- parent = (child - 1) / 2
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
//选出最大的孩子
while (child < n)
{
if (child + 1 < n && a[child + 1] > a[child])
{
child++;
}
//最大的孩子和父亲比
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* a, int n)
{
//建堆--升序建大堆
//向下调整建堆 --时间复杂度:O(n)
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
快速排序
快速排序递归版(进行过三数取中优化+小区间优化)
三数取中,解决的是取得keyi是最值的问题。小区间优化,是为了减少递归调用次数。
快速排序递归版1——hoare
注意点:
- 左边选keyi,右边先走;右边选keyi,左边先走
- 右边选比 a[keyi]小的值,左边先比 a[keyi] 大的值
- 注意特殊情况对边界的处理。
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{
int keyi = left;
int mid = GetMidnum(a, left, right);
Swap(&a[mid], &a[keyi]);
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
}
快速排序递归版2——挖坑法
这个和hoare版本差不多,只是在理解的思维上有所不同。挖坑法的思路是比较好理解的。不同区哪个先走的问题。
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{
int mid = GetMidnum(a, left, right);
Swap(&a[mid], &a[left]);
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[left] = key;
return left;
}
快速排序递归版3——前后指针法
这个版本是我比较推荐的快速排序的实现方法。主要是因为其编写代码的坑相对于上面两种比较少。而且整体代码比较简短。
// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = prev + 1;
int mid = GetMidnum(a, left, right);
Swap(&a[mid], &a[left]);
while (cur <= right)
{
if (a[cur] < a[keyi] && prev++ != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return prev;
}
上述三个版本,在性能上没有什么差别,只是在思维的理解上,挖坑法比较好理解。而前后指针法比较好写代码。
快速排序非递归1
快速排序的非递归实现,需要利用数据结构栈。解决的是,递归版本下,栈溢出的情况。
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
{
ST st;
STInit(&st);
if (left < right)
{
STPush(&st, right);
STPush(&st, left);
}
while (!STEmpty(&st))
{
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
int keyi = PartSort3(a, begin, end);
//[begin,keyi - 1] keyi [ keyi + 1, end]
if (keyi + 1 < end)
{
STPush(&st, end);
STPush(&st, keyi + 1);
}
if (begin < keyi - 1)
{
STPush(&st, keyi - 1);
STPush(&st, begin);
}
}
STDestroy(&st);
}
快速排序非递归2
栈实现的头文件.h
#pragma once
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* pst);
void STDestroy(ST* pst);
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);
STDataType STTop(ST* pst);
bool STEmpty(ST* pst);
int STSize(ST* pst);
栈实现的功能文件.c
#include "Stack.h"
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL;
//pst->top = -1; // top 指向栈顶数据
pst->top = 0; // top 指向栈顶数据的下一个位置
pst->capacity = 0;
}
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}
void STPush(ST* pst, STDataType x)
{
if (pst->top == pst->capacity)
{
int newCapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* tmp = (STDataType*)realloc(pst->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->a = tmp;
pst->capacity = newCapacity;
}
pst->a[pst->top] = x;
pst->top++;
}
void STPop(ST* pst)
{
assert(pst);
assert(!STEmpty(pst));
pst->top--;
}
STDataType STTop(ST* pst)
{
assert(pst);
assert(!STEmpty(pst));
return pst->a[pst->top - 1];
}
bool STEmpty(ST* pst)
{
assert(pst);
/*if (pst->top == 0)
{
return true;
}
else
{
return false;
}*/
return pst->top == 0;
}
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}
归并排序
归并排序递归版
归并排序递归版1(进行过小区间优化)
归并排序是一个使用二分来划分区间,然后进行归并的排序。主要还是要注意区间的划分。
void _MergeSort(int* a, int begin, int end, int* tem)
{
// 递归结束的条件
if (begin == end)
return;
//小区间优化
if ((begin - end) < 10)
{
InsertSort(a, begin - end + 1);
}
int mid = (begin + end) / 2;
//[left , mid] [ mid + 1, right]
_MergeSort(a, begin, mid, tem);
_MergeSort(a, mid + 1, end, tem);
//归并数据
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tem[i++] = a[begin1++];
}
else
{
tem[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tem[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tem[i++] = a[begin2++];
}
memmove(a + begin, tem + begin, sizeof(int) * (end2 - begin + 1));
}
//归并排序 -- 递归版
void MergeSort(int* a, int n)
{
int* tem = (int*)malloc(sizeof(int) * n);
_MergeSort(a, 0, n - 1,tem);
free(tem);
}
归并排序非递归版
归并排序非递归版1(部分归并思路实现)
非递归版本的归并排序,最主要的是要处理好区间边界的问题和修正,防止越界。以及拷贝数据时,区间的边界把控问题。
//归并排序 -- 非递归版1
void MergeSortNonR(int* a, int n)
{
int* tem = (int*)malloc(sizeof(int) * n);
int begin = 0;
int end = n - 1;
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//printf("修正前:[ %d , %d ] [ %d , %d ]\n",begin1,end1,begin2,end2);
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
//printf("修正后:[ %d , %d ] [ %d , %d ]\n", begin1, end1, begin2, end2);
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tem[j++] = a[begin1++];
}
else
{
tem[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tem[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tem[j++] = a[begin2++];
}
memmove(a + i, tem + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
}
归并排序非递归版2(整体归并思路实现)
//归并排序 -- 非递归版2
void MergeSortNonR2(int* a, int n)
{
int* tem = (int*)malloc(sizeof(int) * n);
int begin = 0;
int end = n - 1;
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//printf("修正前:[ %d , %d ] [ %d , %d ]\n",begin1,end1,begin2,end2);
if (end1 >= n)
{
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if(begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
else if(end2 >= n)
{
end2 = n - 1;
}
//printf("修正后:[ %d , %d ] [ %d , %d ]\n", begin1, end1, begin2, end2);
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tem[j++] = a[begin1++];
}
else
{
tem[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tem[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tem[j++] = a[begin2++];
}
}
memmove(a, tem, sizeof(int) * n);
gap *= 2;
}
}
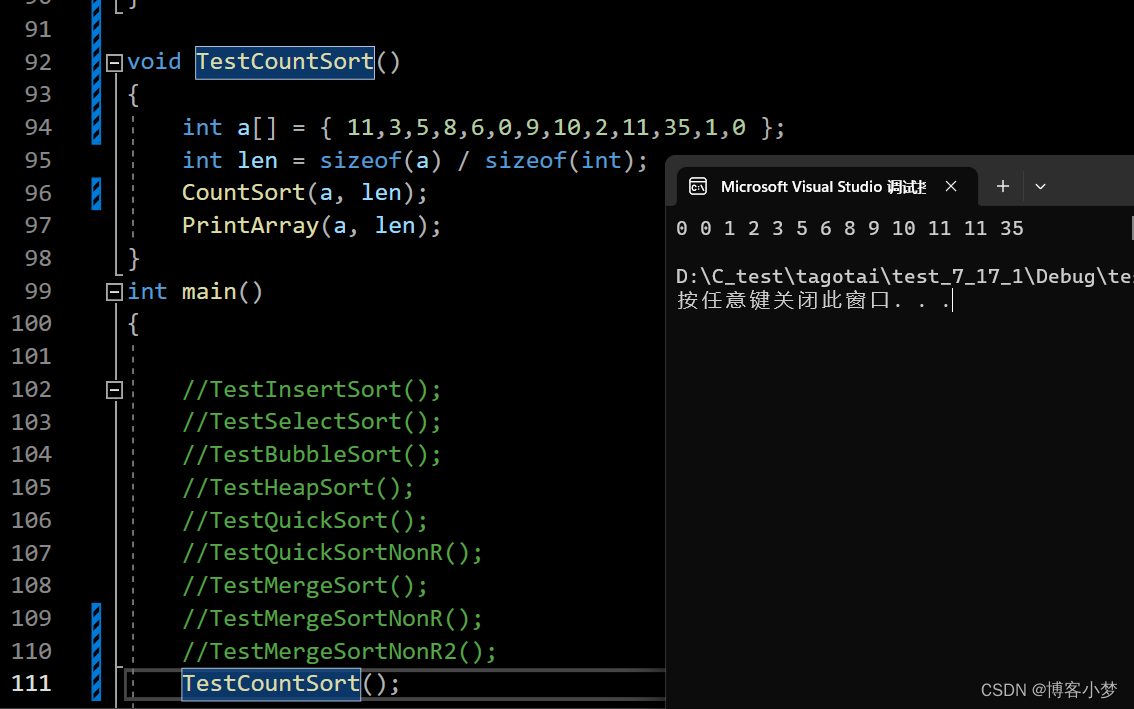
对于上述的排序,我都进行了一个验证,结果都是正确的。
总结撒花
本篇文章旨在分享的是C语言手撕八大经典排序。希望大家通过阅读此文有所收获!
😘如果我写的有什么不好之处,请在文章下方给出你宝贵的意见😊。如果觉得我写的好的话请点个赞赞和关注哦~😘😘😘