文章目录
- DOM4j
- XML 解析技术原理
- XML 解析技术介绍
- DOM4J 介绍
- DOM4j 中,获得 Document 对象的方式有三种
- 源码
- 增删改查代码
DOM4j
文档: https://dom4j.github.io/javadoc/1.6.1/
本地文档: dom4j-1.6.1\docs\index.html
XML 解析技术原理
- 不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的dom 技术来解析
- document 对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)
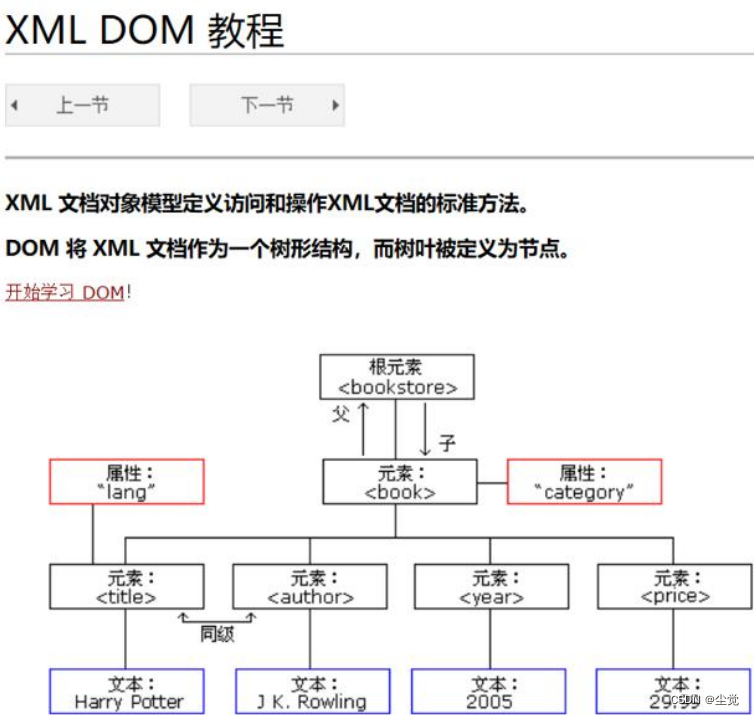
XML 解析技术介绍
● 早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 Sax 简介
- dom 解析技术是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。 Java 对 dom 技术解析也做了实现
- sun 公司在 JDK5 版本对 dom 解析技术进行升级:SAX( Simple API forXML)SAX解析,它是以类似事件机制通过回调告诉用户当前正在解析的内容。 是一行一行的读取 xml 文件进行解析的不会创建大量的 dom 对象。 所以它在解析 xml 的时候,在性能上优于 Dom 解析
- 这两种技术已经过时,知道有这两种技术即可
● 第三方的 XML 解析技术
- jdom 在 dom 基础上进行了封装
- dom4j 又对 jdom 进行了封装。
- pull 主要用在 Android 手机开发,是在跟 sax 非常类似都是事件机制解析 xml 文件
DOM4J 介绍
- Dom4j 是一个简单、灵活的开放源代码的库(用于解析/处理 XML 文件)。Dom4j 是由早期开发JDOM 的人分离出来而后独立开发的。
- 与 JDOM 不同的是,dom4j 使用接口和抽象基类,虽然 Dom4j 的 API 相对要复杂一些,但它提供了比 JDOM 更好的灵活性。
- Dom4j 是一个非常优秀的 Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的 Dom4j。
DOM4j 中,获得 Document 对象的方式有三种
● 开发 dom4j 要导入 dom4j 的包
1、读取 XML 文件,获得 document 对象
SAXReader reader = new SAXReader(); //创建一个解析器
Document document = reader.read(new File(“src/input.xml”));//XML Document
2、解析 XML 形式的文本,得到 document 对象
String text = “”;
Document document = DocumentHelper.parseText(text);
3.主动创建 document 对象.
Document document = DocumentHelper.createDocument(); //创建根节点
Element root = document.addElement(“members”);
DOM4j 应用实列
源码
增删改查代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.jupiter.api.Test;
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
public class Dom4j_ {
指定读取第一个学生的信息 就是 dom4j+xpath
@Test
public void readOne() throws DocumentException {
//得到一个解析器
SAXReader reader = new SAXReader();
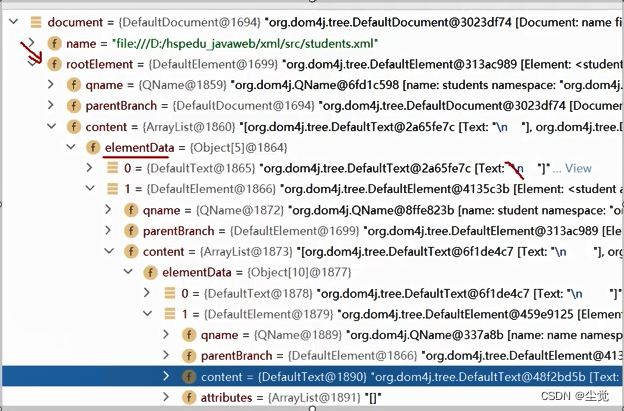
//代码技巧->debug 看看 document 对象的属性
//分析了 document 对象的底层结构
Document document = reader.read(new File("src/students.xml"));
//1. 得到 rootElement, 你是 OOP
Element rootElement = document.getRootElement();
//2. 获取第一个学生
Element student = (Element) rootElement.elements("student").get(1);
//3. 输出该信息
System.out.println("该学生的信息= " + student.element("name").getText() + " " +
student.element("age").getText() + " " +
student.element("resume").getText() +
student.element("gender").getText());
//4. 获取 student 元素的属性
System.out.println("id= " + student.attributeValue("id"));
}
加元素(要求: 添加一个学生到 xml 中) [不要求,使用少,了解]
@Test
public void add() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个 xml 文件
Document document = saxReader.read(new File("src/students.xml"));
//首先我们来创建一个学生节点对象
Element newStu = DocumentHelper.createElement("student");
Element newStu_name = DocumentHelper.createElement("name");
//如何给元素添加属性
newStu.addAttribute("id", "04");
newStu_name.setText("宋江");
//创建 age 元素
Element newStu_age = DocumentHelper.createElement("age");
newStu_age.setText("23");
//创建 resume 元素
Element newStu_intro = DocumentHelper.createElement("resume");
newStu_intro.setText("梁山老大");
//把三个子元素(节点)加到 newStu 下
newStu.add(newStu_name);
newStu.add(newStu_age);
newStu.add(newStu_intro);
//再把 newStu 节点加到根元素
document.getRootElement().add(newStu);
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
output.setEncoding("utf-8");//输出的编码 utf-8
//把我们的 xml 文件更新
// lets write to a file
//new FileOutputStream(new File("src/myClass.xml"))
//使用到 io 编程 FileOutputStream 就是文件字节输出流
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
}
- //删除元素(要求:删除第一个学生) 使用少,了解
@Test
public void del() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个 xml 文件
Document document = saxReader.read(new File("src/students.xml"));
//找到该元素第一个学生
Element stu = (Element)
document.getRootElement().elements("student").get(2);
//删除元素
stu.getParent().remove(stu);
// //删除元素的某个属性
// stu.remove(stu.attribute("id"));
//更新 xml
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
韩顺平 Java 工程师
output.setEncoding("utf-8");//输出的编码 utf-8
//把我们的 xml 文件更新
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
System.out.println("删除成功~");
}
更新元素(要求把所有学生的年龄+3) 使用少,了解
@Test
public void update() throws Exception {
//1.得到解析器
SAXReader saxReader = new SAXReader();
//2.指定解析哪个 xml 文件
Document document = saxReader.read(new File("src/students.xml"));
//得到所有学生的年龄
List<Element> students = document.getRootElement().elements("student");
//遍历, 所有的学生元素的 age+3
for (Element student : students) {
//取出年龄
Element age = student.element("age");
age.setText((Integer.parseInt(age.getText()) + 3) + "");
}
//更新
//直接输出会出现中文乱码:
OutputFormat output = OutputFormat.createPrettyPrint();
output.setEncoding("utf-8");//输出的编码 utf-8
//把我们的 xml 文件更新
XMLWriter writer = new XMLWriter(
new FileOutputStream(new File("src/students.xml")), output);
writer.write(document);
writer.close();
System.out.println("更新成功~");
}
}
![[Juc进阶]Callable、Future和FutureTask](https://img-blog.csdnimg.cn/img_convert/c6015c96c94dd7e364ac22bdbda4e5a1.png)