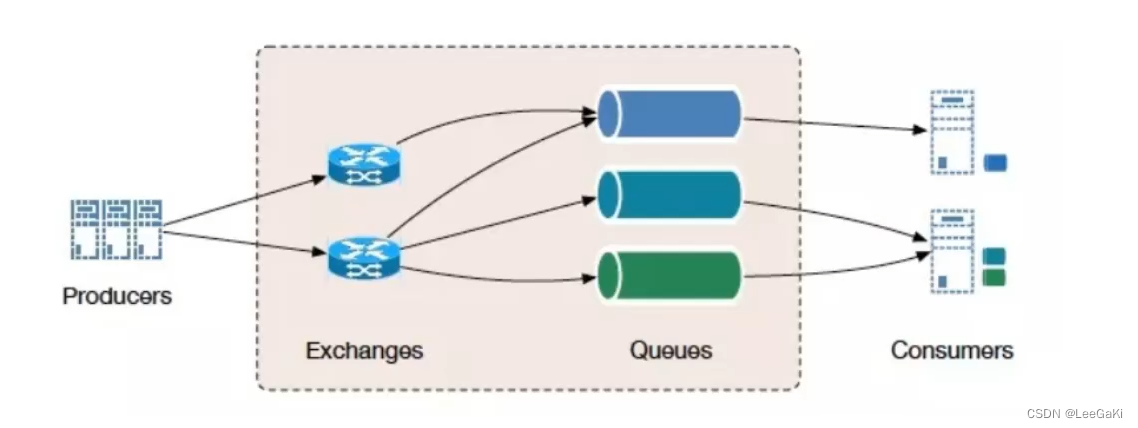
一. 为什么选择RabbitMq?
1.支持持久化消息,持久化消息主要是指我们机器在不可抗力因素等情况下挂掉了,消 息不会丢失的机制。
2.支持高并发,erlang语言面向并发面向消息的函数编程语言,可以很快创建轻量级线程。
3.社区活跃度
二.为什么使用RabbitMq(有个什么业务场景用到mq可以增大效率)
1.解耦
新增两个服务不需要改动之前代码,只需订阅相对的队列即可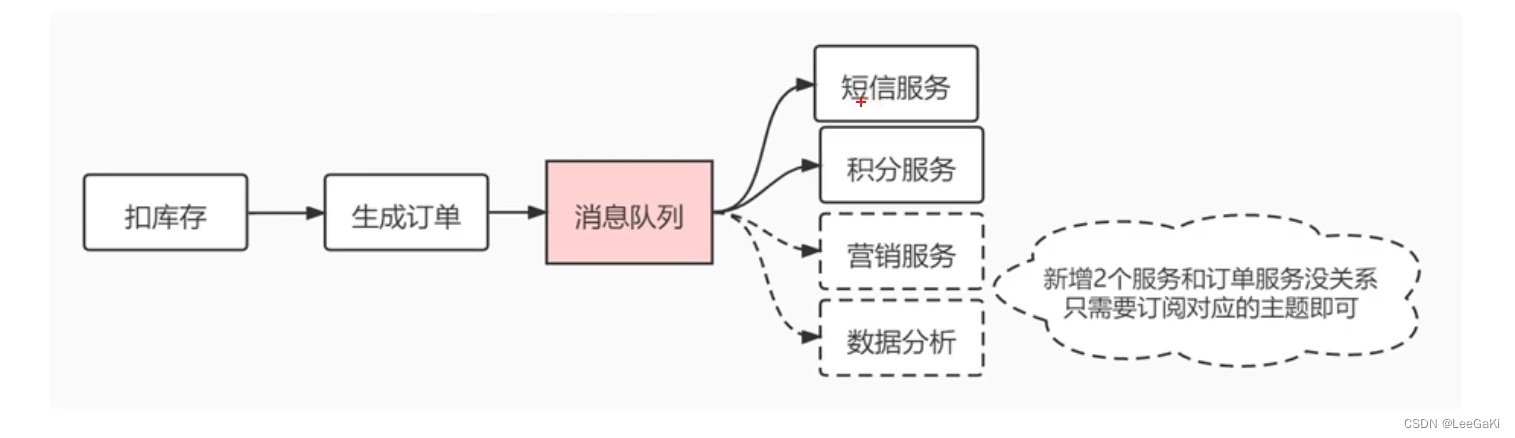
2.异步
假如没有消息队列,同步处理,需要16ms才能返回结果
假如短信服务宕机,依旧可以完成下订单,等待短信服务上线再进行消费
3.削峰(时间换空间)
三.如何保证消息的不丢失?
1.确保消息到mq(发送方确认模式打开)
工作机制:消息从生产者投递到exchange(信道),会返回一个confirmCallback。无论是否投递成功,都会返回。当ack=true,表示成功,当ack=fase,表示失败
2.确保消息路由到正确的队列(开启路由失败通知)回退模式
当消息由Exchange路由到queue失败后,如果设置了 spring.rabbitmq.template.mandatory=true,则消息回回退给消息生产者producer,并执行回调函数
3.确保消息再队列中正确的存储(交换器、消息、队列都需要持久化)
4.确保消息从队列中正确的投递给消费者(取消自动确认,开启手动确认)
自动确认是指,当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除。但是在实际业务处理中,很可能消息接收到,业务处理出现异常,那么该消息就会丢失。
手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息。
四.重复消息的产生,如何防止重复消费?
1.发送消息到消息中间件,消息存储成功但发送端没有收到发送成功的消息返回而重试
2.将消息投递给消费者消费,消费成功没有收到成功返回而重复投递
解决
主要是要求消费者来处理这种重复的操作,要求消息接收者的消息处理的幂等性的。
比如一条sql语句执行多次,不会影响实际数据情况,成为幂等操作。
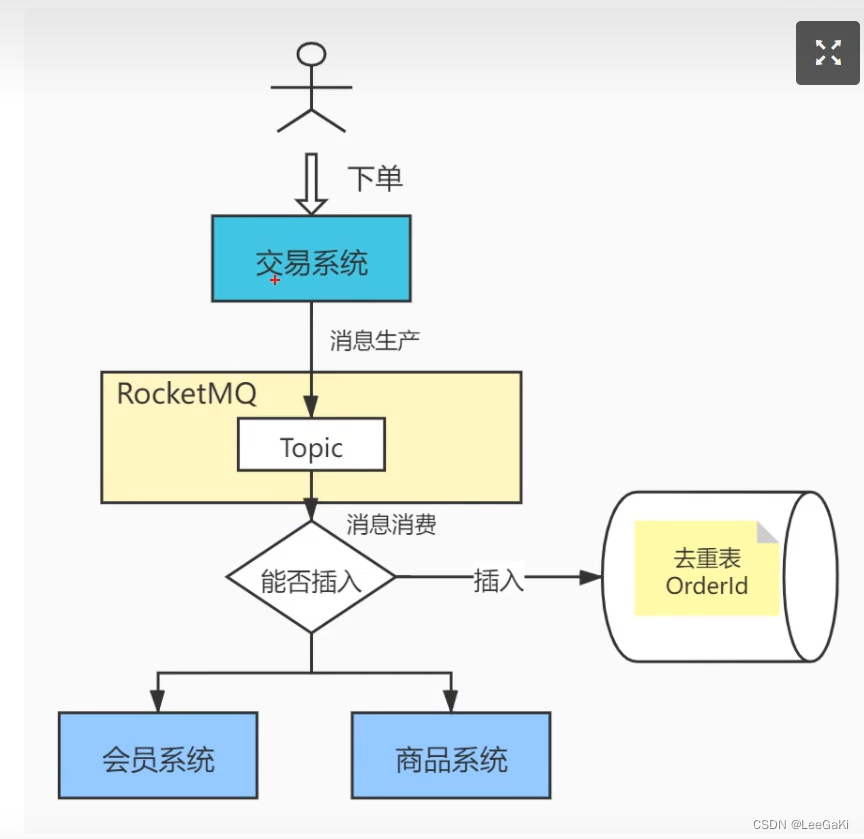
1.MVCC多版本并发控制,是乐观锁的一种实现,再生产者发送消息时带上数据的版本号,相同的版本号只有一次成功的机会,一旦失败必须重新获取新的版本号重新消费。
2.去重表(将唯一的数据作为表的id进行插入,一旦失败直接返回达到不重复消费)