作者:黑夜路人
时间:2023年7月
Inputs Process(输入处理层)实现
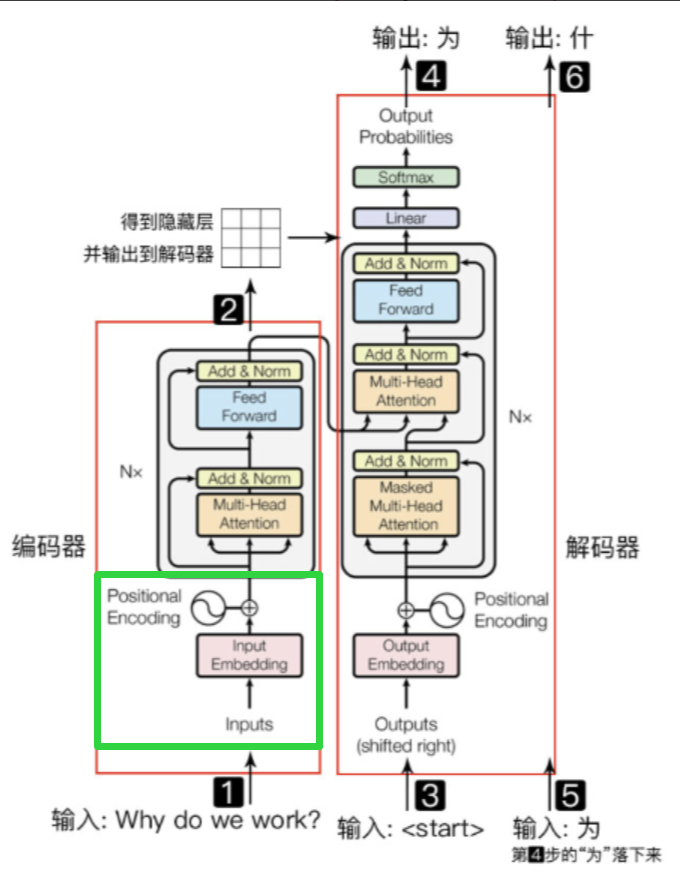
我们看整个绿色框的整个位置,就是Inputs Process(输入处理层)。
在输入处理层,其实非常容易理解,主要就是把输入的每个内容(文字)变成能够跟Encoder交互的,深度学习能够理解识别的东西。
里面主要是两个步骤,一个是对输入字符串进行切分(Tokenize)成为一个个token,另外一个步骤是把token放到一个高纬矩阵中(Input Embedding)的过程,还有一个步骤是为了保证知道输入的token的顺序,所以需要把token位置也进行Embedding(Positional Encoding)。
Embedding就是用一个低维稠密的向量“表示”一个对象,这里所说的对象可以是一个词(Word2vec),也可以是一个物品(Item2vec),亦或是网络关系中的节点(Graph Embedding)。其中“表示”这个词意味着Embedding向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。Embedding目前在NLP领域有很多模型,不同技术解决方案不同,比如传统的 word2vec,还有后面的FastText、GIoVe、Bert Embedding 等等。
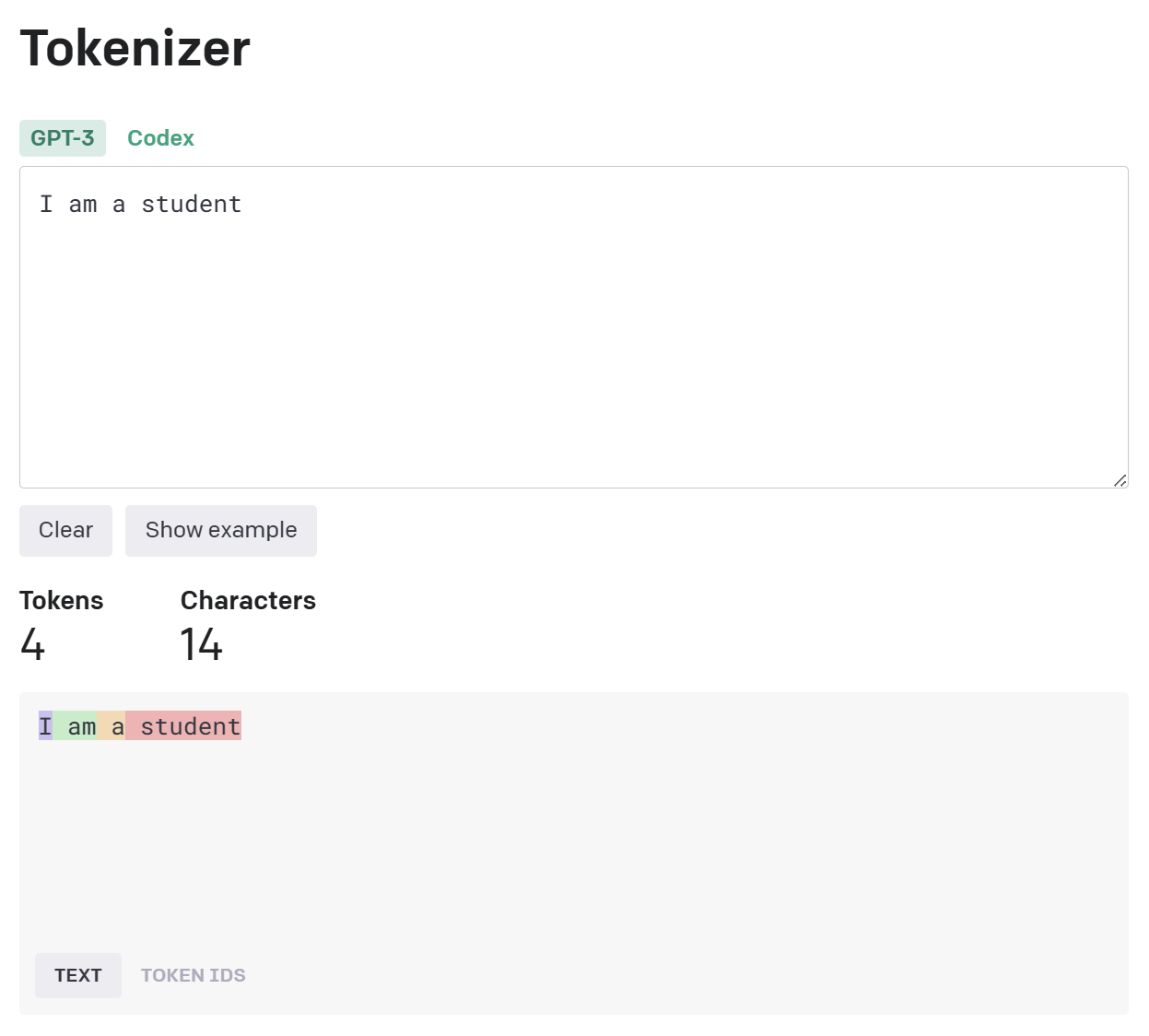
需要做Embedding,首先必须把相关的输入内容(文本)变成一个个token(可以简单理解为搜索里面的分词过程),我们看一个OpenAI GPT Tokenize 结果:
针对整个tokenize和token embedding的大概代码,主要是引用 Transformers 中的bert预训练模型和一些相关词表进行tokenize和embedding的过程:
import torch
from transformers import BertTokenizer, BertModel, AutoTokenizer, AutoModel
# Tokenizer class
class Tokenizer:
def __init__(self, model_path):
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
def tokenize(self, text):
return self.tokenizer.tokenize(text)
def convert_tokens_to_ids(self, tokens):
return self.tokenizer.convert_tokens_to_ids(tokens)
def convert_ids_to_tokens(self, ids):
return self.tokenizer.convert_ids_to_tokens(ids)
def convert_tokens_to_string(self, tokens):
return self.tokenizer.convert_tokens_to_string(tokens)
# Input Sequence Embedding class
class InputEmbedding:
def __init__(self, model_path):
self.embedding_model = BertModel.from_pretrained(model_path)
self.tokenizer = BertTokenizer.from_pretrained(model_path)
def get_seq_embedding(self, sequence):
input_tokens = self.tokenizer(sequence, return_tensors='pt')
output_tensors = self.embedding_model(**input_tokens)
return output_tensors
def get_input_seq_ids(self, sequence):
return self.tokenizer(sequence, return_tensors='pt')
def get_input_tokens_embedding(self, input_tokens):
return self.embedding_model(**input_tokens)大概测试 tokenize和embedding 的代码以及输出:
# define pretrained model path
MODEL_BERT_BASE_ZH = "D:/Data/Models/roc-bert-base-zh"
MODEL_BERT_BASE_CHINESE = "bert-base-chinese"
MODEL_BERT_BASE = "bert-base-cased"
# input sequence list
seqs = [
'我的名字叫做黑夜路人',
'My name is Black',
]
# call transformers tokenizer get tokens and token-ids
tokenizer = Tokenizer(MODEL_BERT_BASE_ZH)
input_embedding = InputEmbedding(MODEL_BERT_BASE_CHINESE)
for seq in seqs:
tokens = tokenizer.tokenize(seq)
print(seq, ' => ', tokens)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(seq, ' => ', ids)
s = input_embedding.get_seq_embedding(seq)
print(s[0].shape)
print(s[0])以上Tokenize和Embedding代码最终输出大概如下结果:
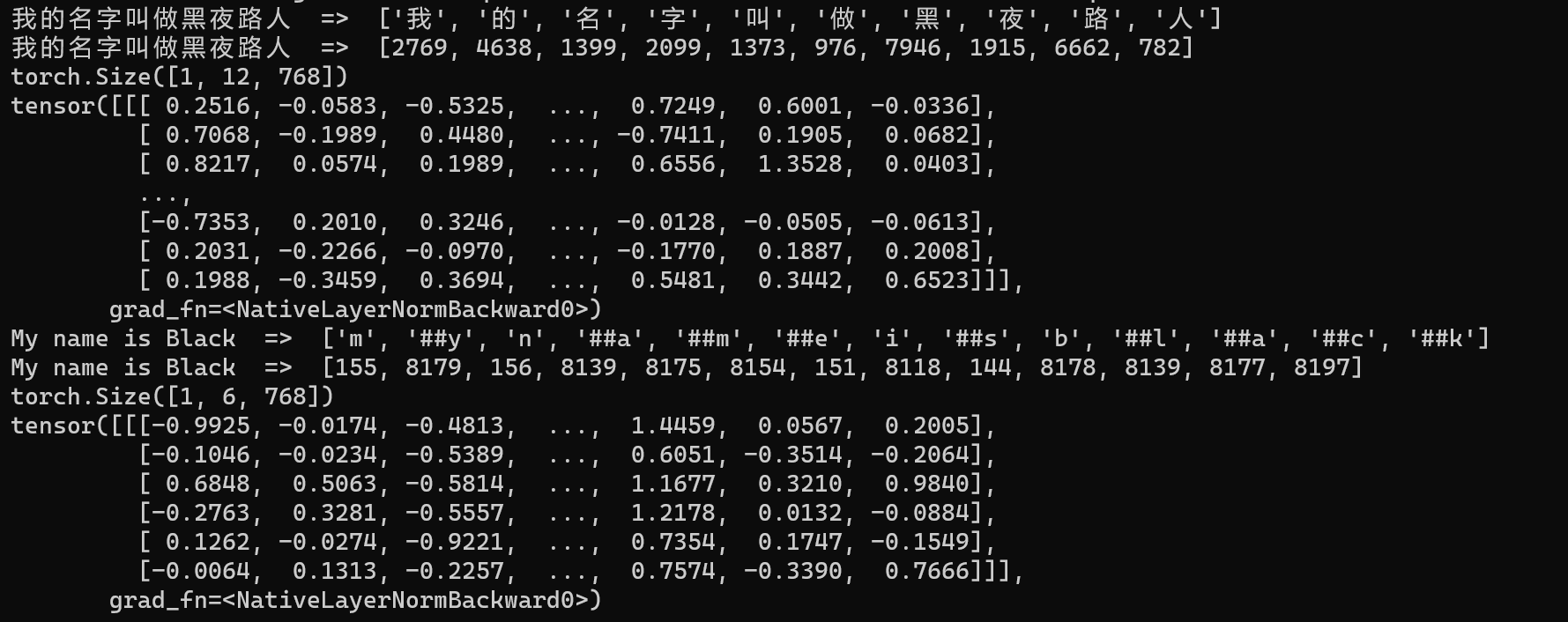
对于Transformer等框架来说,基本在处理 Embedding 场景里,基本主要就是每个字符使用 768 个数字来标识一个token(或者是token id)。比如说,假设常用字有5000个,然后基本都只有一个样本,那么大概会生成一个 tensor.Size([5000, 1, 768]) 的矩阵,就能够在一个高纬矩阵里表示所有的字符了。
Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
任何一门语言中,词语的位置和顺序对句子意思表达都是至关重要的。传统的RNN模型在处理句子时,以序列的模式逐个处理句子中的词语,这使得词语的顺序信息在处理过程中被天然的保存下来了,并不需要额外的处理。
而对于Transformer来说,由于句子中的词语都是同时进入网络进行处理,顺序信息在输入网络时就已丢失。因此,Transformer是需要额外的处理来告知每个词语的相对位置的。其中的一个解决方案,就是论文中提到的Positional Encoding,将能表示位置信息的编码添加到输入中,让网络知道每个词的位置和顺序。
如果你对现有训练好的Tokenize不满意,因为这个会对最终的深度学习模型效果产生影响,那么我们可以自己简单做Tokenize的技术实现。
比如我们依赖于GPT-2的BPE词表生成自己的一个Tokenize程序,下面是一个自主实现的Tokenize的核心代码:
# API: BlackTokenizer.encode(text)
# 将一个字符串编码成一个整数列表(tokens)
def encode(self, text):
"""
Transforms a string into an array of tokens
:param text: string to be encoded
:type text: str
:returns: an array of ints (tokens)
"""
if not isinstance(text, str):
text = text.decode(self._DEFAULT_ENCODING)
bpe_tokens = []
matches = self._regex_compiled.findall(text)
for token in matches:
token = ''.join([self._byte_encoder[x] for x in self._encode_string(token)])
new_tokens = [self._encoder[x] for x in self._bpe(token, self._bpe_ranks).split(' ')]
bpe_tokens.extend(new_tokens)
return bpe_tokens
# API: BlackTokenizer.decode(tokens)
# 将输入的整数列表 tokens 转换成原始字符串
def decode(self, tokens):
"""
Transforms back an array of tokens into the original string
:param tokens: an array of ints
:type tokens: list
:returns: the original text which was encoded before
"""
text = ''.join([self._decoder[x] for x in tokens])
textarr = [int(self._byte_decoder[x]) for x in list(text)]
text = bytearray(textarr).decode("utf-8")
return text
里面比较核心的是针对bpe编码和配套encoder.json的处理,BPE文件格式大概是这样:
配套的encoder.json 大概长这样:

处理BPE的核心代码大概是这样的:
# use BPE algorithm encode input word or phrase
# 使用 BPE(Byte Pair Encoding)算法将输入的单词或词组进行编码, 该方法只负责对单个单词或词组进行 BPE 编码,如果要对一组文本数据进行 BPE 编码,需要调用 _bpe_batch 方法
"""
BPE 是一种压缩算法,用于将文本数据中常见的连续字符序列合并成单个字符,以减少词汇量并提高压缩效率
1. 基于训练数据生成 BPE 码表,即生成常见字母或字符串的组合,并给组合编码一个整数作为标识符。
2. 将文本中所有的单词划分成字符或者字符组成的子串。
3. 在所有单词中找出出现次数最多的字符或者字符组合,将这个字符或者字符组合当做一个新的字符来替代原有单词中的这个字符或者字符组合。并在编码表中添加这个字符或者字符组合的编码。
3. 重复步骤 3 直到达到预设的 BPE 编码次数或者到达最小词频。
"""
def _bpe(self, token, bpe_ranks):
if token in self._cache:
return self._cache[token]
word = list(token)
pairs = self._get_pairs(word)
if not pairs:
return token
while True:
min_pairs = {}
for pair in pairs:
pair_key = ','.join(pair)
rank = bpe_ranks.get(pair_key, float("nan"))
min_pairs[10e10 if math.isnan(rank) else rank] = pair_key
bigram = min_pairs[min(map(int, min_pairs.keys()))]
if not bigram in bpe_ranks:
break
bigram = bigram.split(',', 1)
first = bigram[0]
second = bigram[1]
new_word = []
i = 0
while i < len(word):
j = -1
try:
j = word.index(first, i)
except:
pass
if j == -1:
new_word.extend(word[i:])
break
new_word.extend(word[i:j])
i = j
if word[i] == first and i < len(word)-1 and word[i+1] == second:
new_word.append(first+second)
i += 2
else:
new_word.append(word[i])
i += 1
word = new_word
if len(word) == 1:
break
pairs = self._get_pairs(word)
word = ' '.join(word)
self._cache[token] = word
return word基于以上的Tokenize,我们通过一段测试代码:
seqs = [
'我的名字叫做黑夜路人',
'My name is Black',
"我的nickname叫heiyeluren",
"はじめまして",
"잘 부탁 드립니다",
"До свидания!",
"😊😁😄😉😆🤝👋",
"今天的状态很happy,表情是😁",
]
print('\n------------------BlackTokenize Test------------------')
tk = BlackTokenize()
for seq in seqs:
token_list = tk.get_token_list(seq)
# print('Text:', seq, ' => Tokens:', tokens)
enc_seq = tk.encode(seq)
# continue
dec_seq = tk.decode(enc_seq)
token_count = tk.count_tokens(seq)
print( 'RawText:', seq, ' => TokenList:', token_list, ' => TokenIDs', enc_seq, ' => TokenCount:', token_count, '=> DecodeText:', dec_seq)
print('------------------BlackTokenize Test------------------\n')测试代码输出结果:
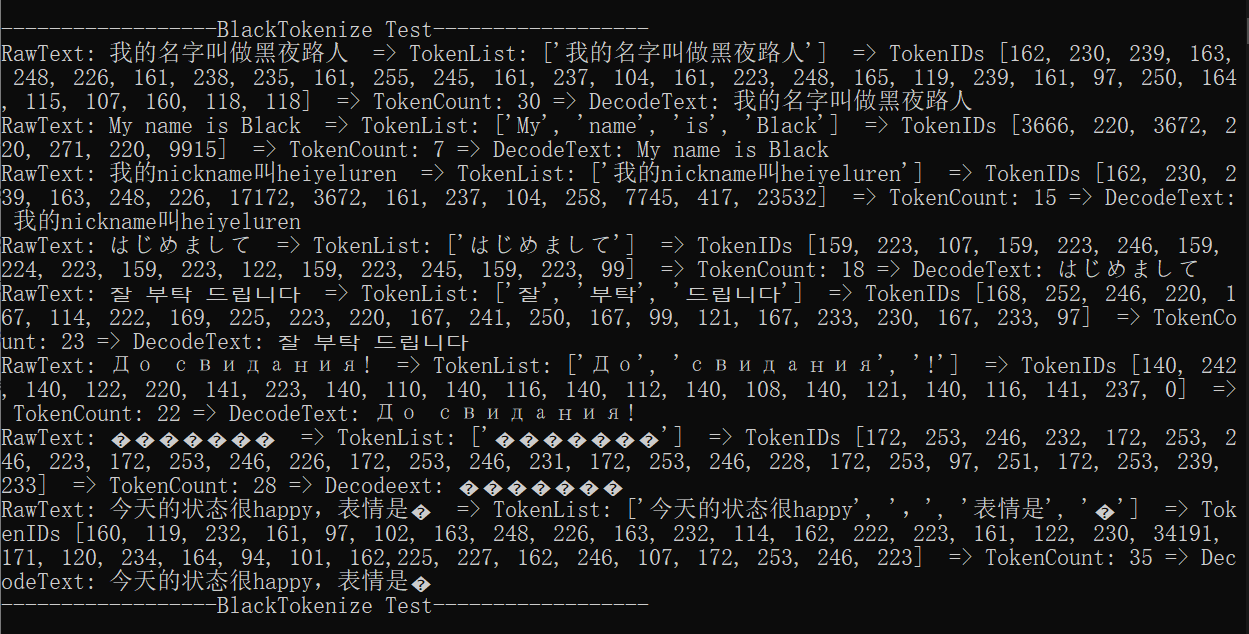
输出结果可以看到,本质就是把不同的字符或者是字符串转成了一个或多个int类型的数字编码,整个Tokenize的过程算完成。
除了Tokenize(token to id)的过程,还有就是Embedding的过程,对于Transformer来说,主要包含词嵌入和位置嵌入两个环节。
我们实现一下这个输入嵌入(Inputs Embedding)的核心代码:
# 输入嵌入(Input Embeddings)层的构建
'''
这个层的作用是将 tokens 的整数列表编码成相应的向量集合,以便后续可以输入到神经网络中.
为了解决能够体现词与词之间的关系,使得意思相近的词有相近的表示结果,这种方法即 Word Embedding(词嵌入)。
最方便的途径是设计一个可学习的权重矩阵 W,将词向量与这个矩阵进行点乘,即得到新的表示结果。
假设 “爱” 和 “喜欢” 这两个词经过 one-hot 后分别表示为 10000 和 00001,权重矩阵设计如下:
[ w00, w01, w02
w10, w11, w12
w20, w21, w22
w30, w31, w32
w40, w41, w42 ]
那么两个词点乘后的结果分别是 [w00, w01, w02] 和 [w40, w41, w42],在网络学习过程中(这两个词后面通常都是接主语,如“你”,“他”等,或者在翻译场景,
它们被翻译的目标意思也相近,它们要学习的目标一致或相近),权重矩阵的参数会不断进行更新,从而使得 [w00, w01, w02] 和 [w40, w41, w42] 的值越来越接近。
我们还把向量的维度从5维压缩到了3维。因此,word embedding 还可以起到降维的效果。
另一方面,其实,可以将这种方式看作是一个 lookup table:对于每个 word,进行 word embedding 就相当于一个lookup操作,在表中查出一个对应结果。
'''
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)另外把相应位置做嵌入:
# 实现的是 Transformer 模型中的位置编码(Positional Encoding)
'''
word embedding,我们获得了词与词之间关系的表达形式,但是词在句子中的位置关系还无法体现。
由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Embedding
预定义一个函数,通过函数计算出位置信息,大概公式如下:
\begin{gathered}
PE_{(pos,2i)}=\sin{(pos/10000^{2i/d})} \\
P E_{(p o s,2i+1)}=\operatorname{cos}\left(p o s_{\substack{i=1}{\mathrm{osc}}/\mathrm{1}{\mathrm{999}}\mathrm{2}i/d\right)
\end{gathered}
Transformer 模型使用自注意力机制来处理序列数据,即在编码器和解码器中分别使用自注意力机制来学习输入数据的表示。
由于自注意力机制只对序列中的元素进行注意力权重的计算,它没有固定位置的概念,
因此需要为序列中的元素添加位置信息以帮助 Transformer 模型学习序列中元素的位置。
'''
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model) # max_len代表句子中最多有几个词
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) # d_model即公式中的d
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)] # 原向量加上计算出的位置信息才是最终的embedding
return self.dropout(x)实际中Tokenize有很多实现方法,可以用已经预训练好的模型直接调用,或者是现成的各种包进行实现。比如 bert tokenize、spacy Tokenize、tiktoken、gpt3_tokenizer等等都可以,只是中英文处理效果不同,或者是最后的token数量切割大小不同,当然,这个最终也会影响训练效果。
取代你的不是AI,而是比你更了解AI和更会使用AI的人!
##End##