上一章:
Django实现接口自动化平台(十一)项目模块Projects序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客
本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看:
python django vue httprunner 实现接口自动化平台(最终版)_python+vue自动化测试平台_做测试的喵酱的博客-CSDN博客
一、DebugTalks 背景及相关接口
1.1 DebugTalks 应用
接口自动化,驱动使用的是httprunner==1.0版本。
httprunner 中,有一个debugtalks.py 文件,来编写自定义函数。
所以我们在创建项目时,会自动创建一个debugtalks.py 文件。一个项目对应一个debugtalks.py文件。
1.2 DebugTalks 接口
| 请求方式 | URI | 对应action | 实现功能 |
| GET | /debugtalks/ | .list() | 查询debugtalk列表 |
| GET | /debugtalks/{id}/ | .retrieve() | 检索一条debugtalk的详细数据 |
| PUT | /debugtalks/{id}/ | update() | 更新一条数据中的全部字段 |
| PATCH | /debugtalks/{id}/ | .partial_update() | 更新一条数据中的部分字段 |
二、DebugTalks 接口
debugtalks 就是一个python文件
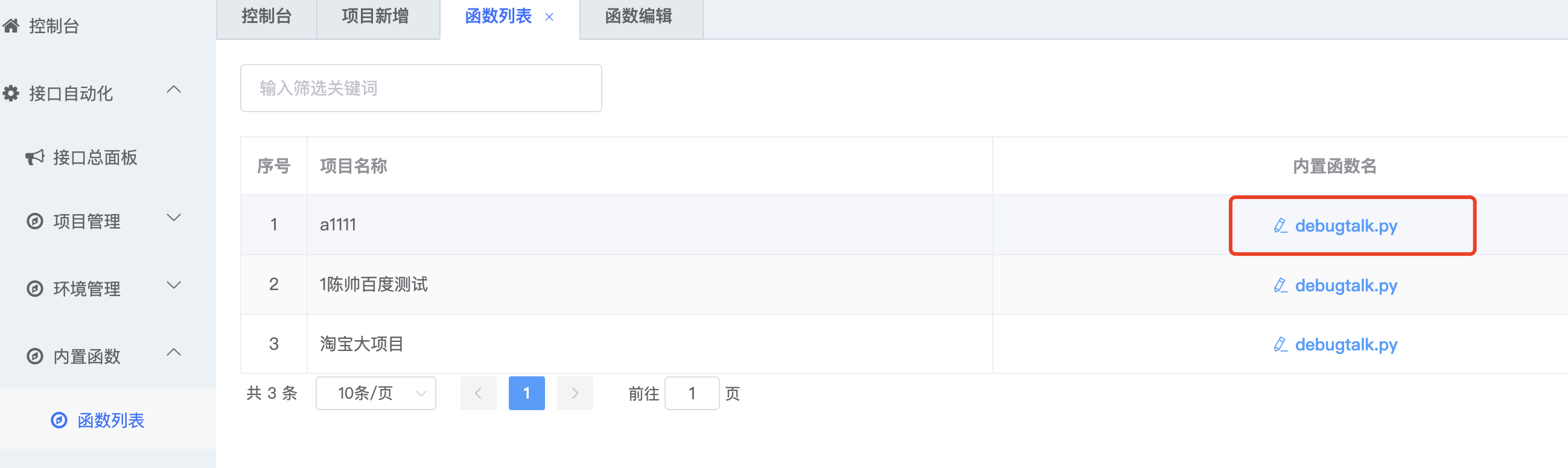
2.1 内置函数文件的列表 .list()

内置函数文件,是伴随的项目产生的。创建一个项目,自动创建一个debugtalk.py文件。删除一个项目,自动删除对应的debugtalk.py文件。
| GET | /debugtalks/ | .list() | 查询debugtalk列表 |
2.2 查看内置函数文件 .retrieve()
| GET | /debugtalks/{id}/ | .retrieve() | 检索一条debugtalk的详细数据 |
点击文件
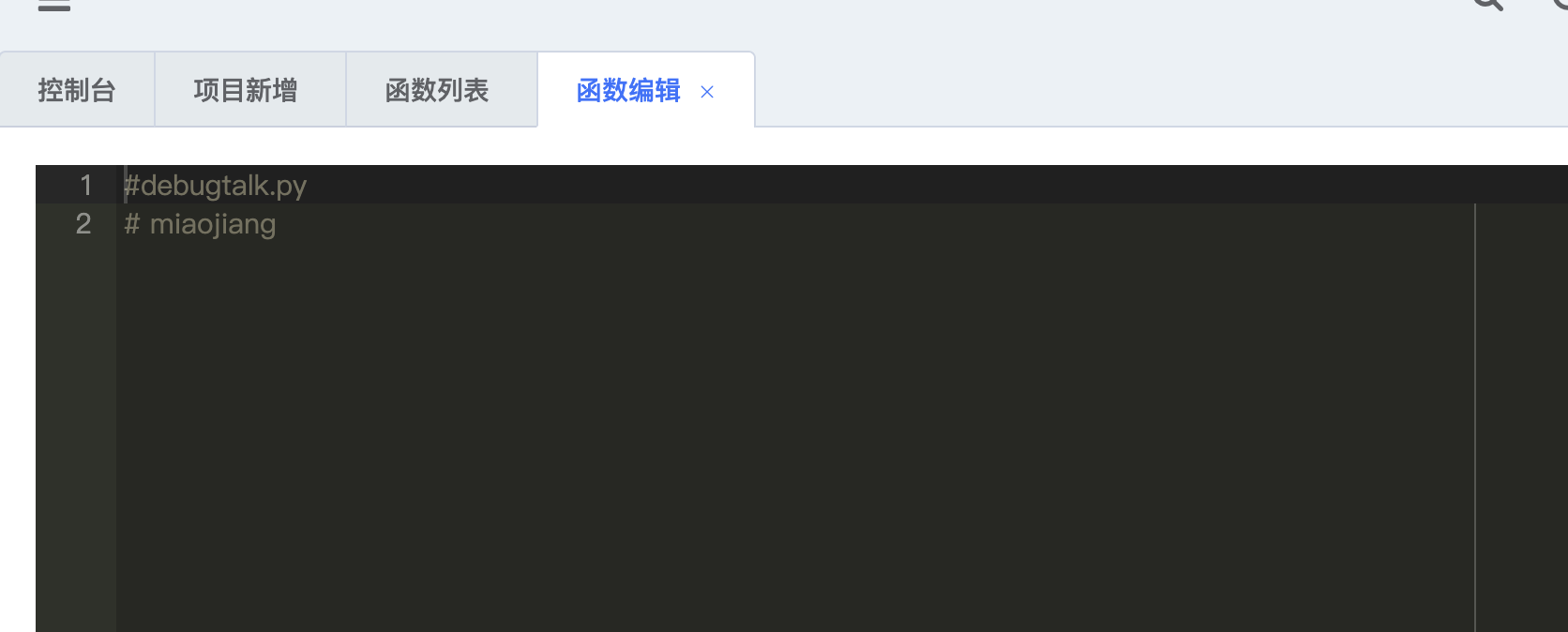
2.3 更新内置函数文件
| PUT | /debugtalks/{id}/ | update() | 更新一条数据中的全部字段 |
点击底部保存,更新文件。
2.4 创建与删除
创建与删除,是伴随项目 创建与删除的,所以内置文件的创建与删除,不是通过接口实现的。
三、模型类model
from django.db import models
from utils.base_models import BaseModel
class DebugTalks(BaseModel):
id = models.AutoField(verbose_name='id主键', primary_key=True, help_text='id主键')
name = models.CharField('debugtalk文件名称', max_length=200, default='debugtalk.py', help_text='debugtalk文件名称')
debugtalk = models.TextField(null=True, default='#debugtalk.py', help_text='debugtalk.py文件')
project = models.OneToOneField('projects.Projects', on_delete=models.CASCADE,
related_name='debugtalks', help_text='所属项目')
class Meta:
db_table = 'tb_debugtalks'
verbose_name = 'debugtalk.py文件'
verbose_name_plural = verbose_name
ordering = ('id',)
def __str__(self):
return self.name
这段代码定义了一个名为 DebugTalks 的 Django 模型(Model)类,表示一个 debugtalk.py 文件。
该模型类继承自 BaseModel,并包含以下字段:
- id:自增的主键字段,类型为 AutoField。
- name:debugtalk 文件的名称,类型为 CharField。
- debugtalk:debugtalk.py 文件的内容,类型为 TextField。
- project:与该 debugtalk.py 文件关联的项目,采用一对一(OneToOne)关系,类型为外键(ForeignKey)字段,关联到 projects.Projects 模型。
此外,该模型类还定义了以下元数据(Meta):
- db_table:指定数据库中表的名称为 tb_debugtalks。
- verbose_name:该模型在后台管理页面中显示的名称为 "debugtalk.py 文件"。
- verbose_name_plural:该模型在后台管理页面中显示的复数名称也为 "debugtalk.py 文件"。
- ordering:指定按照 id 字段进行升序排序。
通过这个模型类,可以在数据库中创建一个名为 tb_debugtalks 的表,存储 debugtalk.py 文件的信息,并与项目进行关联。
四、序列化器类
from rest_framework import serializers
from .models import DebugTalks
class DebugTalksModelSerializer(serializers.ModelSerializer):
project = serializers.SlugRelatedField(slug_field='name', read_only=True)
class Meta:
model = DebugTalks
exclude = ('create_datetime', 'update_datetime',)
extra_kwargs = {
'debugtalk': {
'write_only': True
}
}
class DebugTalksSerializer(serializers.ModelSerializer):
class Meta:
model = DebugTalks
fields = ('id', 'debugtalk')
定义了两个序列化器类:
1、DebugTalksModelSerializer 类继承自 DRF 的 ModelSerializer。其中:
- project 字段使用 SlugRelatedField,将关联到 DebugTalks 模型的 project 字段以 name 属性的形式进行展示,且只读(read_only=True)。
- Meta 内部类中指定了模型为 DebugTalks,并且排除了 create_datetime 和 update_datetime 字段。
- extra_kwargs 定义了对于 debugtalk 字段的额外属性,此处设置为只写(write_only=True)。
2、DebugTalksSerializer 类也继承自 DRF 的 ModelSerializer。其中:
- Meta 内部类中指定了模型为 DebugTalks,并且只包含 id 和 debugtalk 两个字段。
这些序列化器可以用于将 DebugTalks 模型实例转换为 JSON 格式的数据,或者将 JSON 数据反序列化为 DebugTalks 模型实例。通过定义不同的字段和属性,可以对数据进行验证、创建和更新操作,以满足特定的需求。
五、视图
from rest_framework import viewsets
from rest_framework.decorators import action
from rest_framework import permissions
from .models import DebugTalks
from rest_framework import mixins
from . import serializers
class DebugTalksViewSet(mixins.ListModelMixin,
mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
viewsets.GenericViewSet):
queryset = DebugTalks.objects.all()
serializer_class = serializers.DebugTalksModelSerializer
permission_classes = [permissions.IsAuthenticated]
def get_serializer_class(self):
return serializers.DebugTalksSerializer if self.action == 'retrieve' else self.serializer_class
首先导入了必要的库和模块:
- from rest_framework import viewsets 导入了 DRF 的视图集。
- from rest_framework.decorators import action 导入了 DRF 的装饰器,用于定义自定义动作。
- from rest_framework import permissions 导入了 DRF 的权限类。
- from .models import DebugTalks 导入了当前项目中的 DebugTalks 模型类。
- from rest_framework import mixins 导入了 DRF 的 Mixin 类。
- from . import serializers 导入了当前项目中的序列化器。
然后定义了一个 DebugTalksViewSet 类,该类继承了 DRF 提供的各种 Mixin 类和 GenericViewSet 类。其中:
- mixins.ListModelMixin 提供了列表展示功能。
- mixins.RetrieveModelMixin 提供了详情展示功能。
- mixins.UpdateModelMixin 提供了更新功能。
- viewsets.GenericViewSet 是一个通用的视图集类。
在类中定义了以下属性和方法:
- queryset 属性指定了视图集的查询集,即需要进行操作的数据集合,这里是 DebugTalks.objects.all(),表示获取 DebugTalks 模型的所有实例。
- serializer_class 指定了默认使用的序列化器类为 serializers.DebugTalksModelSerializer。
- permission_classes 指定了默认的权限类为 permissions.IsAuthenticated,表示只有认证的用户才能访问该视图集。
接下来定义了一个自定义方法 get_serializer_class(),用于根据不同的动作决定使用哪个序列化器类。如果动作是 retrieve(详情展示),则使用 serializers.DebugTalksSerializer,否则使用默认的序列化器类。
通过这些配置和定义,DebugTalksViewSet 类可以提供列表展示、详情展示和更新功能,并根据不同的动作选择合适的序列化器类进行数据的序列化和反序列化操作。同时,该视图集还具备权限控制,只有认证的用户才能访问。