一、前言
在许多搜索引擎中,都内置了以图搜图的功能。以图搜图功能,可以极大简化搜索工作。今天要做的就是实现一个以图搜图引擎。
我们先来讨论一下以图搜图的难点,首当其冲的就是如何对比图片的相似度?怎么样的图片才叫相似?人可以一眼判断,但是计算机却不一样。图片以数字矩阵的形式存在,而相似度的比较也是比较矩阵的相似度。但是这有一些问题。
第二个问题就是大小问题,图片的大小通常是不一样的,而不同大小的矩阵也无法比较相似度。不过这个很好解决,直接修改图片尺寸即可。
第三个问题则是像素包含的信息非常有限,无法表达抽象信息。比如画风、物体、色调等。
根据上面描述,我们现在要解决两个问题:用什么信息替换像素信息、怎么计算相似度。下面一一解决。在开始前,我们先实现一个简易的以图搜图功能。
二、简易以图搜图实现
2.1 如何计算相似度
首先来讨论一下直接使用像素作为图像的表示,此时我们应该如何完成以图搜图的操作。一个非常简单的想法就是直接计算两个图片的几何距离,假如我们目标图片为target,图库中的图片为source,几何距离的计算如下:
distance = sum[(target−source)2]distance = \sqrt{sum[(target - source)^2]}distance = sum[(target−source)2]
然后把距离最小的n个图片作为搜索结果。
这个方法看起来不可靠,但是实际使用时也会有不错的结果。如果图库图片本身不是非常复杂,比如动漫头像,那么这种方式非常简单有效,而其它情况下结果会比较不稳定。
2.2 基于几何距离的图片搜索
基于几何距离的图片搜索实现步骤如下:
- 把图片修改到同一尺寸,如果尺寸不同则无法计算几何距离
- 选定一个图片作为目标图片,即待搜索图片
- 遍历图库,计算几何距离,并记录到列表
- 对列表排序,获取几何距离最小的n张图片
这里使用蜡笔小新的图片作为图库进行搜索,下面是图片的一些示例:

部分图片有类似的风格,我们希望能根据一张图片找到类似风格的图片。实现代码如下:
import os
import cv2
import random
import numpy as np
base_path = r"G:\datasets\lbxx"
# 获取所有图片路径
files = [os.path.join(base_path, file) for file in os.listdir(base_path)]
# 选取一张图片作为目标图片
target_path = random.choice(files)
target = cv2.imread(target_path)
h, w, _ = target.shape
distances = []
# 遍历图库
for file in files:
# 读取图片,转换成与目标图片同一尺寸
source = cv2.imread(file)
if not isinstance(source, np.ndarray):
continue
source = cv2.resize(source, (w, h))
# 计算几何距离,并加入列表,这里没有开方
distance = ((target - source) ** 2).sum()
distances.append((file, distance))
# 找到相似度前5的图片,这里拿了6个,第一个是原图
distances = sorted(distances, key=lambda x: x[-1])[:6]
imgs = list(map(lambda x: cv2.imread(x[0]), distances))
result = np.hstack(imgs)
cv2.imwrite("result.jpg", result)
下面是一些比较好搜索结果,其中最左边是target,其余10张为搜索结果。



如果换成猫狗图片,下面是一些搜索结果:


2.3 存在的问题
上面的实现存在两个问题,其一是像素并不能表示图像的深层含义。搜索结果中经常会返回颜色相似的图片。第二个则是计算复杂度的问题,如果图片大小未224×224,那么图片有150528个像素,计算几何距离会比较耗时。而且在搜索时,需要遍历整个图库,当图库数量较大时,计算量将不可忍受。因此需要对上面的方法进行一些改进。
三、改进一,用特征代替像素
3.1 图像特征
在表示图片时,就是从基本的像素到手工特征再到深度学习特征。相比之下,用卷积神经网络提取的图像特征有几个有点,具体如下:
- 具有很强的泛化能力,提取的特征受角度、位置、亮度等的影响会像素和手工特征。
- 较少的维度,使用ResNet50提取224×224图片的特征时,会返回一个7×7×2048的张量,这比像素数量要少许多。
- 具有抽象性,相比前面两种,卷积神经网络提取的特征具有抽象性。比如关于图片中类别的信息,这是前面两种无法达到的效果。
在本文我们会使用ResNet50来提取图片特征。
3.2 Embedding的妙用
使用ResNet50提取的特征也可以被称为Embedding,也可以简单理解为图向量。Embedding近几年在人工智能领域发挥了巨大潜力,尤其在自然语言处理领域。
3.2.1 关系可视化
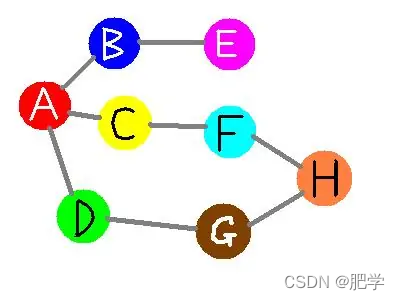
早期Embedding主要用于词向量,通过word2vec把单词转换成向量,然后就可以完成一些奇妙的操作。比如单词之间关系的可视化,比如下面这张图:

在图片中可视化了:mother、father、car、auto、cat、tiger六个单词,从图可以明显看出mother、father比较近;car、auto比较近;cat、tiger比较近,这些都与我们常识相符。
3.2.2 关系运算
我们希望训练良好的Embedding每一个维度都有一个具体的含义,比如第一维表示词性,第二维表示情感,其余各个维度都有具体含义。如果能达到这个效果,或者达到近似效果,那么就可以使用向量的计算来计算单词之间的关系。
比如“妈妈-女性+男性≈爸爸”,或者“国王-男性+女性≈皇后”。比如以往要搜索“物理学界的贝多芬是谁”可能得到非常奇怪的结果,但是如果把这个问题转换成“贝多芬-音乐界+物理学界≈?”,这样问题就简单多了。
3.2.3 聚类
当我们可以用Embedding表示图片和文字时,就可以使用聚类算法完成图片或文字的自动分组。在许多手机的相册中,就有自动图片归类的功能。
聚类还可以加速搜索的操作,这点会在后面详细说。
3.3 以图搜图改进
下面使用图像特征来代替像素改进以图搜图,代码如下:
import os
import cv2
import random
import numpy as np
from keras.api.keras.applications.resnet50 import ResNet50
from keras.api.keras.applications.resnet50 import preprocess_input
w, h = 224, 224
# 加载模型
encoder = ResNet50(include_top=False)
base_path = r"G:\datasets\lbxx"
files = [os.path.join(base_path, file) for file in os.listdir(base_path)]
target_path = random.choice(files)
target = cv2.resize(cv2.imread(target_path), (w, h))
# 提取图片特征
target = encoder(preprocess_input(target[None]))
distances = []
for file in files:
source = cv2.imread(file)
if not isinstance(source, np.ndarray):
continue
# 读取图片,提取图片特征
source = cv2.resize(source, (w, h))
source = encoder(preprocess_input(source[None]))
distance = np.sum((target - source) ** 2)
distances.append((file, distance))
# 找到相似度前5的图片,这里拿了6个,第一个是原图
distances = sorted(distances, key=lambda x: x[-1])[:6]
imgs = list(map(lambda x: cv2.imread(x[0]), distances))
result = np.hstack(imgs)
cv2.imwrite("result.jpg", result)
这里使用在imagenet上预训练的ResNet50作为特征提取网络,提取的关键操作如下:
- 加载模型
# 加载ResNet50的卷积层,舍弃全连接部分
encoder = ResNet50(include_top=False)
- 图片预处理
# 把图片转换成224×224,并使用ResNet50内置的预处理方法处理
target = cv2.resize(cv2.imread(target_path), (w, h))
target = preprocess_input(target[None])
- 提取特征
# 使用ResNet40网络提取特征
target = encoder(preprocess_input(target)
下面是改进后的搜索结果:

四、改进二,使用聚类改进搜索速度
4.1 实现原理
在前面的例子中,我们都是使用线性搜索的方式,此时需要遍历所有图片。搜索复杂度为O(n),通常可以用树结构来存储待搜索的内容,从而把复杂度降低到O(logn)。这里我们使用更简单的方法,即聚类。
首先我们要做的就是对图片的特征进行聚类,聚成c个簇,每个簇都会对应一个簇中心。簇中心可以认为是一个簇中的平均结构,同一簇中的样本相似度会比较高。
在完成聚类后,我们可以拿到target图片的向量,在c个簇中心中查找target与哪个簇最接近。然后再到当前簇中线性查找最相似的几个图片。

4.2 代码实现
代码实现分为下面几个步骤:
- 把图片转换成向量
这部分代码和前面基本一样,不过这次为了速度快,我们把图像特征存储到embeddings.pkl文件:
import os
import cv2
import pickle
import numpy as np
import tensorflow as tf
from keras.api.keras.applications.resnet50 import ResNet50
from keras.api.keras.applications.resnet50 import preprocess_input
w, h = 224, 224
# 加载模型
encoder = ResNet50(include_top=False)
base_path = r"G:\datasets\lbxx"
# 获取所有图片路径
files = [os.path.join(base_path, file) for file in os.listdir(base_path)]
# 将图片转换成向量
embeddings = []
for file in files:
# 读取图片,转换成与目标图片同一尺寸
source = cv2.imread(file)
if not isinstance(source, np.ndarray):
continue
source = cv2.resize(source, (w, h))
embedding = encoder(preprocess_input(source[None]))
embeddings.append({
"filepath": file,
"embedding": tf.reshape(embedding, (-1,))
})
with open('embeddings.pkl', 'wb') as f:
pickle.dump(embeddings, f)
- 对所有向量进行聚类操作
这里可以使用sklearn完成:
from sklearn.cluster import KMeans
with open('embeddings.pkl', 'rb') as f:
embeddings = pickle.load(f)
X = [item['embedding'] for item in embeddings]
kmeans = KMeans(n_clusters=500)
kmeans.fit(X)
preds = kmeans.predict(X)
for item, pred in zip(embeddings, preds):
item['cluster'] = pred
joblib.dump(kmeans, 'kmeans.pkl')
with open('embeddings.pkl', 'wb') as f:
pickle.dump(embeddings, f)
如果图片数量比较多的话,这部分操作会比较耗时。然后调用kmeans.predict方法就可以知道某个图片属于哪个簇,这个也可以事先存储。
- 找到输入图片最近的簇中心
在训练完成后,就可以拿到所有簇中心:
kmeans.cluster_centers_
现在要做的就是找到与输入图片最近的簇中心,这个和前面的搜索一样:
# 查找最近的簇
closet_cluster = 0
closet_distance = sys.float_info.max
for idx, center in enumerate(centers):
distance = np.sum((target.numpy() - center) ** 2)
if distance < closet_distance:
closet_distance = distance
closet_cluster = idx
- 在当前簇中查找图片
这个和前面也是基本一样的:
distances = []
for item in embeddings:
if not item['cluster'] == closet_cluster:
continue
embedding = item['embedding']
distance = np.sum((target - embedding) ** 2)
distances.append((item['filepath'], distance))
# 对距离进行排序
distances = sorted(distances, key=lambda x: x[-1])[:11]
imgs = list(map(lambda x: cv2.imread(x[0]), distances))
result = np.hstack(imgs)
cv2.imwrite("result.jpg", result)
下面是一些搜索结果:



效果还是不错的,而且这次搜索速度快了许多。不过在编码上这种方式比较繁琐,为了让代码更简洁,下面引入向量数据库。
五、向量数据库
5.1 向量数据库
向量数据库和传统数据库不太一样,可以在数据库中存储向量字段,然后完成向量相似度检索。使用向量数据库可以很方便实现上面的检索功能,而且性能方面会比前面更佳。
向量数据库与传统数据库有很多相似的地方,在关系型数据库中,数据库分为连接、数据库、表、对象。在向量数据库中分别对应连接、数据库、集合、数据。集合中,可以添加embedding类型的字段,该字段可以用于向量检索。
5.2 Milvus向量数据库的使用
下面简单说一下Milvus向量数据库的使用,首先需要安装Milvus,执行下面两条执行即可:
wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo docker-compose up -d
下载完成后,需要连接数据库,代码如下:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='127.0.0.1', port='19530')
然后创建集合:
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='ids', max_length=500, is_primary=True,
auto_id=True),
FieldSchema(name='filepath', dtype=DataType.VARCHAR, description='filepath', max_length=512),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='embedding vectors', dim=dim),
]
schema = CollectionSchema(fields=fields, description='reverse image search')
collection = Collection(name=collection_name, schema=schema)
# create IVF_FLAT index for collection.
index_params = {
'metric_type': 'L2',
'index_type': "IVF_FLAT",
'params': {"nlist": 2048}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('images', 2048)
其中create_milvus_collection的第二个参数是embedding的维度,这里传入图片特征的维度。然后把图片特征存储到向量数据库中,这里需要注意维度不能超过32768,但是ResNet50返回的维度超过了这个限制,为此可以用PCA降维或者采用其它方法获取图片embedding。
import pickle
from sklearn.decomposition import PCA
with open('embeddings.pkl', 'rb') as f:
embeddings = pickle.load(f)
X = [item['embedding'] for item in embeddings]
pca = PCA(n_components=2048)
X = pca.fit_transform(X)
for item, vec in zip(embeddings, X):
item['embedding'] = vec
with open('embeddings.pkl', 'wb') as f:
pickle.dump(embeddings, f)
with open('pca.pkl', 'wb') as f:
pickle.dump(pca, f)
这样就可以插入数据了,代码如下:
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}
with open('embeddings.pkl', 'rb') as f:
embeddings = pickle.load(f)
base_path = r"G:\datasets\lbxx"
# 获取所有图片路径
files = [os.path.join(base_path, file) for file in os.listdir(base_path)]
for item in embeddings:
collection.insert([
[item['filepath']],
[item['embedding']]
])
现在如果想要搜索图片,只需要下面几行代码即可:
import os
import cv2
import joblib
import random
import numpy as np
import tensorflow as tf
from PIL import Image
from keras.api.keras.applications.resnet50 import ResNet50
from keras.api.keras.applications.resnet50 import preprocess_input
from pymilvus import connections, Collection
pca = joblib.load('pca.pkl')
w, h = 224, 224
encoder = ResNet50(include_top=False)
base_path = r"G:\datasets\lbxx"
files = [os.path.join(base_path, file) for file in os.listdir(base_path)]
target_path = random.choice(files)
target = cv2.resize(cv2.imread(target_path), (w, h))
target = encoder(preprocess_input(target[None]))
target = tf.reshape(target, (1, -1))
target = pca.transform(target)
# 连接数据库,加载images集合
connections.connect(host='127.0.0.1', port='19530')
collection = Collection(name='images')
search_params = {"metric_type": "L2", "params": {"nprobe": 10}, "offset": 5}
collection.load()
# 在数据库中搜索
results = collection.search(
data=[target[0]],
anns_field='embedding',
param=search_params,
output_fields=['filepath'],
limit=10,
consistency_level="Strong"
)
collection.release()
images = []
for result in results[0]:
entity = result.entity
filepath = entity.get('filepath')
image = cv2.resize(cv2.imread(filepath), (w, h))
images.append(np.array(image))
result = np.hstack(images)
cv2.imwrite("result.jpg", result)
下面是一些搜索结果,整体来看还是非常不错的,不过由于降维的关系,搜索效果可能或略差于前面,但是整体效率要高许多。



六、总结
本文我们分享了以图搜图的功能。主要思想就是将图片转换成向量表示,然后利用相似度计算,在图库中查找与之最接近的图片。最开始使用线性搜索的方式,此时查找效率最低。而后使用聚类进行改进,把把图片分成多个簇,把查找分为查找簇和查找最近图片两个步骤,可以大大提高查找效率。
改进后代码变得比较繁琐,于是引入向量数据库,使用向量数据库完成检索功能。这样就完成了整个程序的编写。









![[黑苹果EFI]Lenovo ThinkPad T490电脑 Hackintosh 黑苹果引导文件](https://img-blog.csdnimg.cn/189ebc1b34c64e26b7d5258c75c7a526.png)