scala分布式kmeans
- 1.分布式Kmeans算法设计思路
- 2.分布式Kmeans算法代码实现
- 2.1 Driver(主要负责分配、汇总数据)
- 2.2 Executor(主要负责计算)
- 2.3 Executor2(主要负责计算)
- 3.分布式Kmeans算法spark集群部署
- 3.1 将三个代码打成jar包上传到三个saprk节点上
- 3.2 第一个spark节点上运行Driver
- 3.3 第二个spark节点上运行Executor
- 3.4 第三个spark节点上运行Executor2
- 4.过程
- 4、spark上运行分布式kmeans源码:一个Driver,两个Executor训练5次
- 3、kmeans一个Driver,两个Executor训练5次
- 2、kmeans一个Driver,一个Executor训练5次
- 1、一个Driver,一个Executor
1.分布式Kmeans算法设计思路

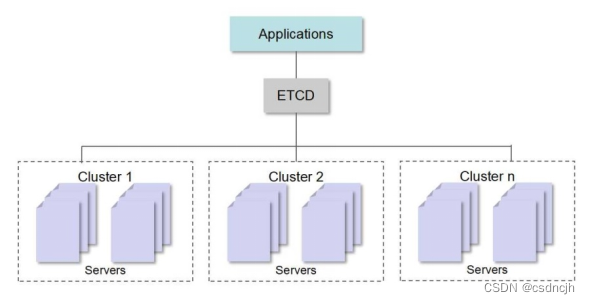
在分布式环境下,不能将所有数据都传给一个节点进行计算。需要将数据分成若干个分片,分别交给不同的节点进行计算,提高计算效率。同时,每个节点需要和Driver节点进行通信,用以实现发送和接收数据,以便实现分布式计算。在分布式kmeans算法中,Driver主要对数据进行划分、汇总,两个Executor主要进行计算。
1、Driver将样本坐标分为两部分给两个Executor计算,算出每个点距离最短的聚类中心,将该点划分给该聚类。
1.计算一:聚类划分
2.Executor划分的聚类:(0.0,0.0) -> List((1.0,1.0), (2.0,2.0), (3.0,3.0)), (7.0,7.0) -> List((4.0,4.0), (5.0,5.0), (6.0,6.0), (11.0,11.0))
3.Executor2划分的聚类:(0.0,0.0) -> List((0.0,0.0)), (7.0,7.0) -> List((12.0,12.0), (13.0,13.0), (14.0,14.0), (15.0,15.0), (16.0,16.0), (7.0,7.0))
2、两个Executor将更新后的聚类结果传给Driver,由Driver对聚类结果进行汇总。
1.整合后的聚类结果:(0.0,0.0) -> List((1.0,1.0), (2.0,2.0), (3.0,3.0), (0.0,0.0)), (7.0,7.0) -> List((4.0,4.0), (5.0,5.0), (6.0,6.0), (11.0,11.0), (12.0,12.0), (13.0,13.0), (14.0,14.0), (15.0,15.0), (16.0,16.0), (7.0,7.0))
3、Driver将聚类中心分为两部分给两个Executor计算,算出每个聚类中所有点x,y坐标的平均值作为新的聚类中心。
1.计算二:更新中心
2.划分中心点1_newClassified2_First:
3.(0.0,0.0): (1.0,1.0), (2.0,2.0), (3.0,3.0), (0.0,0.0)
4.划分中心点2_newClassified2_Second:
5.(7.0,7.0): (4.0,4.0), (5.0,5.0), (6.0,6.0), (11.0,11.0), (12.0,12.0), (13.0,13.0), (14.0,14.0), (15.0,15.0), (16.0,16.0), (7.0,7.0)
4、两个Executor将更新后的聚类中心传给Driver,由Driver对聚类中心进行汇总。
1.更新中心点1_Centroids_1: (1.5,1.5)
2.更新中心点2_Centroids_2: (10.3,10.3)
3.整合新中心点_centroids: (1.5,1.5), (10.3,10.3)
5、将更新后的聚类样本坐标和更新后的聚类中心重新迭代计算步骤1-4,迭代5次。
2.分布式Kmeans算法代码实现
2.1 Driver(主要负责分配、汇总数据)
1)定义聚类数据为datas,每个二元组表示一个点的坐标(xi, yi)。
2)为了分布式处理,需要将k-means算法的两个计算环节:聚类划分和更新聚类中心,分别部署在两个节点上并行执行,数据集会被切分为两个子集,交由两个不同的节点进行处理。
3)每个节点具有不同的IP地址和端口号,都会在自己的机器上启动socket,通过socket实现发送和接收数据。
4)聚类划分:Driver将聚类中心和切分后的样本坐标,发送给两个Executor节点进行计算,每个样本划分给距离最近的聚类,然后将划分的结果发送回Driver进行汇总。
5)更新聚类中心:将数据按照聚类中心切分成两部分,在两个Executor节点上进行计算,新的聚类中心是通过简单的平均计算获得的,计算完之后将结果传给Driver进行汇总。
6)完成计算后所有使用的 socket 都会被关闭。并更新聚类划分和聚类中心,进入下一次循环。
1.package com.atguigu.bigdata.spark.wc.jd_cs
2.import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
3.import java.net.Socket
4.object Driver {
5. def main(args: Array[String]): Unit = {
6. val datas = Seq(
7. (1.0, 1.0),
8. (2.0, 2.0),
9. (3.0, 3.0),
10. (4.0, 4.0),
11. (5.0, 5.0),
12. (6.0, 6.0),
13. (11.0, 11.0),
14. (12.0, 12.0),
15. (13.0, 13.0),
16. (14.0, 14.0),
17. (15.0, 15.0),
18. (16.0, 16.0),
19. (0.0, 0.0),
20. (7.0, 7.0)
21. )
22. var centroids = Seq((0.0, 0.0), (7.0, 7.0))
23. val datas1 = datas.take(7)
24. val datas2 = datas.takeRight(7)
25.
26. // 循环执行
27. var i = 0
28. while (i < 5) {
29. println("-------------------------")
30. println(s"第 ${i + 1} 次执行:")
31. println("-------------------------")
32. println("计算一:聚类划分")
33. //链接服务器("192.168.10.103",9999) ("localhost",9999)
34. val client1 = new Socket("localhost", 9999)
35. // out1发送数据、out1接收数据
36. val out1: OutputStream = client1.getOutputStream
37. val objOut1 = new ObjectOutputStream(out1)
38. objOut1.writeObject(datas1)
39. objOut1.writeObject(centroids)
40. val in_1: InputStream = client1.getInputStream
41. val objectin_1 = new ObjectInputStream(in_1)
42. val result_1 = objectin_1.readObject().asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
43. println(s"Executor划分的聚类:${result_1.mkString(", ")}")
44. //链接服务器("192.168.10.104",8888) ("localhost",9999)
45. val client2 = new Socket("localhost", 8888)
46. // out2发送数据、out2接收数据
47. val out2: OutputStream = client2.getOutputStream
48. val objOut2 = new ObjectOutputStream(out2)
49. objOut2.writeObject(datas2)
50. objOut2.writeObject(centroids)
51. val in_2: InputStream = client2.getInputStream
52. val objectin_2 = new ObjectInputStream(in_2)
53. val result_2 = objectin_2.readObject().asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
54. println(s"Executor2划分的聚类:${result_2.mkString(", ")}")
55. //整合out1和out2的数据
56. val newClassified2 = result_1.foldLeft(result_2) { case (classified, (center_1, points_1)) =>
57. val points_2 = classified.getOrElse(center_1, Seq.empty[(Double, Double)])
58. classified + (center_1 -> (points_1 ++ points_2))
59. }
60. println(s"整合后的聚类结果:${newClassified2.mkString(", ")}")
61.
62. println("计算二:更新中心")
63. val newClassified2_First = newClassified2.take(1) ++ newClassified2.drop(2)
64. println("划分中心点1_newClassified2_First: ")
65. newClassified2_First.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
66. val newClassified2_Second = newClassified2.tail
67. println("划分中心点2_newClassified2_Second: ")
68. newClassified2_Second.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
69. //计算2__1
70. val driverOut_1 = new ObjectOutputStream(client1.getOutputStream)
71. driverOut_1.writeObject(newClassified2_First)
72. driverOut_1.flush()
73. val finalCentroids_1 = objectin_1.readObject.asInstanceOf[Seq[(Double, Double)]]
74. println(s"更新中心点1_Centroids_1: ${finalCentroids_1.mkString(", ")}")
75. //计算2__2
76. val driverOut_2 = new ObjectOutputStream(client2.getOutputStream)
77. driverOut_2.writeObject(newClassified2_Second)
78. driverOut_2.flush()
79. val finalCentroids_2 = objectin_2.readObject.asInstanceOf[Seq[(Double, Double)]]
80. println(s"更新中心点2_Centroids_2: ${finalCentroids_2.mkString(", ")}")
81. val centroids1 = finalCentroids_1 ++ finalCentroids_2
82. centroids = centroids1
83. println(s"整合新中心点_centroids: ${centroids.mkString(", ")}")
84. //关闭链接
85. objOut1.flush()
86. objOut1.close()
87. client1.close()
88. objOut2.flush()
89. objOut2.close()
90. client2.close()
91. println("客户端数据发送完毕")
92. // 计数器加一
93. i += 1
94. }
95. }
96.}
2.2 Executor(主要负责计算)
1)distance函数:计算两个点之间的直线距离。
2)classify函数:根据当前的数据点和聚类中心,将数据点分类到距离最小的聚类中心中去,返回一个Map,键为聚类中心点,值为该聚类中心点对应的数据点集合。
3)updateCentroids函数:该函数将一个聚类中心和聚类中心序列作为输入,将更新后的聚类中心作为输出。对每个聚类中心,找到属于它的所有点,然后计算这些点的平均值,作为更新的聚类中心坐标。
4)在main函数中,程序首先在while循环中等待来自Driver的数据。一旦接收到数据,程序运行classify函数,并将聚类划分结果返回给Driver。Driver汇总聚类划分结果后,重新发送最新的聚类划分。main函数接收Driver发送的新的聚类划分,重新计算每个聚类中心点的坐标,最终将更新后的聚类中心坐标发送给Driver进行汇总,并进入下一个循环。
1.package com.atguigu.bigdata.spark.wc.jd_cs
2.import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
3.import java.net.{ServerSocket, Socket}
4.object Executor {
5. def distance(p1: (Double, Double), p2: (Double, Double)): Double = {
6. Math.sqrt(Math.pow(p1._1 - p2._1, 2.0) + Math.pow(p1._2 - p2._2, 2.0))
7. }
8. def classify(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Map[(Double, Double), Seq[(Double, Double)]] = {
9. val grouped = points.groupBy { point =>
10. centroids.minBy { centroid =>
11. distance(point,centroid)
12. }
13. }
14. centroids.map { centroid =>
15. centroid -> grouped.getOrElse(centroid, Seq())
16. }.toMap
17. }
18. def updateCentroids(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Seq[(Double, Double)] = {
19. centroids.map { centroid =>
20. val clusteredPoints = points.filter { point =>
21. classify(Seq(point), centroids)(centroid).nonEmpty
22. }
23. val sumX = clusteredPoints.map(_._1).sum
24. val sumY = clusteredPoints.map(_._2).sum
25. val count = clusteredPoints.length
26. (sumX / count, sumY / count)
27. }
28. }
29. def main(args: Array[String]): Unit = {
30. while (true) {
31. //启动服务器接收数据
32. val server = new ServerSocket(9999)
33. println("服务器9999启动,等待接受数据")
34. //等待客户端的链接
35. val client: Socket = server.accept()
36. val in: InputStream = client.getInputStream
37. val objectin = new ObjectInputStream(in)
38. val datas = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
39. val centroids = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
40. var classified = classify(datas, centroids)
41. val out: OutputStream = client.getOutputStream
42. val objectOut = new ObjectOutputStream(out)
43. objectOut.writeObject(classified)
44. objectOut.flush()
45. // 接收来自 Driver 的 classified 数据
46. val driverIn = new ObjectInputStream(client.getInputStream)
47. val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
48. classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
49. println("接收到 Driver 发来的 classified 数据")
50. // 使用 Driver 发来的 classified 数据计算最终结果
51. var updatedCentroids = updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
52. //classified = Task.classify(task.points, updatedCentroids)
53. // 返回计算结果
54. objectOut.writeObject(updatedCentroids)
55. objectOut.flush()
56. in.close()
57. objectin.close()
58. objectOut.close()
59. client.close()
60. server.close()
61. }
62. }
63.}
2.3 Executor2(主要负责计算)
Executor2和Executor计算方式完全一样,只是ip和端口号不同。
1.package com.atguigu.bigdata.spark.wc.jd_cs
2.import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
3.import java.net.{ServerSocket, Socket}
4.object Executor2 {
5. def distance(p1: (Double, Double), p2: (Double, Double)): Double = {
6. Math.sqrt(Math.pow(p1._1 - p2._1, 2.0) + Math.pow(p1._2 - p2._2, 2.0))
7. }
8. def classify(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Map[(Double, Double), Seq[(Double, Double)]] = {
9. val grouped = points.groupBy { point =>
10. centroids.minBy { centroid =>
11. distance(point,centroid)
12. }
13. }
14. centroids.map { centroid =>
15. centroid -> grouped.getOrElse(centroid, Seq())
16. }.toMap
17. }
18. def updateCentroids(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Seq[(Double, Double)] = {
19. centroids.map { centroid =>
20. val clusteredPoints = points.filter { point =>
21. classify(Seq(point), centroids)(centroid).nonEmpty
22. }
23. val sumX = clusteredPoints.map(_._1).sum
24. val sumY = clusteredPoints.map(_._2).sum
25. val count = clusteredPoints.length
26. (sumX / count, sumY / count)
27. }
28. }
29. def main(args: Array[String]): Unit = {
30. while (true) {
31. //启动服务器接收数据
32. val server = new ServerSocket(8888)
33. println("服务器8888启动,等待接受数据")
34. //等待客户端的链接
35. val client: Socket = server.accept()
36. val in: InputStream = client.getInputStream
37. val objectin = new ObjectInputStream(in)
38. val datas = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
39. val centroids = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
40. var classified = classify(datas, centroids)
41. val out: OutputStream = client.getOutputStream
42. val objectOut = new ObjectOutputStream(out)
43. objectOut.writeObject(classified)
44. objectOut.flush()
45. // 接收来自 Driver 的 classified 数据
46. val driverIn = new ObjectInputStream(client.getInputStream)
47. val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
48. classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
49. println("接收到 Driver 发来的 classified 数据")
50. // 使用 Driver 发来的 classified 数据计算最终结果
51. var updatedCentroids = updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
52. //classified = Task.classify(task.points, updatedCentroids)
53. // 返回计算结果
54. objectOut.writeObject(updatedCentroids)
55. objectOut.flush()
56.
57. in.close()
58. objectin.close()
59. objectOut.close()
60. client.close()
61. server.close()
62. }
63. }
64.}
3.分布式Kmeans算法spark集群部署
3.1 将三个代码打成jar包上传到三个saprk节点上

将上述三个代码在idea中打成jar包。分别部署到三个saprk节点上,分别由spark-submit执行。
3.2 第一个spark节点上运行Driver


3.3 第二个spark节点上运行Executor

3.4 第三个spark节点上运行Executor2

4.过程
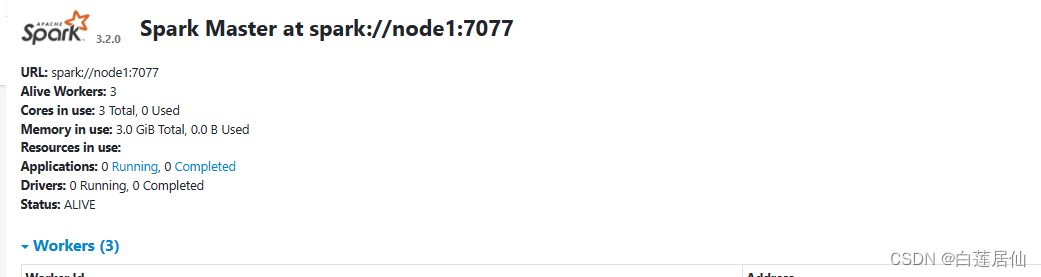
4、spark上运行分布式kmeans源码:一个Driver,两个Executor训练5次
./bin/spark-submit --class com.atguigu.bigdata.spark.wc.jd_cs.Driver --master spark://192.168.10.102:7077 --executor-memory 1g --total-executor-cores 1 /home/gpb/Driver.jar
./bin/spark-submit --class com.atguigu.bigdata.spark.wc.jd_cs.Executor --master spark://192.168.10.103:7077 --executor-memory 1g --total-executor-cores 1 /home/gpb/Executor.jar
./bin/spark-submit --class com.atguigu.bigdata.spark.wc.jd_cs.Executor2 --master spark://192.168.10.104:7077 --executor-memory 1g --total-executor-cores 1 /home/gpb/Executor2.jar
package com.atguigu.bigdata.spark.wc.jd_cs
import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
val datas = Seq(
(1.0, 1.0),
(2.0, 2.0),
(3.0, 3.0),
(4.0, 4.0),
(5.0, 5.0),
(6.0, 6.0),
(11.0, 11.0),
(12.0, 12.0),
(13.0, 13.0),
(14.0, 14.0),
(15.0, 15.0),
(16.0, 16.0),
(0.0, 0.0),
(7.0, 7.0)
)
var centroids = Seq((0.0, 0.0), (7.0, 7.0))
val datas1 = datas.take(7)
val datas2 = datas.takeRight(7)
// 循环执行
var i = 0
while (i < 5) {
println("-------------------------")
println(s"第 ${i + 1} 次执行:")
println("-------------------------")
println("计算一:划分中心")
//链接服务器("192.168.10.103",9999) ("localhost",9999)
val client1 = new Socket("192.168.10.103", 9999)
// out1发送数据、out1接收数据
val out1: OutputStream = client1.getOutputStream
val objOut1 = new ObjectOutputStream(out1)
objOut1.writeObject(datas1)
objOut1.writeObject(centroids)
val in_1: InputStream = client1.getInputStream
val objectin_1 = new ObjectInputStream(in_1)
val result_1 = objectin_1.readObject().asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
println(s"Executor收到的数据:${result_1.mkString(", ")}")
//链接服务器("192.168.10.104",8888) ("localhost",9999)
val client2 = new Socket("192.168.10.104", 8888)
// out2发送数据、out2接收数据
val out2: OutputStream = client2.getOutputStream
val objOut2 = new ObjectOutputStream(out2)
objOut2.writeObject(datas2)
objOut2.writeObject(centroids)
val in_2: InputStream = client2.getInputStream
val objectin_2 = new ObjectInputStream(in_2)
val result_2 = objectin_2.readObject().asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
println(s"Executor2收到的数据:${result_2.mkString(", ")}")
//整合out1和out2的数据
val newClassified2 = result_1.foldLeft(result_2) { case (classified, (center_1, points_1)) =>
val points_2 = classified.getOrElse(center_1, Seq.empty[(Double, Double)])
classified + (center_1 -> (points_1 ++ points_2))
}
println(s"整合后的newClassified2:${newClassified2.mkString(", ")}")
println("计算二:更新中心")
val newClassified2_First = newClassified2.take(1) ++ newClassified2.drop(2)
println("划分中心点1_newClassified2_First: ")
newClassified2_First.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
val newClassified2_Second = newClassified2.tail
println("划分中心点2_newClassified2_Second: ")
newClassified2_Second.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
//计算2__1
val driverOut_1 = new ObjectOutputStream(client1.getOutputStream)
driverOut_1.writeObject(newClassified2_First)
driverOut_1.flush()
val finalCentroids_1 = objectin_1.readObject.asInstanceOf[Seq[(Double, Double)]]
println(s"更新中心点1_finalCentroids_1: ${finalCentroids_1.mkString(", ")}")
//计算2__2
val driverOut_2 = new ObjectOutputStream(client2.getOutputStream)
driverOut_2.writeObject(newClassified2_Second)
driverOut_2.flush()
val finalCentroids_2 = objectin_2.readObject.asInstanceOf[Seq[(Double, Double)]]
println(s"更新中心点2_finalCentroids_2: ${finalCentroids_2.mkString(", ")}")
val centroids1 = finalCentroids_1 ++ finalCentroids_2
centroids = centroids1
println(s"整合新中心点_centroids: ${centroids.mkString(", ")}")
//关闭链接
objOut1.flush()
objOut1.close()
client1.close()
objOut2.flush()
objOut2.close()
client2.close()
println("客户端数据发送完毕")
// 计数器加一
i += 1
}
}
}
package com.atguigu.bigdata.spark.wc.jd_cs
import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
import java.net.{ServerSocket, Socket}
object Executor {
def distance(p1: (Double, Double), p2: (Double, Double)): Double = {
Math.sqrt(Math.pow(p1._1 - p2._1, 2.0) + Math.pow(p1._2 - p2._2, 2.0))
}
def classify(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Map[(Double, Double), Seq[(Double, Double)]] = {
val grouped = points.groupBy { point =>
centroids.minBy { centroid =>
distance(point,centroid)
}
}
centroids.map { centroid =>
centroid -> grouped.getOrElse(centroid, Seq())
}.toMap
}
def updateCentroids(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Seq[(Double, Double)] = {
centroids.map { centroid =>
val clusteredPoints = points.filter { point =>
classify(Seq(point), centroids)(centroid).nonEmpty
}
val sumX = clusteredPoints.map(_._1).sum
val sumY = clusteredPoints.map(_._2).sum
val count = clusteredPoints.length
(sumX / count, sumY / count)
}
}
def main(args: Array[String]): Unit = {
while (true) {
//启动服务器接收数据
val server = new ServerSocket(9999)
println("服务器9999启动,等待接受数据")
//等待客户端的链接
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objectin = new ObjectInputStream(in)
val datas = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
val centroids = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
var classified = classify(datas, centroids)
val out: OutputStream = client.getOutputStream
val objectOut = new ObjectOutputStream(out)
objectOut.writeObject(classified)
objectOut.flush()
// 接收来自 Driver 的 classified 数据
val driverIn = new ObjectInputStream(client.getInputStream)
val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
println("接收到 Driver 发来的 classified 数据")
// 使用 Driver 发来的 classified 数据计算最终结果
var updatedCentroids = updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
//classified = Task.classify(task.points, updatedCentroids)
// 返回计算结果
objectOut.writeObject(updatedCentroids)
objectOut.flush()
in.close()
objectin.close()
objectOut.close()
client.close()
server.close()
}
}
}
package com.atguigu.bigdata.spark.wc.jd_cs
import java.io.{InputStream, ObjectInputStream, ObjectOutputStream, OutputStream}
import java.net.{ServerSocket, Socket}
object Executor2 {
def distance(p1: (Double, Double), p2: (Double, Double)): Double = {
Math.sqrt(Math.pow(p1._1 - p2._1, 2.0) + Math.pow(p1._2 - p2._2, 2.0))
}
def classify(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Map[(Double, Double), Seq[(Double, Double)]] = {
val grouped = points.groupBy { point =>
centroids.minBy { centroid =>
distance(point,centroid)
}
}
centroids.map { centroid =>
centroid -> grouped.getOrElse(centroid, Seq())
}.toMap
}
def updateCentroids(points: Seq[(Double, Double)], centroids: Seq[(Double, Double)]): Seq[(Double, Double)] = {
centroids.map { centroid =>
val clusteredPoints = points.filter { point =>
classify(Seq(point), centroids)(centroid).nonEmpty
}
val sumX = clusteredPoints.map(_._1).sum
val sumY = clusteredPoints.map(_._2).sum
val count = clusteredPoints.length
(sumX / count, sumY / count)
}
}
def main(args: Array[String]): Unit = {
while (true) {
//启动服务器接收数据
val server = new ServerSocket(8888)
println("服务器8888启动,等待接受数据")
//等待客户端的链接
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objectin = new ObjectInputStream(in)
val datas = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
val centroids = objectin.readObject().asInstanceOf[Seq[(Double, Double)]]
var classified = classify(datas, centroids)
val out: OutputStream = client.getOutputStream
val objectOut = new ObjectOutputStream(out)
objectOut.writeObject(classified)
objectOut.flush()
// 接收来自 Driver 的 classified 数据
val driverIn = new ObjectInputStream(client.getInputStream)
val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[(Double, Double), Seq[(Double, Double)]]]
classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
println("接收到 Driver 发来的 classified 数据")
// 使用 Driver 发来的 classified 数据计算最终结果
var updatedCentroids = updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
//classified = Task.classify(task.points, updatedCentroids)
// 返回计算结果
objectOut.writeObject(updatedCentroids)
objectOut.flush()
in.close()
objectin.close()
objectOut.close()
client.close()
server.close()
}
}
}
3、kmeans一个Driver,两个Executor训练5次
package com.atguigu.bigdata.spark.wc.test3
import java.io.{ObjectInputStream, ObjectOutputStream}
import java.net.Socket
import scala.collection.mutable
object Driver {
def main(args: Array[String]): Unit = {
// 定义任务和初始聚类中心
val task = Task(Seq(
Point(1.0, 1.0),
Point(2.0, 2.0),
Point(3.0, 3.0),
Point(4.0, 4.0),
Point(5.0, 5.0),
Point(6.0, 6.0),
Point(11.0, 11.0),
Point(12.0, 12.0),
Point(13.0, 13.0),
Point(14.0, 14.0),
Point(15.0, 15.0),
Point(16.0, 16.0),
Point(0.0, 0.0),
Point(7.0, 7.0)
), 2, 10)
val task_1 = Task(task.points.take(7), 2, 10)
val task_2 = Task(task.points.takeRight(7), 2, 10)
var centroids_1 = Seq(
Point(0.0, 0.0),
Point(7.0, 7.0)
)
var centroids_2 = Seq(
Point(0.0, 0.0),
Point(7.0, 7.0)
)
// 循环执行
var i = 0
while (i < 5) {
println(s"第 ${i+1} 次执行:")
// 连接 Executor,进行第一轮分类
val client_1 = new Socket("localhost",9999)
val client_2 = new Socket("localhost",8888)
//计算1__1
val objOut_1 = new ObjectOutputStream(client_1.getOutputStream)
objOut_1.writeObject(task_1)
objOut_1.flush()
val objOut_cent_1 = new ObjectOutputStream(client_1.getOutputStream)
println(s"centroids: ${centroids_1.mkString(", ")}")
objOut_cent_1.writeObject(centroids_1)
objOut_cent_1.flush()
// 接收计算结果
val objIn_1 = new ObjectInputStream(client_1.getInputStream)
val classified_1 = objIn_1.readObject.asInstanceOf[Map[Point, Seq[Point]]]
println("objOut_cent_1: ")
classified_1.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
//计算1__2
val objOut_2 = new ObjectOutputStream(client_2.getOutputStream)
objOut_2.writeObject(task_2)
objOut_2.flush()
val objOut_cent_2 = new ObjectOutputStream(client_2.getOutputStream)
println(s"centroids: ${centroids_2.mkString(", ")}")
objOut_cent_2.writeObject(centroids_2)
objOut_cent_2.flush()
// 接收计算结果
val objIn_2 = new ObjectInputStream(client_2.getInputStream)
val classified_2 = objIn_2.readObject.asInstanceOf[Map[Point, Seq[Point]]]
println("classified_2: ")
classified_2.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
val newClassified2 = classified_1.foldLeft(classified_2) { case (classified, (center_1, points_1)) =>
val points_2 = classified.getOrElse(center_1, Seq.empty[Point])
classified + (center_1 -> (points_1 ++ points_2))
}
println("整合classified_2: ")
newClassified2.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
val newClassified2_First = newClassified2.take(1) ++ newClassified2.drop(2)
println("整合newClassified2_First: ")
newClassified2_First.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
val newClassified2_Second = newClassified2.tail
println("整合newClassified2_Second: ")
newClassified2_Second.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
//需要将整合后的classified,根据中心点分为两个在Executor和Executor2上计算
//计算2__1
val driverOut_1 = new ObjectOutputStream(client_1.getOutputStream)
driverOut_1.writeObject(newClassified2_First)
driverOut_1.flush()
// 接收最终结果
val finalCentroids_1 = objIn_1.readObject.asInstanceOf[Seq[Point]]
println(s"Final finalCentroids_1: ${finalCentroids_1.mkString(", ")}")
centroids_1 = finalCentroids_1
//计算2__2
val driverOut_2 = new ObjectOutputStream(client_2.getOutputStream)
driverOut_2.writeObject(newClassified2_Second)
driverOut_2.flush()
// 接收最终结果
val finalCentroids_2 = objIn_2.readObject.asInstanceOf[Seq[Point]]
println(s"Final finalCentroids_2: ${finalCentroids_2.mkString(", ")}")
centroids_2 = finalCentroids_2
val centroids = centroids_1 ++ centroids_2
centroids_1 = centroids
println(s"合并后的 finalCentroids_1: ${centroids_1.mkString(", ")}")
centroids_2 = centroids
println(s"合并后的 finalCentroids_2: ${centroids_2.mkString(", ")}")
// 关闭资源
driverOut_1.close()
objOut_1.close()
objIn_1.close()
client_1.close()
// 关闭资源
driverOut_2.close()
objOut_2.close()
objIn_2.close()
client_2.close()
println("计算完成,连接关闭")
// 计数器加一
i += 1
}
}
}
package com.atguigu.bigdata.spark.wc.test3
import java.io.{ObjectInputStream, ObjectOutputStream}
import java.net.ServerSocket
object Executor {
def main(args: Array[String]): Unit = {
while (true) {
val server = new ServerSocket(9999)
println("服务器[9999]启动,等待连接...")
val client = server.accept()
println("[9999]连接建立,接收数据...")
// 读取 Task 对象进行 js1 计算
val objIn = new ObjectInputStream(client.getInputStream)
val task = objIn.readObject.asInstanceOf[Task]
val objIn_cent = new ObjectInputStream(client.getInputStream)
val centroids = objIn_cent.readObject().asInstanceOf[Seq[Point]]
println(s"centroids: ${centroids.mkString(", ")}")
var classified = Task.classify(task.points, centroids)
// 返回计算结果的 Map[Point, Seq[Point]]
val objOut = new ObjectOutputStream(client.getOutputStream)
objOut.writeObject(classified)
objOut.flush()
// 接收来自 Driver 的 classified 数据
val driverIn = new ObjectInputStream(client.getInputStream)
val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[Point, Seq[Point]]]
classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
println("接收到 Driver 发来的 classified 数据")
// 使用 Driver 发来的 classified 数据计算最终结果
var updatedCentroids = Task.updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
//classified = Task.classify(task.points, updatedCentroids)
// 返回计算结果
objOut.writeObject(updatedCentroids)
objOut.flush()
// 关闭资源
objOut.close()
objIn.close()
driverIn.close()
client.close()
server.close()
println("计算[9999]结果已返回,连接关闭")
}
}
}
package com.atguigu.bigdata.spark.wc.test3
import java.io.{ObjectInputStream, ObjectOutputStream}
import java.net.ServerSocket
object Executor2 {
def main(args: Array[String]): Unit = {
while (true) {
val server = new ServerSocket(8888)
println("服务器[8888]启动,等待连接...")
val client = server.accept()
println("[8888]连接建立,接收数据...")
// 读取 Task 对象进行 js1 计算
val objIn = new ObjectInputStream(client.getInputStream)
val task = objIn.readObject.asInstanceOf[Task]
val objIn_cent = new ObjectInputStream(client.getInputStream)
val centroids = objIn_cent.readObject().asInstanceOf[Seq[Point]]
println(s"centroids: ${centroids.mkString(", ")}")
var classified = Task.classify(task.points, centroids)
// 返回计算结果的 Map[Point, Seq[Point]]
val objOut = new ObjectOutputStream(client.getOutputStream)
objOut.writeObject(classified)
objOut.flush()
// 接收来自 Driver 的 classified 数据
val driverIn = new ObjectInputStream(client.getInputStream)
val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[Point, Seq[Point]]]
classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
println("接收到 Driver 发来的 classified 数据")
// 使用 Driver 发来的 classified 数据计算最终结果
var updatedCentroids = Task.updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
//classified = Task.classify(task.points, updatedCentroids)
// 返回计算结果
objOut.writeObject(updatedCentroids)
objOut.flush()
// 关闭资源
objOut.close()
objIn.close()
driverIn.close()
client.close()
server.close()
println("计算[8888]结果已返回,连接关闭")
}
}
}
package com.atguigu.bigdata.spark.wc.test3
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.concurrent._
import scala.concurrent.duration._
import scala.concurrent.ExecutionContext.Implicits.global
import com.atguigu.bigdata.spark.wc.ParallelKMeans.Point
case class Point(x: Double, y: Double)
case class Task(points: Seq[Point], k: Int, iterations: Int) extends Serializable
object Task {
def distance(p1: Point, p2: Point): Double = {
Math.sqrt(Math.pow(p1.x - p2.x, 2) + Math.pow(p1.y - p2.y, 2))
}
def classify(points: Seq[Point], centroids: Seq[Point]): Map[Point, Seq[Point]] = {
val grouped = points.groupBy { point =>
centroids.minBy { centroid =>
distance(point, centroid)
}
}
centroids.map { centroid =>
centroid -> grouped.getOrElse(centroid, Seq())
}.toMap
}
def updateCentroids(points: Seq[Point], centroids: Seq[Point]): Seq[Point] = {
centroids.map { centroid =>
val clusteredPoints = points.filter { point =>
classify(Seq(point), centroids)(centroid).nonEmpty
}
val sumX = clusteredPoints.map(_.x).sum
val sumY = clusteredPoints.map(_.y).sum
val count = clusteredPoints.length
Point(sumX / count, sumY / count)
}
}
def js1(points: Seq[Point], k: Int, iterations: Int): Map[Point, Seq[Point]] = {
if (k <= 0 || iterations <= 0) {
Map()
} else {
// 从点集points中取出前k个点作为初始聚类中心点
var centroids = points.take(k)
var classified = classify(points, centroids)
classified.foreach { case (center, clusteredPoints) =>
println(s"Center: $center, Points: $clusteredPoints")
}
centroids = classified.keys.toSeq
classified = classify(points, centroids)
classified
}
}
def js2(classified: Map[Point, Seq[Point]]): Seq[Point] = {
val centroids = classified.keys.toSeq
val updatedCentroids = updateCentroids(classified.values.flatten.toSeq, centroids)
updatedCentroids
}
}
2、kmeans一个Driver,一个Executor训练5次
package com.atguigu.bigdata.spark.wc.test3
import java.io.{ObjectInputStream, ObjectOutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
// 定义任务和初始聚类中心
val task = Task(Seq(
Point(1.0, 1.0),
Point(2.0, 2.0),
Point(3.0, 3.0),
Point(4.0, 4.0),
Point(5.0, 5.0),
Point(6.0, 6.0),
Point(11.0, 11.0),
Point(12.0, 12.0),
Point(13.0, 13.0),
Point(14.0, 14.0),
Point(15.0, 15.0),
Point(16.0, 16.0),
Point(0.0, 0.0),
Point(7.0, 7.0)
), 2, 10)
var centroids = Seq(
Point(0.0, 0.0),
Point(7.0, 7.0)
)
// 循环执行
var i = 0
while (i < 5) {
println(s"第 ${i+1} 次执行:")
// 连接 Executor,进行第一轮分类
val client = new Socket("localhost", 9999)
//计算1
val objOut = new ObjectOutputStream(client.getOutputStream)
objOut.writeObject(task)
objOut.flush()
val objOut_cent = new ObjectOutputStream(client.getOutputStream)
println(s"Final centroids: ${centroids.mkString(", ")}")
objOut_cent.writeObject(centroids)
objOut_cent.flush()
// 接收计算结果
val objIn = new ObjectInputStream(client.getInputStream)
val classified = objIn.readObject.asInstanceOf[Map[Point, Seq[Point]]]
println("Centroids: ")
classified.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
//计算2
// 将 classified 数据发送给 Executor
val driverOut = new ObjectOutputStream(client.getOutputStream)
driverOut.writeObject(classified)
driverOut.flush()
// 接收最终结果
val finalCentroids = objIn.readObject.asInstanceOf[Seq[Point]]
println(s"Final centroids: ${finalCentroids.mkString(", ")}")
centroids = finalCentroids
// 关闭资源
driverOut.close()
objOut.close()
objIn.close()
client.close()
println("计算完成,连接关闭")
// 计数器加一
i += 1
}
}
}
package com.atguigu.bigdata.spark.wc.test3
import java.io.{ObjectInputStream, ObjectOutputStream}
import java.net.ServerSocket
object Executor {
def main(args: Array[String]): Unit = {
while (true) {
val server = new ServerSocket(9999)
println("服务器启动,等待连接...")
val client = server.accept()
println("连接建立,接收数据...")
// 读取 Task 对象进行 js1 计算
val objIn = new ObjectInputStream(client.getInputStream)
val task = objIn.readObject.asInstanceOf[Task]
val objIn_cent = new ObjectInputStream(client.getInputStream)
val centroids = objIn_cent.readObject().asInstanceOf[Seq[Point]]
println(s"centroids: ${centroids.mkString(", ")}")
var classified = Task.classify(task.points, centroids)
// 返回计算结果的 Map[Point, Seq[Point]]
val objOut = new ObjectOutputStream(client.getOutputStream)
objOut.writeObject(classified)
objOut.flush()
// 接收来自 Driver 的 classified 数据
val driverIn = new ObjectInputStream(client.getInputStream)
val classifiedFromDriver = driverIn.readObject.asInstanceOf[Map[Point, Seq[Point]]]
classifiedFromDriver.foreach(entry => println(s"${entry._1}: ${entry._2.mkString(", ")}"))
println("接收到 Driver 发来的 classified 数据")
// 使用 Driver 发来的 classified 数据计算最终结果
var updatedCentroids = Task.updateCentroids(classifiedFromDriver.values.flatten.toSeq, classifiedFromDriver.keys.toSeq)
classified = Task.classify(task.points, updatedCentroids)
// 返回计算结果
objOut.writeObject(updatedCentroids)
objOut.flush()
// 关闭资源
objOut.close()
objIn.close()
driverIn.close()
client.close()
server.close()
println("计算结果已返回,连接关闭")
}
}
}
package com.atguigu.bigdata.spark.wc.test3
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.concurrent._
import scala.concurrent.duration._
import scala.concurrent.ExecutionContext.Implicits.global
import com.atguigu.bigdata.spark.wc.ParallelKMeans.Point
case class Point(x: Double, y: Double)
case class Task(points: Seq[Point], k: Int, iterations: Int) extends Serializable
object Task {
def distance(p1: Point, p2: Point): Double = {
Math.sqrt(Math.pow(p1.x - p2.x, 2) + Math.pow(p1.y - p2.y, 2))
}
def classify(points: Seq[Point], centroids: Seq[Point]): Map[Point, Seq[Point]] = {
val grouped = points.groupBy { point =>
centroids.minBy { centroid =>
distance(point, centroid)
}
}
centroids.map { centroid =>
centroid -> grouped.getOrElse(centroid, Seq())
}.toMap
}
def updateCentroids(points: Seq[Point], centroids: Seq[Point]): Seq[Point] = {
centroids.map { centroid =>
val clusteredPoints = points.filter { point =>
classify(Seq(point), centroids)(centroid).nonEmpty
}
val sumX = clusteredPoints.map(_.x).sum
val sumY = clusteredPoints.map(_.y).sum
val count = clusteredPoints.length
Point(sumX / count, sumY / count)
}
}
def js1(points: Seq[Point], k: Int, iterations: Int): Map[Point, Seq[Point]] = {
if (k <= 0 || iterations <= 0) {
Map()
} else {
// 从点集points中取出前k个点作为初始聚类中心点
var centroids = points.take(k)
var classified = classify(points, centroids)
classified.foreach { case (center, clusteredPoints) =>
println(s"Center: $center, Points: $clusteredPoints")
}
centroids = classified.keys.toSeq
classified = classify(points, centroids)
classified
}
}
def js2(classified: Map[Point, Seq[Point]]): Seq[Point] = {
val centroids = classified.keys.toSeq
val updatedCentroids = updateCentroids(classified.values.flatten.toSeq, centroids)
updatedCentroids
}
}
1、一个Driver,一个Executor
package com.atguigu.bigdata.spark.wc.test2
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.concurrent._
import scala.concurrent.duration._
import scala.concurrent.ExecutionContext.Implicits.global
import com.atguigu.bigdata.spark.wc.ParallelKMeans.Point
case class Point(x: Double, y: Double)
case class Task(points: Seq[Point], k: Int, iterations: Int) extends Serializable
object Task {
def distance(p1: Point, p2: Point): Double = {
Math.sqrt(Math.pow(p1.x - p2.x, 2) + Math.pow(p1.y - p2.y, 2))
}
def classify(points: Seq[Point], centroids: Seq[Point]): Map[Point, Seq[Point]] = {
val grouped = points.groupBy { point =>
centroids.minBy { centroid =>
distance(point, centroid)
}
}
centroids.map { centroid =>
centroid -> grouped.getOrElse(centroid, Seq())
}.toMap
}
def updateCentroids(points: Seq[Point], centroids: Seq[Point]): Seq[Point] = {
centroids.map { centroid =>
val clusteredPoints = points.filter { point =>
classify(Seq(point), centroids)(centroid).nonEmpty
}
val sumX = clusteredPoints.map(_.x).sum
val sumY = clusteredPoints.map(_.y).sum
val count = clusteredPoints.length
Point(sumX / count, sumY / count)
}
}
def parallelKMeans(points: Seq[Point], k: Int, iterations: Int): Seq[Point] = {
if (k <= 0 || iterations <= 0) {
Seq()
} else {
// 从点集points中取出前k个点作为初始聚类中心点
var centroids = points.take(k)
for (i <- 1 to iterations) {
val classified = classify(points, centroids)
classified.foreach { case (center, clusteredPoints) =>
println(s"Center: $center, Points: $clusteredPoints")
}
println("-----------------------")
val futureCentroids = Future.sequence {
centroids.map { centroid =>
Future {
val clusteredPoints = classified(centroid)
val sumX = clusteredPoints.map(_.x).sum
val sumY = clusteredPoints.map(_.y).sum
val count = clusteredPoints.length
Point(sumX / count, sumY / count)
}
}
}
centroids = Await.result(futureCentroids, Duration.Inf)
}
centroids
}
}
}
package com.atguigu.bigdata.spark.wc.test2
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
// 创建 Task 对象
val task = Task(Seq(
Point(1.0, 1.0),
Point(1.0, 2.0),
Point(2.0, 2.0),
Point(8.0, 8.0),
Point(9.0, 8.0),
Point(8.0, 9.0)
), 2, 10)
// 连接 Executor
val client = new Socket("localhost", 9999)
val out: OutputStream = client.getOutputStream
val objOut = new ObjectOutputStream(out)
objOut.writeObject(task)
objOut.flush()
objOut.close()
client.close()
println("数据已发送到 Executor")
}
}
package com.atguigu.bigdata.spark.wc.test2
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
object Executor {
def main(args: Array[String]): Unit = {
// 启动服务器接收数据
val server = new ServerSocket(9999)
println("服务器启动,等待接收数据...")
val client = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
// 读取 Task 对象
val task = objIn.readObject.asInstanceOf[Task]
// 执行 Task 中的计算逻辑
val centroids = Task.parallelKMeans(task.points, task.k, task.iterations)
println(s"Parallel centroids: $centroids")
// 关闭连接,释放资源
objIn.close()
client.close()
server.close()
}
}