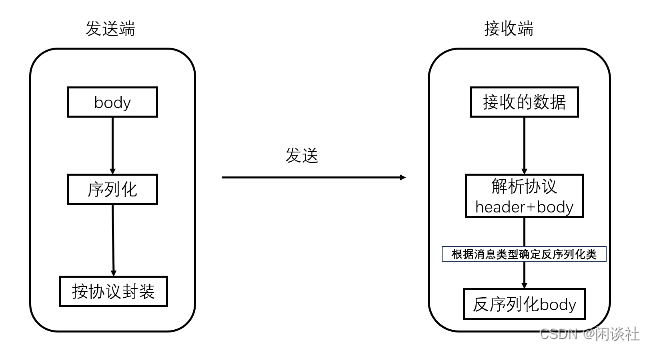
文章目录
- 一、协议概述
- 二、消息的完整性
- 三、协议设计
- 3.1 协议设计实例
- IM即时通讯的协议设计
- nginx协议
- HTTP协议
- redis协议
- 3.2 序列化方法
- 3.3 协议安全
- 3.4 协议压缩
- 3.5 协议升级
- 四、Protobuf
- 4.1 安装编译
- 4.2 工作流程
- 4.3 标量数值类型
- 4.4 编码原理
- 4.4.1 Varints 编码
- 4.4.2 Zigzag 编码
- 4.5 数据组织
- 4.6 总结
一、协议概述
协议是一种约定,通过约定,不同的进程可以对⼀段数据产生相同的理解,从而可以相互协作,存在进程间通信的程序就⼀定需要协议。

比如不同表的插头,需要根据不同的国标进行各种转换。如果我们两端进行通信没有约定好协议,那彼此是不知道对方发送的数据是什么意义。
二、消息的完整性
判断消息的完整性,关键在于区分消息的边界。为了能让对端知道如何给消息帧分界,目前⼀般有以下做法:
1)以特定符号来分界。如每个消息都以特定的字符来结尾(如\r\n),当在字节流中读取到该字符时,则表明上⼀个消息到此为止。
2)固定消息头+消息体结构。这种结构中⼀般消息头部分是⼀个固定字节长度的结构,并且消息头中会有⼀个特定的字段指定消息体的大小。收消息时,先接收固定字节数的头部,解出这个消息完整长度,按此⻓度接收消息体。这是目前各种网络应用中使用最多的⼀种消息格式;header + body
3)在序列化后的buffer前面增加一个字符流的头部,其中有个字段存储消息总长度,根据特殊字符 (比如根据\n或者\0)判断头部的完整性。这样通常比3要麻烦一些,HTTP和REDIS采用的是这种方式。收消息的时候,先判断已收到的数据中是否包含结束符,收到结束符后解析消息头,解出这个消息完整长度,按此长度接收消息体。
三、协议设计
根据不同的业务,设计不同的协议,但重点在于
1)消息边界。使用什么方式界定消息边界。
2)版本区分。版本号放在何处合适。
3)消息类型区分。对应不同的业务。
3.1 协议设计实例
IM即时通讯的协议设计
| 字段 | 类型 | 长度(字节) | 说明 |
|---|---|---|---|
| length | unsigned int | 4 | 整个消息的⻓度包括 协议头 + BODY |
| version | unsigned short | 2 | 通信协议的版本号 |
| appid | unsigned short | 2 | 对外SDK提供服务时,用来识别不同的客户 |
| service_id | unsigned short | 2 | 对应命令的分组类比,比如login和msg是不同分组 |
| command_id | unsigned short | 2 | 分组里面的子命令,比如login和login response |
| seq_num | unsigned short | 2 | 消息序号 |
| reserve | unsigned short | 2 | 预留字节 |
| body | unsigned char[] | n | 具体的协议数据 |
注意:
1)length一定要约定好是body的长度还是header+body的长度。
2)版本号尽量靠前,是为了版本升级的便携性,反正不同版本的后续字段不同导致的未知问题。
3)内部有不同业务,可以考虑使用appid来做识别。
4)消息类型的识别。比如登录业务和消息聊天业务,登录有登录请求和响应等,消息聊天又有私聊和群里等。
5)消息序列号主要用来业务的应答。判断消息是否已被接收处理成功,要不要重发等。TCP数据传输可靠不代表业务可靠。
6)一般来说,设计协议的时候要留一些预留位,为了后期有变动或扩展时能兼容。
nginx协议
typedef struct {
ngx_char_t magic[2]; // sync word,通信协议数据包的开始标志
ngx_short_t version; // 版本号
ngx_short_t type; // 类型:序列化方式:json, xml, binary, protobuf and so on
ngx_short_t len; // 消息体 body 长度
ngx_uint_t seq; // 序列号:保证业务可靠
ngx_short_t id; // 消息id,区分消息类型
ngx_char_t reserve[2]; // 预留字节
} ngx_message_head_t;
应用层数据也需要序列号保证可靠传输, 这是因为 tcp 数据传输可靠,但是并不代表业务可靠。考虑这种场景,服务器收到消息,然后宕机,没有及时处理消息,这时客户发送的信息丢失,需要保证客户的信息正确到达,比如微信的提示重发功能。
HTTP协议
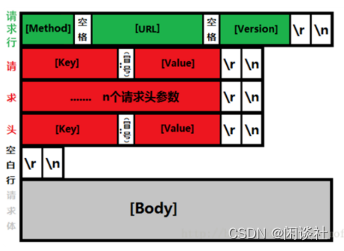
HTTP协议是我们最常见的协议,我们是否可以采用HTTP协议作为互联网后台的协议呢?这个一般是不适当的,主要是考虑到以下2个原因:
1)HTTP协议只是一个框架,没有指定包体的序列化方式,所以还需要配合其他序列化的方式使用才能传递业务逻辑数据
2)HTTP协议解析效率低,而且比较复杂(不知道有没有人觉得HTTP协议简单,其实不是http协议简单,而是HTTP大家比较熟悉而已)
有些情况下是可以使用HTTP协议的:
1)对公网用户api,HTTP协议的穿透性最好,所以最适合;
2)效率要求没那么高的场景;
3)希望提供更多人熟悉的接口,比如新浪微、腾讯博提供的开放接口;
HTTP的body是文本还是二进制?
这依赖于是否压缩,如果没有压缩就是文本;如果压缩了就是二进制,需要客户端解压成文本;如果传输的是视频流或图片,那么body就是二进制的。头部一定是文本的。
redis协议
redis 采用 RESP 序列化协议,协议的不同部分使用以CRLF(\r\n) 结束。
基本原理是:先发送一个 字符串表示参数个数,然后再逐个发送参数。每个参数发送的时候,先发送一个字符串表示参数的数据长度,再发送参数的内容。
RESP 支持的数据类型,通过第一个字符判断数据类型
- 单行(Simple Strings)回复:回复的第一个字节是“+”
- 错误(Errors)信息:回复的第一个字节是“_"
- 整形数字(Integers):回复的第一个字节是“:”
- 多行字符串(Bulk Strings):回复的第一个字节是“$"
- 数组(Arrays):回复的第一个字节是“*”
3.2 序列化方法
序列化是将对象的状态转换为可以存储或传输的格式的过程,而反序列化则是将存储或传输的数据恢复为对象的状态的过程。
比如对于网络传输过程:
1)序列化方法有
1)TVL编码及其变体(TVL是tag,length和value的缩写):比如protobuf。
2)文本流编码:比如xml、json。
3)固定结构编码:基本原理是,协议约定了传输字段类型和字段含义,和TLV的⽅式类似,但是没有了 tag和len,只有value,⽐如TCP/IP。
4)内存dump:基本原理是,把内存中的数据直接输出,不做任何序列化操作。反序列化的时候,直接还 原内存。
2)主流序列化协议:
XML:是一种通用和重量级的数据交换格式。 以文本格式进行存储,适用于本地等。
JSON:是⼀种通用和轻量级的数据交换格式。以文本格式进行存储,适用于http,api等
Protobuf(protocol buffer):是Google的⼀种独立和轻量级的数据交换格式。以二进制格式进行存储,适用于 rpc, 游戏,即时通讯等
3)为什么需要序列化方法?
因为字段值大多是变长的,需要规定起始和结束位置。
xml 中 <字段描述>表示字段起始,</字段描述>表示字段结束
<?xml version="1.0" encoding="utf-8" ?>
<?xml-stylesheet type="text/css" href="test.css"?>
<test>
<name>HelloWorld</name>
<sex>male</sex>
<birthday>7.1</birthday>
<skill>AI</skill>
</test>
json 中字段描述 : 字段,: 表示字段起始,,表示字段结束。
{
"name": "HelloWorld",
"age": 80,
"languages": ["C","linux","C++"],
"phone": {
"number": "12345678901",
"type": "home"
},
"china": true,
"books":[
{
"name": "Linux c development",
"price": 18.8
},
{
"name": "Linux server development",
"price": 188.8
}
],
}
protocol buffer字段描述和前两者都不同,采用的是字段编号,以二进制形式存储,结构紧凑,传输速度快。
16 36 16 36 00 00 16 36 16 36 16 36 16 36 00 00 sf
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 sf
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 sf
00 00 00 00 00 00 9C 00 00 00 00 00 E7 00 36 76 sf
11 11 40
3.3 协议安全
xxtea 固定key
AES 固定key
openssl
Signal protocol 端到端的通讯加密协议
3.4 协议压缩
数据压缩:文本的情况下压缩,二进制压缩(视屏、图片)没多大意义。常见的压缩方式有
- deflate nginx
- gzip
- lzw
3.5 协议升级
协议升级:增加字段。
1)通过版本号指明协议版本,即是通过版本号辨别不同类型的协议 。
2) 支持协议头部可扩展,即是在设计协议头部的时候有一个字段用来指明头部的长度。
四、Protobuf
Protocol buffers 是一种语言中立,平台无关,可扩展的序列化数据的格式,可用于通信协议,数据存储等。
Protocol buffers 在序列化数据方面,它是灵活的,高效的。相比于 XML 来说,Protocol buffers 更加小巧,更加快速,更加简单。一旦定义了要处理的数据的数据结构之后,就可以利用 Protocol buffers 的代码生成工具生成相关的代码。甚至可以在无需重新部署程序的情况下更新数据结构。只需使用Protobuf 对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
Protocol buffers 很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
4.1 安装编译
1)下载
https://github.com/protocolbuffers/protobuf
2)解压、编译
# 解压
tar zxf protobuf-cpp-3.19.6.tar.gz
# 编译
cd protobuf-3.19.6/
./configure
make
sudo make install
sudo ldconfig
# 显示版本信息
protoc --version
3)编写proto文件
4)将proto文件生成对应的.cc和.h文件
protoc -I=/路径1 --cpp_out=./路径2 /路径1/addressbook.proto
路径1为.proto所在的路径,路径2为.cc和.h生成的位置
例如,将指定proto文件生成.pb.cc和.pb.h
protoc -I=./ --cpp_out=./ test.proto
将对应目录的所有proto文件生成.pb.cc和.pb.h
protoc -I=./ --cpp_out=./ *.proto
5)编译
例如
g++ -std=c++11 -o list_people list_people.cc addressbook.pb.cc -lprotobuf - lpthread
4.2 工作流程
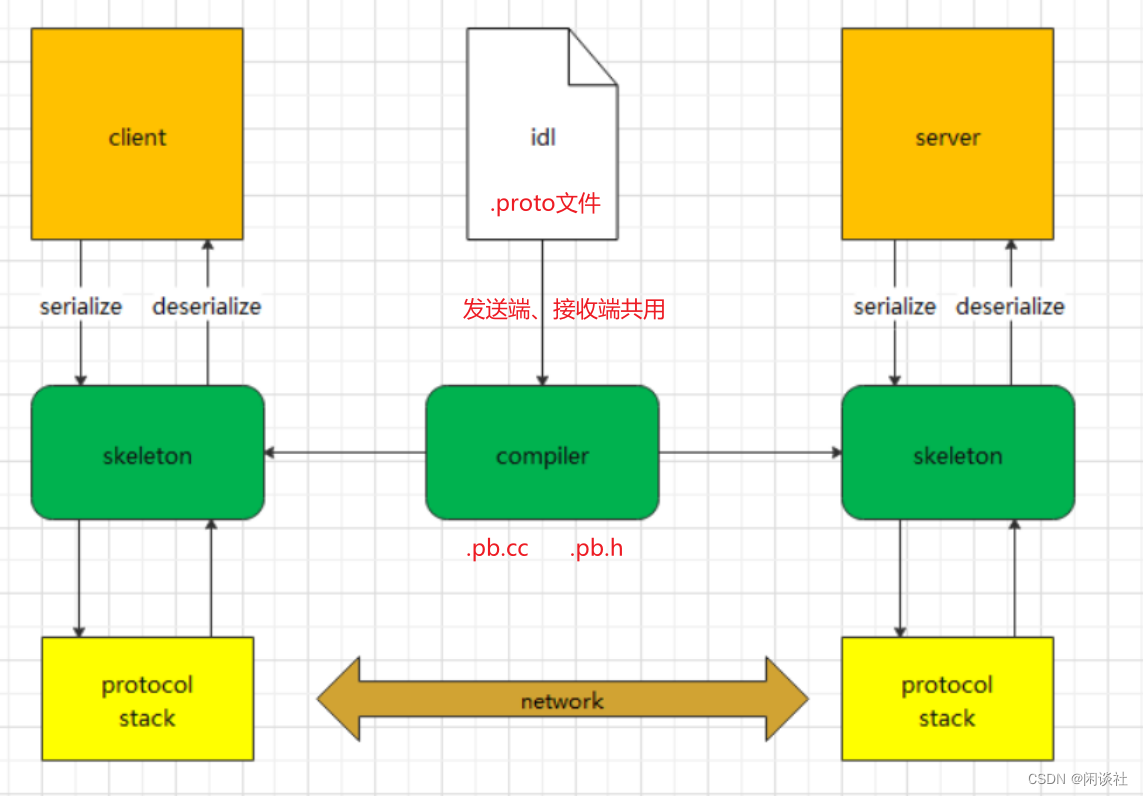
接口描述语言 IDL,Interface description language
可以看到,对于序列化协议来说,使用方只需要关注业务对象本身,即 idl 定义 (.proto),序列化和反序列化的代码只需要通过工具生成即可。
4.3 标量数值类型
⼀个标量消息字段可以含有一个如下的类型——该表格展示了定义于.proto文件中的类型,以及与之对应 的、在自动生成的访问类中定义的类型:
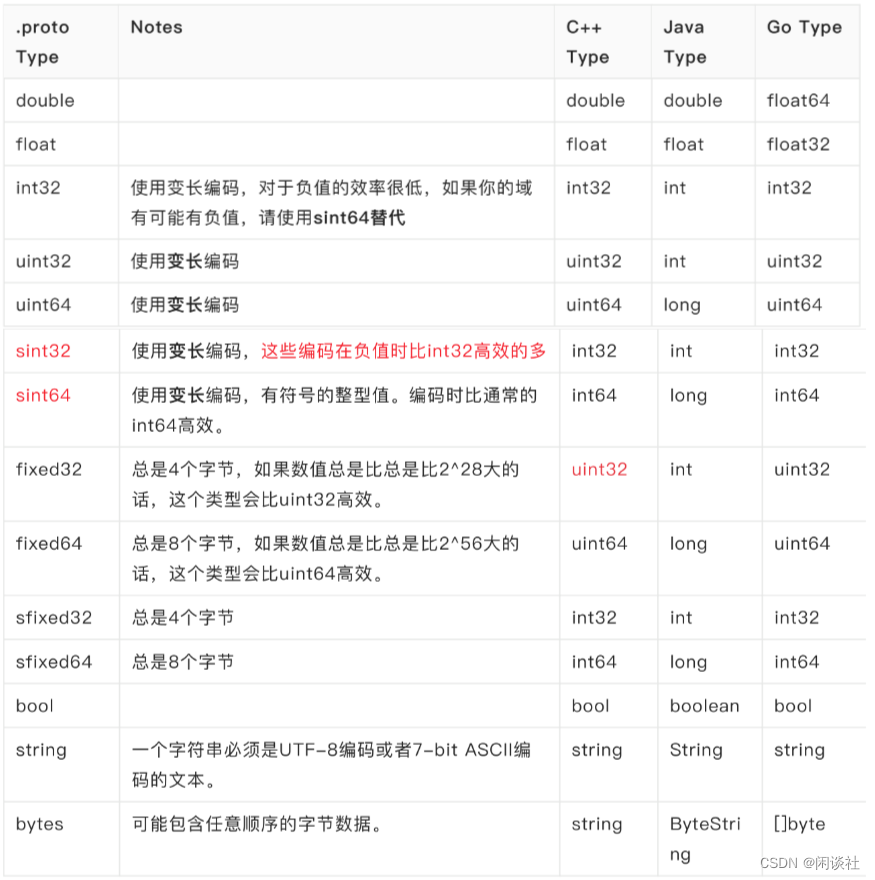
变长编码:值小的时候,减少表示字节数。
4.4 编码原理
4.4.1 Varints 编码
为什么设计变长编码?
普通的 int 数据类型,无论其值的大小,所占用的存储空间都是相等的,比如不管是0x12345678 还是0x12都占用4字节,那能否让0x12在表示的时候只占用1个字节呢?是否可以根据数值的大小来动态地占用存储空间,使得值比较小的数字占用较少的字节数,值相对比较大的数字占用较多的字节数,这即是变长整型编码的基本思想。
Varints 编码的实质在于去掉数字开头的 0, 因此可缩短数字所占的存储字节数。
采用变长整型编码的数字,其占用的字节数不是完全一致的,Varints 编码使用每个字节的最高有效位作为标志位,而剩余的 7 位以二进制补码的形式来存储数字值本身,当最高有效位为 1 时,代表其后还跟有字节,当最高有效位为 0 时,代表已经是该数字的最后的一个字节。
在 Protobuf 中,使用的是 Base128 Varints 编码,在这种方式中,使用 7 bit (即7的2次方128)来存储数字,在 Protobuf 中,Base128 Varints 采用的是小端序,即数字的低位存放在高地址。
举例来看, 对于数字 1, 我们假设 int 类型占 4 个字节, 以标准的整型存储, 其⼆进制表示应为
00000000 00000000 00000000 00000001
可见, 只有最后⼀个字节存储了有效数值, 前 3 个字节都是 0, 若采⽤用Varints 编码, 其二进制形式为
00000001
再比如数字 666, 其以标准的整型存储, 其⼆进制表示为
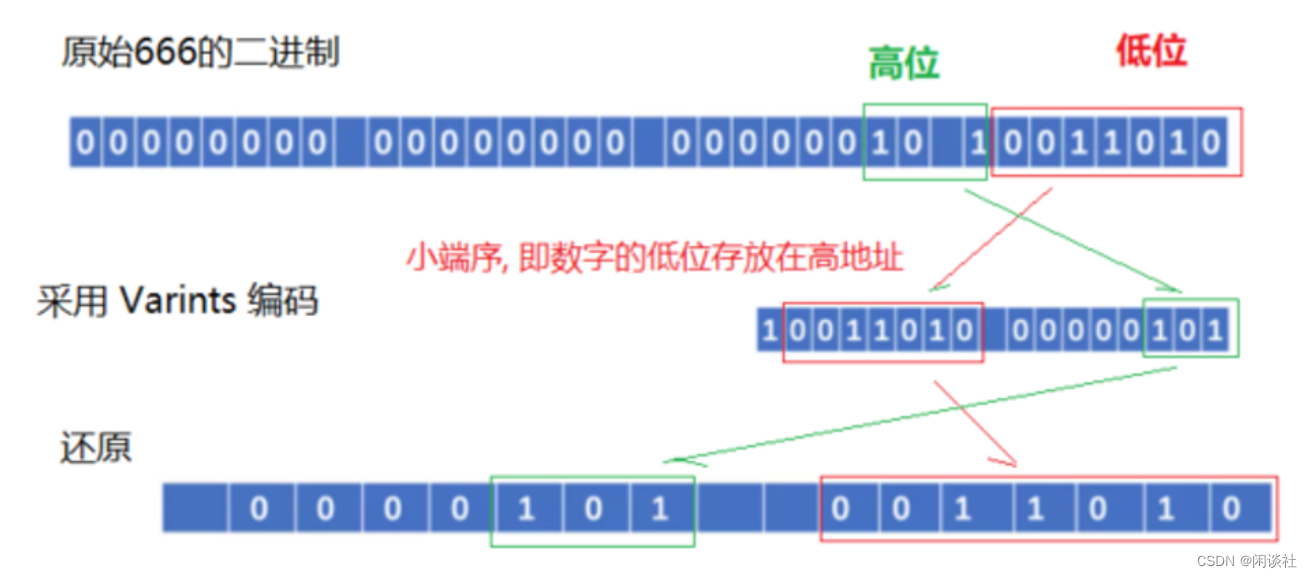
从上面的编码解码过程可以看出, 可变长整型编码对于不同大小的数字, 其所占用的存储空间是不同的。
通俗的说:
每个字节用7bit表示数值的信息,用1 bit标记结束(1表示没有结束,0表示结束,也就是最后一个字节的位置)。编码时从低位开始取7bit,放在高位。还原时从高位取,放到低位。
对于大数字来说,使用 Varints 编码,意味着占用较多的字节数。对于数字的位数不超过 28 bit 适合使用变长编码。若数字位数超过 28 bit,例如 32 bit,使用变长编码需要的存储空间为 [32 /7 ] = 5 个字节。因此使用 fixed32, sfixed32 固定 4 字节的类型更合适。
4.4.2 Zigzag 编码
在上面的例子中,只举例说明了正数的 Varints 编码但如果数字为负数,则采用 Varints 编码会恒定占用10个字节,原因在于负数的符号位为 1,对于负数其从符号位开始的高位均为 1,在 Protobuf 的具体实现中,会将此视为一个很大的无符号数。
比如 对于 int32 类型的数字 -5, 其二进制表示为
// 取 5 的 原 码 :
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101
// 得 反 码 :
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111010
// 对 反 码 加 1 最 后 得 补 码 :
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111011
// 即 -5 在 计 算 机 ⾥ ⽤ ⼆ 进 制 表 示 结 果
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111011
转成每7bit占用1个字节:
(高位)1 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111111 1111011(低位)
然后高地址存储到低地址,并且不是结束字节最高位为1,即是 :
(低位)11111011 11111111 11111111 11111111 11111111 11111111 11111111 11111111
11111111 00000001(高位)
因此对于 int32 类型的数字 -5, 其序列化之后的二进制为:
11111011 11111111 11111111 1111111 11111111 11111111 11111111 00000001
转成16进制:fb ff ff ff ff ff ff ff ff 01 ,数据本身就占⽤了10字节。
可见 Varints 编码对于表示负数毫无优势,甚至比普通的固定 32 位存储还要多占 4 个字节。Varints 编码的实质在于设法移除数字开头的 0 比特而对于负数,由于其数字高位都是 1,因此 Varints 编码在此场景下失效,Zigzag 编码便是为了解决这个问题。
Zigzag 编码的大致思想是首先对负数做一次变换,将其映射为一个正数,变换以后便可以使用 Varints 编码进行压缩。其计算方式
正向:(n << 1) ^ (n >> 31)
逆向:(n >> 1) ^ -(n & 1)

4.5 数据组织
⾸先来看⼀个例子, 假设客户端和服务端使用 protobuf 作为数据交换格式, proto 的具体定义为
syntax = "proto3";
package pbTest;
message Request {
int32 age = 1;
}
Request 中包含了一个名称为 name 的字段,客户端和服务端双方都用同一份相同的 proto 文件是没有任何问题的。假设客户端自己将 proto 文件做了修改,修改后的 proto 文件如下
syntax = "proto3";
package pbTest;
message Request {
int32 age_test = 1;
}
在这种情形下,服务端不修改应用程序仍能够正确地解码。原因在于序列化后的 Protobuf 没有使用字段名称而仅仅采用了字段编号。
json xml 等协议格式是完全自描述的,即拿到了 json 消息体,便可以知道这段消息体中有哪些字段,每个字段的值分别是什么。而Protobuf 不是一种完全自描述的协议格式,即接收端在没有 proto 文件定义的前提下是无法解码一个 protobuf 消息体的。
其实对于客户端和服务端通信双方来说,约定好了消息格式之后完全没有必要在每一条消息中都携带字段名称。因此,Protobuf 在通信数据中移除字段名称,可以大大降低消息的长度,提高通信效率。
Protobuf 进一步将通信线路上消息类型做了划分
| Tpye | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 5 | 32-bit | fixed32, sfixed32, float |
序列化后的数据没法区分你到底是int32、int64.
int32 :按int32做变长varints编码
sint32 :Zigzag 编码 -> 做变长 varints编码
Protobuf 除了存储字段的值之外, 还存储了字段的编号以及字段在通信线路上的格式类型(wire- type),具体的存储⽅式为:
field_num << 3 | wire type
即将字段标号逻辑左移 3 位, 然后与该字段的 wire type 的编号按位或。接收端可以利⽤这些信息,结合 proto ⽂件来解码消息结构体。
上例子中,假设 age 为 5,由于 age 在 proto 文件中定义 的是 int32 类型, 因此序列化之后它的 wire type 为 0,其字段编号为 1。因此按照上面的计算⽅式, 即 1 << 3 | 0, 所以其类型和字段编号的信息只占 1 个字节, 即 00001000。后面跟上字段值 5 的 Varints 编码,,所以整个结构体序列化之后为:
00001000 00000101
有了字段编号和 wire type,其后所跟的数据的长度便是确定的。因此 Protobuf 是⼀种非常紧密的数据组织格式,其不需要特别地加入额外的分隔符来分割⼀个消息字段,这可大大提升通信的效率, 规避冗余的数据传输。
4.6 总结
1)Protobuf 采用 Varints 编码和 Zigzag 编码来编码数据其中 Varints 编码的思想是移除数字高位的 0,用变长的二进制位来描述一个数字,对于小数字,其编码长度短,可提高数据传输效率。另外对于负数,直接采用 Varints编码将恒定占用10个字节。Zigzag 编码可将负数映射为无符号的正数,然后采用 Varints 编码进行数据压缩。因此当字段可能为负数时,我们应使用 sint32 或sint64。这样 Protobuf 会按照 Zigzag编码将数据变换后再采用 Varints 编码进行压缩,从而缩短数据的二进制位数.
2)Protobuf 不是完全自描述的信息描述格式。接收端需要有相应的解码器(即 proto 定义)才可解析数据格式,序列化后的 Protobuf 数据不携带字段名,只使用字段编号来标识一个字段。字段编号会被编码进二进制的消息结构中,因此我们应尽可能地使用小字段编号。
3)Protobuf 是一种紧密的消息结构,编码后字段之间没有间隔。每个字段头由两部分组成:字段编号和 wire type,字段头可确定数据段的长度。因此其字段之前无需加入间隔,也无需引入特定的数据来标记字段未尾。因此 Protobuf 的编码长度短,传输效率高。