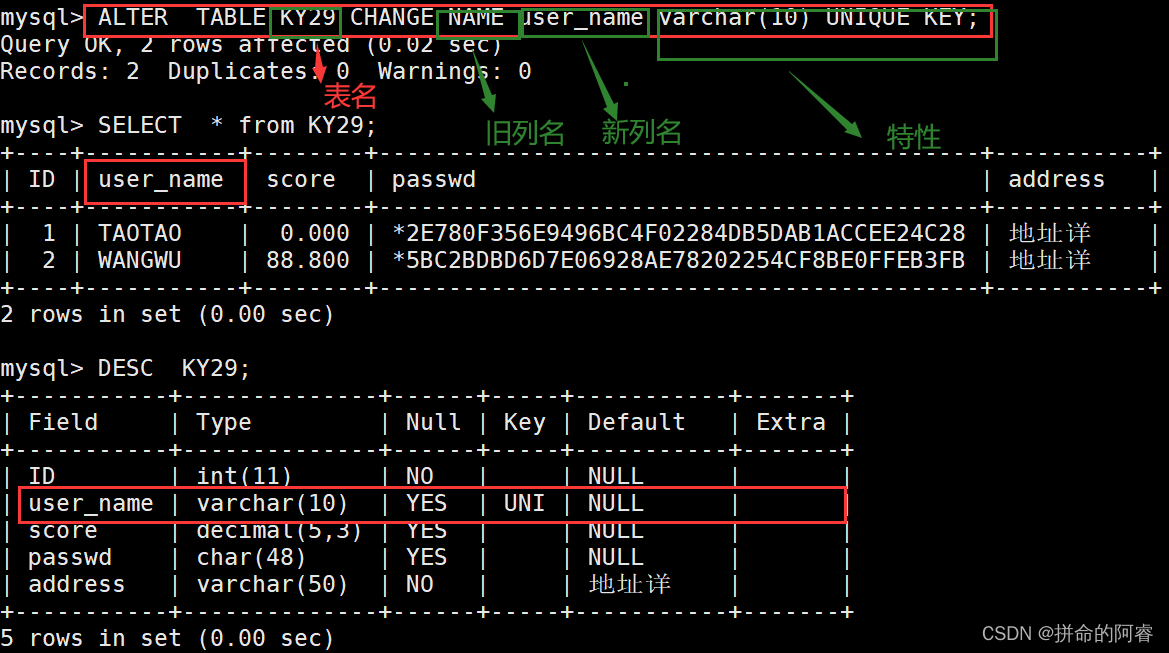
MIT 6.829 -- L0 Background: Single-Link Communication
- 前言
- Problem
- Modulation(调制) & Demodulation(解调)
- Framing
- Error Detection
- Error Recovery
- ARQ
- Shared Media Access
- 总结
本课程为MIT 6.829 计网课程,课程对应官网链接: Computer Networks Lecture Notes
本节对应课程文档链接: Background: Single-Link Communication
前言
本节课,我们会考虑将两台计算机用相同的通讯介质连接起来并尝试在它们之间交换数据时,会出现的问题。我们会先从P2P连接开始介绍,在P2P连接中唯一出现的电脑就是线路两端的电脑。之后我们会介绍共享传输介质,例如以太网。这一篇的内容在传统的网络分层的中属于Layer 2,也就是链路层,但是,这篇笔记也会涉及Layer 1,也就是物理层。
Problem
我们先来看一个似乎很简单的场景:将两台计算机连在一起,并且使得它们彼此之间进行“交谈”。我们最终会发现这个场景并不是它看起来的那么简单。
接下来,我们会系统的将这个场景转换成五个问题,并一个一个的解决这些问题。
-
第一个问题:物理介质(例如电话线,线缆或者以太网)实际传输的是模拟信号,而不是比特位(也就是数字信号)。因此,我们需要有一种方法来在发送端将数字信号转换成模拟信号,这种行为通常被称为调制(modulation)。对应的,在接收端将模拟信号转换成数字信号的行为被称为解调(demodulation)。在网络的物理层完成的众多事情当中,调制解调是一个重要的步骤。
-
但是我们真正想做的事情是将一个大文件从一个计算机传递到另一个计算机。假设我们已经解决了调制解调的问题,也就是说我们知道如何在物理介质发送数字信号,我们还需要方法能够将文件拆分打包,并有效的发送出去。一种方式是将文件传输看成是bit流,并且持续不断的传输bit。另一种方法是将文件的内容拆分成更小的包,并且传输这些包。第二种方式就是分包(framing)问题。
-
物理上的定律使得在任何情况下都无法达到无噪音通讯。所以在很多场景下,我们都关心接收者是否完整精确的收到了发送者的数据。这意味着接收端需要机制来进行错误探测(error detection)。
-
在某些场景下,接收端可以探测出错误并且直接丢弃相应的数据块。然而,在很多场景下,仅仅是探测到错误是不够的,从错误中恢复也很重要。这就是错误修正或者错误恢复问题。
-
最后,很多物理介质,比如以太网,可以连接超过2台计算机。所以我们还需要考虑物理介质共享的问题。这是media access(注,MAC地址全称就是Media Access Control)或者channel access问题,它会决定在任何时刻,谁可以发送数据,以及当channel中发生竞争时,如何仲裁和解决。
Modulation(调制) & Demodulation(解调)
方案1-NRZ
- 在最简单的调制方案中,bit “1”会被当做高电平发送,而bit “0”会被当做低电平发送。尽管名字“Non-Return to Zero”(NRZ)让人很不解,但是它就是这种方案的名字。NRZ的主要问题是,连续的相同bit(对应相同的电平),会使得接收端难以区分。举个例子,很难区分bit “0”和无信号(注,无信号的时候也是低电平);同样的,太多连续的bit “1”,会使得信号电平偏离真实的平均值。
- 大多数的调制解调方案都有一个关键的需求,那就是可以很容易的实现clock recovery。因为发送端会将信息(也就是bit位)通过时钟周期的触发发送出来,clock recovery是指接收端能够推断(或者是恢复)发送端的时钟频率(这样就可以通过发送端的时钟频率判断是否有bit “0”,以及连续的bit “0”有几个)。直观上来看,如果有频繁的0-1和1-0的转变,clock recovery将会很容易。
方案2-NRZI
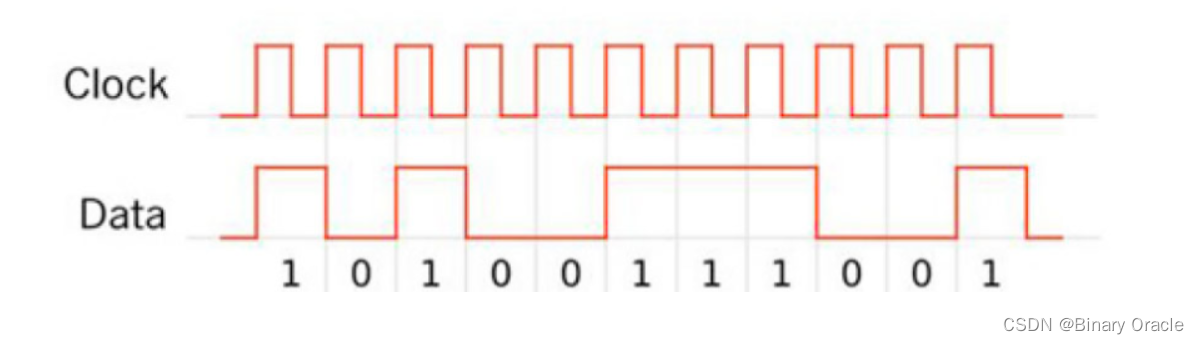
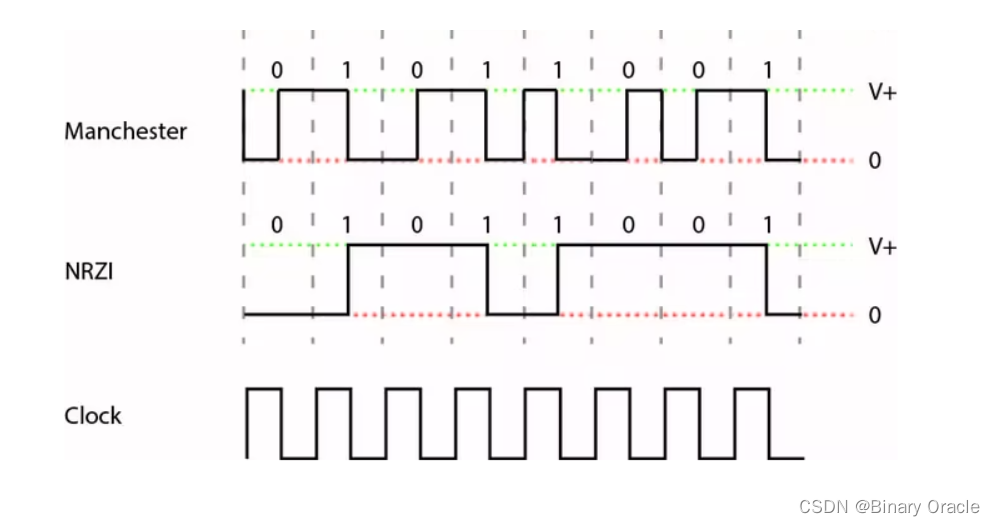
- NRZI全称是Non-Return to Zero Inverted。这里发送端在发送bit “0”时,保持电平不变,发送bit “1”时会变化电平。当然,这里并没有解决连续bit “0”的问题,但是却解决了连续bit “1”的问题。
方案3-Manchester编码:
- Manchester编码中,发送方在发送bit “0”时,会将电平从低变高;发送bit “1”时,会将电平从高变低。这样就确保了每个bit位都有一次电平的变化,从而使得clock recovery可以实现。虽然它解决了上面提到的NRZ问题,但是它在某种程度上效率比较低(因为首先速率需要收发双方协商,其次最高只能按照接收端的内部时钟频率的一半来传输,这样接收端才能识别出每个bit的电平变化)。
方案4-4B/5B
- 这个方案通过在传输数据中加入额外的bit,来阻止过多的连续bit “0”和连续bit “1”,从而解决了Manchester编码低效率的问题。你可以认为它为数据增加了一些冗余,从而使得clock recovery容易实现。具体来说,它将每4个连续的数据bit转换成了5个bit,以确保不会出现大于等于3个连续的bit “0”(注,4B编码不是简单的在4个数据bit之后增加一个bit,而是将4个数据bit映射成一个最多只有2个连续bit “0”的5bit数,详见参考),之后再通过NRZI将其编码,避免使用了Manchester编码,又解决了NRZI的问题(这就是为什么上面还要单独一部分介绍NRZI编码)。
Framing
Framing协议的一些例子是PPP(the Point to Point Protocol)和HDLC(High-level Data Link Control)。这里的思路是,发送端通过一个起始标志(HDLC协议中是一个众所周知的8bit 01111110)来分隔发送端的数据bit流。两个起始标志之间的数据bit被称为一个帧(Frame)。链路层之后会通过上面介绍的某一种调制方式,将Frame发送给接收端。在接收端,链路层需要接收这些Frame,并将它们传输给发送端应用程序想要交互的接收端应用程序。
上面提到的分包方式中,有一个问题是起始标志有可能出现在实际传输的数据中。如果不做处理的话,这会使得接收端在分包时出错。这个问题的解决方法是bit stuffing,这种方法非常像转义序列(escape sequence)。在HDLC和PPP的场景下,发送端会在数据中每5个连续的bit “1”后面加一个额外的bit “0”。在接收端,现在会使用如下的解码策略:如果看到了5个连续的bit “1”,那么再检查之后的一个bit。如果这个bit是0,那么这是被填充的bit,接收端会去除这个bit “0”并继续处理。如果这个bit是1,那么这是一个下一个frame的起始标志。
HDLC和PPP使用的分包方式被称为面向bit的分包。这种方法引入的另一个问题是,经过填充bit的frame长度是不固定的,它的具体长度取决于实际的数据内容。
Error Detection
在数据传输中有很多方法可以用来探测错误,按照复杂程度排序的话有:奇偶校验,校验和,和CRC。错误探测的挑战在于做好探测的同时,引入尽可能少的额外负担。
Error Recovery
在有噪音或者易丢失数据的通道里面,有两种形式的错误恢复:
-
ARQ(Automatic Repeat reQuest):ARQ通过接收端的某种确认来进行重传。TCP就是一种ARQ的实现。
-
FEC(Forward Error Correction):基于编码学来将一些冗余的数据加到传输数据中,从而使得接收端可以修正某些特定的常见错误。本课程中并不会学习特定的FEC方法。
ARQ
最简单的错误恢复方法就是通过确认重传。发送端发送一个包(或者帧),之后等待来自接收端的确认,收到确认之后再发送下一个包。如果在一定的时间内没有收到确认,那么发送端就假设包数据破损了或者包在传输中被丢弃了,并重传包。这种简单的方法被称为stop-and-wait。
你可能会认为,对于stop-and-wait方法,并不需要在包头部添加任何信息,因为任何时间点,最多只可能有一个包在传输。但这是错误的,因为发送端并不能确认一个自己认为丢失了的包是不是真的丢失(或者数据破损)了。数据包可能只是因为某种原因被阻塞超过了约定的超时时间。所以,ARQ需要在包头部添加一个序列号来使得接收端能区分重复的包。
通常来说,发送端和接收端在一个易于出错的网络中不能达成真正的同步。这是著名的“Two generals problem”,它是指在一个山谷的两端,分别有两位将军想要通过骑马的士兵在山谷内传递消息,来商定一个相同的时间以进攻位于同一个山谷内的敌人。这里的消息是易于丢失的,因为不走运的士兵会被山谷内的敌人消灭或者扣押。可以通过反证法来证明为什么不能达成真正的同步。假设存在一种协议通过最少次数通信可以达成真正的同步,那么这个协议中的最后一条消息其实是多余的,因为它是可能丢失的。如果这条消息是多余的,那么这与我们所做的最少次数通信的假设是矛盾的,因此假设不成立。
stop-and-wait的主要缺点是:它只允许在一个RTT(Round Trip Time)内发送一个包,这使得最大的传输速率是包长度除以RTT。也就是说,它并不能填满发送端和接收端之间的通信通道。
那么发送端和接收端之间的通道最多能有多少数据呢?假设我们知道通道的带宽是B,RTT是d,对应的数据量是P。当通道被填满时,B会被完全利用;并且,当通道内的未被确认的字节数是P时,没有数据丢失,所以接收端可以观察到的吞吐是P/d。因此,如果带宽和RTT不变的话,通道的容量是P=Bd。这个数字通常会被称为发送端和接收端之间的网络带宽时延积(Bandwidth-delay product)。理想情况下,发送端会确保有Bd的数据存在于通道中,而不是等待每个packet的确认再发送下一个包(除非B*d < S,S是一个包的大小,也就是通道里面容纳不下一个包)。
这里可以通过一个基于窗口的协议来完成。直观上来看,理想的窗口大小是B*d,因为这时可以达到最大的链路利用率。实际实现中,我们不能先发送一个窗口大小的包,等待确认,再发送下一个窗口的包,我们需要使用滑动窗口协议。
滑动窗口协议的工作方式是:接收端确认它收到的每个包,当发送端收到确认之后,将其窗口向右滑动一个packet。之后,发送端再发送一个新的包以确保正在发送的且未被确认的包的大小总和等于窗口的大小。在大多数实际的协议中,这个窗口是受限的,会通过流控(flow control)来确保接收端的缓存不会被发送端发送过多的数据而撑满。
尽管我这里是在链路层介绍的ARQ,但是使用滑动窗口和确认重传也可以应用在其他地方。之后在这门课程,我们会看到TCP使用了相同的思路。
Shared Media Access
通常情况下,我们可以在同一个物理介质(链路)中挂载多个节点,典型的例子就是流行的以太网技术。像以太网这样的技术被称为共享的介质,并且它带出了另一个重要的问题:Media Access。这是指在共享的通道中,多个终端之间的竞争抢占的问题。解决这个问题的协议被称为MAC(Media Access Control)协议。
通常来说,MAC协议分为好几类。中心化的协议依赖网络上中心化的控制器来决定,在任何时候谁才能拥有共享通道上的权限。分布式的协议并没有一个专门的节点来完成这个任务,而是依赖一些去中心化的机制以确定共享通道的访问权限。以太网中使用的协议,就一个非常有趣的分布式协议的例子,它被称为CSMA/CD(Carrier Sense Multiple Access/Collision Detect),它非常的成功。
它的具体实现是,当一个终端想要传输数据时,它会首先通过探测线路上的电压,来判断当前通道是否正在被使用。如果电压高于基线,那么说明通道正在被使用。如果电压小于等于基线,那么它会继续发送网络包。之后它会等待一个特定的时间(在10M以太网中这个值是51.2us),然后再发送另一个包。这里的等待使得其他终端在等待间隔的时间内可以有机会发送包。
如果终端探测到了当前通道正在被使用,它会等待通道空闲再传输网络包。当然,两个终端可能会在同一个时间传输数据,这就会引起冲突(collision)。以太网终端支持冲突探测(collision detection,CSMA/CD中的CD部分)。每当一个终端探测到了冲突,它会假设发生冲突的包已经破损且无法恢复。它会等一段时间再重试。这里等待的时间被称为回退(backoff)时间。有很多种方式可以用来选择回退时间,以太网使用的是指数级回退的方法。这里的思路是,每次探测到了冲突,回退时间的上限都会加倍,回退时间会从0和上限之间随机选择。随机可以帮助避免终端之间的同步(以相同的节奏回退,会导致始终冲突),而指数级回退提高了系统的稳定性,因为它减少了冲突的可能性。
实际上,如果终端数量是无限的,指数级回退也不能带来稳定性。幸运的是,我们不用在实际中处理无限终端。
使用回退机制的背后思想是,每一个终端都尝试预估通道当前有多拥挤,如果竞争越激烈,那么终端的回退时间就越长。(因为协议的分布式特性,没有一个终端能够知道在任何时间到底有多少个其他活跃的终端)。终端并不会无限尝试,它们会在固定的尝试之后放弃(通常是16次)。发送端的逻辑(也是协议的大部分实现逻辑)被总结在了图1。
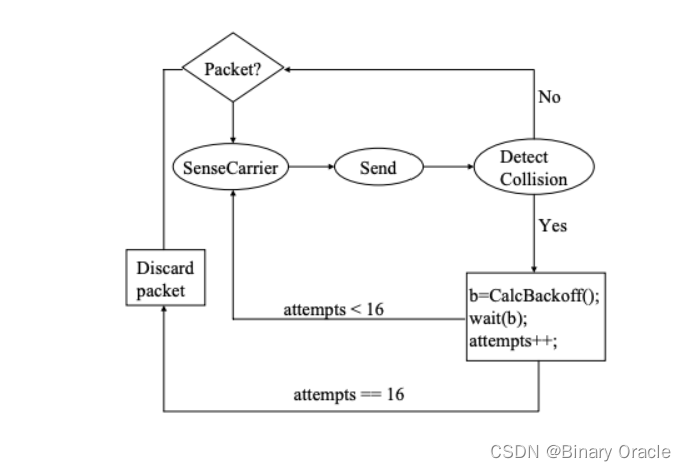
图1:总结了以太网的MAC协议。函数CalcBackoff会从0和当前的回退间隔中随机一个数。每次失败的传输,都会使得回退间隔加倍。
有关以太网协议的理论和实际性能是过去很多年的研究主题。当包的大小足够小,终端足够多的时候(也就是最差情况下),不难算出线路的利用率只有1/e(37%)。然而,在大多数实际的情况下,以太网工作的非常好,通常能达到高达90%的利用率。一些在以太网上简单的获取高利用率的方法有:
- 去除长的线路(以太网线路可以长达1.5km,但是实际中没有必要拉这么长的线)
- 承接更少的终端
- 使用大于最低64字节的包大小
总结
从上面的内容我们可以看到,对于一个你可以想到的最小尺寸的网络,我们仍然有很多棘手的问题。下一章,也是课程的第一节课,我们会考虑packet switching的问题,以及多条同种类型的链路是如何连接起来以形成一些更大的网络。