目录:
- 多表简介
- SQL 约束-外键约束
- 多表关系简介
- 多表查询
- 多表查询-内连接查询
- 多表查询-外连接查询
- 子查询简介
- 子查询实战
- 数据库进阶
- redis 内存数据库
- mongodb nosql 数据库
- neo4j 图数据库
1.多表简介
多表及使用场景介绍:
- 多表顾名思义就是在数据库设计中使用多张表格来实现数据存储的要求
- 在实际的项目开发中,数据量大而且复杂,需要分库分表
- 分表:按照一定的规则,对原有的数据库和表进行拆分
- 表与表之间可以通过外键建立连接
多表设计案例:
假定我们现在需要创建一张员工信息表,包含字段:
- eid 员工ID (自增主键)
- ename 员工姓名
- age 年龄
- gender 性别
- dept_name 所在部门
- dept_id 部门ID
- dept_manager 部门主管
- dept_location 所在地点
以单表的形式完成建表:(创建员工信息表)
CREATE TABLE emp(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT ,
gender VARCHAR(10),
dept_name VARCHAR(20),
dept_id INT,
dept_manager VARCHAR(20),
dept_location VARCHAR(20)
);
插入数据:
INSERT INTO emp VALUES (1,'张三', 20, '男','研发部',1,'张无忌','北京');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('李四', 25, '男','研发部',1,'张无忌','北京');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('宋江', 40, '男','研发部',1,'张无忌','北京');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('林冲', 25, '男','研发部',1,'张无忌','北京');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('林徽因', 25, '女','研发部',1,'张无忌','北京');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('周芷若', 25, '女','运营部',2,'赵敏','深圳');
INSERT INTO emp(ename, age,gender,dept_name,dept_id,dept_manager, dept_location) VALUES ('任盈盈', 25, '女','运营部',2,'赵敏','深圳');
单表数据冗余:

多表设计模式:
- 将数据拆分为员工信息表employee和部门信息表dept
- 两个表之间通过部门id:dept_id字段连接
# 创建员工信息表
CREATE TABLE emp_part(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT ,
gender VARCHAR(10),
dept_id INT
);
# 创建部门表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(20),
dept_manager VARCHAR(20),
dept_location VARCHAR(20)
);
# 向部门表插入数据
INSERT INTO dept(dept_name,dept_manager,dept_location) VALUES('研发部','张无忌','北京');
INSERT INTO dept(dept_name,dept_manager,dept_location) VALUES('运营部','赵敏','深圳');
# 向员工信息表插入数据
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('李四', 25, '男',1);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('宋江', 40, '男',1);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('张三', 20, '男',1);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('林冲', 25, '男',1);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('林徽因', 25,'女',1);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('周芷若', 25,'女',2);
INSERT INTO emp_part(ename,age,gender,dept_id) VALUES ('任盈盈', 25, '女',2);
多表关系:

使用多表的优点:
- 简化数据
- 提高复用性
- 方便权限控制
- 提高系统的稳定性和负载能力
2.SQL 约束-外键约束
外键约束的定义与意义:
-
主键:可以唯一标识一条记录的列
-
外键:从表中与主表的主键对应的字段
-
主表:外键所指向的表,约束其他表的表
-
从表:外键所在的表,被约束的表
-
价值:建立主表与从表的关联关系,为两个表的数据建立连接,约束两个表中数据的一致性和完整性

建立外键约束:
# 创建一个关联到主表的从表
CREATE TABLE emp_part(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT ,
gender VARCHAR(10),
dept_id INT,
-- 添加外键约束
CONSTRAINT emp_dept FOREIGN KEY(dept_id) REFERENCES dept(id)
);
# 插入一条非法数据
INSERT INTO emp_part VALUES(1,'cindy',20,'female','4')
删除外键约束:
# 删除外键约束
ALTER TABLE emp_part DROP FOREIGN KEY emp_dept
# 插入一条非法数据
INSERT INTO emp_part VALUES(1,'cindy',20,'female','4') SELECT * FROM emp_part
# 向主表中插入一条数据
INSERT INTO dept VALUES(2,'运营部','张三','北京')
# 向从表中插入一条数据
INSERT INTO emp_part VALUES(1,'cindy',20,'female','2')
# 删除主表中的数据
DELETE FROM dept WHERE id=2
级联删除:
- 删除主表数据的同时,也删除掉从表中相关的数据
- ON DELETE CASCADE ```sql
创建员工信息表并添加级联删除的外键约束:
CREATE TABLE emp_part(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT ,
gender VARCHAR(10),dept_id INT,
– 添加外键约束
CONSTRAINT emp_dept FOREIGN KEY(dept_id) REFERENCES dept(id)
– 设置允许级联删除
ON DELETE CASCADE
);
# 向员工信息表中添加一条数据
INSERT INTO emp_part VALUES(1,‘cindy’,20,‘female’,‘2’)
#删除主表中部门id=2的部门
DELETE FROM dept WHERE id=2
# 查看从表中的数据是否同时被删除
SELECT * FROM emp_part
3.多表关系简介
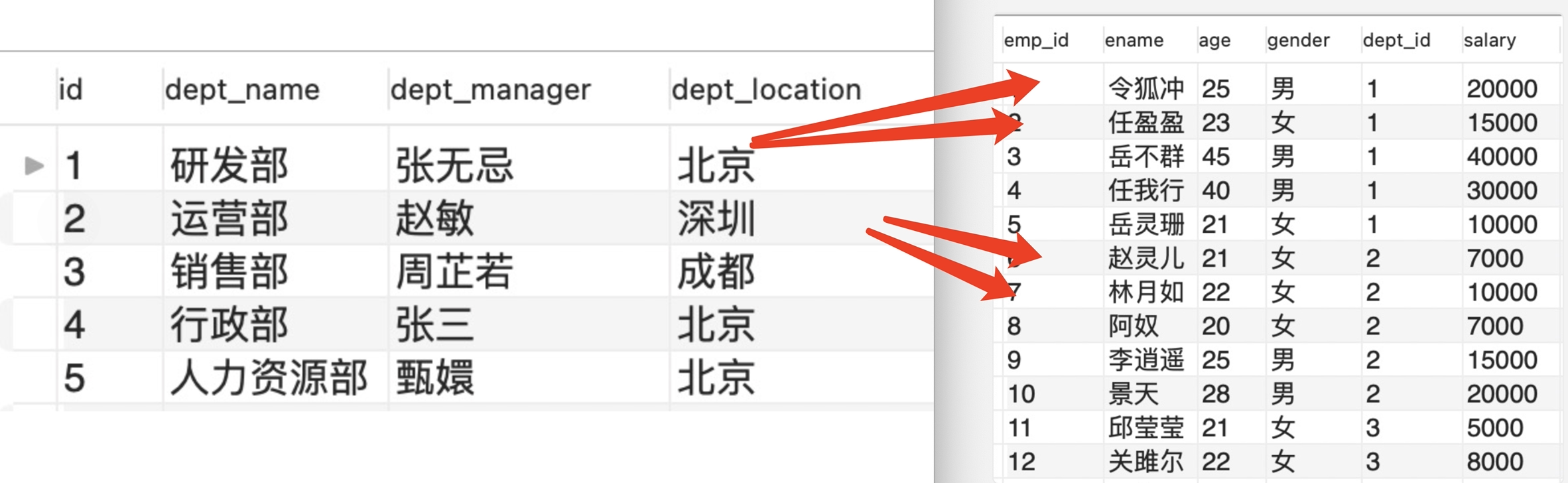
一对多:
- 定义: 主表的一条记录可以对应从表的多条记录
- 例子: 部门表,员工表
- 建表原则:在一对多关系中,多的表定位从表,设置外键指向主表
多对多:
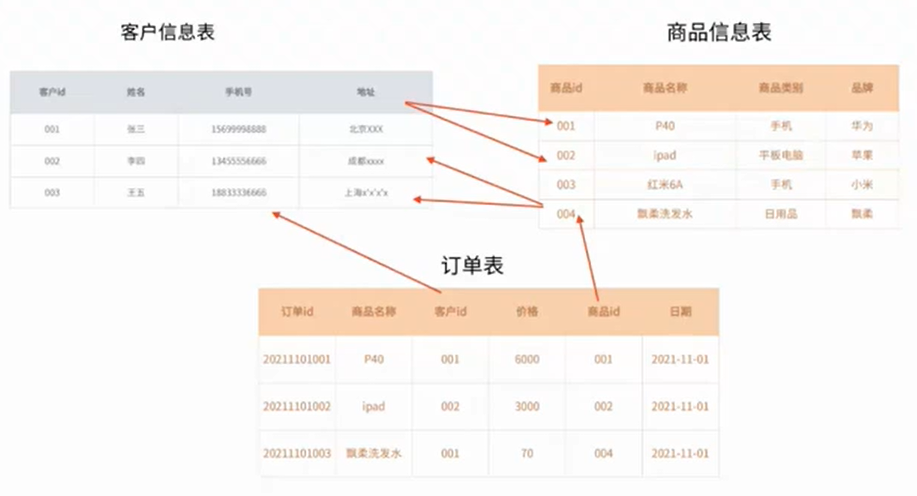
- 定义:主表的多条记录可以对应从表的多条记录
- 例子:商品信息表,客户表,订单表
- 建表原则:需要创建第三张表作为中间表,中间表需要包含两张表的主键。
一对一:
- 定义:从表的一条记录对应主表的一条记录
- 例子:员工信息表与身份证表,联系方式
- 建表原则: 这种对应关系的数据,通常放在单表里
4.多表查询
多表查询的定义:
- 定义: 通过查询多张表格获取数据,至少涉及两张表
- 数据准备:
- 创建部门表,插入三条数据
- 创建员工信息表添加外键约束,允许级联删除,并向三个部门插入对应的员工信息
## 创建部门信息表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(20),
dept_manager VARCHAR(20),
dept_location VARCHAR(20)
);
INSERT INTO dept VALUES(1,'研发部','张无忌','北京');
INSERT INTO dept VALUES(2,'运营部','赵敏','深圳');
INSERT INTO dept VALUES(3,'销售部','周芷若','成都');
# 创建员工信息表并添加级联删除的外键约束
CREATE TABLE emp_part(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT ,
gender VARCHAR(10),
dept_id INT,
salary INT,
-- 添加外键约束
CONSTRAINT emp_dept FOREIGN KEY(dept_id) REFERENCES dept(id)
-- 设置允许级联删除
ON DELETE CASCADE
);
向员工信息表中插入数据:
INSERT INTO emp_part VALUES(1,'令狐冲',25,'男','1',20000);
INSERT INTO emp_part VALUES(2,'任盈盈',23,'女','1',15000);
INSERT INTO emp_part VALUES(3,'岳不群',45,'男','1',40000);
INSERT INTO emp_part VALUES(4,'任我行',40,'男','1',30000);
INSERT INTO emp_part VALUES(5,'岳灵珊',21,'女','1',10000);
INSERT INTO emp_part VALUES(6,'赵灵儿',21,'女','2',7000);
INSERT INTO emp_part VALUES(7,'林月如',22,'女','2',10000);
INSERT INTO emp_part VALUES(8,'阿奴',20,'女','2',7000);
INSERT INTO emp_part VALUES(9,'李逍遥',25,'男','2',15000);
INSERT INTO emp_part VALUES(10,'景天',28,'男','2',20000);
INSERT INTO emp_part VALUES(11,'邱莹莹',21,'女','3',5000);
INSERT INTO emp_part VALUES(12,'关雎尔',22,'女','3',8000);
INSERT INTO emp_part VALUES(13,'曲筱绡',23,'女','3',10000);
INSERT INTO emp_part VALUES(14,'樊胜美',30,'女','3',10000);
INSERT INTO emp_part VALUES(15,'安迪',28,'女','3',20000);
笛卡尔积简介:
-
定义: 笛卡尔积是一个数学概念,又称直积,它是指两个集合元素所有可能有序对的集合。
-
例子:
A={a,b},B={c,d}A*B ={(a,c),(b,c),(a,d),(b,d)}
-
语法:select 字段名称 from 表1, 表2
查询出运营部的部门信息及该部门下的员工信息:
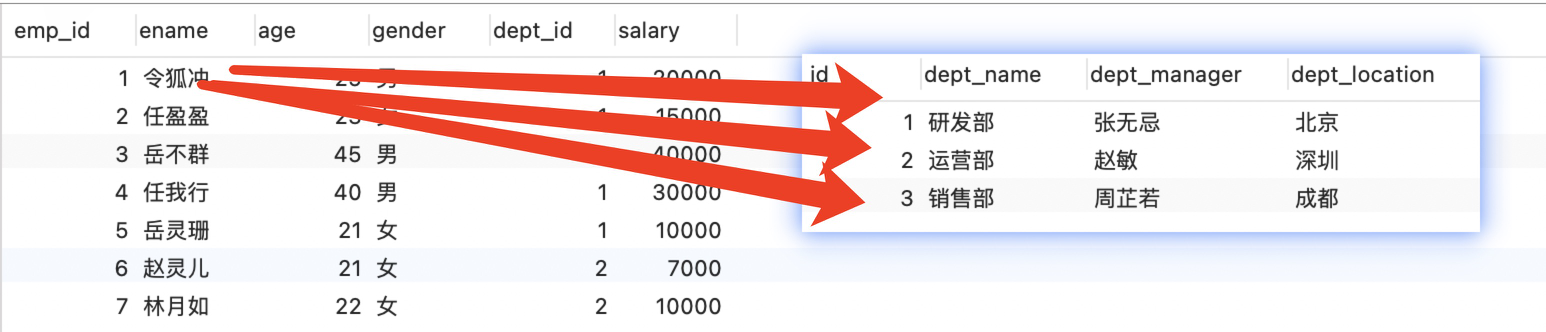
select * from dept, emp_part where dept.id=emp_part.dept_id and dept.id=2;
5.多表查询-内连接查询
内连接的定义:
- 内连接(INNER JOIN):使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行,组合成新的记录。匹配上显示,匹配不上不显示。
- 例子: 比如使用外键=主键这个条件过滤掉无效数据
- 按语法结构分为: 隐式内连接和显式内连接
隐式内连接:
-
在笛卡尔积的的基础上,使用where条件过滤无用的数据,这种连接方式是隐式内连接.
-
语法:select [字段名称] from 表1,表2 where [条件]
-
例1: 筛选出运营部的员工的id,姓名以及所在城市
SELECT emp_id,ename,dept_location FROM emp_part,dept WHERE dept_id=id and dept_name="运营部";
显式内链接:
INNER关键字可以省略
SELECT column1, column2, ...
FROM table1
JOIN table2
ON table1.column = table2.column;
SELECT column1, column2, ...
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
6.多表查询-外连接查询
外连接介绍:
-
外连接查询:查询多个表中相关联的行,有时候需要包含没有关联的行中数据,即返回查询结果集合中不仅包含符合连接条件的行,还包括左表(左连接)、右表(右连接)中的所有数据行。
-
左外连接 , 使用 LEFT OUTER JOIN , OUTER 可以省略
-
右外连接 , 使用 RIGHT OUTER JOIN , OUTER 可以省略
左连接:
-
左连接:以左表为基准匹配右表的数据,右表中没有的项,显示为空
-
语法:SELECT [字段] FROM [左表] LEFT JOIN [右表] ON [条件]
-
例子:公司新成立人力资源部,还未招聘员工,请使用左连接查询方式查询出公司所有部门员工的员工号,姓名,性别以及他们所在的部门名称和城市
#向部门表中插入人力资源部
INSERT INTO dept VALUES(4,'人力资源部','甄嬛','北京');
#查询出需要的数据
SELECT emp_id,ename,gender,dept_name,dept_location FROM dept LEFT JOIN emp_part ON dept.id=emp_part.dept_id
右连接:
-
右连接:以右表为基准匹配左表的数据,左表中没有的项,显示为空
-
语法:SELECT [字段] FROM [左表] RIGHT JOIN [右表] ON [条件]
-
使用右连接的方式查询出所有员工信息以及他们所在的部门名称和城市
SELECT emp_id,ename,gender,dept_name,dept_location FROM dept RIGHT JOIN emp_part ON dept.id=emp_part.dept_id
7.子查询简介
-
定义:子查询指一个查询语句嵌套在另一个查询语句内部,在SELECT子句中先计算子查询,子查询的结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。 这个特性从MySQL 4.1开始引入。
-
子查询作为过滤条件时需要用
()包裹
子查询的常见分类:
- From型子查询:将子查询的结果作为父查询的表来使用
- in/not in 型子查询:子查询的结果是单列多行,作为where的过滤条件
- where型子查询:查询结果作为过滤条件出现在比较运算符的一端
带From关键字的子查询:
- 子查询是一张多行多列的表,将子查询作为父查询的表来嵌套查询
- 子查询语句必须用()包裹且需要有别名
- 计算出各部门性别为男性的员工人数
select
dept_name,
count( emp_id )
from
( select dept_name, emp_id, ename, gender from dept inner join emp_part where id = dept_id and gender = '男' ) b
group by
dept_name;
带IN关键词的子查询
- 将子查询作为where语句后的过滤条件,常用于子查询结果是单列多行的情况
- 子查询语句必须用()包裹
- in/not in
- 查询出北京地区所有的员工信息
SELECT
*
FROM
emp_part
WHERE
dept_id IN (
SELECT
id
FROM
dept
WHERE
dept_location = '北京')
带比较运算符的子查询:
- 将子查询的结果作为过滤条件,放在比较运算符的一端
- 常用于子查询结果为单个结果的情况
- 子查询语句必须用()包裹
#查询出薪资大于公司平均薪资的员工id,姓名及薪资
SELECT
emp_id,
ename,
salary
FROM
emp_part
WHERE
salary > ( SELECT AVG( salary ) FROM emp_part );
with…as
-
如果一整句查询语句中,某个子查询的结果会被多个父查询引用,通常建议将共用的子查询用简写表示出来
-
语法: with [表名] as ( select… )
# 查询出部门平均薪资大于公司平均薪资的部门名称,部门主管,所在地及部门平均薪资
# 不使用 with ...as
select
dept_id,
dept_name,
dept_manager,
dept_location,
avg_salary
from
dept
inner join ( select dept_id, avg( salary ) avg_salary from emp_part group by dept_id ) b on id = dept_id
and avg_salary > ( select avg( avg_salary ) from ( select dept_id, avg( salary ) avg_salary from emp_part group by dept_id ) b );# 使用 with ...as
with dept_avg as ( select dept_id, avg( salary ) avg_salary from emp_part group by dept_id ) select
dept_id,
dept_name,
dept_manager,
dept_location,
avg_salary
from
dept
inner join dept_avg on id = dept_id
and avg_salary > ( select avg( avg_salary ) from dept_avg );
8.子查询实战
某软件销售公司2022年1月销售数据分析,项目介绍:
- A公司是一家软件产品销售公司,在北京,上海,深圳,成都,杭州都设有销售部门,其中销售部门分布如下:
- 北京有3个销售部门,分别为bj001,bj002,bj003
- 上海有三个销售部门为:sh001,sh002,sh003
- 深圳有两个销售部门为:sz001,sz002
- 成都有一个销售部门为:cd001
- 杭州有一个销售部门为:hz001
- department表中记录了部门相关的信息
- sales_list表中记录了最近2周各部门的销售订单相关数据
项目需求:
需求1:在mysql中创建数据库test_db1 并导入相关数据:
- 部门表字段
- dept_id 部门id
- city 所在城市
- manager 部门经理
- 订单表
- dept_id 部门id
- order_id 订单号
- volume 客单价
- sales_date 销售日期
需求2:计算出各部门最近两周的的总销售业绩,并按业绩由高到低显示:
# 计算出各部门最近两周的总业绩,并按业绩由高到低排名
SELECT
order_list.dept_id,
city,
manager,
SUM( volume ) total_volume
FROM
order_list
INNER JOIN department ON order_list.dept_id = department.dept_id
GROUP BY
order_list.dept_id
ORDER BY
SUM( volume ) DESC
需求3:查询出最近两周的销售额超过全公司平均销售额的部门
WITH temp_dept AS (
SELECT
order_list.dept_id,
city,
manager,
SUM( volume ) total_volume
FROM
order_list
INNER JOIN department ON order_list.dept_id = department.dept_id
GROUP BY
order_list.dept_id
ORDER BY
SUM( volume ) DESC
) SELECT
*
FROM
temp_dept
WHERE
total_volume >(
SELECT
AVG( total_volume )
FROM
temp_dept)
视图:
- 定义:视图是一种虚拟的表,它并不会在你的存储空间复制一份数据,而是对原有数据的一种引用。可以将视图理解为一种存储起来的sql语句
- 视图可以简化多表查询
- 视图也可以用于控制用户权限
- 使用关键词view来创建视图
- 语法:CREATE VIEW [视图名称] AS SELECT…..
CREATE VIEW temp_dept AS (
SELECT
order_list.dept_id,
city,
manager,
SUM( volume ) total_volume
FROM
order_list
INNER JOIN department ON order_list.dept_id = department.dept_id
GROUP BY
order_list.dept_id
ORDER BY
SUM( volume ) DESC
);
SELECT
*
FROM
temp_dept
WHERE
total_volume >(
SELECT
AVG( total_volume )
FROM
temp_dept
);#查询出最近两周的冠军销售部门
SELECT * FROM temp_dept WHERE total_volume=(SELECT max(total_volume) FROM temp_dept);
9.数据库进阶
10.redis 内存数据库
11.mongodb nosql 数据库
12.neo4j 图数据库