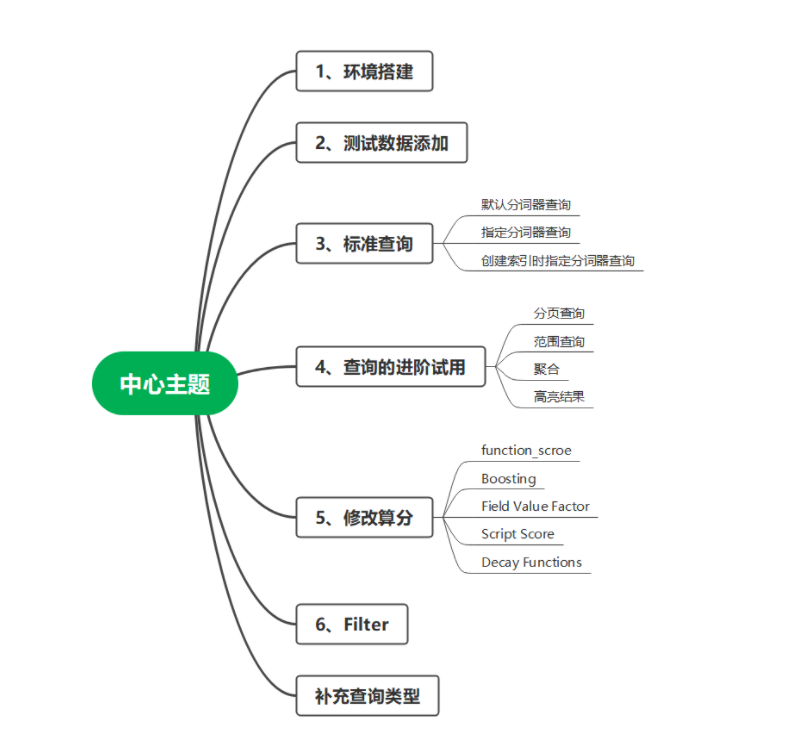
还是惯例,开头先放章节目录,如果有帮到你的地方,欢迎点赞关注转发,如有错误,欢迎指出,不胜感激
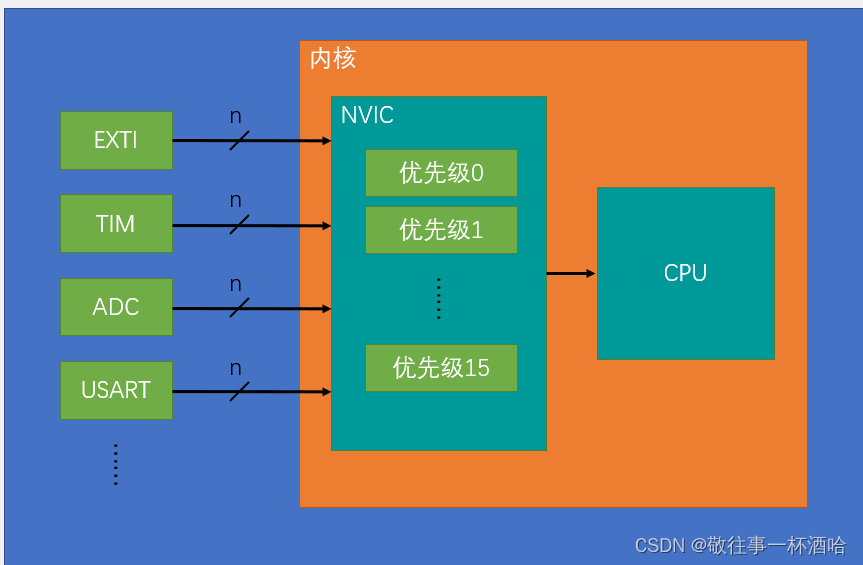
一、环境初始化
version: '3.8'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://eshot:9200
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:8.1.3
container_name: kibana
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
- ELASTICSEARCH_HOSTS=http://eshot:9200
- server.publicBaseUrl=http://192.168.160.234:5601
ports:
- "5601:5601"
networks:
- elastic
eshot:
image: elasticsearch:8.1.3
container_name: eshot
environment:
- node.name=eshot
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=hot
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\eshot\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\eshot\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
networks:
- elastic
eswarm:
image: elasticsearch:8.1.3
container_name: eswarm
environment:
- node.name=eswarm
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=warm
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\eswarm\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\eswarm\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
networks:
- elastic
escold:
image: elasticsearch:8.1.3
container_name: escold
environment:
- node.name=escold
- cluster.name=es-docker-cluster
- discovery.seed_hosts=eshot,eswarm,escold
- cluster.initial_master_nodes=eshot,eswarm,escold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- xpack.security.enabled=false
- node.attr.node_type=cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- D:\zuiyuftp\docker\es8.1\escold\data:/usr/share/elasticsearch/data
- D:\zuiyuftp\docker\es8.1\escold\logs:/usr/share/elasticsearch/logs
- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/plugins
networks:
- elastic
# volumes:
# eshotdata:
# driver: local
# eswarmdata:
# driver: local
# escolddata:
# driver: local
networks:
elastic:
driver: bridge
二、测试数据添加
创建测试索引
PUT /zfc-doc-000001
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":2
}
},
"mappings": {
"properties": {
"title":{
"type":"keyword"
},
"content":{
"type":"text"
},
"createTime":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"agreeNum":{
"type": "integer"
},
"comment":{
"type": "nested",
"properties": {
"content":{
"type":"text"
},
"name":{
"type":"keyword"
},
"time":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
}
2.1、添加测试数据
PUT _bulk
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "1" } }
{ "title" : "Java知识点大全","content":"java 泛型,基本类型有哪些","createTime": "2022-12-19","agreeNum":"99","comment":{"name":"张三","content":"学习java必备","time":"2022-12-19 09:00:00"} }
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "2" } }
{ "title" : "MySQL必知必会","content":"mysql 索引、事务、锁","createTime": "2022-12-18","agreeNum":"500","comment":[{"name":"张三","content":"学习mysql通俗易懂","time":"2022-12-18 09:00:00"},{"name":"李四","content":"mysql 入门到精通必备的","time":"2022-12-18 10:00:00"} ]}
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "3" } }
{ "title" : "Redis运维实战","content":"redis的rdb与aof","createTime": "2022-12-18","agreeNum":"300","comment":[{"name":"小红","content":"redis的备份","time":"2022-12-18 09:00:00"},{"name":"李四","content": "redis 入门","time":"2022-12-18 15:00:00"} ]}
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "4" } }
{ "title" : "Elasticsearch","content":"ES crud","createTime": "2022-12-17","agreeNum":"300","comment":[{"name":"小红","content":"es的基础SQL语法","time":"2022-12-17 09:00:00"},{"name":"李四","content": "es 入门","time":"2022-12-18 16:00:00"} ]}
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "5" } }
{ "title" : "常见MQ知识点汇总","content":"rabbitmq kafka rockmq activemq","createTime": "2022-12-16","agreeNum":"260","comment":[{"name":"小红","content":"kafka的基础概念","time":"2022-12-18 09:00:00"},{"name":"李四","content": "事务消息","time":"2022-12-18 15:00:00"} ]}
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "6" } }
{ "title" : "ES奇淫技巧","content":"玩转es","createTime": "2022-12-18","agreeNum":"600","comment":[{"name":"小红1号","content":"es的基础SQL语法","time":"2022-12-17 09:00:00"},{"name":"李四1号","content": "es 入门","time":"2022-12-18 16:00:00"} ]}
{ "index" : { "_index" : "zfc-doc-000001", "_id" : "7" } }
{ "title" : "ES","content":"真的666","createTime": "2022-12-17","agreeNum":"300","comment":[{"name":"小红1号","content":"es的基础SQL语法","time":"2022-12-17 09:00:00"},{"name":"李四1号","content": "es 入门","time":"2022-12-18 16:00:00"} ]}
三、标准查询语句使用
根据一个字段进行检索,假如我们要搜索content包含ES的文档,我们的查询语句可以这样写
GET zfc-doc-000001/_search
{
"query": {
"match":{
"content":"ES"
}
}
}
上面这个语句的意思简单理解就是查询content字段中包含ES的文档。在深一层次来看,首先查看content字段的类型,通过查看上面的创建索引语句可以知道,content字段定义的是text类型,所以Elasticsearch会对content字段进行分词检索,返回文档中出现es的,除了上面这种写法外还可以使用如下几种方式进行检索
# 分词匹配es或者crud的文档
GET zfc-doc-000001/_search
{
"query": {
"match":{
"content":"ES crud"
}
}
}
# 短语查询分词es
GET zfc-doc-000001/_search
{
"query": {
"match_phrase":{
"content":"es"
}
}
}
# 前缀检索分词es
GET zfc-doc-000001/_search
{
"query": {
"prefix":{
"content":"es"
}
}
}
# 模糊匹配分词es
GET zfc-doc-000001/_search
{
"query": {
"fuzzy":{
"content":"es*"
}
}
}
为了查询结果的更精确,增加title字段为ES的约束条件,需要注意大小写,因为title字段类型为keyword,不区分大小写的,所以查询语句可以这样写
该语句返回content字段中分词匹配词语ES(不区分大小写)的文档或者title字段精确匹配ES的文档
GET zfc-doc-000001/_search
{
"query": {
"multi_match": {
"query": "ES",
"fields":["content","title"]
}
}
}
一个简单的检索语句通过上述几种方式即可实现了,但是实际工作中,肯定还是用到分词器的,下面就以常用的IK分词器进行说明
3.1、查询时指定分词器
首先是第一种查询时指定分词器的形式进行检索
GET /zfc-doc-000001/_search
{
"query": {
"match": {
"content": {
"query": "es",
"analyzer": "ik_max_word"
}
}
}
}
通过上面指定分词器的形式,我们在查询时就可以使用ik_max_word来作为检索分词来处理了,我们也可以在创建索引时增加字段分词的配置,方便检索时默认使用指定分词器检索,下面就是创建索引指定分词器的步骤
3.2、初始化默认分词器
1、删除刚才创建的索引
DELETE zfc-doc-000001
2、修改content字段,加入分词器ik_max_word,修改部分如下
"content":{
"type":"text",
"analyzer": "ik_max_word"
}
完整的语句如下所示
PUT /zfc-doc-000001
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":2
}
},
"mappings": {
"properties": {
"title":{
"type":"keyword"
},
"content":{
"type":"text",
"analyzer": "ik_max_word"
},
"createTime":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"agreeNum":{
"type": "integer"
},
"comment":{
"type": "nested",
"properties": {
"content":{
"type":"text"
},
"name":{
"type":"keyword"
},
"time":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
}
通过上面语句创建完索引之后,content字段就是使用ik_max_word分词的了,这样使用普通的match查询即可,这里也就不再演示了
GET zfc-doc-000001/_search
{
"query": {
"match":{
"content":"es"
}
}
}
四、查询的进阶使用
4.1、分页查询
我们可以使用from和size参数配置使用,其中from为要跳过的文档数量,size为要返回的文档数量
在全部文档中,过滤前两个文件,从第3个文档开始,返回10个文档
GET zfc-doc-000001/_search
{
"query": {
"match_all": {
}
},
"size": 10,
"from": 2
}
4.2、范围查询
对于范围查询,我们可以使用range查询,最简单的参数就是gte与lte
GET zfc-doc-000001/_search
{
"query": {
"range": {
"agreeNum": {
"gte": 100,
"lte": 300
}
}
}
}
4.3、聚合
聚合语法的使用就是对一个文档中某个字段的统计,类似与关系型数据库中的先group 在count一个字段的值,具体使用如下,如果我们不想返回都是哪些数据参与了聚合,还可以加入参数"size":0,如下语句中,其中my_aggs是自定义聚合的名称,terms是聚合的类型,field是要对哪个字段进行聚合,需要注意的是text类型是无法使用聚合的,terms下面的"size":10是指如果聚合桶的数量超过10的话只取前10个
GET zfc-doc-000001/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"my_aggs": {
"terms": {
"field": "title",
"size": 10
}
}
}
}
Elasticsearch支持多种聚合类型,每种类型都有不同的功能和用途。以下是一些常用的聚合类型及其含义:
-
Terms Aggregation(词条聚合):根据指定字段的值进行分组,并计算每个分组的文档数量。可以用于统计某个字段的分布情况。
-
Range Aggregation(范围聚合):将指定字段的值划分为不同的范围,并计算每个范围内的文档数量。可用于分析数值型字段的分布情况。
-
Date Histogram Aggregation(日期直方图聚合):根据指定日期字段的值进行分组,并按照时间间隔(如按月、按周)计算每个时间段内的文档数量。
-
Histogram Aggregation(直方图聚合):根据指定字段的值进行分组,并按照指定的间隔计算每个分组的文档数量。适用于分析数值型字段的分布情况。
-
Average Aggregation(平均值聚合):计算指定字段的平均值。
-
Sum Aggregation(求和聚合):计算指定字段的总和。
-
Min Aggregation(最小值聚合):计算指定字段的最小值。
-
Max Aggregation(最大值聚合):计算指定字段的最大值。
-
Cardinality Aggregation(基数聚合):计算指定字段的唯一值的数量。
-
Stats Aggregation(统计聚合):计算指定字段的统计信息,包括最小值、最大值、平均值、总和和文档数量。
这只是一小部分聚合类型的示例,Elasticsearch还提供了其他类型的聚合,如Percentiles Aggregation(百分位数聚合)、Extended Stats Aggregation(扩展统计聚合)等。你可以根据你的具体需求选择适合的聚合类型,并结合查询条件和其他聚合层级来进行复杂的数据分析和统计。
如果你看到这了,欢迎点个关注、后续推文深度只会越来越深,期待你的关注,让我们共同进步
elasticsearch还支持嵌套聚合,只需要在aggs里面在写一个aggs即可,可以参考如下写法,对该示例不符合,仅供参考
GET /zfc-doc-000001/_search
{
"size": 0,
"aggs": {
"my_aggs1": {
"terms": {
"field": "field1"
},
"aggs": {
"my_aggs2": {
"terms": {
"field": "field2"
},
"aggs": {
"avg_value": {
"avg": {
"field": "numeric_field"
}
}
}
}
}
}
}
}
4.4、高亮结果
如果我们想在返回结果中对命中的关键词进行高亮显示可以使用如下语句
GET zfc-doc-000001/_search
{
"query": {
"match": {
"content": "ES"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
默认是在返回结果中加入em标签,如果我们想自定义标签可以使用如下语句,如下示例是改为了strong标签
GET zfc-doc-000001/_search
{
"query": {
"match": {
"content": "es"
}
},
"highlight": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"],
"fields": {
"content": {}
}
}
}
五、修改算分提升匹配度
5.1、function_score
假设我们的原始查询语句如下
GET zfc-doc-000001/_search
{
"query": {
"match": {
"content": "es"
}
}
}
返回结果如下,ID为6的排在了第一位
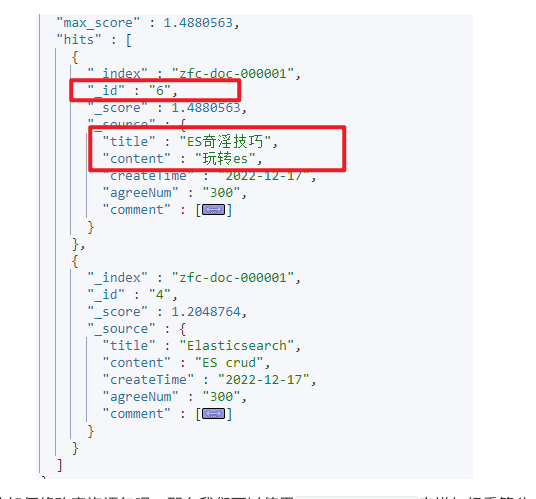
如果我们想让ID为4的排在第一位如何修改查询语句呢,那么我们可以使用function_score来增加权重算分,比如使用title中匹配Elasticsearch的
此处是为举例,要学习思想,以后工作中才有更好的思路
修改之后的查询语句如下
GET zfc-doc-000001/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "es"
}
},
"functions": [
{
"filter": {
"term": {
"title": "Elasticsearch"
}
},
"weight":2
}
],
"score_mode": "multiply",
"boost_mode": "multiply"
}
}
}
可以看到,显示结果已经发生改变,ID为4的算分已经高于ID为6的算分了
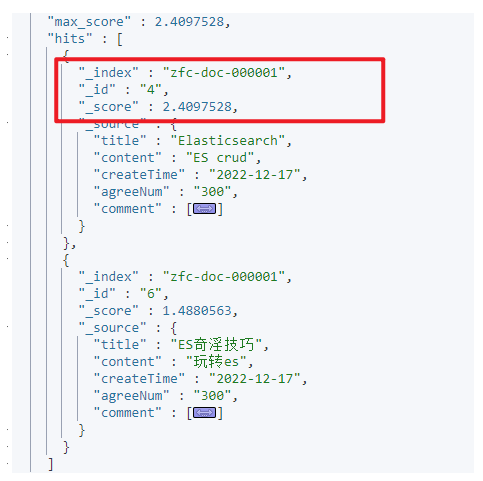
其中,query参数用于指定正常的查询语句,functions参数用于定义一个或多个函数来修改文档得分
score_mode和boost_mode是用于控制function_score查询中如何计算文档得分和如何影响文档的排名的参数。
-
score_mode:参数用于指定多个函数如何组合计算得分。它支持以下取值:-
multiply: 将所有函数的得分相乘 -
sum: 将所有函数的得分相加 -
avg: 将所有函数的得分求平均值 -
max: 取所有函数的最大得分作为文档得分 -
min: 取所有函数的最小得分作为文档得分 -
first: 取第一个函数的得分作为文档得分 -
weighted_sum: 将所有函数的得分相加,并乘以给定的权重系数。
-
-
boost_mode参数用于指定得分如何影响文档的排名。它支持以下取值:-
multiply: 将得分与文档的原始得分相乘 -
replace: 使用得分替换文档的原始得分 -
sum: 将得分与文档的原始得分相加 -
avg: 将得分与文档的原始得分求平均值 -
max: 取得分和文档的原始得分的最大值作为文档得分 -
min: 取得分和文档的原始得分的最小值作为文档得分
-
请注意,score_mode和boost_mode参数的取值会影响文档得分和排名的计算方式,需要根据具体的需求来选择合适的取值。另外,function_score查询中可以定义多个函数来修改文档得分,也可以使用weight函数来给定固定的分值,这些函数的组合和参数设置可能会对结果产生重要影响。
除了使用上述方式外,还可以使用如下几种方式进行算分的修改
5.2、Boosting
如下是匹配content字段中包含es的,对content中包含es的进行减分
GET zfc-doc-000001/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"content": "es"
}
},
"negative": {
"term": {
"content": "玩转"
}
},
"negative_boost": 0.5
}
}
}
5.3、Field Value Factor
需要注意的是,
field_value_factor函数用于根据字段的数值进行打分计算,要求字段是数值类型的。
我们使用Field Value Factor来根据字段agreeNum的值对包含ES关键词的文档进行加权。使用log1p修饰符可以将字段值的对数应用于计算
GET zfc-doc-000001/_search
{
"query": {
"match": {
"content": "ES"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
GET zfc-doc-000001/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "ES"
}
},
"field_value_factor": {
"field": "agreeNum",
"factor": 0.1,
"modifier": "log1p"
}
}
},
"sort": [
{
"_score": {
"order": "asc"
}
}
]
}
其中field_value_factor的参数含义如下
-
field: 要计算得分的字段名 -
factor: 一个乘数,用于缩放字段值的影响。可以使用任何非负数值。假如factor的值是 0.1,表示字段值的影响将会被减小 -
modifier: 一个修饰符,用于对数值进行修改以调整得分-
none:不应用任何修饰符,默认情况下为1 -
log:对计算结果取对数,以减少较大值的影响 -
log1p:与log类似,但在计算结果前先加1,可以避免对0值进行对数运算
-
5.4、Script Score
我们可以使用script_score来自定义计算得分,此处仅为示例,具体可以根据自己的业务来修改。具体计算分可以通过explain来查看验证
GET zfc-doc-000001/_search
{
"explain": true,
"query": {
"function_score": {
"query": {
"match": {
"content": "es"
}
},
"script_score": {
"script": {
"source": "Math.log(doc['agreeNum'].value + 10)"
}
}
}
}
}
5.5、Decay Functions
我们使用Gauss衰减函数根据字段createTime的值来衰减文档的得分。在这个例子中,以2022-12-01为中心,每过10天,得分将衰减一半。参考结果可以使用下面两个查询语句对应
GET zfc-doc-000001/_search
{
"query": {
"match": {
"content": "es"
}
}
}
GET zfc-doc-000001/_search
{
"query": {
"function_score": {
"query": {
"match": {
"content": "es"
}
},
"functions": [
{
"gauss": {
"createTime": {
"origin": "2022-12-01",
"scale": "10d"
}
}
}
]
}
}
}
六、Filter
Filter和Query是Elasticsearch中用于检索和过滤数据的两种不同方式,它们各自有一些优缺点
Filter的优点:
-
性能更高:Filter对结果进行缓存,可以重复使用缓存结果,提高查询的性能。当使用相同的过滤条件进行多次查询时,Filter可以避免重复计算 -
精确性更高:Filter对结果进行精确匹配,只返回满足过滤条件的文档,不计算相关性得分。这使得Filter非常适用于那些不需要考虑相关性的精确匹配查询 -
可缓存性:Filter的结果可以被缓存,可以在后续的查询中重复使用。如果数据没有变化,那么缓存的结果可以直接返回,减少了计算的开销
Filter的缺点:
-
无法计算相关性得分:Filter不计算相关性得分,因此无法进行排序或评分。如果需要根据文档的相关性进行排序或评分,就需要使用Query -
不支持全文搜索:Filter只能进行精确匹配,无法进行全文搜索。如果需要进行全文搜索,就需要使用Query
Query的优点:
-
支持全文搜索:Query可以进行全文搜索,可以对文本进行分词和相关性评分,返回与查询条件最匹配的文档 -
支持排序和评分:Query可以根据文档的相关性得分进行排序和评分,使得搜索结果更具有相关性 -
灵活性更高:Query提供了更多的查询选项和查询语法,可以进行复杂的查询操作,包括布尔逻辑、范围查询、模糊查询等
Query的缺点:
-
性能相对较低:Query需要计算相关性得分,并对所有文档进行评分和排序,因此相对于Filter而言,性能较低 -
无法缓存结果:由于Query计算的是相关性得分,结果会随着数据的变化而变化,无法进行缓存和重复使用
综上所述,Filter适用于需要精确匹配和高性能的查询场景,而Query适用于需要全文搜索、排序和评分的场景。根据具体的需求和性能要求,选择合适的过滤方式可以提高查询的效率和准确性
补充
Elasticsearch的查询DSL语句中有很多常用的参数,用于指定查询的条件和行为。以下是一些常用的查询:
-
match: 使用match查询参数可以执行全文本搜索,它会将查询字符串分析为词项并与文档进行匹配 -
term:term查询参数用于精确匹配某个字段的值,不进行分析 -
bool:bool查询参数用于组合多个查询条件,如must(与操作)、should(或操作)、must_not(非操作) -
range:range查询参数用于匹配指定范围内的值,可以用于数值、日期等类型的字段 -
exists:exists查询参数用于匹配包含指定字段的文档 -
prefix:prefix查询参数用于匹配以指定前缀开头的字段值 -
wildcard:wildcard查询参数用于支持通配符匹配,如使用*和?进行模糊匹配 -
fuzzy:fuzzy查询参数用于执行模糊匹配,可以处理拼写错误或相似度较高的查询字符串 -
match_phrase:match_phrase查询参数用于匹配包含指定短语的文档 -
multi_match:multi_match查询参数用于在多个字段中执行全文本搜索 -
terms:terms查询是一种多词项查询,用于查找包含给定词项中任何一个的文档 -
match_phrase_prefix:match_phrase_prefix查找包含指定短语前缀的文档。它可以通过指定一个短语前缀和一个最大扩展长度来实现 -
regexp:regexp是使用正则表达式匹配文档的,能够在文本字段中匹配符合正则表达式的文本,从而检索文档
本文由 mdnice 多平台发布