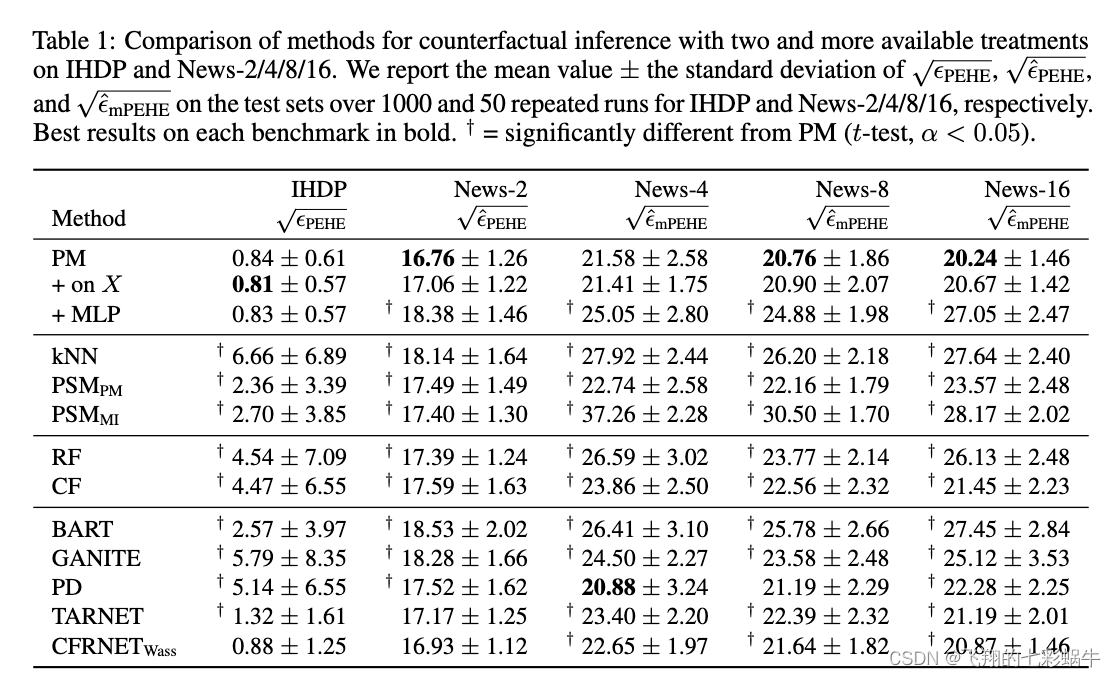
背景
最近被问了几次nutsdb事务是怎么实现的,也就是并发控制是怎么做的。我说,用一把大的读写锁,写事务拿到写锁,读事务拿读锁,这样子做的。提问者先是震惊,接着说是有一点鄙夷,我感觉大概心里是在想,怎么这么low啊。我感觉用读写锁也还好,应该也不至于那么不堪吧。为什么呢?这篇文章记录了我在这个过程中的一些思考和探索,里面有一些属于个人观点。如若有说的不对的地方,还请多多指正。
为什么会觉得读写锁不太行呢?
我们先来一波理论分析,为什么提问者会感觉读写锁不是很可以呢?读写并发有四种情况,读读,写写,读写,写读。读写锁在处理写事务的时候是会阻塞住读事务,写写就没什么好说的,必定互斥,读读可以并发。
在这个逻辑下,可以保证数据的安全和一致性,因为对数据有修改的操作都是在互斥的环境下执行。不过互斥会影响一些性能啦,因为你在写东西的时候别人都不可以做事了。所以如果能解放一部分互斥环境下并发操作,这样就会带来一些性能提升。
如果我们用MVCC做多版本控制,毕竟bitcask天生就是会存多版本的数据的,每个读写操作在刚开始的时候拿到一个属于自己的版本,而不是读锁或者写锁,那么读写就存在一定的并发空间,从而释放一定的读写并发能力。至于MVCC怎么做这里就不多赘述了,这是个很大的话题,容我后面补一篇文章说明。
但是事实真的是这样吗?是的,至少在理论上。但是我认为,在bitcask模型中,乃至在存储引擎中,思考问题应该要将磁盘IO操作对性能的影响纳入思考范围内。如果都是内存操作,并发能力的提升当然给程序带来巨大的提升,但是如果要把磁盘带上,就不一定了。为什么?
为什么要考虑磁盘IO操作对性能的影响?
在过去几十年的时间里,计算机各个部分的硬件取得了飞跃性的发展,但是每个组件之间的性能差距同时也越拉越大。一个一分钟7200转的硬盘,完成一次磁盘读取大概要9ms,但是一台台500 -MIPS的机器这时候可以完成几十万条指令。
在这个背景下,让我们把思绪回到bitcask模型中。数据写入的时候会先写入到wal中,防止数据丢失,不过现在有一些存储引擎实现了一些策略,可以做个buffer,buffer满了之后再批量写入,或者做个批量数据写入,提升性能嘛,毕竟每一条数据都直接写磁盘也蛮奢侈的。这时候就是看用户对数据完整性的要求了,因为这里可能会丢失一些数据。这些都不是什么大事,反正最后都是要写磁盘的。
至于读取,bitcask不像基于LSM实现的存储引擎那样,可以在memtable或者block cache中读取数据。bitcask读取数据是会去磁盘中读取的。
综上,无论读写,bitcask都需要都需要和磁盘打交道。那么这个时候读写锁和版本控制这两种并发方式的性能差异真的有那么重要吗?锁资源的并发增强对比起IO的开销,我认为是萤火和皓月的区别,所以我感觉读写锁也没有那么不堪,甚至好像还可以。
怀着这样的想法,我在电脑上简单的做了个实验,验证一下这个想法。
做一下实验
怎么实验呢。我的想法是简单模拟读写锁和版本控制的逻辑,读写操作就做简单的读取和写入一些数据。大致探究在不同的读写操作比例上的性能差异,比如读操作占总操作的百分之90,性能对比如何,读操作占10%,性能对比如何。好,让我们马上进入实验环节。
模拟版本控制的并发读写方式:
type VersionControlWriter struct {
version atomic.Value
fd *os.File
}
func (vw *VersionControlWriter) Write() {
vw.increase()
vw.fd.Write([]byte(writeStr))
}
func (vw *VersionControlWriter) Read() {
vw.increase()
vw.fd.ReadAt(readBytes, 0)
}
func (vw *VersionControlWriter) increase() {
v := vw.version.Load().(int)
v++
vw.version.Store(v)
}
可以看到就是简单的用一个原子变量来代表读写事务的版本。每次读写事务开始操作之前,先通过原子变量自增的方式来获取事务版本,保证每个事务都获得自增的,独一无二的id。
至于写入的话是把hello world以追尾的方式写入磁盘。读取的话是读取文件开头的第一条Hello world。
读写锁并发读写方式模拟:
type RWLockWriter struct {
lock sync.RWMutex
fd *os.File
}
func (rw *RWLockWriter) Write() {
rw.lock.Lock()
defer rw.lock.Unlock()
rw.fd.Write([]byte(writeStr))
}
func (rw *RWLockWriter) Read() {
rw.lock.RLock()
defer rw.lock.RUnlock()
rw.fd.ReadAt(readBytes, 0)
}
可以看到,读写锁的方式读取写入的数据都是一样的。最大程度保持两边实验环境的相似程度。我把这两个结构体抽象成一个接口ReadWrite,在流量控制的时候抽象成一个函数。代码如下所示。
type ReadWrite interface {
Read()
Write()
}
func flowControl(threshold int, rw ReadWrite) {
seed := rand.Intn(100)
if seed < threshold {
rw.Write()
} else {
rw.Read()
}
}
我用一个随机数来分配读写流量。随机数的算法都有等概率性,所以可以放心用它来做流量切分。另外在这段代码中我们可以看到的是,对于版本控制来说,不管读写有没有冲突,也不管数据一致性的情况,只要有读操作我就立马读,这样子对于这个实验来说,其实他的实现效果会偏好。
然后我们在go中写下一个benchmark.
func BenchmarkWriterPerformance(b *testing.B) {
for _, config := range []TestConfig{
{
flowControlThreshold: 20,
},
{
flowControlThreshold: 50,
},
{
flowControlThreshold: 80,
},
} {
rw, vw, err := initTestResources()
if err != nil {
b.Error(err)
}
b.Run(fmt.Sprintf("test the performance for RWLock for flowcontorl %d", config.flowControlThreshold), func(b *testing.B) {
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
flowControl(config.flowControlThreshold, rw)
}
})
})
b.Run(fmt.Sprintf("test the performance for version control flowcontorl %d", config.flowControlThreshold), func(b *testing.B) {
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
flowControl(config.flowControlThreshold, vw)
}
})
})
err = closeTestResources(rw, vw)
if err != nil {
b.Error(err)
}
}
}
让我们运行这个benchmark看看结果:
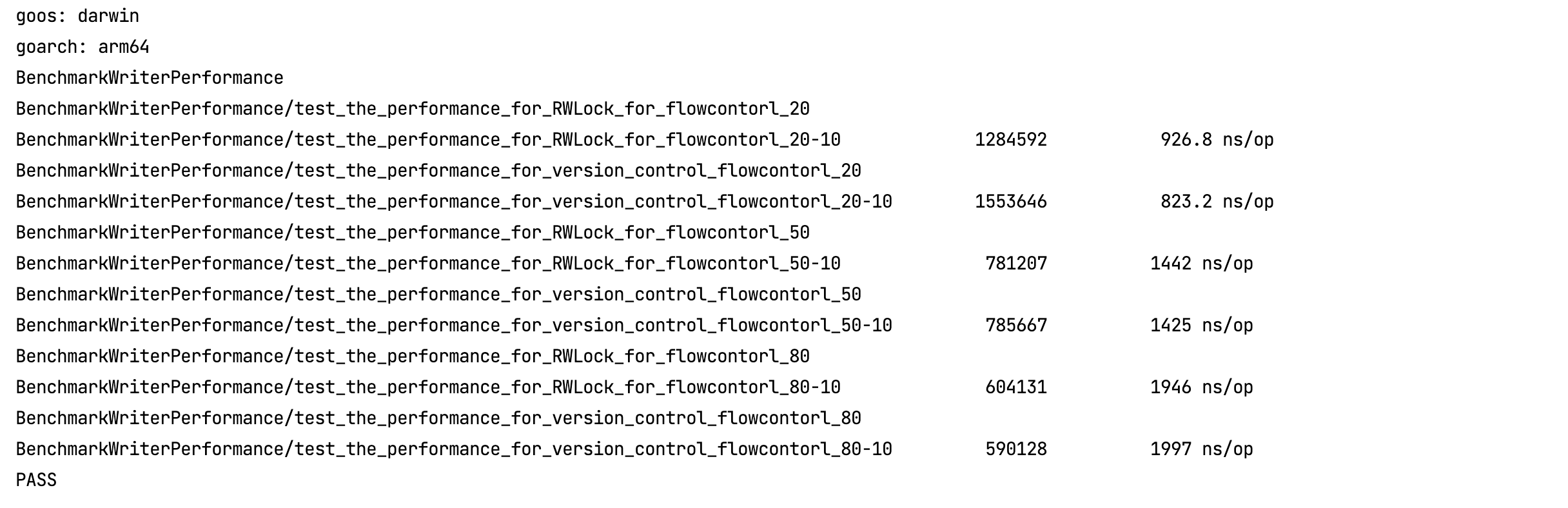
可以看到,在读操作占比比较多的时候,读写锁和版本控制性能上还是有一些差别的。大概20%这样。但是写操作占比越来越大的时候性能上的差距愈发接近。其实这也符合我们之前做的理论分析和假设。
总结
可以看到,对于存储引擎,IO才是最大的瓶颈。那么为什么MySQL要实现MVCC呢。MySQL一般是读多写少,所以做MVCC收益比较大。另外MySQL是有数据缓存在内存的,可能对于大多数读取操作来说,根本不需要磁盘IO去读取。这样一来,又是一大波优化。但是当我们把目光拉会到bitcask,读写操作都需要经过磁盘,批次写只是延迟写入,我认为这样只是降低了写操作的比例,因为几个写操作合并成一个写入磁盘了。本质上没多大差别。
所以这也符合了我一开始心中的想法,读写锁,也没那么不堪。对于基于bitcask模型实现的存储引擎来说。
PS。本人水平有限,这个实验也有一些取巧的地方,另外实验环境实在我的电脑上,实验结果有不具备普遍性结论的可能,大家也可以在自己电脑上运行一下这个代码。代码地址我贴在下面。另外这篇文章个人观点比较多。大家有什么疑问可以联系我,大家一起交流探讨。感谢。
延伸阅读
- 文章中实验代码地址:https://github.com/elliotchenzichang/go-experiment/blob/master/go/writor_test.go