目录
1:公司流程
1.1. 测试用例的4个特性
1.1. 测试用例通常包括以下几个组成元素:
1. 编写测试用例的基本方法
1.1.1. 概念
1.1.1. 示例
1.1练习案例:
1.1. 边界值法
1.1.1. 确定边界值的方法()
1.1. 因果图法
1.1.1. 概念:
1.1.2. 因果图基本图形符号
1.1.1. 因果图的约束符号
1.1.1. 因果图测试用例
1.1. 场景法
1.1.1. 测试用例设计的思想
1.1.1. 银行案例ATM:
1.1. 错误推测法
总结:
1:公司流程
开发:编写概要和详细设计--- 编码并自测(开发环境)
立项(确定项目)--编写需求(需求人员)--需求评审(编写需求人员发起)-- ---------------部署环境(linux)---冒烟测试(通过)--提交bug---回归测试(测试报告)--验收测试--上线
测试: 测试用例--测试用例评审(测试人员发起)
1.1. 测试用例的4个特性
代表性:能够代表并覆盖各种合理的和不合理、合法的和不合法的、边界的和越界的以及极限的输入数据、操作等。
针对性:对程序中的可能存在的错误有针对性地测试
可判定性:测试执行结果的正确性是可判定的,每一个测试用例都应有相应的期望结果
可重现性:对同样的测试用例,系统的执行结果应当是相同的。
1.1. 测试用例通常包括以下几个组成元素:
用例编号、测试模块、用例标题、用例级别、测试环境、测试输入、执行操作、预期结果,实际结果….
1.2测试用例示例


1. 编写测试用例的基本方法
1.1.1. 概念
有效,无效
等价类划分是指分步骤地把海量(无限)的测试用例集减得很小,但过程同样有效。
等价类 :何为等价类,某个输入域的集合,在这个集合中每个输入条件都是等效的。
一般可分为有效等价类和无效等价类
比如:一个青少年考试的分数(备注13-17岁为青少年)
假设青少年年龄为x,13<=x<=17,数学成绩为y:0<=y<=100
那么年龄按照等价类划分可分为x<13,13<=x<=17,x>17,有效等价类是13<=x<=17,无效等价类是x<13,x>17
数学成绩按照等价类划分可分为y<0,0<=y<=100,y>100,有效等价类是0<=y<=100,无效等价类是y<0,y>100
1.1.1. 示例
计算两个1~100之间整数的和。
如果要进行完全测试,一共要设计多少个测试用例呢?
加数1有1~100共计100个取值,加数2也有1~100共计100个取值,所以他们之间的组合就有100*100=10000种组合可能,但这只是测试了正常范围内的取值。如果用户输入的数据不在1~100之间呢,穷举测试肯定不可能的。由此引入了等价类划分思想。
等价类划分为:
有效等价类:指符合《需求规格说明书》,输入合理的数据集合
无效等价类:指不符合《需求规格说明书》,输入不合理的数据集合

我们将输入域分成了一个有效等价类(1~100)和两个无效等价类(<1,>100),并为每一个等价类进行编号,然后我们就可以从每一个等价类中选取一个代表性的数据来测试,设计如下表所示的测试用


1.1练习案例:

划分等价类并编号,下表为等价类划分的结果

1.1. 边界值法
一般边界值分析是因为程序开发循环体时的取数可能会因为<,<=搞错。
比如下面代码
for(int i = 0;i <100; i ++)
{
int j = i+1;
System.out.println("循环第“+j+"次")//循环地做某件事情
}
这里的程序是循环了100次,所以会做100次;
如果程序员不小心,把i <100写成i <= 100,则多循环添加一次,这时候边界值检查是一个很好的测试方法。
比如:在一个系统中,填写一个多少岁的青少年考了多少分(假设成年人年龄为x,13<=x<=17,数学成绩为y:0<=y<=100
根据上面的等价类划分法我们可知,年龄的有效等价类是13<=x<=17,所以边界值就是12, 18
数学成绩的,有效等价类是0<=y<=100,所以边界值就是-1,0,100,101
对数据进行软件测试,就是在检查用户输入的信息、返回的结果以及中间计算结果是否正确。即使最简单的程序要处理的数据量也可能极大,使这些数据得以测试的技巧是,根据一些关键的原则进行等价类的划分,以合理减少测试用例,这些关键的原则是:边界条件,次边界条件、空值和无效数据。
1.1.1. 确定边界值的方法()
选取正好等于、刚刚大于或刚刚小于边界值作为测试数据
输入要求是1 ~ 100之间的整数,因此自然产生了1和100两个边界,我们在设计测试用例的时,要重点考虑这两个边界问题。
[1 100] 上点1 ,100 离点 0 101所属
(1,100) 上点 2,99 离点 1 ,100
(1,100] 上点 2,100 离点 1 ,101

1.1. 因果图法
1.1.1. 概念:
因果图法比较适合输条件比较多的情况,测试所有的输入条件的排列组合。所谓的原因就是输入,所谓的结果就是输出。
1.1.2. 因果图基本图形符号
恒等:若原因出现,则结果出现;若原因不出现,则结果不出现。
非(~):若原因出现,则结果不出现;若原因不出现,则结果出现。
或(∨):若几个原因中有一个出现,则结果出现;若几个原因都不出现,则结果不出现。
与(∧):若几个原因都出现,结果才出现;若其中有一个原因不出现,则结果不出现。

1.1.1. 因果图的约束符号
E(互斥):表示两个原因不会同时成立,两个中最多有一个可能成立
I(包含):表示三个原因中至少有一个必须成立
O(惟一):表示两个原因中必须有一个,且仅有一个成立
R(要求):表示两个原因,a出现时,b也必须出现,a出现时,b不可能不出现
M(屏蔽):两个结果,a为1时,b必须是0,当a为0时,b值不定

1.1.1. 因果图测试用例
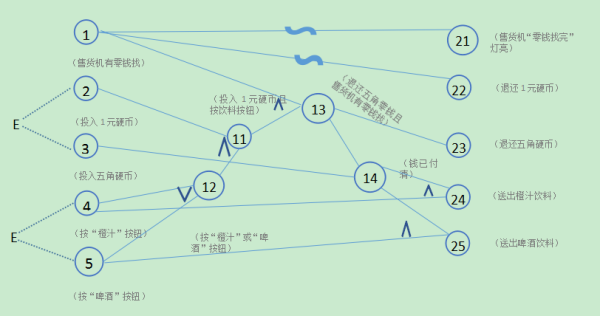
例如:有一个处理单价为2.5元的盒装饮料的自动售货机软件。若投入2.5元硬币,按“可乐”、“啤酒”、或“奶茶”按钮,相应的饮料就送出来。若投入的是3元硬币,在送出饮料的同时退还5角硬币。
分析这一段说明,我们可列出原因和结果
原因(输入):
投入2.5元硬币;
投入3元;
按“可乐”按钮;
按“啤酒”按钮;
按“奶茶”按钮。
中间状态: ① 已投币;②已按钮
结果(输出):
退还5角硬币;
送出“可乐”饮料;
送出“啤酒”饮料;
送出“奶茶”饮料;

1.1. 场景法
1.1.1. 测试用例设计的思想
现在的软件几乎都是用事件触发来控制流程的,事件触发时的情景便形成了场景,而同一事件不同的触发顺序和处理结果就形成事件流。这种在软件设计方面的思想也可以引入到软件测试中,可以比较生动地描绘出事件触发时的情景,有利于测试设计者设计测试用例,同时使测试用例更容易理解和执行。
用例场景是通过描述流经用例的路径来确定的过程,
这个流经过程要从用例开始到结束遍历其中所有基本流和备选流。

遵循上图中每个经过用例的可能路径,可以确定不同的用例场景。从基本流开始,再将基本流和备选流结合起来,可以确定以下用例场景:

基本流和备选流的区别

1.1.1. 银行案例ATM:
个人标识号 (PIN=personal identification number ),用于保护智能卡免受误用的秘密标识代码。PIN 与密码类似,只有卡的所有者才知道该 PIN。只有拥有该智能卡并知道 PIN 的人才能使用该智能卡


第一次测试中,根据测试计划,我们需要核实提款用例已经正确地实施。此时尚未实施整个用例,只实施了下面的事件流:
基本流-提取预设金额(100 元、200元、500元、1000元)
备选流2 - ATM 内没有现金
备选流3 - ATM 内现金不足
备选流4 - PIN 有误
备选流5 - 帐户不存在/帐户类型有误
备选流6 - 帐面金额不足

对于这7个场景中的每一个场景都需要确定测试用例。可以采用矩阵或决策表来确定和管理测试用例。
从确定执行用例场景所需的数据元素入手构建矩阵。然后,对于每个场景,至少要确定包含执行场景所需的适当条件的测试用例。
下面显示了一种通用格式,其中各行代表各个测试用例,而各列则代表测试用例的信息。
本示例中,对于每个测试用例,存在一个测试用例ID、条件(或说明)、测试用例中涉及的所有数据元素(作为输入或已经存在于数据库中)以及预期结果。


1.1. 错误推测法
错误猜测法是测试经验丰富的人喜欢使用的一种测试用例设计方法。
一般这种方法是基于经验和直觉推测程序中可能发送的各种错误,有针对性地设计。只能作为一种补充。
例如,测试手机终端的通话功能,可以设计各种通话失败的情况来补充测试用 例:
1) 无SIM 卡插入时进行呼出(非紧急呼叫)
2) 插入已欠费SIM卡进行呼出
3) 射频器件损坏或无信号区域插入有效SIM卡呼出
4) 网络正常,插入有效SIM卡,呼出无效号码(如1、888、333333、不输入任何号码等)
5) 网络正常,插入有效SIM卡,使用“快速拨号”功能呼出设置无效号码的数字
技巧:最重要的是要思考和分析测试对象的各个方面,多参考以前发现的bug的相关数据,总结的经验,个人多考虑异常的情况、反面的情况、特殊的输入,以一个攻击者的态度对待程序,就能设计出比较完善的测试用例来。
总结:
感谢每一个认真阅读我文章的人!!!
我个人整理了我这几年软件测试生涯整理的一些技术资料,包含:电子书,简历模块,各种工作模板,面试宝典,自学项目等。欢迎大家点击下方名片免费领取,千万不要错过哦。