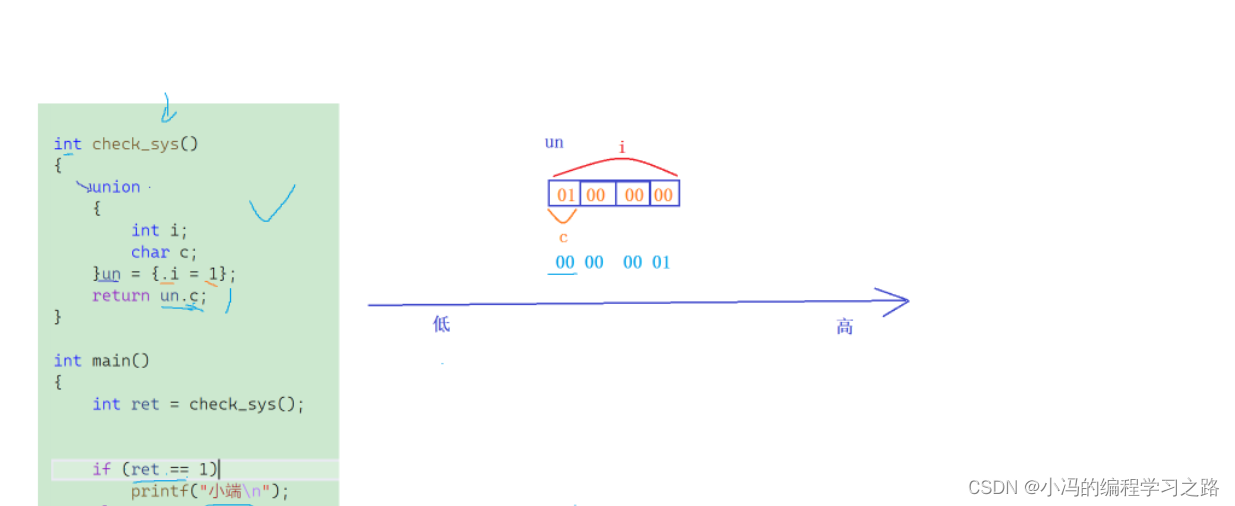
前言
最近在开发需求的时候,用到了select...for update。在代码评审的时候,一位同事说 ,唯一索引+一个非索引字段,是否可能会锁全表呢?本文田螺哥将通过9个实验操作的例子,给大家验证select...for update到底加了什么锁,是表锁还是行锁。
这是本文的提纲哈:
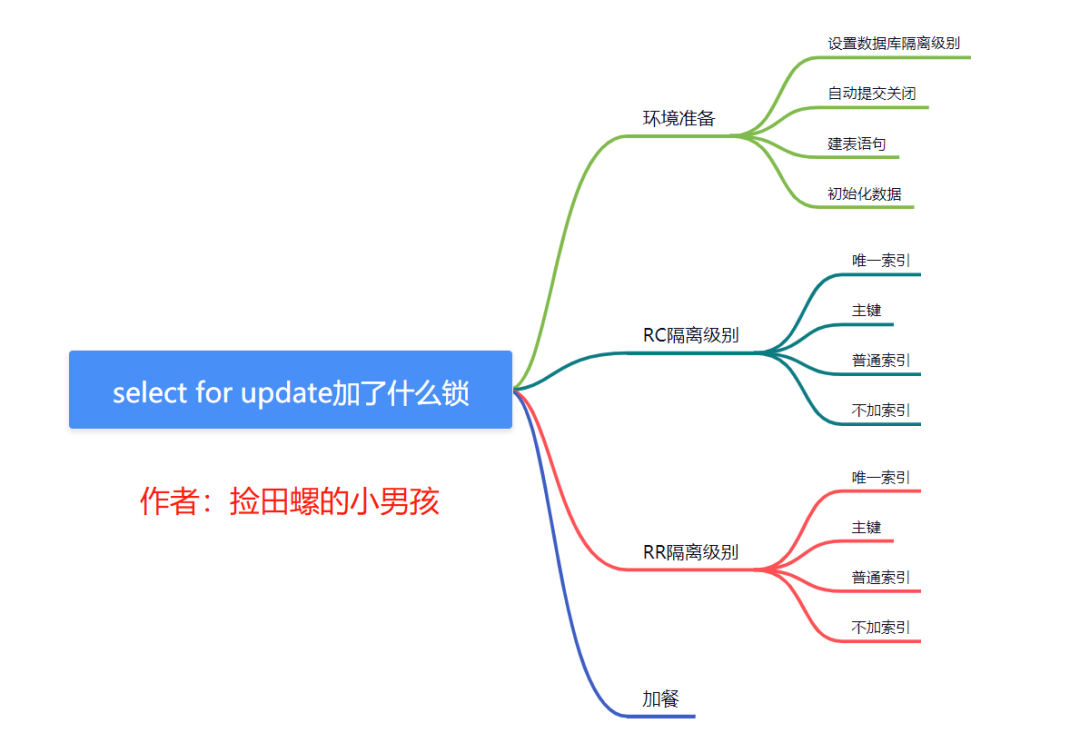
因为加锁是跟数据库的隔离级别息息相关的。而常用的数据库隔离级别也就RC(读已提交)和RR(可重复读),所以本文分别根据RC(读已提交) 和 RR(可重复读)隔离级别展开讲述。
1. 环境准备
设置数据库隔隔离级别
mysql> set global TRANSACTION ISOLATION level read COMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-COMMITTED |
+-------------------------+
1 row in set (0.00 sec)
自动提交关闭
mysql> set @@autocommit=0; //设置自动提交关闭
Query OK, 0 rows affected (0.00 sec)
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 0 |
+--------------+
1 row in set (0.00 sec)
建表语句
CREATE TABLE `user_info_tab` (
`id` int NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
`status` varchar(4) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_name` (`user_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1570072 DEFAULT CHARSET=utf8mb3;
初始化数据(接下来的实验证明,都是基于这几条初始数据)
insert into user_info_tab(`user_name`,`age`,`city`,`status`) values('杰伦',18,'深圳','1');
insert into user_info_tab(`user_name`,`age`,`city`,`status`) values('奕迅',26,'湛江','0');
insert into user_info_tab(`user_name`,`age`,`city`,`status`) values('俊杰',28,'广州','1');
MYSQL 版本
mysql> select @@version;
+-----------+
| @@version |
+-----------+
| 8.0.31 |
+-----------+
1 row in set (0.00 sec)
2.RC 隔离级别
2.1 RC隔离级别 + 唯一索引
先把隔离级别设置为RC,因为user_name为唯一索引,我们使用user_name为条件去执行select......for update语句,然后开启另外一个事务去更新数据同一条数据,发现被阻塞了。如下图:

事务二的更新语句为什么会阻塞呢?
因为事务一的
select......for update已经加了锁。那加的是行锁还是表锁呢?如果加的是表锁的话,我们更新其他行的记录的话,应该是也会阻塞的,如果是行锁的话,更新其他记录是可以顺利执行的。
大家可以再看下这个图:
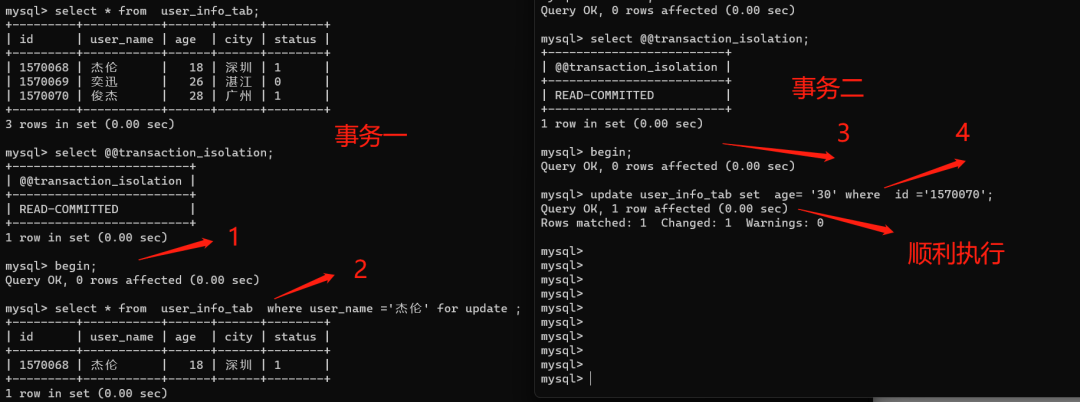
通过实验,可以发现:如果事务中是更新其他行记录的话,是可以顺利执行的。因此在RC隔离级别下,如果条件是唯一索引,那么select...for update加的应该是行锁。
有些小伙伴会很好奇,到底加了什么锁呢? 接下来带大家看看,具体加的是什么锁。
我用的MySQL版本是8.0+,用这个语句查看:
SELECT * FROM performance_schema.data_locks\G;
如下图,select * from user_info_tab where user_name ='杰伦' for update语句一共加了三把锁,分别是 IX意向排他锁(表级别的锁,不影响插入)、两把X排他锁(行锁,分别对应唯一索引,主键索引)
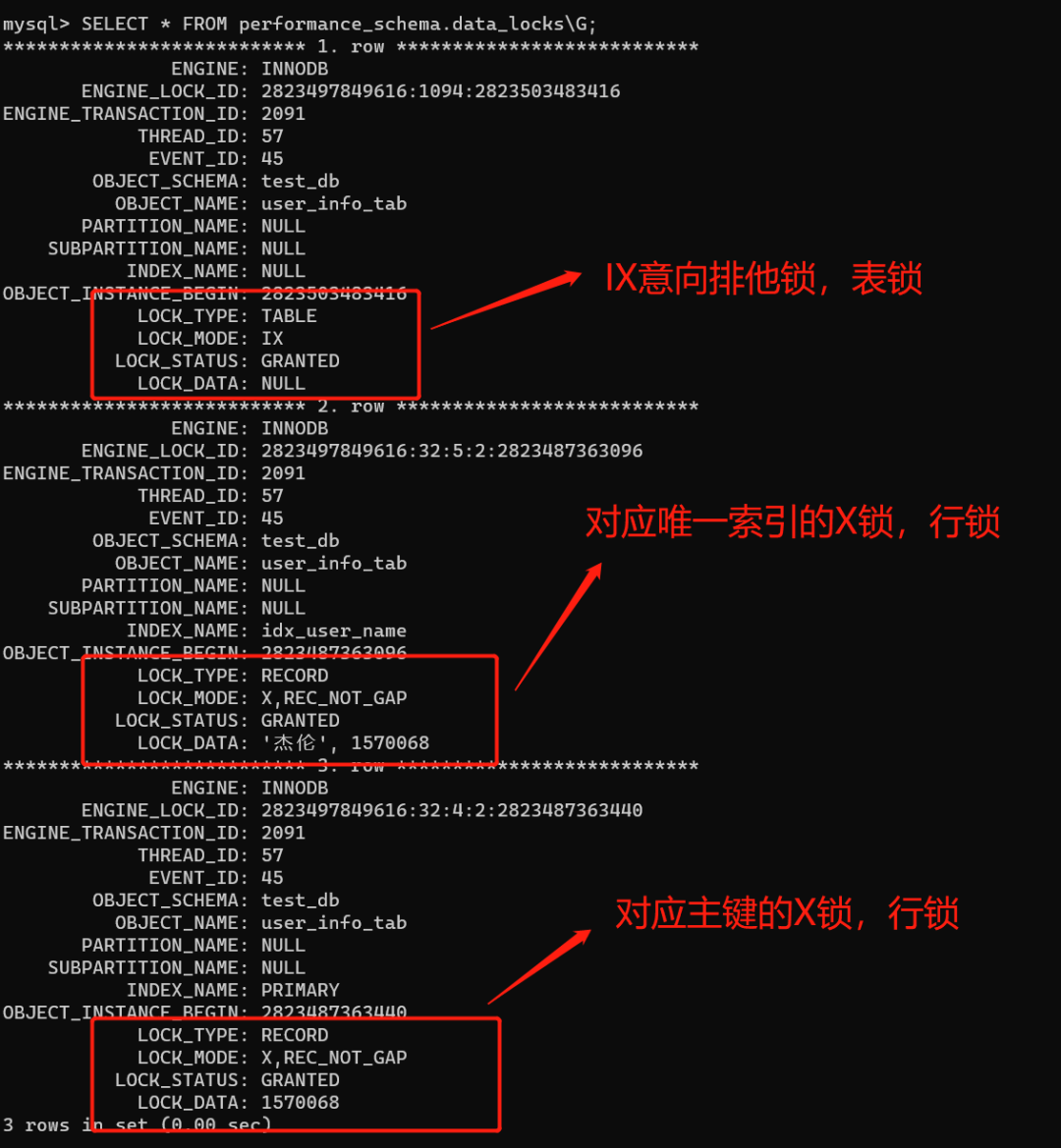
有些读者朋友说,这里不是加了IX表锁嘛?为什么不阻塞其他行的更新? 其实这个是意向排他锁。
意向排他锁:简称
IX锁,当事务准备在某条记录上加上X锁时,需要在表级别加一个IX锁。如select ... for update,要给表设置IX锁;
那既然有表锁,为啥事务二在执行其他行的更新语句时,并不会阻塞,这是因为:意向锁仅仅表明意向的锁,意向锁之间不会互斥,是可以并行的。,锁的兼容性如下:
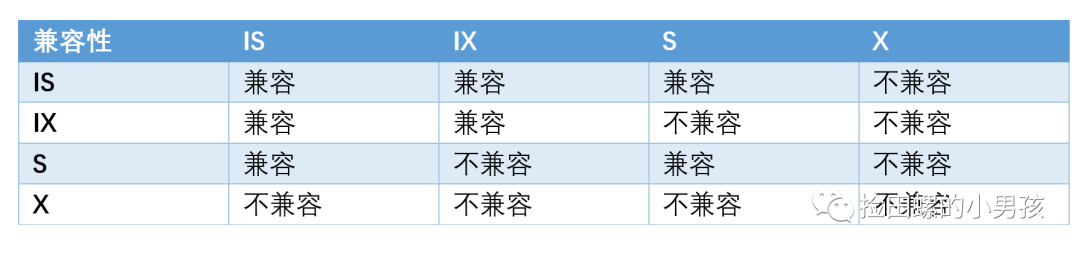
有些小伙伴可能还有疑问,为啥会有两把的X锁呢? 不是都锁住的是同一行嘛?其实RC隔离级别下,唯一索引的加锁是这样的:

为什么不是唯一索引上加X锁就可以了呢?为什么主键索引上的记录也要加锁呢?
如果并发的一个SQL,通过唯一索引条件,来更新主键索引:
update user_info_tab set user_name = '学友' where id = '1570068';此时,如果select...for update语句没有将主键索引上的记录加锁,那么并发的update就会感知不到select...for update语句的存在,违背了同一记录上的更新/删除需要串行执行的约束。
2.2 RC 隔离级别 + 主键
在RC 隔离级别下,如果select...for update的查询条件是主键id,加的又是什么锁呢?
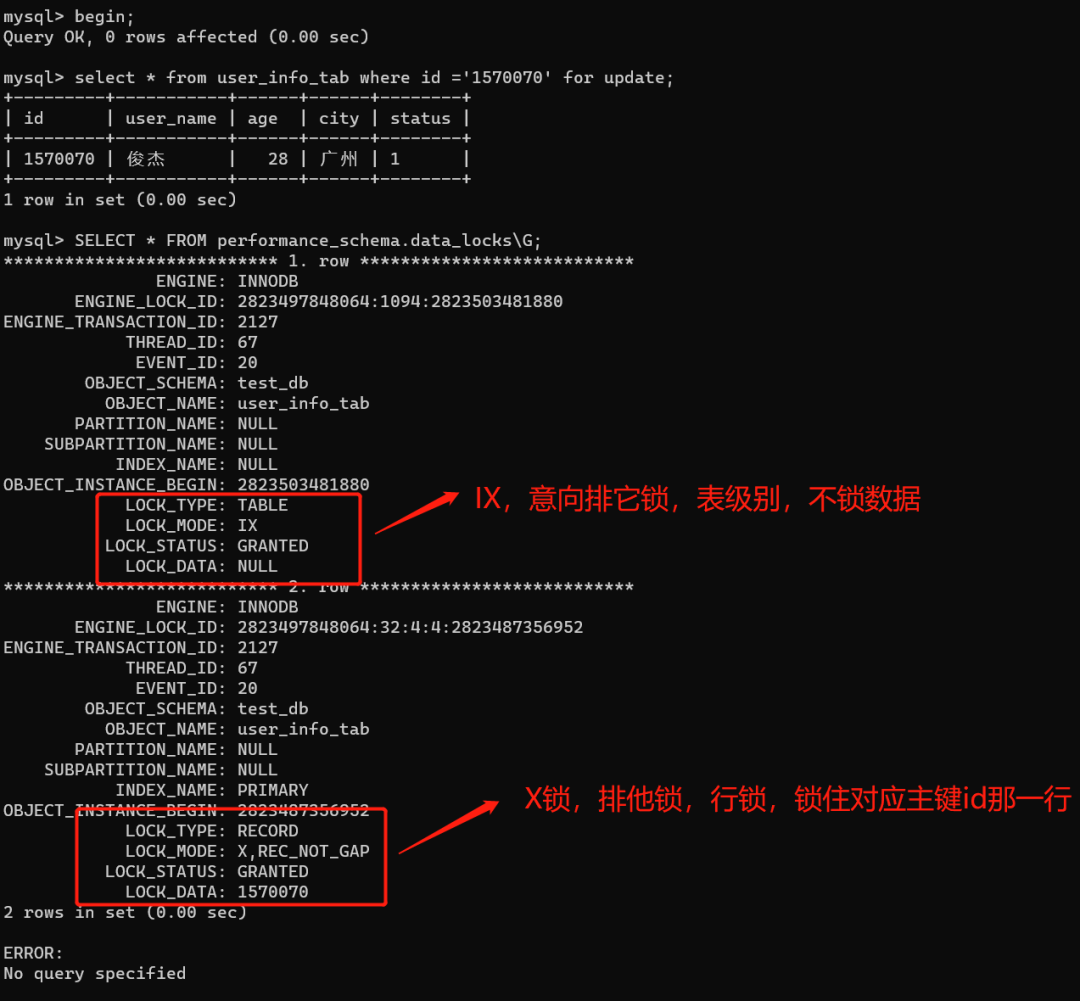
我们执行语句:select * from user_info_tab where id ='1570070' for update;然后开启另外一个事务去更新数据同一条数据,发现被阻塞了。如下图:

事务二更新的是其他行的记录,则是可以顺利执行的,如下图:

通过实验,可以发现:
如果事务中是更新其他行记录,是可以顺利执行的话。在RC隔离级别下,如果条件是主键,那么
select...for update锁的也是行。
根据2.1小节的结论,select...for update都会加个表级别的IX意向排他锁。所以,查询条件是id的话,select...for update会加两把锁,分表是IX意向排他锁(表锁,不影响插入)、一把X排他锁(行锁,对于主键索引)
我们执行语句,查询一下到底加的是什么锁。
begin;
select * from user_info_tab where id ='1570070' for update;
SELECT * FROM performance_schema.data_locks\G;
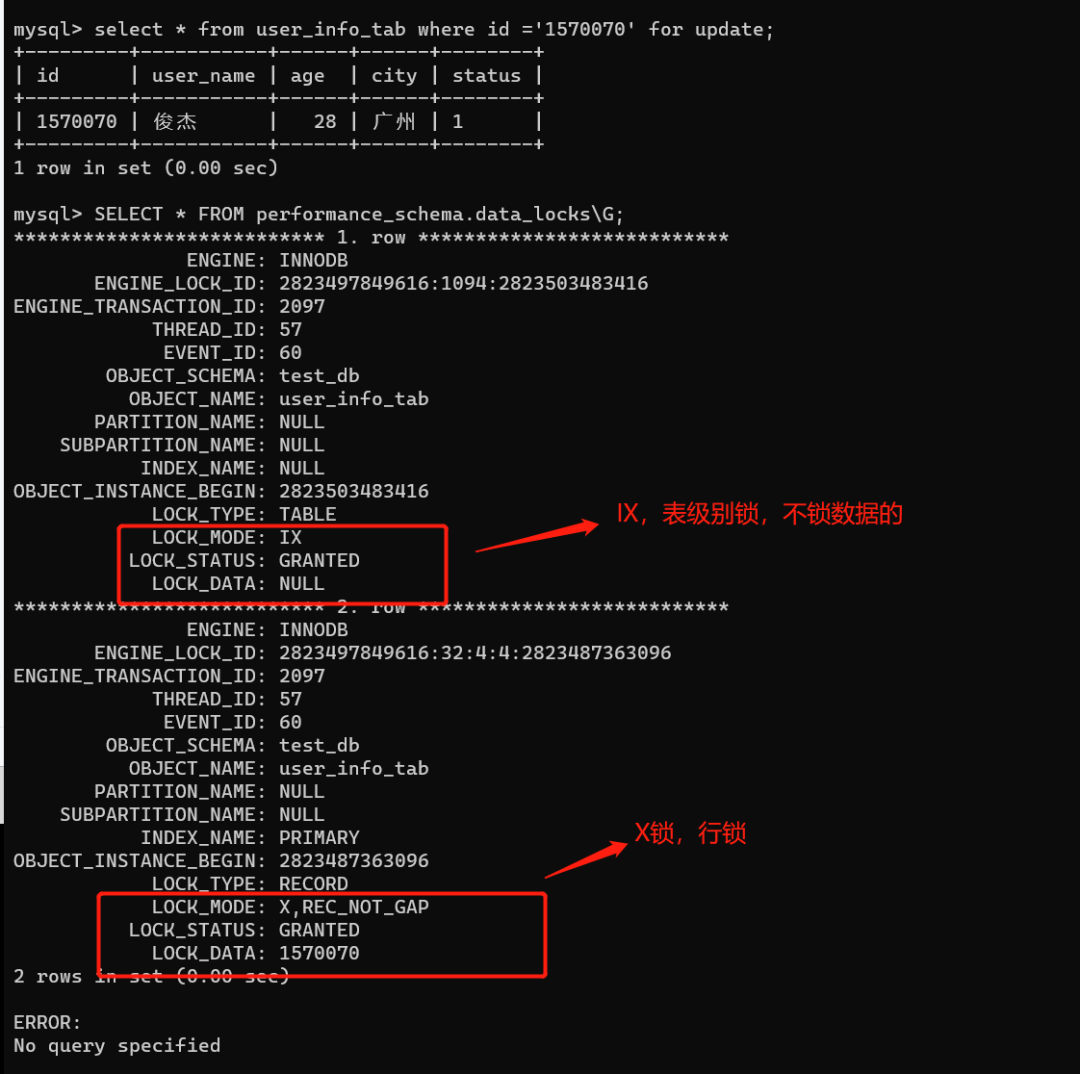
因此在RC隔离级别下,如果条件是主键,那么select......for update加的就是两把锁,一把IX意向排他锁(不影响插入),一把对应主键的X排他锁(行锁,会锁住主键索引那一行)。
2.3 RC 隔离级别 + 普通索引
在RC 隔离级别下,如果select......for update的查询条件是普通索引,加的又是什么锁呢?
我们这里先给原来表加上普通索引:
alter table user_info_tab add index idx_city (city);
我们执行语句:select * from user_info_tab where city ='广州' for update;然后开启另外一个事务去更新同一条数据,发现被阻塞了。如下图:

如果事务二更新的是其他行的记录,还是可以顺利执行的,如下图:

我们看一下select * from user_info_tab where city ='广州' for update;到底加了什么锁,如下图:
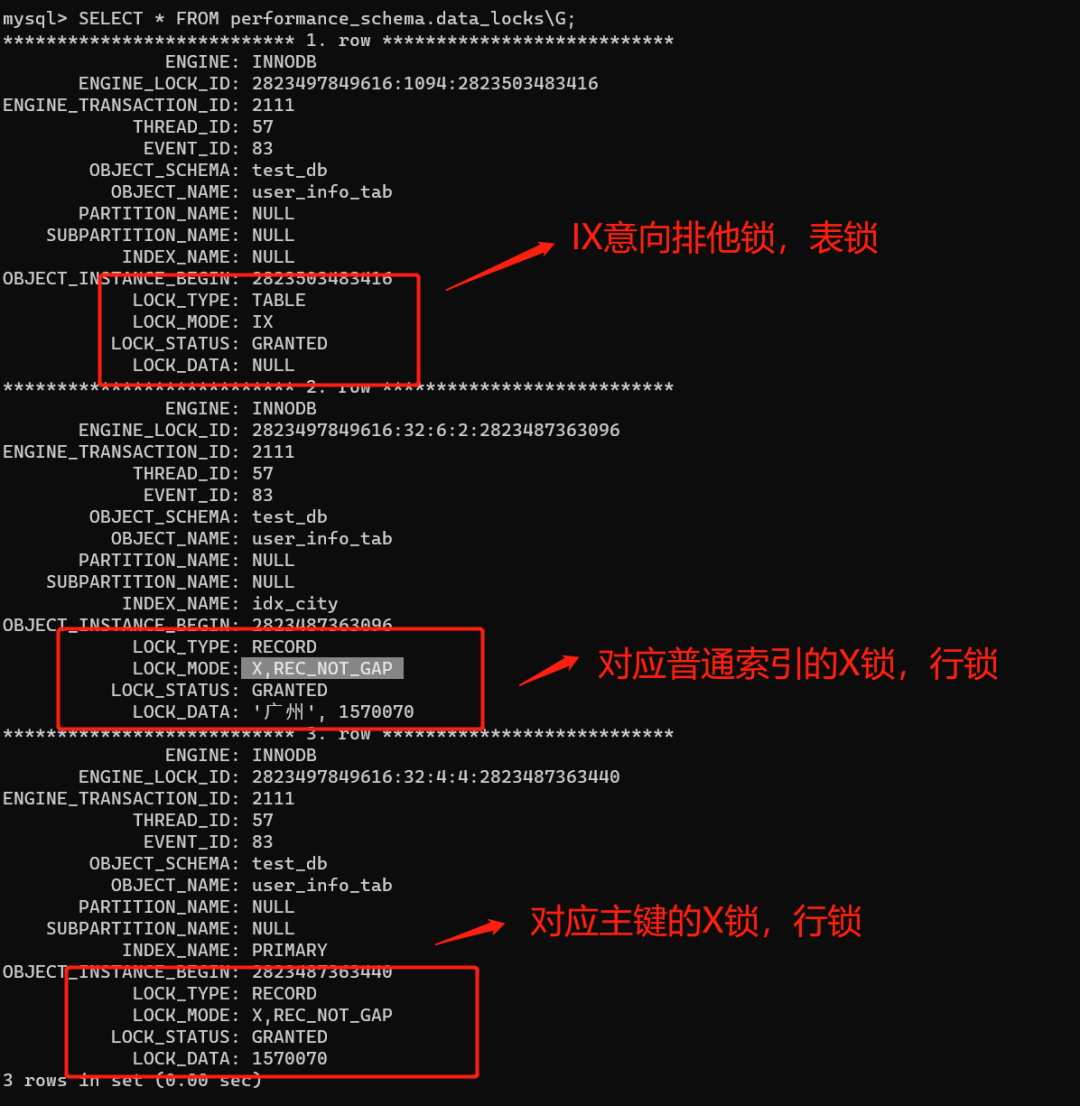
发现一共加了三把锁,分别是:IX意向排他锁(表锁)、两把X排他锁(行锁,分别对应普通索引的X锁,对应主键的X锁)。
如果查询条件,没有命中数据库表的记录,又加什么锁呢?
我们把查询条件改一下:select * from user_info_tab where city ='广州' and status='0' for update;
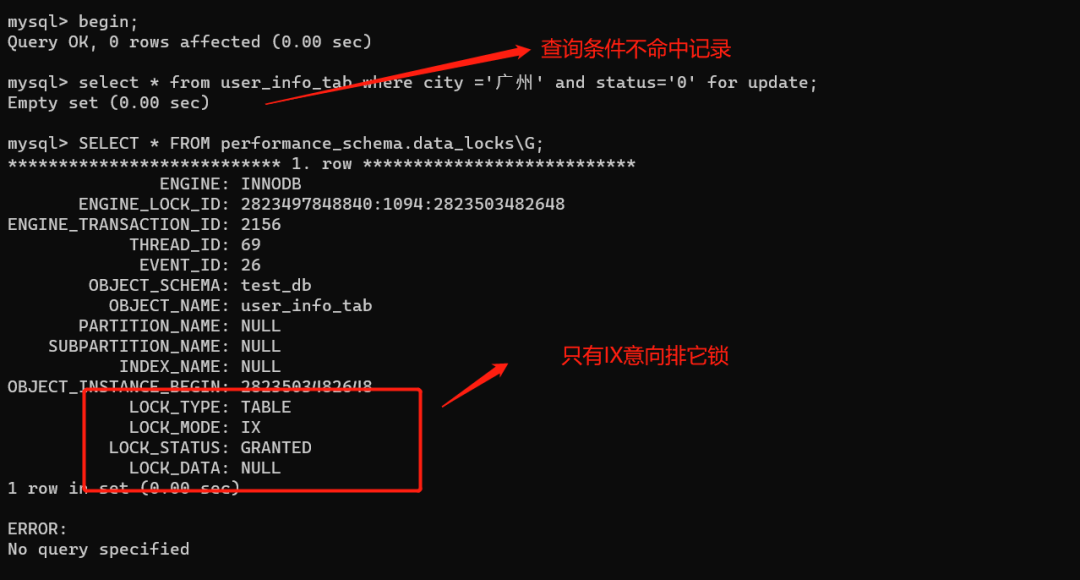
发现只加了一把锁,即IX意向排他锁(表锁,不影响插入)。
2.4 RC 隔离级别 + 无索引
在RC 隔离级别下,如果select...for update的查询条件是无索引呢,加的又是什么锁呢?
多数读者凭感觉都是锁表了,我们来验证一下。
我们执行语句:select * from user_info_tab where age ='26' for update;(age是没有加索引的),然后开启另外一个事务去更新数据。如下图:

由上图可以发现,事务一 先执行select......for update,然后事务二先更新别的行,发现可以顺利执行,如果执行for update的同一行,还是会阻塞等待。
可推出结论,select...for update的查询条件是无索引,主要还是行锁。我们看下具体的加锁情况:
SELECT * FROM performance_schema.data_locks\G;
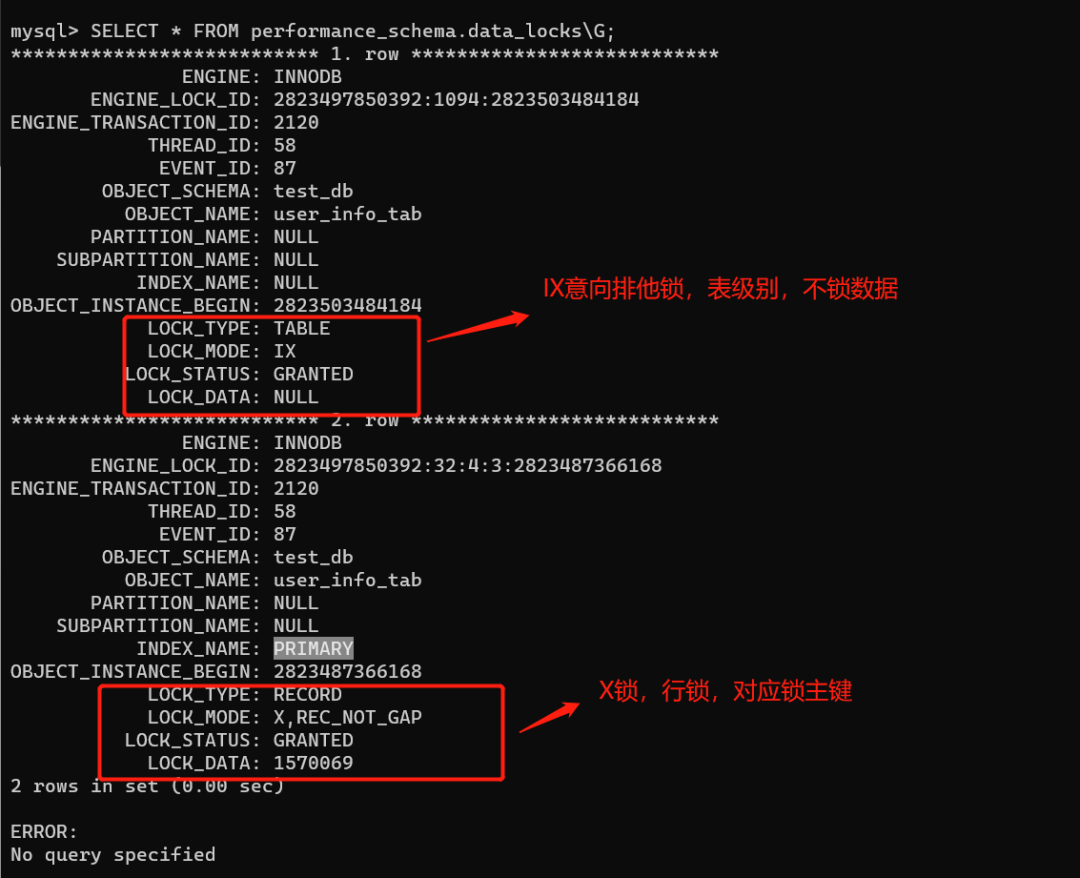
发现一共加了两把锁,分别是:IX意向排他锁(表锁)、一把X排他锁(行锁,对应主键的X锁)。
为什么不是一个锁表的X锁呢? 这是因为:
若
age列上没有索引,MySQL会走聚簇(主键)索引进行全表扫描过滤。每条记录都会加上X锁。但是,为了效率考虑,MySQL在这方面进行了改进,在扫描过程中,若记录不满足过滤条件,会进行解锁操作。同时优化违背了2PL原则。
3.RR 隔离级别
3.1 RR隔离级别 + 唯一索引
如果是RR(可重复)的数据库隔离级别呢,select...for update的查询条件是唯一索引的话,加的又是什么锁呢?
我们知道RR隔离级别比RC隔离级别,主要差异还是有间隙锁这个概念。接下来我们还是通过实验去验证,先把数据库隔离级别设置为RR:
mysql> set global transaction isolation level repeatable read; (设置完好像要重启一下)
Query OK, 0 rows affected (0.00 sec)
我们执行语句:select * from user_info_tab where user_name ='杰伦' for update;(user_name是唯一索引的),然后开启另外一个事务去更新数据。如下图:

由上图可以发现,即使是RR数据库隔离级别,事务一先执行select...for update,然后事务一先更新别的行,发现可以顺利执行,如果执行更新for update的那一行,还是会阻塞超时。
再去看下具体加了什么锁:
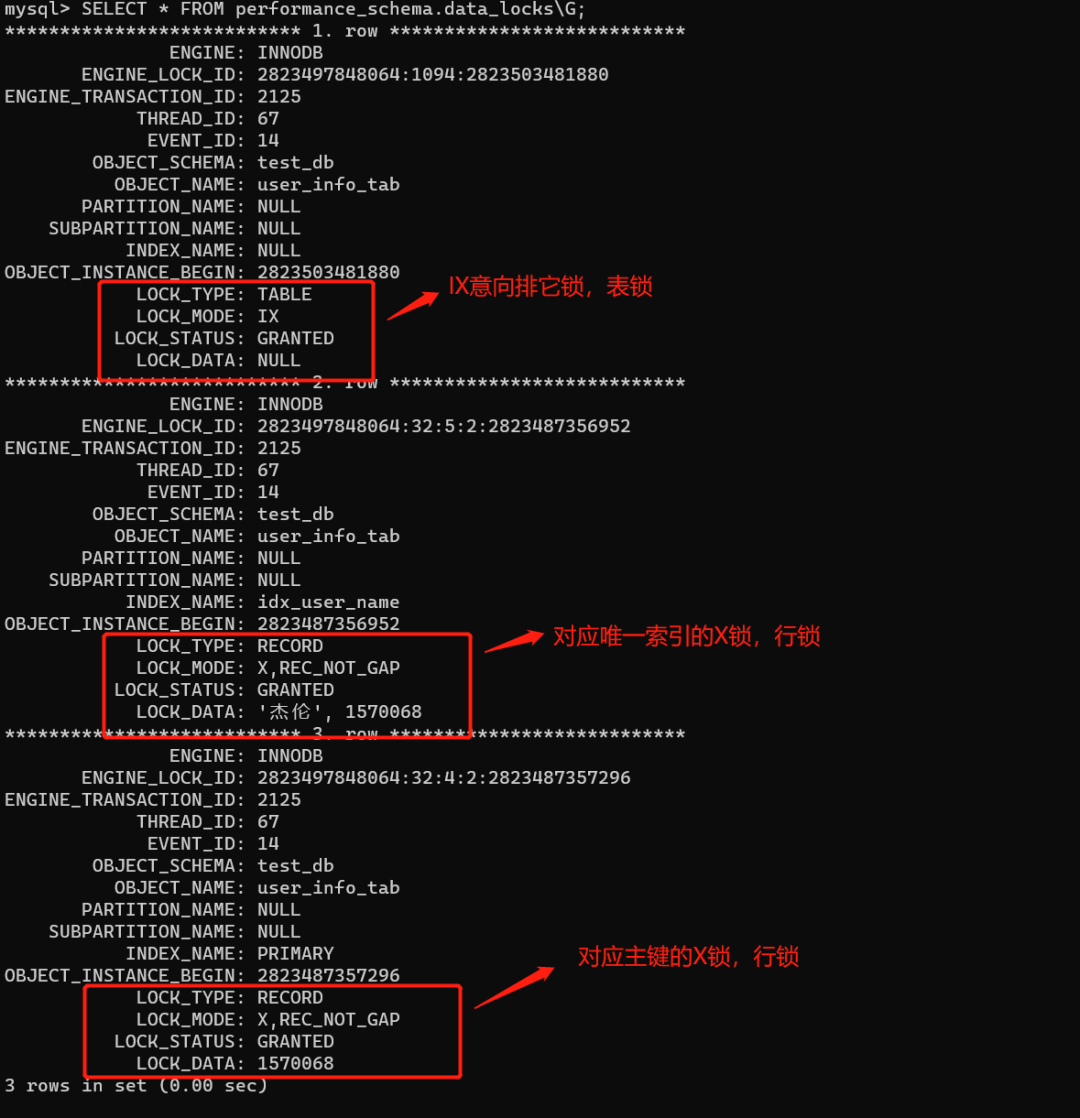
大家可以发现,不管是RC隔离级别还是RR隔离级别,select...for update,查询条件是唯一索引,命中数据库表记录时,一共会加三把锁:一把IX意向排他锁 (表锁,不影响插入),一把对应主键的X排他锁(行锁),一把对应唯一索引的X排他锁 (行锁)。
3.2 RR 隔离级别 + 主键
如果是 RR(可重复读)的数据库隔离级别,select...for update的查询条件是主键的话,加的又是什么锁呢?
根据前面的实验结果,我们其实可以推测得出来了,应该跟RC隔离级别一样,会加两把锁:一把IX意向排他锁(表锁,不影响插入),一把对应主键的X排他锁(行锁,影响对应主键那一行的插入)。
我们通过语句确认一下,先输入一下语句:
begin;
select * from user_info_tab where id ='1570070' for update;
SELECT * FROM performance_schema.data_locks\G;
大家可以看下,跟我们的推测是一样的:
3.3 RR 隔离级别 + 普通索引
在RR隔离级别下,如果select...for update的查询条件是普通索引的话,除了会加X锁,IX锁,还会加Gap 锁。
Gap锁的提出,是为了解决幻读问题引入的,它是一种加在两个索引之间的锁。
我们来验证一下,先开始事务一,执行一下操作:
begin;
select * from user_info_tab where city ='广州' for update;
接着开启事务二
begin;
insert into user_info_tab(`user_name`,`age`,`city`,`status`) values('方燕',27,'汕头','1');
验证流程图如下:

大家可以发现,插入新记录,会被阻塞,那是因为有间隙锁的缘故,我们再看下到底加了哪些锁:

发现相对于RC隔离级别,确实多了间隙锁,锁住范围了。我画一下这种场景的加锁示意图:
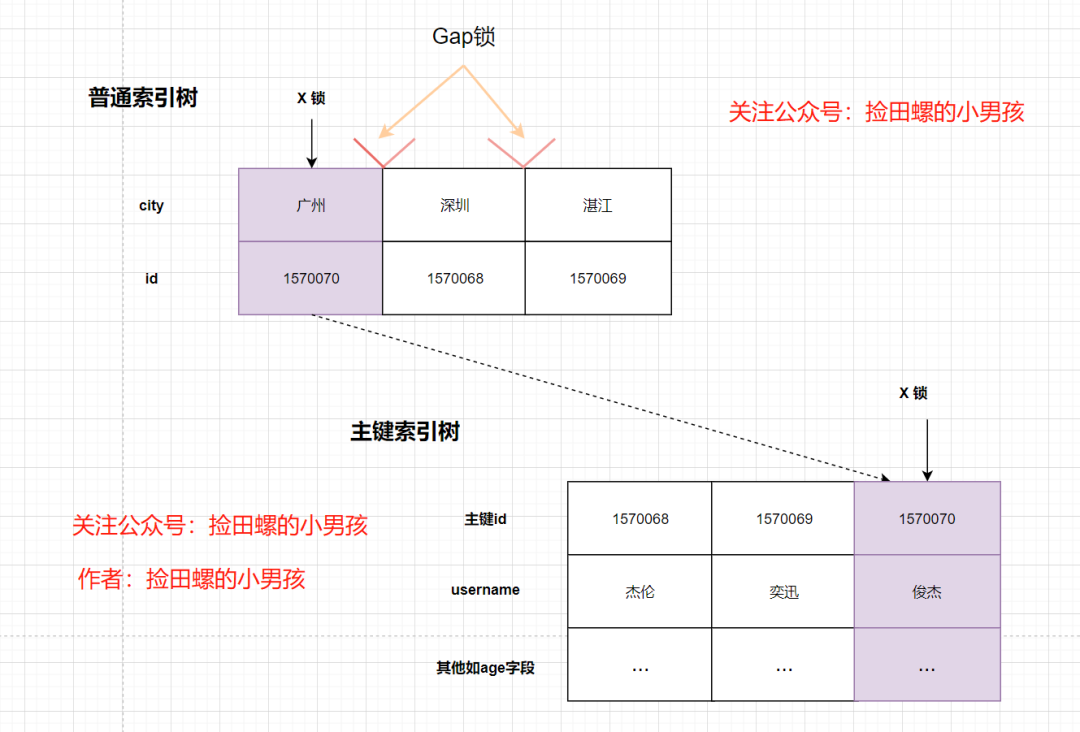
如果要插入汕头城市的记录,会被Gap锁锁住了,因此会阻塞。
因此,在RR隔离级别下,如果select...for update的查询条件是普通索引的话,命中查询记录的话,除了会加X锁(行锁),IX锁(表锁,不影响插入),还会加Gap 锁(间隙锁,会影响插入)。
3.4 RR隔离级别 + 无索引
在RR隔离级别下,如果select...for update的查询条件是无索引的话,会锁全表嘛?来一起验证一下
我们直接按顺序执行以下这些语句:
begin;
select * from user_info_tab where age ='26' for update;
select OBJECT_NAME,INDEX_NAME, LOCK_TYPE,LOCK_MODE, LOCK_STATUS, LOCK_DATA FROM performance_schema.data_locks;
可以发现加了这么多锁:
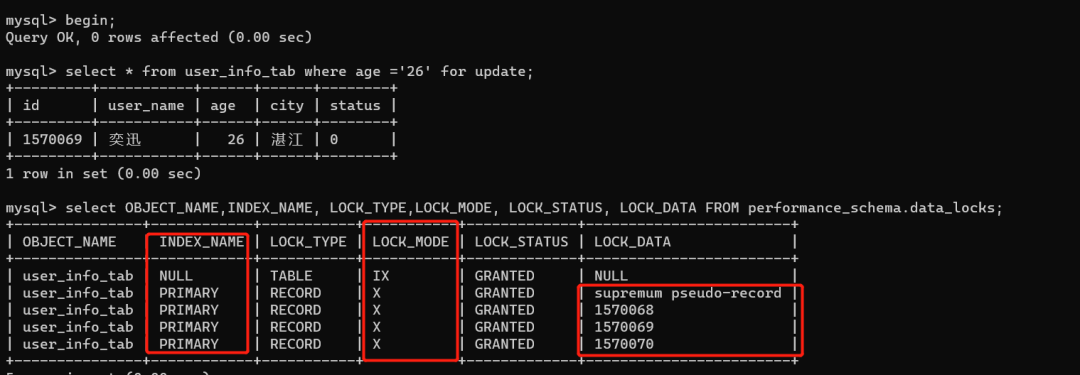
一共五把锁,这个IX锁(表级别,意向排他锁),我们可以理解,跟前面几个例子的一样。后面三把行锁,就是把每一行的数据记录,都加了X排他锁(行锁,锁的对象对应于主键Id),我们也可以理解。但是这个第二行,是一把怎么样的X锁呢?

我谷歌了一下,什么是supremum pseudo-record,找到了这个解释:
For the last interval, the next-key lock locks the gap above the largest value in the index and the “supremum” pseudo-record having a value higher than any value actually in the index. The supremum is not a real index record, so, in effect, this next-key lock locks only the gap following the largest index value.
翻译过来,大概意思就是:相当于比索引中所有值都大,但却不存在索引中,相当于最后一行之后的间隙锁。我理解就是如果查询条件有索引的话,类似于一个(索引最大值,+无穷)的虚拟间隙锁。
但是因为我们的查询字段age并没有索引,锁为X锁,lock_data值为supremum pseudo-record,它表示:全表行锁,要走聚簇索引进行全部扫描。
也就是说RR隔离级别下,对于select...for update,查询条件无索引的话,会加一个IX锁(表锁,不影响插入),每一行实际记录行的X锁,还有对应于supremum pseudo-record的虚拟全表行锁。这种场景,通俗点讲,其实就是锁表了。
我们来做个实验,验证虚拟全表行锁的存在,先开启事务一,执行:
begin;
select * from user_info_tab where age ='26' for update;
然后开启事务二,执行一个插入语句:
begin;
insert into user_info_tab(id,`user_name`,`age`,`city`,`status`) values(1,'小明',31,'北京','1');
大家可以看下,阻塞了,:

加餐
大家有没有发现,田螺哥列举RR数据库隔离级别的例子,select...for update条件都是命中数据库表记录的。在这里,田螺哥给大家出道题。在RR隔离级别下,如果select...for update的查询条件,没命中当前数据表记录的话,又加什么锁呢?
我们来搞点刺激的,select...for update 搞两个条件:一个唯一索引(user_name) + 一个无索引(status),然后没命中当前数据表记录,你觉得会加什么锁呢?
CREATE TABLE `user_info_tab` (
`id` int NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
`status` varchar(4) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_name` (`user_name`) USING BTREE,
KEY `idx_city` (`city`)
) ENGINE=InnoDB AUTO_INCREMENT=1570074 DEFAULT CHARSET=utf8mb3
我们按顺序执行者几条语句:
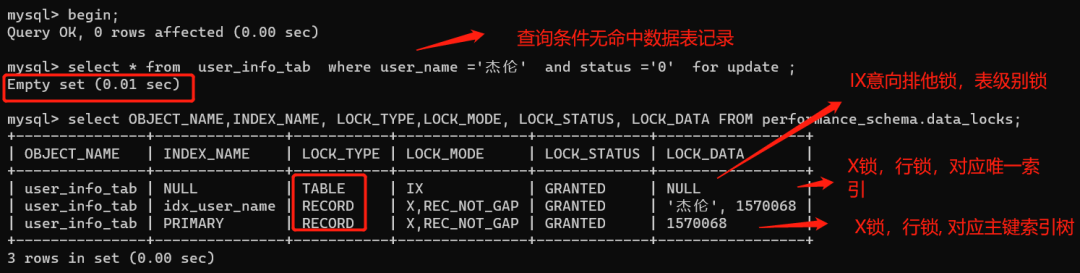
begin;
select * from user_info_tab where user_name ='杰伦' and status ='0' for update ;
select OBJECT_NAME,INDEX_NAME, LOCK_TYPE,LOCK_MODE, LOCK_STATUS, LOCK_DATA FROM performance_schema.data_locks;
最后
通过本文,大家学到哪些知识点呢?
-
select...for update在不同场景,都加了什么锁。 -
如何查看一个SQL 加了什么锁 (执行完原生SQL,再执行
SELECT * FROM performance_schema.data_lock -
如何手写个死锁 (分别开两个事务,制造锁冲突,文章的例子,好多都是死锁的case)