数据可视化(五)制作全球地震散点图:JSON格式
- 1.地震数据
- 2.查看JSON数据
- 3.创建地震列表
- 4.提取震级
- 5.提取位置数据
- 6.绘制震级散点图
- 7.另一种指定图表数据的方式
下载一个数据集,其中记录了一个月内全球发生的所有地震,再制作一幅散点图来展示这些地震的位置和震级。这些数据是以JSON格式存储的,因此要使用模块json来处理。Plotly提供了根据位置数据绘制地图的工具,适合初学者使用。你将使用它来进行可视化并指出全球的地震分布情况。
1.地震数据
请将文件eq_data_1_day_m1.json复制到存储本章程序的文件夹中。地震是以里氏震级度量的,而该文件记录了(截至写作本节时)最近24小时内全球发生的所有不低于1级的地震。
2.查看JSON数据
如果打开文件eq_data_1_day_m1.json,你将发现其内容密密麻麻,难以阅读:
{"type":"FeatureCollection","metadata":{"generated":1550361461000,...
{"type":"Feature","properties":{"mag":1.2,"place":"11km NNE of Nor...
{"type":"Feature","properties":{"mag":4.3,"place":"69km NNW of Ayn...
{"type":"Feature","properties":{"mag":3.6,"place":"126km SSE of Co...
{"type":"Feature","properties":{"mag":2.1,"place":"21km NNW of Teh...
{"type":"Feature","properties":{"mag":4,"place":"57km SSW of Kakto...
--snip--
这些数据适合机器而不是人来读取。不过可以看到,这个文件包含一些字典,还有一些我们感兴趣的信息,如震级和位置。
模块json提供了各种探索和处理JSON数据的工具,其中一些有助于重新设置这个文件的格式,让我们能够更清楚地查看原始数据,继而决定如何以编程的方式来处理。
我们先加载这些数据并将其以易于阅读的方式显示出来。这个数据文件很长,因此不打印出来,而是将数据写入另一个文件,再打开该文件并轻松地在数据中导航:eq_explore_data.py
import json
# 探索数据的结构。
filename = 'data/eq_data_1_day_m1.json'
with open(filename) as f:
❶ all_eq_data = json.load(f)
❷ readable_file = 'data/readable_eq_data.json'
with open(readable_file, 'w') as f:
❸ json.dump(all_eq_data, f, indent=4)
首先导入模块json,以便恰当地加载文件中的数据,并将其存储到all_eq_data中(见❶)。函数json.load()将数据转换为Python能够处理的格式,这里是一个庞大的字典。在❷处,创建一个文件,以便将这些数据以易于阅读的方式写入其中。函数json.dump()接受一个JSON数据对象和一个文件对象,并将数据写入这个文件中(见❸)。参数indent=4让dump()使用与数据结构匹配的缩进量来设置数据的格式。
如果你现在查看目录data并打开其中的文件readable_eq_data.json,将发现其开头部分像下面这样:readable_eq_data.json
{
"type": "FeatureCollection",
❶ "metadata": {
"generated": 1550361461000,
"url": "https://earthquake.usgs.gov/earthquakes/.../1.0_day.geojson",
"title": "USGS Magnitude 1.0+ Earthquakes, Past Day",
"status": 200,
"api": "1.7.0",
"count": 158
},
❷ "features": [
--snip--
这个文件的开头是一个键为"metadata"的片段(见❶),指出了这个数据文件是什么时候生成的,以及能够在网上的什么地方找到。它还包含适合人类阅读的标题以及文件中记录了多少次地震:在过去的24小时内,发生了158次地震。
这个geoJSON文件的结构适合存储基于位置的数据。数据存储在一个与键"features"相关联的列表中(见❷)。这个文件包含的是地震数据,因此列表的每个元素都对应一次地震。这种结构可能有点令人迷惑,但很有用,让地质学家能够将有关每次地震的任意数量信息存储在一个字典中,再将这些字典放在一个大型列表中。
我们来看看表示特定地震的字典:readable_eq_data.json
--snip--
{
"type": "Feature",
❶ "properties": {
"mag": 0.96,
--snip--
❷ "title": "M 1.0 - 8km NE of Aguanga, CA"
},
❸ "geometry": {
"type": "Point",
"coordinates": [
❹ -116.7941667,
❺ 33.4863333,
3.22
]
},
"id": "ci37532978"
},
键"properties"关联到了与特定地震相关的大量信息(见❶)。我们关心的主要是与键"mag"相关联的地震震级以及地震的标题,因为后者很好地概述了地震的震级和位置(见❷)。
键"geometry"指出了地震发生在什么地方(见❸),我们需要根据这项信息将地震在散点图上标出来。在与键"coordinates"相关联的列表中,可找到地震发生位置的经度(见❹)和纬度(见❺)。
这个文件的嵌套层级比我们编写的代码多。如果这让你感到迷惑,也不用担心,Python将替你处理大部分复杂的工作。我们每次只会处理一两个嵌套层级。我们将首先提取过去24小时内发生的每次地震对应的字典。
注意 说到位置时,我们通常先说纬度、再说经度,这种习惯形成的原因可能是人类先发现了纬度,很久后才有经度的概念。然而,很多地质学框架都先列出经度、后列出纬度,因为这与数学约定[插图]一致。geoJSON格式遵循(经度, 纬度)的约定,但在使用其他框架时,获悉其遵循的约定很重要。
3.创建地震列表
首先,创建一个列表,其中包含所有地震的各种信息:eq_explore_data.py
import json
# 探索数据的结构。
filename = 'data/eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data = json.load(f)
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))
我们提取与键’features’相关联的数据,并将其存储到all_eq_dicts中。我们知道,这个文件记录了158次地震。下面的输出表明,我们提取了这个文件记录的所有地震:
158
注意,我们编写的代码很短。格式良好的文件readable_eq_data.json包含超过6000行内容,但只需几行代码,就可读取所有的数据并将其存储到一个Python列表中。下面将提取所有地震的震级。
4.提取震级
有了包含所有地震数据的列表后,就可遍历这个列表,从中提取所需的数据。下面来提取每次地震的震级:eq_explore_data.py
--snip--
all_eq_dicts = all_eq_data['features']
❶ mags = []
for eq_dict in all_eq_dicts:
❷ mag = eq_dict['properties']['mag']
mags.append(mag)
print(mags[:10])
我们创建了一个空列表,用于存储地震震级,再遍历列表all_eq_dicts(见❶)。每次地震的震级都存储在相应字典的’properties’部分的’mag’键下(见❷)。我们依次将地震震级赋给变量mag,再将这个变量附加到列表mags末尾。
为确定提取的数据是否正确,打印前10次地震的震级:
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
接下来,我们将提取每次地震的位置信息,然后就可以绘制地震散点图了。
5.提取位置数据
位置数据存储在"geometry"键下。在"geometry"键关联的字典中,有一个"coordinates"键,它关联到一个列表,而列表中的前两个值为经度和纬度。下面演示了如何提取位置数据:eq_explore_data.py
--snip--
all_eq_dicts = all_eq_data['features']
mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag']
❶ title = eq_dict['properties']['title']
❷ lon = eq_dict['geometry']['coordinates'][0]
lat = eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
print(mags[:10])
print(titles[:2])
print(lons[:5])
print(lats[:5])
我们创建了用于存储位置标题的列表titles,来提取字典’properties’里’title’键对应的值(见❶),以及用于存储经度和纬度的列表。代码eq_dict[‘geometry’]访问与"geometry"键相关联的字典(见❷)。第二个键(‘coordinates’)提取与"coordinates"相关联的列表,而索引0提取该列表中的第一个值,即地震发生位置的经度。
打印前5个经度和纬度时,输出表明提取的数据是正确的:
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
['M 1.0 - 8km NE of Aguanga, CA', 'M 1.2 - 11km NNE of North Nenana, Alaska']
[-116.7941667, -148.9865, -74.2343, -161.6801, -118.5316667]
[33.4863333, 64.6673, -12.1025, 54.2232, 35.3098333]
6.绘制震级散点图
有了前面提取的数据,就可以绘制可视化图了。首先要实现一个简单的震级散点图,在确保显示的信息正确无误之后,我们再将注意力转向样式和外观方面。绘制初始散点图的代码如下:eq_world_map.py
❶ import plotly.express as px
fig = px.scatter(
x=lons,
y=lats,
labels={"x": "经度", "y": "纬度"},
range_x=[-200, 200],
range_y=[-90, 90],
width=800,
height=800,
title="全球地震散点图",
❷ )
❸ fig.write_html("global_earthquakes.html")
❹ fig.show()
首先,导入plotly.express,用别名px表示。Plotly Express是Plotly的高级接口,简单易用,语法与Matplotlib类似(见❶)。然后,调用px.scatter函数配置参数创建一个fig实例,分别设置[插图]轴为经度[范围是[-200, 200](扩大空间,以便完整显示东西经180°附近的地震散点)]、[插图]轴为纬度[范围是[-90,90]],设置散点图显示的宽度和高度均为800像素,并设置标题为“全球地震散点图”(见❷)。
只用14行代码,简单的散点图就配置完成了,这返回了一个fig对象。fig.write_html方法可以将可视化图保存为html文件。在文件夹中找到global_earthquakes.html文件,用浏览器打开即可(见❸)。另外,如果使用Jupyter Notebook,可以直接使用fig.show方法直接在notebook单元格显示散点图(见❹)。
局部效果如下图所示:
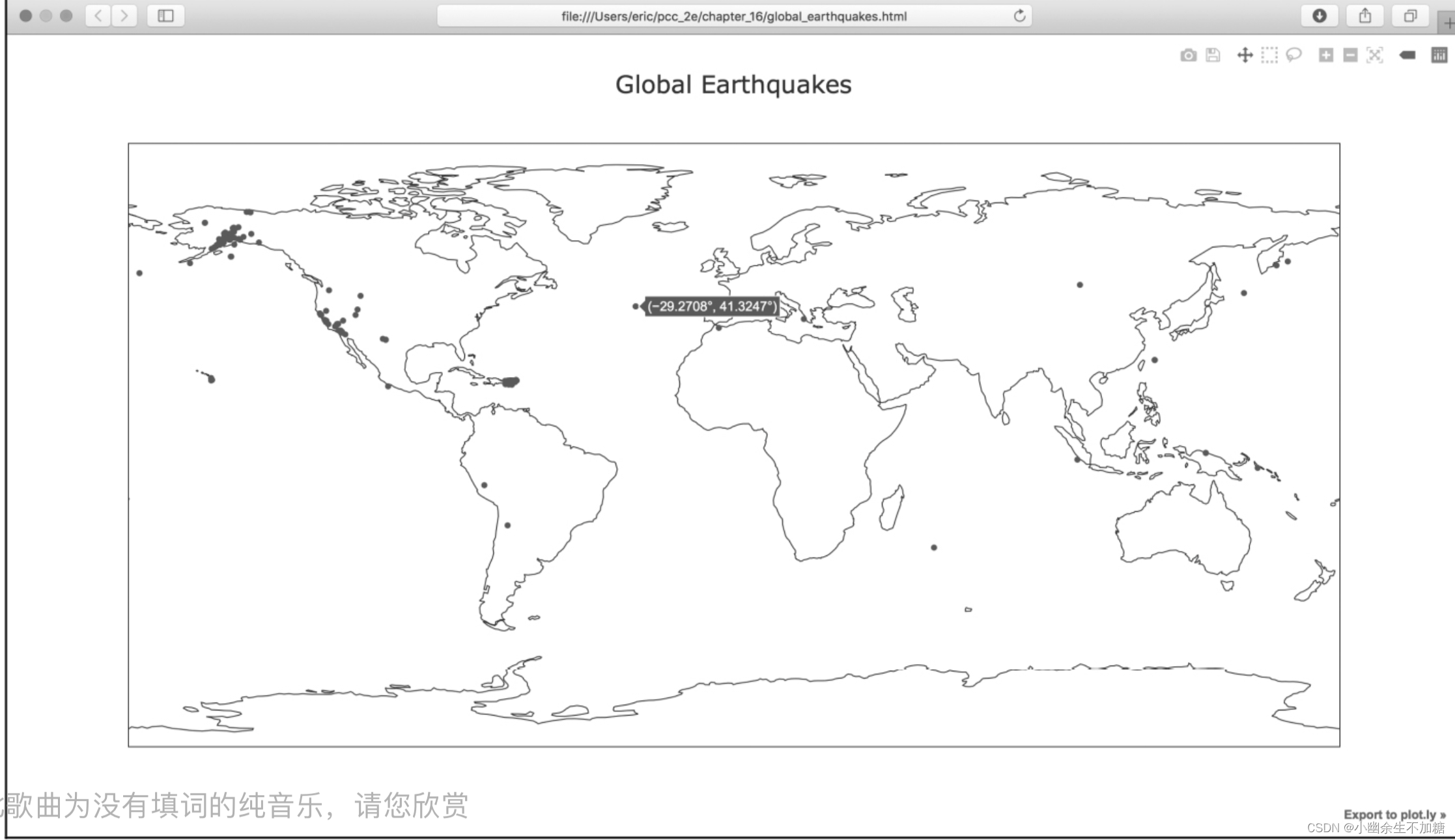
可对这幅散点图做大量修改,使其更有意义、更好懂。下面就来做些这样的修改。
7.另一种指定图表数据的方式
配置这个图表前,先来看看另一种稍微不同的指定Plotly 图表数据的方式。当前,经纬度数据是手动配置的:
--snip--
x=lons,
y=lats,
labels={"x": "经度", "y": "纬度"},
--snip--
这是在Plotly Express中给图表定义数据的最简单方式之一,但在数据处理中并不是最佳的。下面是另一种给图表定义数据的等效方式,需要使用pandas数据分析工具。首先创建一个DataFrame,将需要的数据封装起来:
import pandas as pd
data = pd.DataFrame(
data=zip(lons, lats, titles, mags), columns=["经度", "纬度", "位置", "震级"]
)
data.head()
然后,参数配置方式可以变更为:
--snip--
data,
x="经度",
y="纬度",
--snip--
在这种方式中,所有有关数据的信息都以键值对的形式放在一个字典中。如果在eq_plot.py中使用这些代码,生成的图表是一样的。相比于前一种格式,这种格式让我们能够无缝衔接数据分析,并且更轻松地进行定制。