引言
主要讲解三篇论文,主要思想是把自然语言理解、对话管理和自然语言生成三部分整合到一起。
先导知识
数据集
- CamRest676
- MultiWOZ
都是用的自回归语言模型
- causal
- GPT-2、Transformer Decoder
一个概念:delexicalization
- 通过相应的占位符替换特定的槽值
- 占位符作为特定的token,不关心具体的取值
- 学习取值无关的参数
首先来看第一篇论文
SimpleTOD
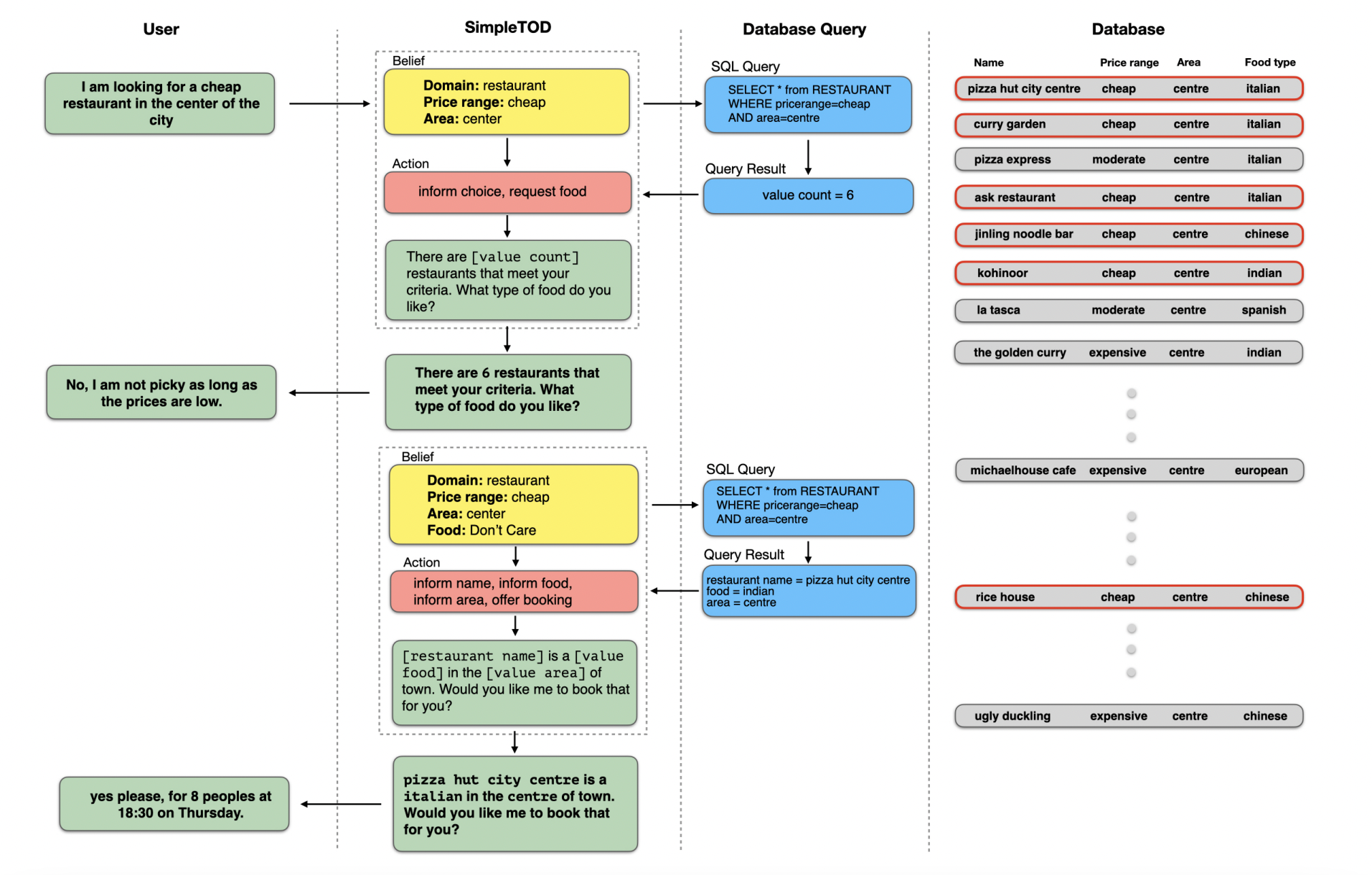
来自论文A Simple Language Model for Task-Oriented Dialogue。
主要做的工作是:
- 采用causal 语言模型(GPT-2)
- 把整个TOD转换成序列预测问题
- 损失函数为最大似然
- 把整个TOD分为几个子任务,建模子任务之间的依赖
TOD指任务导向型的对话系统。
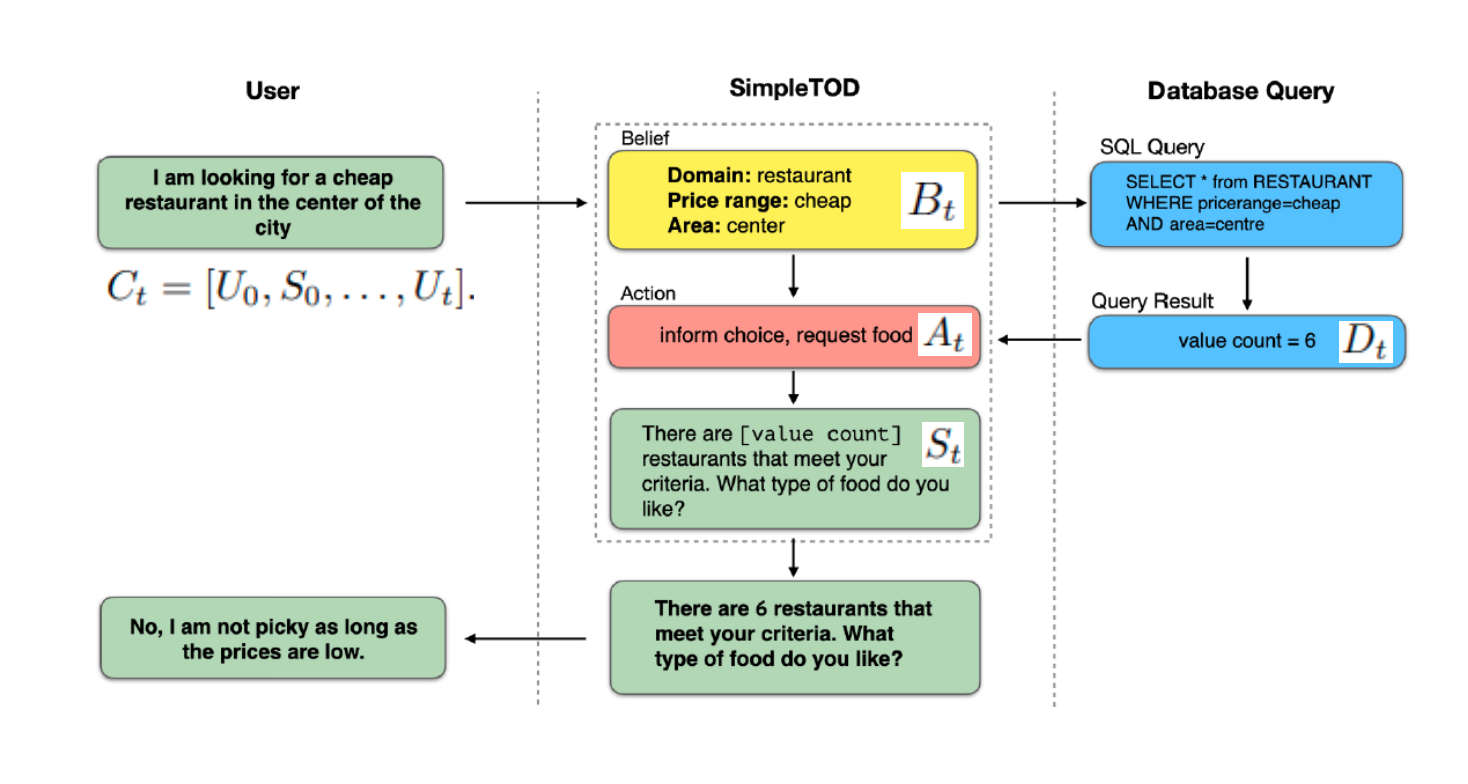
模型的输入是所有的对话历史:
C
t
=
[
U
0
,
S
0
,
⋯
,
U
t
]
C_t=[U_0,S_0,\cdots, U_t]
Ct=[U0,S0,⋯,Ut]
其中
U
0
U_0
U0是用户输入的第一句话;
S
0
S_0
S0是系统回复的第一句话;
然后把这个上下文输入给SimpleTOD模型:
B
t
=
SimpleTOD
(
C
t
)
B_t =\text{SimpleTOD}(C_t)
Bt=SimpleTOD(Ct)
会输出一个belief state,包含domain,slot_name和value。相当于做了NLU+DST的工作。
接下来要做对话动作生成,此时把
C
t
,
B
t
C_t,B_t
Ct,Bt和查询结果
D
t
D_t
Dt拼接起来,再输入给SimpleTOD模型:
A
t
=
SimpleTOD
(
[
C
t
,
B
t
,
D
t
]
)
A_t =\text{SimpleTOD}([C_t, B_t, D_t])
At=SimpleTOD([Ct,Bt,Dt])
生成动作
A
t
A_t
At。
最后生成响应时把上面所有结果拼接,输入给SimpleDOT模型:
S
t
=
SimpleTOD
(
[
C
t
,
B
t
,
D
t
,
A
t
]
)
S_t =\text{SimpleTOD}([C_t, B_t, D_t,A_t])
St=SimpleTOD([Ct,Bt,Dt,At])
来生成回复。这里会涉及到delexicalization,比如上图中的[value count],这里表示这个值是从数据库中查询的结果,不关心具体的值。
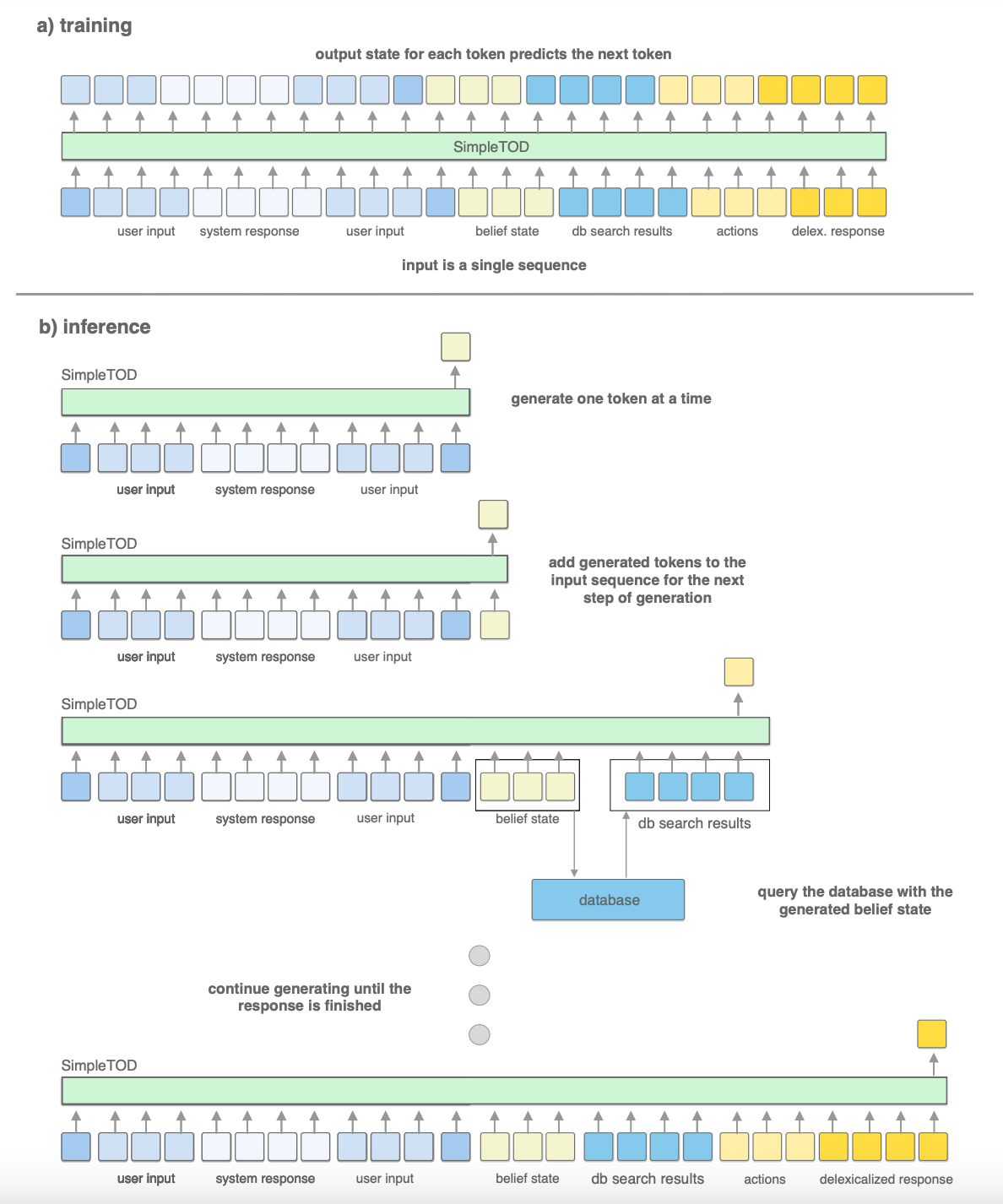
训练过程如上图所示,a)训练就是把用户的输入、系统的回复、belif state、DB查询结果、生成的动作等基于语言模型的要求作为一个token序列喂给SimpleTOD。
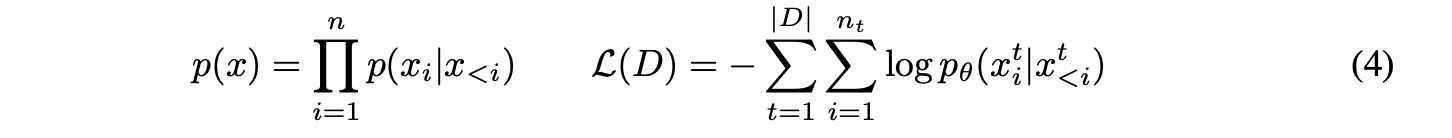
其中
x
=
(
x
1
,
⋯
,
x
n
)
x=(x_1,\cdots,x_n)
x=(x1,⋯,xn);
x
t
=
[
C
t
;
B
t
;
D
t
;
A
t
;
S
t
]
x^t=[C_t;B_t;D_t;A_t;S_t]
xt=[Ct;Bt;Dt;At;St]。
b)推理也是先把 C t C_t Ct拼接起来,送给模型,然后会得到一个belief state,然后再把预测的 B t B_t Bt(和查询到的 D t D_t Dt)也拼起来继续喂给模型得到 A t A_t At,基于这些来生成回复。
SOLOIST

来自论文SOLOIST: Building Task Bots at Scale with Transfer Learning and Machine Teaching。
采用预训练-微调范式
- 自回归语言模型
- 使用更大的对话语料库预训练
- 使用一些任务相关的对话微调
使用的模型是Unified Language Model。
我们来看下它的输入和输出。
输入:
- 历史对话
- belief state
- DB state(DB查询结果)
- delexicalized response
可以用 x = ( s , b , c , r ) x=(s,b,c,r) x=(s,b,c,r)来表示。
预训练时使用task-grouded的预训练,包含
- 多任务目标
- 自监督
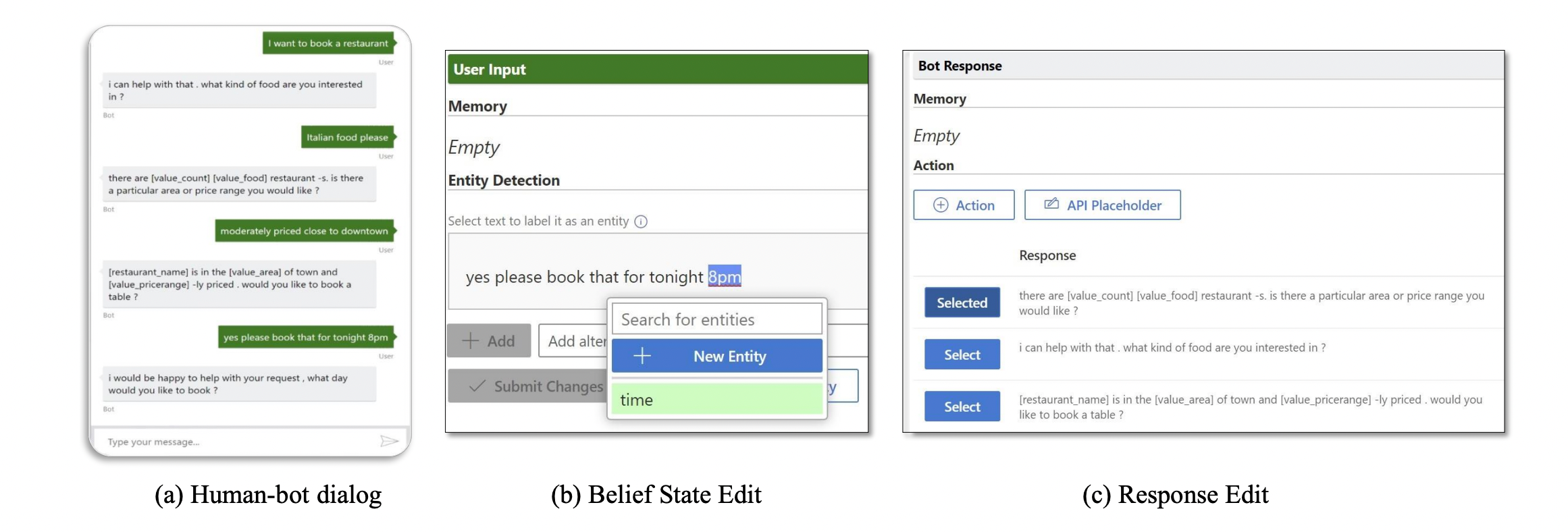
在微调时用了machine teaching的方法。
模型的训练目标,也是分为说那个任务:Belief State Prediction(DST+NLU)、Grounded Response Generation(NLG)和Contrastive Objective(自监督)。
它输入中的历史对话和SimpleTOD有一些区别,这里只有用户说的话,没有系统的回复。
通过以下方式建模:
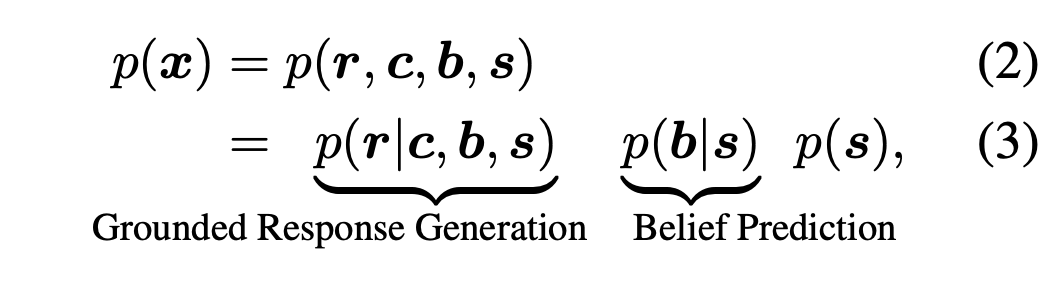
其中主要有两个任务:


最后使用对比损失,将输入中的词以50%的概率随机替换:
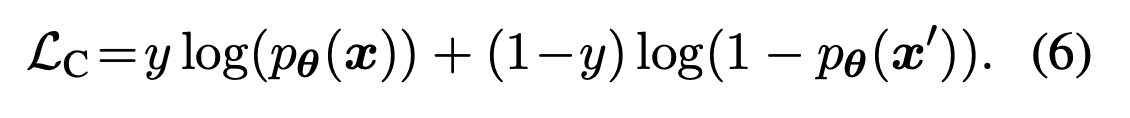
上面说的machine teacher实际是指通过人工更正模型输出的结果:
UBAR
来自论文UBAR: Towards Fully End-to-End Task-Oriented Dialog System with GPT-2
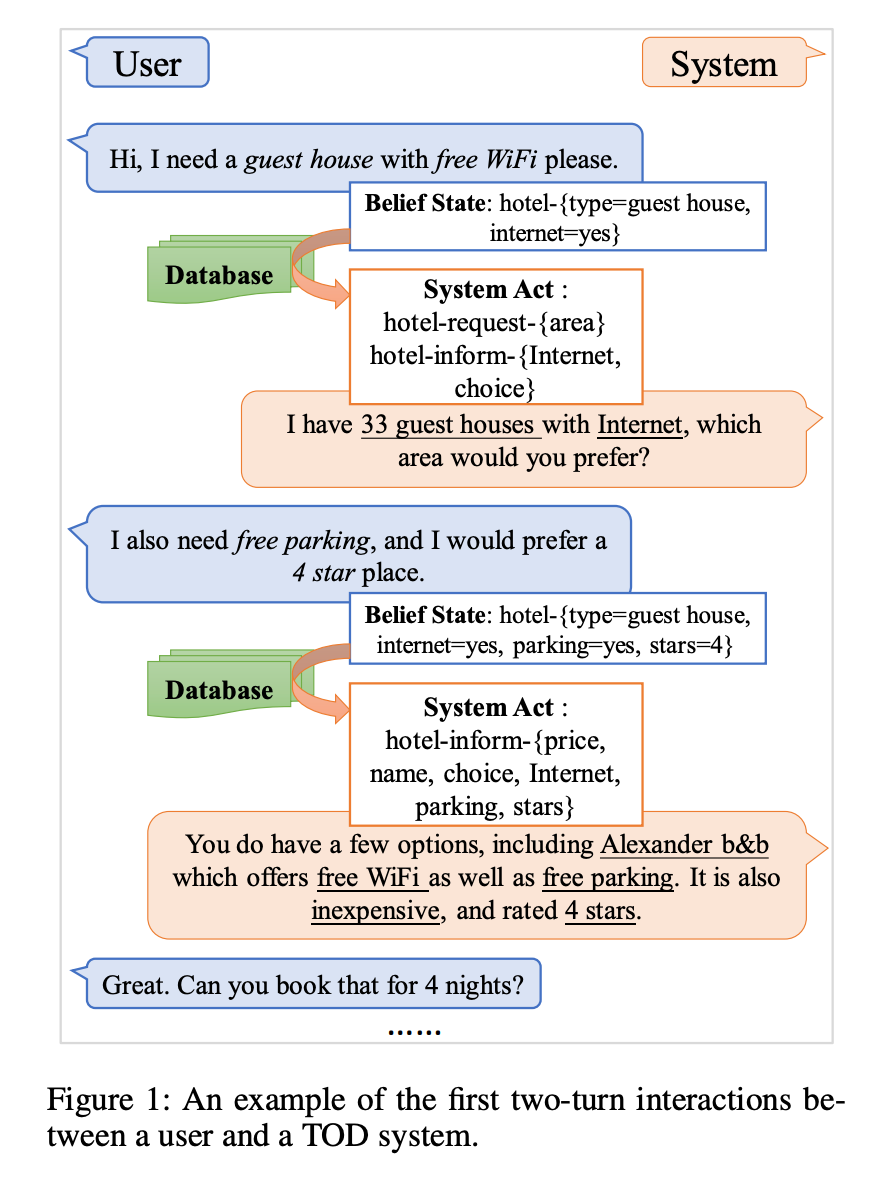
作者尝试把完整的对话历史喂给模型,还是基于GPT-2模型,基于用户的输入,需要预测blief state、system action和system response。
架构类似SimpleTOD和SOLOIST的结合体,任务类似SOLOIST的。
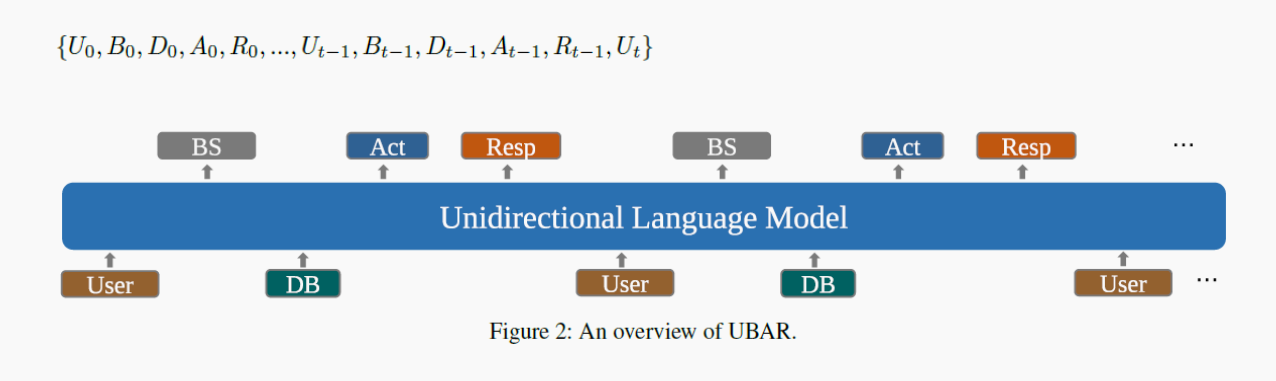
从上图可以看到,其中最上面表示模型的输入,是完整的对话历史。U代表用户的输入;B是需要预测的Blief State,A是Action,R是Response,D是数据库查询。
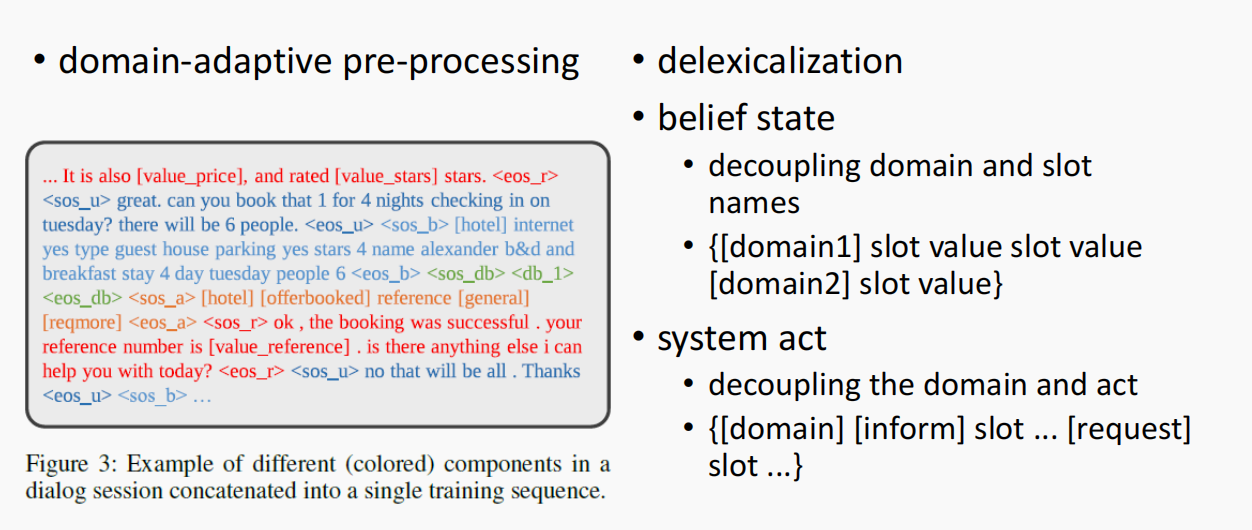
上面是一个输入的范例。
在belief state中对domain和slot value进行解耦;同时在system act中也对domain和action进行解耦。
参考
- 贪心学院课程
- A Simple Language Model for Task-Oriented Dialogue
- SOLOIST: Building Task Bots at Scale with Transfer Learning and Machine Teaching
- UBAR: Towards Fully End-to-End Task-Oriented Dialog System with GPT-2