文章目录
- 前缀树介绍
- 节点
- 初始化前缀树
- 添加敏感词
- 删除敏感词
- 敏感词过滤
- 代码实现
前缀树介绍
前缀树(Trie),也称为字典树或前缀字典树,是一种特殊的多叉树数据结构。它用于高效地存储和检索字符串集合。以下是前缀树的常见数据结构和相关术语:
- 节点(Node):每个节点包含一个字符和指向子节点的链接。通常使用散列表、数组或其他数据结构来存储子节点链接。
- 根节点(Root Node):前缀树的顶层节点,没有父节点。
- 子节点(Child Node):一个节点的直接后代节点。
- 叶节点(Leaf Node):没有后续节点的节点,用来表示字符串的结束字符。
- 边(Edge):连接相邻节点的链接,每个边上都标有一个字符。
- 树的高度(Height):从根节点到最深叶节点的最长路径。
- 前缀(Prefix):从根节点到任意节点的路径,表示一个字符串的前缀。
基于这些术语,前缀树的基本操作包括插入、搜索、删除和前缀匹配。通过构建一个前缀树,可以实现高效地存储和检索大量字符串,快速判断一个字符串是否是集合中的成员,并找到具有给定前缀的所有字符串。
节点
前缀树(Trie)的节点结构通常由两部分组成:节点值和子节点集合。子节点集合通常使用散列表、数组或其他数据结构。
我们还需要使用 endOfWord 标识该节点是否为一个单词的结尾。如果某个节点的 isEndOfWord 为 true,则表示从根节点到当前节点的路径构成了一个完整的单词,即过滤词。
下面是一个示例的前缀树节点结构:
class TrieNode {
private Map<Character, TrieNode> children; // 子节点集合
private boolean endOfWord; // 标识是否为单词的结尾
public TrieNode() {
children = new HashMap<>();
endOfWord = false;
}
public Map<Character, TrieNode> getChildren() {
return children;
}
public boolean isEndOfWord() {
return endOfWord;
}
public void setEndOfWord(boolean endOfWord) {
this.endOfWord = endOfWord;
}
}
通过这种节点结构,我们可以链接节点以形成一个树形结构,每个节点代表一个字符。通过不断地添加子节点,我们可以构建出完整的前缀树,用于高效地存储和搜索字符串集合。
初始化前缀树
前缀树有一个根节点(Root Node)作为起始节点。前缀树的初始化过程如下:
-
创建一个空的前缀树,即一个根节点。
-
遍历字符串集合,逐个插入字符串到前缀树中。
-
对于每个字符串,从根节点开始,检查当前字符是否已经存在于当前节点的子节点中。
- 如果存在,移动到该子节点,并继续处理下一个字符。
- 如果不存在,创建一个新的子节点,将当前字符添加到子节点中,并移动到该子节点。
-
重复步骤3,直到字符串的所有字符都被插入到前缀树中。
-
重复步骤2-4,直到字符串集合中的所有字符串都被插入到前缀树中。
通过上述初始化过程,我们可以构建一个包含所有字符串集合中字符串的前缀树。这样,在后续的搜索或过滤操作中,我们可以利用前缀树的特性来提高效率,快速地查找和处理字符串。
添加敏感词
我们可以将一个敏感词插入到前缀树中。每个字符都对应着一个节点,通过连接节点的方式,形成了一个表示敏感词的路径。最后一个字符对应的节点被标记为敏感词的结尾,以便在后续的搜索操作中判断是否存在完整的敏感词。前缀树中添加一个敏感词的过程如下:
-
创建一个指向根节点的
current变量,用于表示当前节点。 -
遍历敏感词的每个字符。
-
对于每个字符,在当前节点的子节点集合中查找是否存在字符对应的子节点。
- 如果存在子节点,则将
current更新为该子节点; - 如果不存在子节点,则使用创建一个新的子节点,并将
current更新为该新节点。
- 如果存在子节点,则将
-
重复步骤3,直到遍历完整个敏感词的所有字符。
-
将最后一个字符所对应的节点(即单词的末尾字符)设置为单词的结尾,将其
endOfWord属性设置为true,表示该单词在前缀树中存在。
删除敏感词
要删除前缀树中的敏感词,可以采用递归的方式遍历前缀树来查找待删除的敏感词。默认从根节点开始,并通过字符索引递归地将路径沿着前缀树向下移动。
- 如果到达了敏感词的最后一个字符,表示找到了待删除的单词节点。将该节点的
endOfWord属性设置为false,表示该单词不再存在于前缀树中,并判断当前节点是否有其他子节点,如果没有子节点则删除当前字符对应的子节点。 - 如果还没有到达敏感词的最后一个字符,继续向下遍历前缀树,直到找到敏感词的最后一个字符。如果递归地删除该字符之后,发现当前节点没有其他子节点了,则可以将当前字符对应的子节点从父节点的子节点集合中删除,保持树的结构和有效性。
敏感词过滤
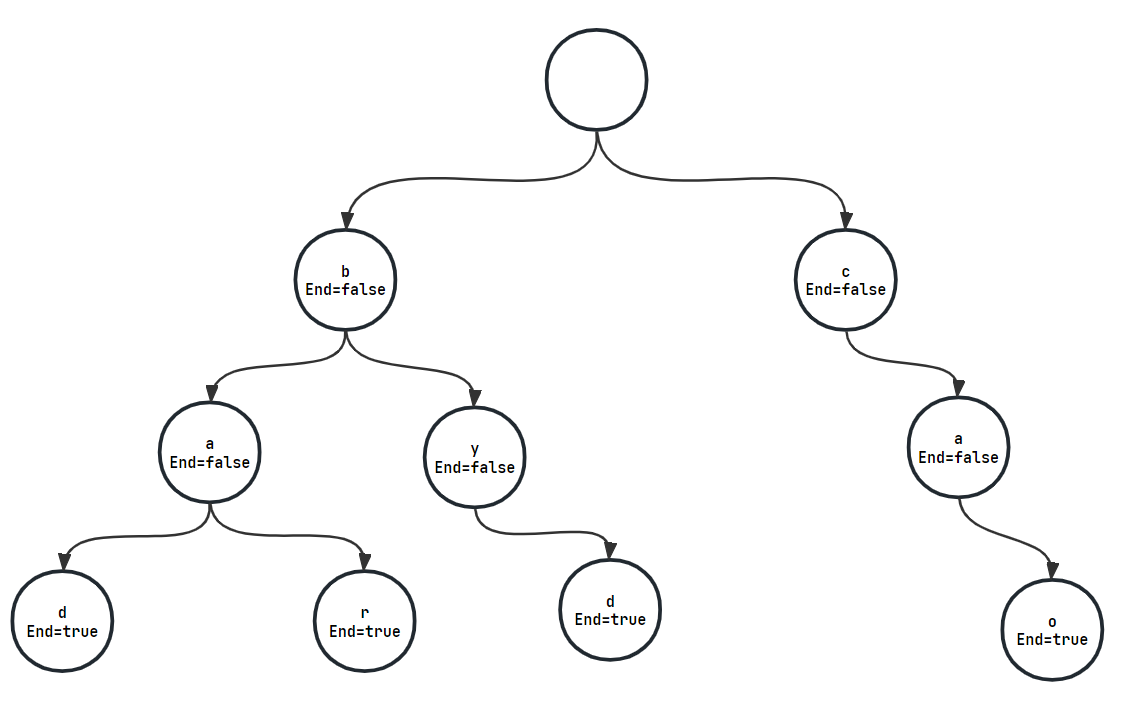
假设我们已经初始化完成一个前缀树,其中包含以下敏感词:「bad」、「bar」、「byd」、「cao」,我们对「This is a bad example. The bar is closed.」进行过滤:
- 逐个字符遍历「This is a bad example. The bar is closed.」:
- 第一个字符「T」与前缀树匹配不上,因此将其添加到过滤后文本中。
- 第二个字符「h」与前缀树匹配不上,因此将其添加到过滤后文本中。
- 第三个字符「i」与前缀树匹配不上,因此将其添加到过滤后文本中。
- 第四个字符「s」与前缀树匹配不上,因此将其添加到过滤后文本中。
- 由于字符「 」(空格)不是字母或数字,直接添加到过滤后文本中,重置前缀树的当前节点为根节点。
- 重复步骤1和2,直到遍历完整个原始文本。
- 遍历到「bad」时:
- 第一个字符「b」与前缀树节点 b 匹配,继续处理下一个字符。
- 第二个字符「a」与前缀树节点 a 匹配,继续处理下一个字符。
- 第三个字符「d」与前缀树节点 d 匹配。
- 当前单词为「bad」,由于结束符号「d」的
endOfWord属性为true,代表这是一个敏感词,将当前单词替换为「***」并添加到过滤后文本中。 - 「bar」匹配流程相同。
- 最终过滤后的文本为:「This is a *** example. The *** is closed.」
通过前缀树,我们可以高效地找到和替换敏感词,将其过滤或标记为合适的内容。这样能够保护用户免受敏感词的影响。
代码实现
代码实现如下:
import java.util.HashMap;
import java.util.Map;
public class TrieFilter {
private TrieNode root;
public TrieFilter() {
root = new TrieNode();
}
// 添加敏感词
public void addWord(String word) {
TrieNode current = root;
for (char c : word.toCharArray()) {
current = current.getChildren().computeIfAbsent(c, k -> new TrieNode());
}
current.setEndOfWord(true);
}
// 删除敏感词
public void deleteWord(String word) {
deleteWord(root, word, 0);
}
private boolean deleteWord(TrieNode current, String word, int index) {
if (index == word.length()) {
if (!current.isEndOfWord()) {
return false; // 单词不存在于前缀树中,无需删除
}
current.setEndOfWord(false); // 将当前节点标记为非单词结尾
return current.getChildren().isEmpty(); // 判断当前节点是否有其他子节点
}
char c = word.charAt(index);
TrieNode child = current.getChildren().get(c);
if (child == null) {
return false; // 单词不存在于前缀树中,无需删除
}
boolean shouldDeleteChild = deleteWord(child, word, index + 1);
if (shouldDeleteChild) {
current.getChildren().remove(c); // 删除当前字符对应的子节点
return current.getChildren().isEmpty(); // 判断当前节点是否有其他子节点
}
return false;
}
// 敏感词过滤
public String filter(String text) {
StringBuilder filteredText = new StringBuilder();
StringBuilder currentWord = new StringBuilder();
TrieNode current = root;
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (Character.isLetterOrDigit(c)) { // 字母或数字,继续匹配
current = current.getChildren().get(Character.toLowerCase(c));
if (current != null) {
currentWord.append(c);
if (current.isEndOfWord()) {
currentWord.replace(0, currentWord.length(), "***");
}
} else {
filteredText.append(currentWord);
filteredText.append(c);
currentWord.setLength(0);
current = root;
}
} else { // 非字母或数字,结束当前单词匹配
filteredText.append(currentWord);
filteredText.append(c);
currentWord.setLength(0);
current = root;
}
}
filteredText.append(currentWord);
return filteredText.toString();
}
// 节点结构
class TrieNode {
private Map<Character, TrieNode> children;
private boolean endOfWord;
public TrieNode() {
children = new HashMap<>();
endOfWord = false;
}
public Map<Character, TrieNode> getChildren() {
return children;
}
public boolean isEndOfWord() {
return endOfWord;
}
public void setEndOfWord(boolean endOfWord) {
this.endOfWord = endOfWord;
}
}
}
使用示例:
public static void main(String[] args) {
TrieFilter filter = new TrieFilter();
filter.addWord("敏感词1");
filter.addWord("敏感词2");
filter.deleteWord("敏感词2");
String text = "这是一段包含敏感词1和敏感词2的文本";
String filteredText = filter.filter(text);
System.out.println(filteredText);
}
输出结果:
这是一段包含***和敏感词2的文本
在上述示例中,我们创建了一个 TrieFilter 类来实现敏感词过滤功能。使用 addWord 方法将敏感词添加到前缀树中,然后使用 filter 方法对文本进行过滤,将匹配到的敏感词替换为 ***,使用 deleteWord 方法从前缀树中删除敏感词。